Где хранить API-ключи для LLM и как их ротировать
Где хранить API-ключи для LLM на серверах, в CI и локально: простая схема без секретов в коде, образах, чатах и логах.
Почему API-ключи утекают
Даже аккуратная команда может потерять секрет в обычный рабочий день. Дело чаще не в халатности, а в том, что ключ проходит через слишком много мест: ноутбук разработчика, переменные окружения, CI, сервер, мониторинг, чат, тикеты. Чем больше точек, тем выше шанс, что его случайно покажут не там.
Утечки редко начинаются с громкого взлома. Обычно все выглядит буднично. Разработчик вставил ключ в пример кода и забыл убрать. Кто-то включил подробные логи запросов. Кто-то отправил скриншот ошибки в общий чат. Кто-то выполнил команду с токеном прямо в терминале, и она осталась в истории shell. Один такой эпизод потом живет в репозитории, логах и переписке месяцами.
Чаще всего секреты всплывают в коде и конфиге, когда ключ "подставили на пять минут". Не отстают логи, если приложение пишет заголовки запросов, тело ошибок или переменные окружения. Отдельная проблема - скриншоты, видео и отладка в CI, где нередко печатаются команды целиком.
С API-ключом риск выше, чем с обычным паролем. Пароль обычно привязан к человеку: есть вход в аккаунт, второй фактор, история сессий, уведомления. Ключ чаще привязан к сервису и работает молча. Если его украли, злоумышленнику не нужно "входить" в систему. Он просто начинает слать запросы от имени вашего приложения, пока вы не отзовете доступ.
Еще одна частая ошибка - один общий ключ на всех. Сначала это удобно: меньше настроек, проще запуск. Потом вы теряете контроль. Непонятно, какой сервис тратит бюджет, кто выбрал лимиты и откуда пошел подозрительный трафик. А если ключ утек, менять его придется сразу везде: на серверах, в CI и в локальной среде команды.
Типичная ситуация выглядит так. Бэкенд-разработчик проверяет новый вызов модели, копирует рабочий ключ в локальный файл и включает debug-логи. Тест падает, он отправляет скриншот в общий чат. На снимке виден кусок токена, а в логах CI лежит полный заголовок Authorization. Никто не хотел ошибиться, но секрет уже разошелся по нескольким системам.
Поэтому защита строится не на доверии к внимательности людей. Нужна схема, при которой секреты не попадают в код, не печатаются в логах и не раздаются всем подряд.
Что считать секретом в LLM-инфраструктуре
Проблемы часто начинаются раньше вопроса "где хранить ключи". Команда просто не договорилась, что именно считать секретом. Один человек бережет только API-ключ провайдера, а другой спокойно коммитит токен для CI, потому что "это же не прод".
В LLM-инфраструктуре секретом считается не только доступ к модели. Секретом нужно считать все, что дает доступ, расширяет права или раскрывает данные: API-ключи провайдеров и шлюзов, сервисные токены для CI и бэкенда, refresh token, webhook secret, signing key, пароли и DSN к базам, очередям, векторным хранилищам, системам логирования, а также приватные конфиги с реальными значениями переменных.
В репозитории можно хранить только то, что не дает доступ само по себе. Подходят шаблоны вроде .env.example, имена переменных, список нужных прав, публичные названия моделей, base URL, флаги функций и инструкции по настройке. Реальные значения хранить нельзя, даже если проект тестовый, репозиторий закрытый, а ключ выдан всего на неделю.
Доступы по средам лучше разделять сразу. Dev, staging и production решают разные задачи, и риск у них разный. Если кто-то случайно сольет dev-ключ, вы потеряете время. Если тот же ключ дает доступ к production, вы получите чужие запросы, лишние расходы и плохой аудит.
Разные ключи для разных сред упрощают и логи, и ротацию. После инцидента можно отключить только staging и не трогать рабочий трафик. То же относится к лимитам, маскированию данных и доступу к журналам.
