Как использовать аудит-логи для разбора инцидентов за 5 минут
Как использовать аудит-логи для разбора инцидентов: разберем, какие вопросы лог обязан закрывать за 5 минут после жалобы пользователя.
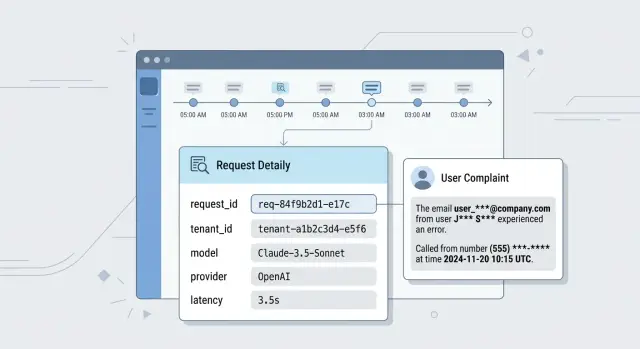
Что происходит после жалобы пользователя
Жалоба почти всегда приходит в плохом виде: "бот выдал чужие данные", "ответ был странный", "пропал нужный блок". У пользователя нет request_id, имени модели и версии промпта. У него есть только время, скриншот и раздражение.
Первыми тикет видят сотрудники поддержки, но полной картины у них обычно нет. Они знают аккаунт, примерное время и текст жалобы. Этого мало. Если лог не связывает сессию, пользователя, API-ключ и конкретный запрос, первые минуты уходят на ручной поиск по чатам, таблицам и памяти команды.
Дальше подключается разработчик и задает несколько простых вопросов. Какой запрос реально ушел в модель? Какой системный промпт добавился? Какая версия шаблона работала в этот момент? Какую модель и какого провайдера выбрал шлюз? Если запросы идут через единый LLM-шлюз, без точного следа легко перепутать и модель, и провайдера, и параметры вызова.
На этом месте спор начинается слишком рано. Один человек уверен, что сработал старый промпт. Другой помнит, что вчера меняли роутинг. Третий считает, что виноват кэш. Без лога команда вспоминает, а не проверяет.
Поэтому вопрос "как использовать аудит-логи для разбора инцидентов" на практике сводится к более простой вещи: можно ли за пять минут восстановить одну понятную историю запроса. Если нельзя, инцидент почти сразу уходит выше, а команда все еще ищет следы.
Обычно в разборе участвуют сразу несколько ролей:
- поддержка хочет понять, кого затронул инцидент и что отвечать пользователю;
- разработчик хочет восстановить точную комбинацию промпта, модели и параметров;
- безопасность проверяет, были ли персональные данные и кто их видел;
- юристы и комплаенс ждут точный след действий, а не пересказ в чате.
Представьте простой случай: менеджер пишет, что ассистент показал не тот номер заказа. Если аудит-лог собран нормально, команда за минуты видит исходный запрос, добавленные инструкции, ответ модели и дальнейшие действия в системе. Если такого следа нет, один инцидент превращается в несколько версий событий, и каждая отнимает время.
Какие вопросы лог должен закрывать сразу
После жалобы у команды обычно нет часа на раскопки. Хороший аудит-лог должен за пять минут показать, это сбой, ошибка в настройке или спорный ответ модели.
Сразу должны закрываться пять вопросов.
- Кто отправил запрос. Без
user_id,tenant_idи идентификатора API-ключа инцидент быстро превращается в гадание. В системах с несколькими клиентами и средами эти поля сразу отделяют пользовательский трафик от тестов и внутренней отладки. - Когда это случилось. Лог должен хранить точное время в UTC и понятное локальное представление. Иначе жалоба на "вчера в 19:40" легко уедет на пару часов вместе со всей цепочкой событий.
- Куда пошел запрос. Недостаточно знать, что ответ дал "LLM". Нужно видеть сервис, маршрут, модель, провайдера и регион. Для шлюза это особенно важно: запрос мог уйти не туда после смены правил, фолбэка или ручной правки конфигурации.
- Что система отправила и что получила обратно. Не обязательно хранить весь текст целиком, но нужны маскированные фрагменты входа и выхода, параметры вызова, тип вложений и статус ответа. Иначе непонятно, ошиблась модель или система исказила запрос до отправки.
- Что изменилось незадолго до инцидента. Если кто-то за десять минут до жалобы поменял маршрут, лимит, правило маскирования или список разрешенных моделей, лог должен показать это сразу с именем актора и временем.
