Как сравнивать цены на LLM-модели без ошибки в расчетах
Как сравнивать цены на LLM-модели: считайте цену входа, кэша, контекста, повторов и длины ответа, а не только ставку за миллион токенов.
Почему цена за миллион токенов сбивает с толку
"Цена за миллион токенов" дает только ориентир. Она не показывает, сколько вы заплатите в реальном сценарии.
Первая ловушка - разные ставки на вход и на выход. У одной модели дешевый input, но дорогой output. У другой наоборот. Если ваш сервис отправляет короткий промпт и получает длинный ответ, итоговая сумма меняется очень сильно, даже когда на странице с тарифами модели выглядят почти одинаково.
Вторая проблема - длина контекста. Сама по себе цена за миллион токенов не говорит, сколько текста вы отправляете до начала ответа. История чата, системные инструкции, примеры, найденные фрагменты документов - все это входит в счет. В задачах с базой знаний или длинными договорами контекст часто стоит дороже самого ответа.
Кэш промптов ломает простое сравнение еще сильнее. Если одни и те же инструкции повторяются в тысячах запросов, часть входа может тарифицироваться дешевле. Тогда модель с более высокой базовой ставкой иногда дает меньший счет в конце месяца.
Есть и расход, про который команды часто забывают: повторы после ошибок. Модель не вернула JSON, превысила лимит, оборвала ответ, не прошла проверку качества - приложение отправляет запрос снова. Даже один лишний ретрай на каждые 10-20 вызовов уже заметно портит расчет, особенно при длинном контексте.
Из-за этого две модели с одинаковой ставкой могут дать разный счет на одном и том же сценарии. В службе поддержки одна модель отвечает кратко, но требует больше истории переписки. Другая читает меньше, зато пишет длиннее. Формально цена за миллион токенов совпадает. На деле одна модель окажется выгоднее для коротких диалогов, а другая - для сложных обращений.
Поэтому смотреть только на цену токена - плохая привычка. Сравнивать нужно стоимость типового запроса с учетом входа, выхода, кэша, контекста и повторов. Иначе экономия останется только в таблице.
Что входит в цену одного запроса
Один запрос почти никогда не равен простой сумме "вход + выход". В счете обычно несколько слоев текста, и каждый влияет на расход по-своему.
Первая часть - новый ввод. Это сообщение пользователя, свежие данные из формы, новый фрагмент документа, новые параметры задачи. Такие токены провайдер обычно считает по полной ставке для input.
Вторая часть - повторяющийся текст. Сюда часто попадают системный промпт, длинные инструкции, шаблон ответа, часть истории чата и общий RAG-контекст, который вы прикладываете снова и снова. Если провайдер поддерживает кэш промптов, одинаковый префикс может стоить дешевле. Но скидка действует не на весь запрос, а только на ту часть, которая действительно совпала.
Здесь ошибаются чаще всего. Команда считает только последнее сообщение пользователя и забывает про весь остальной "хвост". Но модель видит пакет целиком. Если к запросу каждый раз добавляется системный промпт на 800 токенов, история на 1200 и два фрагмента базы знаний еще на 1500, короткий вопрос пользователя уже не выглядит дешевым.
Третья часть - токены ответа. Они тоже стоят денег, и у многих моделей output дороже input. Это быстро становится заметно, когда вы просите не короткую реплику, а сводку, таблицу, письмо, SQL-запрос или JSON с большим числом полей.
Есть и четвертая часть, про которую часто вспоминают слишком поздно: повторы. В продакшене запросы перезапускают после таймаута, ошибки сети, пустого ответа или плохого формата. Если один вызов из двадцати приходится повторять, средняя цена растет примерно на 5%, даже если тарифы на токены не менялись.
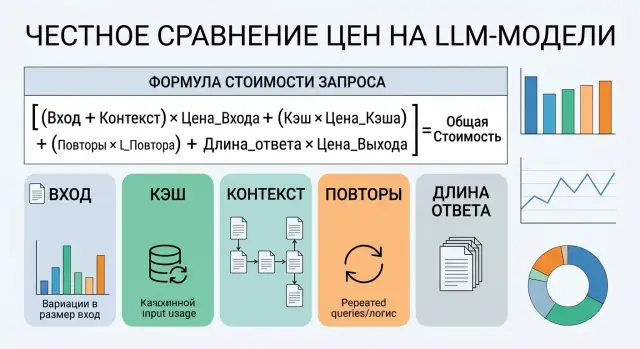
Итоговая цена запроса обычно складывается из новых входных токенов, кэшированных токенов, выходных токенов и повторных вызовов. Если не учитывать длину контекста, долю кэша и частоту ретраев, расчет почти всегда получается слишком оптимистичным.
Формула, которая показывает реальную цену
Для практики важна не абстрактная ставка, а цена одного типового запроса. Нужно учесть, что часть контекста уже лежит в кэше, ответы у моделей разной длины, а некоторые вызовы приходится повторять.
Базовая формула выглядит так:
Итог за запрос =
(новый ввод x ставка входа) +
(кэшированный контекст x ставка кэша) +
(ответ x ставка выхода)
Реальная средняя цена =
Итог за запрос x (1 + среднее число повторов)
Под "новым вводом" считайте только те токены, которые модель видит впервые. Под "кэшированным контекстом" - системный промпт, длинные инструкции, шаблоны и историю, если провайдер берет за них отдельную, более низкую ставку. "Ответ" - все выходные токены, которые модель сгенерировала, даже если часть текста потом не дошла до пользователя.