Не смешивайте личные и сервисные ключи. Личный ключ нужен человеку для локальной проверки и коротких экспериментов. Сервисный нужен приложению, CI или фоновой задаче. Если бэкенд ходит в production под личным ключом инженера, нормального аудита уже не будет, а увольнение или смена роли быстро превращаются в проблему.
Простое правило: все, чем пользуется человек, отделяйте от того, чем пользуется код. Тогда отзыв доступа у сотрудника не ломает production, а замена сервисного секрета не мешает локальной работе команды.
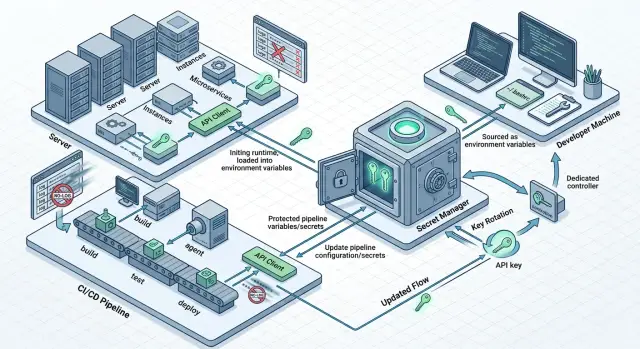
Где хранить ключи на серверах
На production-сервере API-ключ не должен жить в репозитории, в образе контейнера или в .env на диске. Такие файлы легко попадают в бэкапы, снапшоты и служебные архивы. Стоит кому-то скопировать сервер для диагностики, и секрет уедет вместе с ним.
Практичный вариант - менеджер секретов. Это может быть облачный secret manager, Vault или внутренний сервис, который хранит секреты отдельно от приложения. Сервер получает ключ при запуске или забирает его по запросу. Тогда вы меняете секрет в одном месте, а не ищете его вручную по всем машинам.
Обычно хватает двух схем. Первая: приложение получает секрет при старте и держит его только в памяти. Вторая: приложение запрашивает секрет короткими сессиями, если доступ нужно отзывать быстро и сервисов много. Первая схема проще. Вторая удобнее там, где доступы меняются часто.
Один общий ключ на все сервисы почти всегда создает лишний риск. Лучше выдать веб-приложению, воркеру и внутреннему админ-сервису разные ключи. Тогда сразу видно, кто тратит лимит и где произошла утечка. Проще и ограничить ущерб: у каждого сервиса свой лимит, свой набор прав и свое имя в аудит-логах.
Сами секреты часто утекают не из хранилища, а из диагностики. Разработчик открывает служебную страницу со списком переменных окружения, пишет токен в debug-лог или отправляет дамп ошибки в систему мониторинга. После этого даже хорошее хранилище уже мало помогает.
Проверьте две вещи. Приложение не должно печатать переменные окружения целиком, даже в debug-режиме. И обработчики ошибок должны маскировать токены, заголовки Authorization и похожие строки.
Правило здесь простое: сервер может получить секрет, но не должен показывать его человеку. Если токен нужен только для исходящего запроса к LLM API, держите его в памяти процесса, не сохраняйте на диск и не отдавайте в служебные страницы. Это заметно снижает риск даже при обычных сбоях и ночной отладке.
Как хранить секреты в CI
Для CI ответ почти всегда один: храните секреты в защищенных переменных самой CI-системы или во внешнем хранилище, к которому пайплайн получает доступ только на время задачи. Не кладите ключи в YAML-файлы, Dockerfile, тестовые данные и шаблоны команд. Репозиторий копируют, форкают и кэшируют чаще, чем кажется.
Секрет не должен попадать во все шаги сборки подряд. Шаг с линтером не должен видеть токен деплоя, а сборка фронтенда не должна получать production-ключ для LLM. Чем уже область доступа, тем меньше ущерб, если кто-то случайно выведет переменную в лог или сохранит артефакт.
Хорошая схема обычно выглядит так:
- У тестов, сборки и production разные секреты.