Когда эти ответы видны сразу, команда тратит время на решение проблемы, а не на поиск улик.
Что писать в аудит-лог
Если в логе нет идентификаторов, команда тратит время на догадки. Каждая запись должна отвечать на простой вопрос: это тот самый запрос или уже соседний.
Начните с request_id и trace_id. Первый помогает найти конкретный вызов. Второй собирает всю цепочку, если сервисов несколько: API-шлюз, оркестратор, инструмент, база, модерация. Когда пользователь жалуется на один ответ, trace_id часто экономит половину разбора.
Рядом нужны user_id, tenant_id и идентификатор API-ключа. Тогда за минуту понятно, кто отправил запрос, из какой организации он пришел и каким доступом пользовались. Для B2B-сценариев это особенно важно: одна и та же модель может работать для десятков команд, и путаница между арендаторами ломает весь разбор.
Запись должна фиксировать и то, какой код повлиял на ответ. Минимальный набор здесь такой: версия промпта, шаблон ответа и имя сервиса или воркера. Без этих полей вы увидите сам факт ошибки, но не поймете, почему система выдала именно такой текст. Если вчера команда поменяла системный промпт, лог должен показать это без похода в репозиторий.
Отдельный блок нужен для маршрутизации. Храните модель, провайдера, регион и версию маршрута. Это особенно полезно, когда один и тот же запрос может уйти разными путями. Если система работает через общий шлюз, команда должна видеть не только имя модели, но и через какого провайдера прошел вызов.
Текст запроса и ответа тоже нужен, но не в сыром виде. Лучше хранить маскированные фрагменты входа и выхода, например первые 200-500 символов. PII стоит закрывать сразу, а чувствительные поля заменять метками. Этого хватает, чтобы понять смысл диалога и не тащить в лог лишние риски.
В конце записи оставьте операционные поля: задержку по этапам и общую latency, число входных и выходных токенов, вызовы инструментов с именем и статусом, код ошибки и короткую причину. Такой набор закрывает почти все первые вопросы после жалобы: кто отправил запрос, что система увидела, куда его направила, какой код сработал и на каком шаге все пошло не так.
Как собрать одну цепочку событий
Когда пользователь жалуется, команда ищет не "все логи подряд", а одну историю запроса. Она должна начинаться в точке входа и заканчиваться тем ответом, который человек увидел на экране или получил по API.
Для этого нужен один request_id на весь путь запроса. Создайте его на входе и протащите через шлюз, маршрутизацию, проверки, вызовы модели, постобработку и отправку ответа. Если запрос идет через OpenAI-совместимый шлюз вроде AI Router, этот идентификатор не должен теряться между вашим сервисом, шлюзом и провайдером.
Одного общего идентификатора мало, если система делает ретраи или вызывает инструменты. У каждой повторной попытки должен быть свой retry_id, а у каждого вызова инструмента свой tool_call_id. Тогда видно, что первый запрос упал по таймауту, второй ушел в другую модель, а третий уже дал ответ пользователю.
Связь между запросом пользователя и ответом провайдера тоже должна быть прямой, а не "по времени примерно совпало". В логах полезно хранить внешний provider_request_id, имя модели, статус ответа, причину остановки и метки времени на каждом шаге. Без этого команда спорит, где была ошибка: в вашем коде, в маршрутизаторе или у провайдера.
Отдельно фиксируйте все изменения, которые могли повлиять на результат именно в этот момент. Если сервис подменил промпт, переключил модель, включил другой набор правил доступа или применил новую политику маскирования, лог должен показать это явно и со временем изменения.
Обычно хватает пяти связок:
- родительский
request_idдля всей цепочки; - дочерние идентификаторы для ретраев и вызовов инструментов;
provider_request_idдля ответа внешней модели;- версия промпта, модель и версия правил доступа;
- кто и когда менял настройки вручную.
Ручные действия в панели часто ломают разбор сильнее, чем код. Кто-то поменял правило доступа в 14:03, а жалоба пришла в 14:07. Если вы не логируете такие действия с именем сотрудника, временем и старым и новым значением, команда тратит полчаса на догадки.
Хорошая цепочка событий отвечает на один вопрос: что именно произошло с этим запросом, шаг за шагом. Если любой шаг нельзя связать с предыдущим, расследование сразу замедляется.