- Для dev, staging и production используются разные значения.
- Секреты попадают только в те job, где они действительно нужны.
- Деплой получает короткоживущий токен, а не постоянный ключ.
Такой подход упрощает ротацию. Если утек тестовый токен, вы меняете только его. Если деплой идет через временный токен на 10-15 минут, использовать его долго уже не получится.
Больше всего проблем обычно создают логи сборки. Люди добавляют echo, включают подробный режим shell или печатают весь набор переменных среды для отладки. После этого секрет уходит в историю job, уведомления и иногда в внешние системы мониторинга. Поэтому маскируйте секреты в CI, отключайте вывод команд с чувствительными переменными и проверяйте, какие артефакты сохраняет пайплайн.
Полезно считать опасным любой шаг, который пишет в лог. Пусть он получает только то, без чего работа действительно не начнется.
Если команда ходит к моделям через единый шлюз, удобно держать разные ключи для staging и production при одном и том же base_url. Код почти не меняется, а права и лимиты остаются разделенными по средам. Для команд, которые используют AI Router, это особенно удобно: можно оставить прежние SDK и тот же OpenAI-совместимый эндпоинт, но развести доступы и лимиты по отдельным ключам.
Как работать локально без секретов в репозитории
Локальная разработка ломается не из-за сложных атак, а из-за привычек. Кто-то кладет токен в .env, потом случайно коммитит файл. Кто-то вставляет ключ прямо в команду терминала, и он остается в истории shell.
Базовое правило простое: в репозитории не должно быть ни одного живого секрета. Ни в .env, ни в config.yaml, ни в примерах запросов, ни в тестах. Репозиторий должен хранить только форму, а не содержимое.
Для этого нужен шаблон вроде .env.example без значений. В нем оставляют только имена переменных: LLM_API_KEY=, LLM_BASE_URL=, MODEL_NAME=. Новый разработчик копирует шаблон в локальный .env, а реальные данные получает не из чата и не из README, а из защищенного места.
Лучше хранить рабочие секреты в системном хранилище или в командном менеджере паролей. На ноутбуке это может быть Keychain, Credential Manager или другой аналогичный инструмент. Тогда токен не лежит открытым текстом в папке проекта и не уходит в случайный коммит.
Для локальной работы нужен отдельный dev-ключ. Не давайте разработчику тот же ключ, который используется на сервере или в CI. У локального токена должны быть низкие лимиты, отдельная квота и, если возможно, доступ только к тестовым моделям.
Короткая схема такая:
- репозиторий хранит только
.env.exampleи описание переменных; - локальный
.envдобавлен в.gitignore; - реальные токены лежат в системном хранилище или менеджере паролей;
- для разработки используется отдельный dev-ключ.
Есть и менее заметная проблема - история команд. Если разработчик запускал что-то вроде export LLM_API_KEY=... прямо в терминале, токен мог сохраниться в shell history. После такой ошибки мало удалить строку с экрана. Нужно очистить историю, выпустить новый ключ и проверить, не попал ли он в логи IDE, терминала или локальных скриптов.
Хороший тест очень простой: клонируйте проект на чистую машину и попробуйте запустить его по инструкции. Если приложение поднимается без поиска секретов по переписке и без ручных правок в коде, схема уже работает нормально.
Как ротировать ключи по шагам
Тянуть с ротацией не стоит. Чем дольше один и тот же ключ живет в production, тем выше шанс, что он уже попал в старый лог, дамп, скриншот или переменную в CI.
Рабочая схема выглядит так: новый ключ должен начать обслуживать запросы раньше, чем вы отключите старый. Иначе простой вы устроите себе сами.
- Сначала соберите список всех действующих ключей. Для каждого укажите владельца, место хранения, сервисы, которые его используют, и ответственного за замену.
- Выпустите новый ключ заранее. Старый сразу не удаляйте. Оставьте короткое окно, когда оба ключа существуют параллельно.
- Обновите секрет в менеджере секретов, а не в коде и не в файле конфигурации на сервере. Затем перезапустите только те сервисы, которые читают секрет при старте.
- Сразу проверьте реальные запросы после замены. Смотрите на ошибки авторизации, рост 401 и 403, расход лимитов и алерты по отказам.
- Когда убедитесь, что трафик идет через новый ключ, отключите старый и зафиксируйте дату ротации в журнале изменений.
На практике чаще всего ломается третий шаг. Команда обновила секрет, но забыла, что часть воркеров держит его в памяти. В итоге половина запросов проходит, а половина падает. Если сервис кэширует конфиг, дайте ему явный рестарт и проверьте, что новый процесс действительно поднялся с новой версией секрета.
Типичный пример: у вас есть backend, очередь задач и nightly job для оценки промптов. Все три компонента ходят к LLM API. Если вы сменили ключ только у backend, сайт будет работать, а фоновые задачи начнут сыпать ошибки позже. Поэтому список потребителей лучше вести заранее, а не вспоминать по памяти в день ротации.
Если команда использует один LLM-шлюз вместо набора прямых интеграций, ротация обычно проще: вы меняете один секрет в менеджере, а не несколько ключей от разных провайдеров. Но порядок тот же. Сначала новый ключ, потом проверка трафика и только потом отключение старого.
Простой пример для команды
У небольшой SaaS-команды есть два LLM-сценария: чат в продукте и ночные batch-задачи для разметки заявок. Оба обращаются к одному шлюзу, но с разными секретами. Так проще видеть расход, ставить лимиты и не ломать все сразу одной ошибкой.
В production команда хранит только сервисные ключи, по одному на каждый контур и тип нагрузки. Ключ чата живет в менеджере секретов у backend-сервиса. Ключ для batch-задач лежит отдельно, потому что у него другой лимит, другой график запуска и выше риск внезапно сжечь бюджет.
Схема может быть такой:
prod-chat- запросы пользователей из приложения;prod-batch- фоновые задачи и переобработка;dev-shared- тестовый стенд и ручная проверка;personal-dev- личный ключ разработчика с маленьким лимитом.
CI не хранит секрет постоянно. Во время деплоя пайплайн получает нужный production-ключ из хранилища секретов, подставляет его в переменные окружения сервиса и теряет доступ после завершения job. Для тестов CI берет отдельный dev-shared или вообще работает на моках, если реальный вызов модели не нужен.
Локально разработчик не кладет секрет в репозиторий, Dockerfile или переписку. Он берет personal-dev, записывает его в локальный .env, который уже добавлен в .gitignore, и работает с жестким лимитом. Если ноутбук потеряется или ключ попадет в лог, ущерб будет ограниченным.
Когда сотрудник уходит, схема не рассыпается. Команда отключает его SSO, доступ к менеджеру секретов и личный dev-ключ. Production-ключи можно не менять, потому что бывший сотрудник не видел их в явном виде и не хранил у себя на машине.
Частые ошибки
Большинство проблем начинается не со взлома, а с желания сделать побыстрее. Токен кладут "временно" в удобное место, а потом он живет дольше проекта.
Самая дорогая ошибка - один ключ на всех сотрудников и все сервисы. Сначала это выглядит удобно: один токен для бэкенда, тестов, скриптов и нескольких людей из команды. Потом кто-то уходит в отпуск, кто-то меняет доступ, у сервиса растет нагрузка, и вы уже не понимаете, кто сжег лимит и какой процесс дал всплеск расходов. Отозвать такой ключ тоже больно: ломается сразу все.
Чаще всего лучше выдавать разные секреты по ролям и задачам. У сервиса свой ключ, у CI свой, у локальной разработки временный, у каждого человека личный доступ с понятным сроком жизни.