Как провести разбор за пять минут
После жалобы не нужно сразу доказывать точную причину. Сначала нужно убрать туман: понять, что именно произошло, где это случилось и что проверять дальше.
Первая минута уходит на поиск одного опорного идентификатора. Лучше всего работает request_id из тикета, клиентского лога или сообщения об ошибке. Если его нет, ищите по времени события и user_id, но это медленнее и чаще дает лишние совпадения.
На второй минуте проверьте контекст запроса. Кто его отправил, в каком tenant_id, каким API-ключом и в какое время. Тут часто всплывает простая причина: жалоба пришла от одного пользователя, а лог относится к другому аккаунту, тестовому ключу или соседнему окружению.
Дальше восстановите маршрут запроса. Нужны четыре вещи: какой сервис принял запрос, какая модель ответила, через какого провайдера пошел вызов и в каком регионе это случилось. Для LLM-систем это не мелочь. Один и тот же промпт может дать разный результат, если роутер отправил его в другую модель или на другой бэкенд.
Что смотреть в середине разбора
Теперь сравните маскированные вход и выход. Не читайте лог как роман. Проверьте, совпадает ли запрос с жалобой пользователя, были ли повторы, менялся ли промпт после препроцессинга, вернулась ли ошибка до ответа модели или уже после него. Если пользователь пишет "ассистент ответил чужими данными", ищите не только текст ответа, но и следы подмешанного контекста.
Потом откройте вызовы инструментов, кэш и лимиты. Часто проблема не в модели, а в том, что система взяла старый кэш, сходила не в тот инструмент, уткнулась в rate limit или повторила запрос после таймаута. В шлюзе вроде AI Router такие следы особенно полезны, потому что один request_id может пройти через несколько слоев маршрутизации.
К пятой минуте у вас должна быть первая рабочая версия причины. Не окончательный вердикт, а короткая запись: "запрос ушел через другой ключ", "ответ пришел из кэша", "инструмент вернул чужой контекст", "провайдер дал повтор с новым результатом". Рядом запишите следующий шаг: отключить кэш, проверить изоляцию по tenant_id, поднять полный trace или запросить сырой лог у команды бэкенда.
Пример: ассистент ответил чужими данными
Такая жалоба обычно звучит резко и коротко: пользователь пишет, что ассистент показал не его телефон, адрес или номер договора. В этот момент спорить с ощущениями бесполезно. Нужно быстро понять, был ли факт утечки, откуда пришли данные и что именно сломалось.
Аудит-логи LLM должны сразу связать жалобу с конкретной сессией. Если в записи есть tenant_id, session_id и источник данных, команда быстро видит базовую картину: в каком контуре работал запрос, какая сессия его отправила и откуда ассистент взял ответ. Уже на этом шаге часто видно самое неприятное. Например, сессия относится к tenant_id банка A, а инструмент вернул запись из CRM другого tenant_id. Это уже не "галлюцинация", а ошибка изоляции данных.
Следом смотрят вызов инструмента. Лог должен показать, какой поиск сработал: векторный, SQL, CRM API или внутренний каталог. Полезны имя инструмента, параметры запроса, набор найденных record_id и статус авторизации. Тогда картина собирается быстро. Ассистент мог получить чужие поля не потому, что модель их придумала, а потому что backend отдал лишнюю карточку клиента после поиска без фильтра по tenant_id.
Версия промпта тоже многое меняет. Если вчера команда обновила правило для tool calling, это должно быть видно сразу. Допустим, в prompt_version v17 был жесткий запрет отвечать по CRM без проверки владельца записи, а в v18 этот шаг случайно убрали. Тогда причина уже не в модели и не в индексе, а в изменении бизнес-логики.
Последняя проверка - маскированный фрагмент ответа. Он подтверждает факт инцидента без новой утечки. В логе достаточно сохранить кусок вроде: "Ваш номер: +7 7XX XXX 12 34, договор N ***5481". Этого хватает, чтобы понять, что пользователь прав, и не растащить персональные данные по чатам и тикетам.
Если платформа маскирует PII прямо в аудит-логах, разбор идет спокойнее. Инженер видит факт, источник и версию промпта, но не копирует чужие данные дальше по цепочке.
Где команды теряют время
Команда редко теряет часы на саму ошибку. Обычно время съедает лог, который отвечает слишком мало. Жалоба уже пришла, пользователь ждет объяснение, а инженеры сначала пытаются понять, что вообще случилось.
Самый частый провал простой: лог хранит только статус запроса и код ошибки. Для падений этого иногда хватает. Для жалоб вроде "ассистент показал не те данные" или "ответ резко изменился после вчерашнего релиза" такой лог почти пустой. Код 200 не говорит, какой промпт сработал, какая модель ответила, что изменилось в правилах и прошла ли маскировка PII.
В LLM-системах путаница быстро растет, если сервисы пишут разное время. Один сервис пишет локальное время, другой UTC, третий округляет секунды. Потом команда смотрит на три записи и спорит, что было раньше: смена системного промпта, запрос пользователя или ответ модели. На одну такую сверку легко уходит 20 минут.
Еще одна частая дыра: запросы лежат отдельно от смен промптов, правил модерации, маршрутизации и версий шаблонов. Тогда расследование превращается в ручную сборку пазла из нескольких систем. Если запрос ушел через шлюз, потом прошел маскирование данных, а затем постобработку, без общей цепочки событий никто быстро не поймет, на каком шаге появился сбой.
Сырые тексты с персональными данными тоже крадут время. Такой лог страшно давать широкой команде, и доступ сужают до пары людей. Дальше начинаются пересылка скриншотов, ручное редактирование и ожидание. Безопаснее хранить маскированные поля и метаданные, а не складывать в аудит-лог все как есть.
Срок хранения ломает разбор еще до старта. Пользователь пожаловался в понедельник, поддержка эскалировала в среду, инженеры открыли лог в четверг, а нужные записи уже удалились через 48 часов. После этого команда спорит по памяти, а не по фактам.
Есть и более приземленная причина: у схемы лога нет хозяина. Каждая команда пишет поля по-своему, меняет названия без предупреждения и не проверяет качество записей. Через месяц request_id есть не везде, версия промпта пропадает в части запросов, а поле с моделью у одного сервиса называется model, у другого provider_model. В таком логе теряется не только время. Теряется уверенность в выводах.
Чек-лист логирования инцидентов
Хороший лог отвечает на первые вопросы без переписки между поддержкой, ML-командой и бэкендом. Если пользователь прислал время ошибки, request_id или user_id, инцидент должен находиться за пару запросов в поиске, а не через ручной просмотр сотен записей.
Быстрая проверка обычно сводится к шести пунктам:
- запись находится по
request_id,user_idили точному окну времени; - видны
tenant_id, API-ключ, среда и источник запроса; - есть версия промпта, модель, провайдер и маршрут выполнения;
- сохранены маскированные вход и выход, чтобы понять суть жалобы без утечки PII;
- отмечены повторы, кэш, вызовы инструментов и срабатывание
rate limit; - системные события отделены от ручных действий сотрудников.
Последний пункт часто недооценивают. Если сотрудник поддержки перезапустил задачу, сменил промпт, отключил инструмент или временно поднял лимит, это должно жить в отдельном журнале с именем человека и временем действия. Иначе команда спорит о модели, хотя сбой вызвало ручное вмешательство.
Полный текст хранить рискованно, а пустой лог бесполезен. Рабочий компромисс простой: скрывайте PII, но оставляйте структуру запроса, служебные поля, длину текста, названия инструментов, статус кэша и код ответа модели.
Если на этом шаге вы не видите хотя бы половину этих полей, разбор жалоб пользователей уже тормозит. Значит, следующий инцидент снова придется собирать по кусочкам.
Что сделать дальше
Если после жалобы команда все еще ищет ответ по чатам, таблицам и скриншотам, проблема не в людях. Проблема в том, что лог не собирает одну понятную историю запроса.
Начните с малого: утвердите один обязательный набор полей и одну схему имен. Даже мелочь вроде request_id должна называться одинаково во всех сервисах, а не requestId в одном месте и req_id в другом. Для каждой записи обычно нужны идентификатор запроса, безопасный идентификатор пользователя, время события, версия промпта, модель, API-ключ, статус ответа, признак ручного действия и parent_event_id, если событие продолжает другую запись.
Потом возьмите три недавние жалобы и прогоните их через эту схему. Засеките время до первого внятного ответа: что отправил пользователь, какая модель обработала запрос, где именно цепочка пошла не так. Если на это уходит больше пяти минут, аудит-логи LLM пока не решают задачу.