Еще одна частая ошибка - секреты в Dockerfile, готовых образах и Helm-конфигах. Если токен попал в Dockerfile через ARG или ENV, он может остаться в слоях образа и в истории сборки. Если ключ лежит в values-файле Helm, он быстро расползается по репозиторию, артефактам и окружениям. Удалить строку из текущей версии мало. Следы часто остаются в старых коммитах, registry и логах сборки.
Отдельная беда - печать заголовков Authorization в логах. Это случается чаще, чем кажется: отладочный middleware, подробное логирование HTTP-клиента, трассировка ошибок в прокси. Один такой лог потом уходит в систему сбора логов, в чат дежурных или в скриншот для тикета. После этого токен уже нельзя считать секретом.
Плохая практика обычно выглядит так:
- общий ключ для production, CI и локальных запусков;
- токен в Dockerfile или в открытом values-файле;
- полные HTTP-заголовки в access log;
- секреты в Telegram, Slack, почте и тикетах;
- ротация "когда будет время".
Отправка токенов в мессенджеры почти всегда оправдывается срочностью. "Скинь ключ на 10 минут" быстро превращается в постоянный канал утечки. Сообщение копируют, пересылают и находят через поиск по рабочим чатам. Через месяц уже никто не помнит, где лежит последняя рабочая версия.
Ручная ротация без списка владельцев и дат тоже ломает процессы. Если у ключа нет владельца, никто не следит за сроком жизни. Если нет даты следующей замены, ключ живет годами. Если нет списка сервисов, которые от него зависят, ротация превращается в ночную аварию.
Минимум, который стоит внедрить сразу: хранить секреты только в менеджере секретов или в защищенных переменных окружения, назначать владельца каждому ключу, фиксировать дату создания и дату замены, а в логах полностью скрывать токены и заголовки авторизации.
Быстрая проверка перед релизом
Релиз часто ломает не код, а мелочи вокруг него: забытый токен в переменной окружения, отладочный вывод в CI, старый ключ без лимита. За несколько минут до выкладки лучше пройти короткий список и закрыть эти дыры, чем потом разбирать инцидент.
Перед релизом проверьте пять вещей:
- у каждого сервиса свой отдельный ключ, а не общий токен на всю команду;
- для каждого ключа задан лимит по rate limit, бюджету или обоим сразу;
- CI не печатает секреты ни в логах шагов, ни в ошибках, ни в debug-режиме;
- логи приложения и трассировка скрывают токены, заголовки авторизации и PII;
- в календаре есть дата ближайшей ротации и понятный ответственный.
Этот список особенно полезен, когда у вас несколько сервисов: чат поддержки, внутренний поиск, batch-задачи. Если один ключ утечет, вы быстро поймете, какой сервис пострадал, и не остановите все сразу.
CI стоит проверить руками. Откройте последние пайплайны и посмотрите, что попало в stdout и stderr. Секрет часто утекает не в успешном шаге, а в аварийном, когда кто-то выводит полный объект ошибки вместе с заголовками запроса.
С логами правило такое же: разработчик должен видеть, что произошло, но не должен видеть сам секрет. То же относится к персональным данным. Токены лучше скрывать целиком, а PII убирать или заменять безопасными метками.
И еще одно простое замечание. Ротация без ответственного не работает. Если в календаре стоит дата, но никто не знает, кто меняет ключ и кто проверяет сервис после замены, у вас нет процесса, а есть надежда на удачу.
Что сделать дальше
Начните не с нового инструмента, а с ревизии того, что уже лежит в коде, CI и на серверах. После такого просмотра обычно быстро видно, какие ключи живут слишком долго, кто ими пользуется и где их могут случайно вывести в лог.
Исправлять все сразу не обязательно. За один день можно убрать секреты из репозитория, развести доступы по средам и включить маскирование логов. Это уже заметно снижает риск.
Дальше стоит сделать несколько практичных шагов: собрать список всех секретов, назначить владельца каждому из них, разделить dev, staging и production, выбрать одно место для хранения секретов и одно место для правил маскирования логов. Если где-то можно заменить постоянные ключи короткоживущими токенами, начните с CI и временных задач. А для production-потока сразу договоритесь, кто отправляет запросы, где хранятся данные, какие лимиты стоят на каждый сервис и где смотреть аудит.
Если команда работает в Казахстане и ведет LLM-нагрузку через несколько провайдеров, иногда полезно сократить количество прямых секретов на серверах и в CI. В этом месте AI Router может упростить схему: один OpenAI-совместимый эндпоинт, отдельные ключи для сервисов, аудит-логи, rate limits, маскирование PII и хранение данных внутри страны, если это важно для внутренних правил или требований закона.
Хороший ориентир на ближайшую неделю простой: убрать секреты из репозитория, разделить доступы по средам, включить маскирование логов и назначить дату первой ротации. После этого безопасность перестает быть разовой уборкой и становится обычной частью разработки.
Часто задаваемые вопросы
Можно ли хранить API-ключ в .env?
В репозитории — нет. Для локальной работы можно держать его в .env, только если файл попал в .gitignore и вы не копируете его в чат, скриншоты и логи. На сервере и в CI храните секреты в менеджере секретов или в защищенных переменных самой платформы.
Что в LLM-инфраструктуре считать секретом?
Секретом считайте не только доступ к модели. Туда же входят токены CI, refresh token, webhook secret, signing key, пароли к базам, DSN, доступы к очередям, векторным хранилищам и любые конфиги с реальными значениями, которые дают доступ или раскрывают данные.
Почему не стоит использовать один ключ на всех?
Один общий ключ быстро ломает учет и ротацию. Вы не поймете, какой сервис тратит лимит, кто дал всплеск трафика и где произошла утечка. Когда такой ключ утекает, команде приходится менять его сразу везде.
Где лучше хранить ключи на production-сервере?
Держите production-ключи в отдельном хранилище секретов и отдавайте приложению при старте или по короткой сессии. Не кладите их в репозиторий, образ контейнера, Dockerfile или файл на диске. Сам сервис пусть хранит секрет только в памяти процесса.
Как не допустить утечку ключа в логах?
Сразу закройте три места: заголовки Authorization, переменные окружения и полные тексты ошибок. Приложение не должно печатать их даже в debug-режиме, а CI не должен выводить команды с чувствительными переменными. Если нужен разбор сбоя, показывайте причину ошибки, а не сам токен.
Как безопасно хранить секреты в CI?
Храните секреты в защищенных переменных CI или во внешнем хранилище и давайте их только тем job, которым они правда нужны. У тестов, staging и production должны быть разные значения. Для деплоя лучше выдавать короткоживущий токен, чтобы утекший доступ быстро потерял силу.
Как организовать локальную разработку без секретов в репозитории?
Оставьте в репозитории только .env.example без значений и понятную инструкцию по запуску. Реальный dev-ключ разработчик получает из защищенного места и использует отдельно от production. Если есть выбор, храните рабочий токен в системном хранилище, а не открытым текстом в папке проекта.
Как ротировать ключи без простоя?
Сначала выпустите новый ключ и дайте сервисам перейти на него. Потом обновите секрет в хранилище, перезапустите все процессы, которые читают его при старте, и проверьте живой трафик, ошибки 401 и 403 и расход лимитов. Старый ключ отключайте только после этой проверки.
Что делать, если ключ уже утек?
Считайте такой ключ скомпрометированным и меняйте его сразу. Затем проверьте, где он лежал: логи, CI, чат, shell history, скриншоты и локальные файлы. После замены посмотрите на расход, подозрительные запросы и разделите доступы, если раньше один секрет использовали сразу несколько сервисов.
Что проверить перед релизом?
Перед выкладкой быстро проверьте простые вещи: у каждого сервиса свой секрет, у ключей есть лимиты, CI не печатает чувствительные данные, а приложение скрывает токены и PII в логах. Еще одна полезная привычка — заранее назначить владельца ключа и дату следующей замены, чтобы ротация не превращалась в ночной аврал.