Чаще всего время пропадает не на сложных сбоях, а на слепых зонах. Проверьте места, где команды обычно спотыкаются:
- часовой пояс в продукте, шлюзе и хранилище не совпадает;
- повторы и ретраи выглядят как разные инциденты;
- смена системного промпта или шаблона нигде не записана;
- ручные действия поддержки живут отдельно от общей цепочки.
Назначьте одного человека, который пишет первый вывод по инциденту за пять минут. Не полный разбор, а короткую записку: таймлайн, затронутые пользователи, вероятная причина и чего не хватает в логе. Такой ритм быстро показывает слабые места лучше долгих обсуждений.
Если команда работает через AI Router, полезно заранее проверить, что в этой схеме уже задействованы маскирование PII, аудит-логи, rate limits на уровне ключа и хранение данных внутри Казахстана. Для команд, которым важны требования локального законодательства и разбор спорных ответов без ручной сборки следов, это не второстепенные детали. На airouter.kz такой слой контроля можно использовать как часть общей архитектуры, а не как отдельную историю рядом с продакшеном.
Через неделю повторите тот же тест еще на трех жалобах. Если команда собирает цепочку без ручного поиска по разным системам, вы движетесь в правильную сторону. Если нет, добавьте недостающее поле сразу, пока следующий инцидент не сделал ту же дыру дороже.
Часто задаваемые вопросы
Что делать, если у пользователя есть только время и скриншот?
Сначала сузьте окно по времени и аккаунту. Потом ищите запись по user_id, tenant_id, сессии, идентификатору API-ключа и маскированному фрагменту текста. Если лог собран нормально, вы быстро найдете нужный request_id и уже от него восстановите всю цепочку.
Какие поля нужны в аудит-логе в первую очередь?
В каждой записи держите request_id, trace_id, user_id, tenant_id, идентификатор API-ключа, время события, версию промпта, модель, провайдера, регион, маскированные вход и выход, статус ответа и код ошибки. Полезно сразу писать latency, токены, вызовы инструментов и версию маршрута.
Нужно ли хранить полный текст запроса и ответа?
Обычно нет. Для разбора хватает маскированных фрагментов, структуры запроса, параметров вызова и статуса ответа. Полный текст храните только там, где у вас есть строгий доступ и понятная причина, иначе вы сами создадите лишний риск.
Как за пару минут понять, проблема в модели или в системе?
Сравните четыре вещи: что пользователь отправил, какой промпт система добавила, куда роутер направил запрос и что вернул провайдер. Потом проверьте кэш, ретраи и вызовы инструментов. Так вы быстро увидите, сломался код, настройка или ответ реально дался на стороне модели.
Зачем разделять request_id, trace_id и provider_request_id?
Потому что это разные точки цепочки. request_id показывает один пользовательский вызов, trace_id связывает все шаги между сервисами, а provider_request_id ведет к ответу внешнего провайдера. Без этого команда начинает сверять события по времени и часто ошибается.
Как правильно логировать ретраи и вызовы инструментов?
Не смешивайте их в одну запись. На каждый повтор давайте свой retry_id, на каждый вызов инструмента — свой tool_call_id, и привязывайте их к родительскому запросу. Тогда видно, где был таймаут, какой шаг повторили и какой инструмент вернул результат.
Что проверять первым при жалобе на чужие данные?
Сразу смотрите tenant_id, session_id, источник данных, статус авторизации и найденные record_id. Потом проверьте, какой инструмент отдал контекст и не пропал ли фильтр по арендатору. Маскированный фрагмент ответа нужен, чтобы подтвердить факт утечки и не растащить PII дальше.
Почему разбор все равно может тормозить, даже если логи есть?
Чаще всего мешает не сама ошибка, а плохая схема. Время в сервисах не совпадает, названия полей отличаются, ручные правки никто не пишет, а часть событий лежит в другой системе. Из-за этого команда не видит одну историю запроса и тратит время на догадки.
На какой срок стоит хранить аудит-логи?
Храните их не меньше, чем живет обычная цепочка эскалации от поддержки до инженеров. Если жалобу поднимают через два-три дня, срок в 48 часов уже ломает разбор. На практике лучше держать быстрый доступ для свежих инцидентов и отдельное хранение для более старых записей.
Как понять, что текущая схема логов уже работает?
Возьмите несколько недавних жалоб и проверьте, может ли один инженер за пять минут ответить на три вопроса: что отправили, куда ушел запрос и где цепочка свернула не туда. Если для этого все еще нужны чаты, таблицы и ручной поиск, схему надо дополнять.