Повторы часто выпадают из расчета, хотя именно они заметно сдвигают итог. Если 10% запросов вы отправляете заново из-за таймаута, валидации JSON или второй попытки после плохого ответа, среднее число повторов равно 0.10, а множитель - 1.10. Иногда это влияет сильнее, чем разница в несколько центов за миллион токенов.
Как читать формулу на практике
Допустим, у вас один сценарий: 2000 новых токенов, 8000 токенов в кэше, 700 токенов ответа и 12% повторов. Вы подставляете ставки конкретной модели и получаете не рекламную цену, а расход на один рабочий вызов. Потом умножаете результат на дневной или месячный объем.
Чтобы сравнение было честным, держите одинаковыми условия: один и тот же набор запросов, одинаковые системные промпты, одинаковые лимиты на длину ответа и один способ учета повторов. Иначе сравнение разваливается. Одна модель может выглядеть дешевой только потому, что вы дали ей более короткий контекст или разрешили более короткий ответ.
Если команда тестирует модели через единый шлюз, например AI Router, такой расчет делать проще: можно прогнать один и тот же набор запросов через разные модели и сравнить не только тарифы провайдеров, но и фактическую цену одинаковой нагрузки.
Как посчитать это шаг за шагом
Начинать лучше не с прайса, а с логов реальных запросов. Сайт провайдера показывает ставки, но бюджет съедают длинный контекст, повторы, кэш и длина ответа.
Возьмите выгрузку хотя бы за 7 дней. Более короткий период часто врет: в него не попадают редкие, но дорогие сценарии вроде длинных диалогов, регенераций ответа и пустых ответов после ошибки.
Сначала соберите по каждому запросу три числа: новый ввод, кэшированный ввод и токены ответа. Если у вас есть retries или regenerate, отметьте их отдельным флагом. Затем посчитайте цену каждого вызова по одной схеме: новый ввод x ставка input + кэш x ставка cache + ответ x ставка output. Если модель меняет цену на длинном контексте, добавьте и это правило.
После этого разбейте запросы на простые группы, например короткие, обычные и длинные. Слишком детальная классификация редко помогает, а спорить о границах команда будет долго. Дальше добавьте долю повторов и пустых ответов. Даже если ответ пустой, вы уже заплатили за входные токены, а иногда и за повторный запуск.
Считать лучше не стоимость одного вызова, а цену 1000 запросов в каждой группе. Такой формат быстро показывает, где уходит бюджет. Дешевая модель по ставке за миллион токенов может проигрывать в живом трафике просто потому, что пишет ответы в 1,7 раза длиннее.
Таблица для этого нужна совсем простая: группа запросов, число вызовов, средний новый ввод, средний кэш, средний ответ, доля повторов, доля пустых ответов и итоговая стоимость 1000 запросов. Если трафик идет через AI Router, такие поля удобно собирать в одном месте, но сам подход работает и без него.
Пример на рабочем сценарии
Представьте чат поддержки банка. Он отвечает по базе знаний: тарифы, лимиты, блокировка карты, правила переводов. Системный промпт почти не меняется, потому что в нем зашиты тон ответа, ограничения, проверка на PII и юридические оговорки.
На каждом запросе растет не только вопрос клиента. Растут история диалога и найденные фрагменты базы. Поэтому стоимость контекста быстро становится заметнее, чем кажется по прайсу.
Для среднего диалога возьмем такие числа:
- Повторяемый системный блок: 1400 токенов. Из них 85% проходят как кэш промптов.
- История и фрагменты базы: 2800 токенов на вызов.
- Модель А: вход 0,20 доллара за 1 млн токенов, кэш 0,05, выход 1,20. Она пишет в среднем 850 токенов и в 35% случаев просит уточнение, то есть делает 1,35 вызова на диалог.
- Модель Б: вход 0,45 доллара, кэш 0,10, выход 0,80. Она отвечает короче, около 450 токенов, и уходит на второй вызов только в 10% случаев, то есть 1,10 вызова на диалог.
Если смотреть только на цену входа, модель А кажется дешевле больше чем в два раза. Но полный расчет дает другую картину.
У модели А на один диалог выходит примерно 4060 некэшируемых входных токенов, 1600 кэшируемых и 1150 выходных. Это около 0,00227 доллара за диалог.
У модели Б вход дороже, зато она тратит меньше выходных токенов и реже требует повтор. В среднем получается около 3310 некэшируемых входных токенов, 1310 кэшируемых и 495 выходных. Это примерно 0,00202 доллара за диалог.
На одном чате разница почти не заметна. На 100 тысяч диалогов в месяц она уже видна: около 227 долларов против 202. А если модель А еще и чаще отправляет оператора на ручную проверку, разрыв станет больше.
Этот пример хорошо показывает простую вещь: сначала нужно считать повторяемый системный блок, потом стоимость контекста, потом длину ответа и только после этого добавлять вероятность второго вызова.
Где расчеты ломаются чаще всего
Обычно все начинается со слишком простой метрики. Команда берет цену за миллион входных токенов, заносит ее в таблицу и выбирает самую дешевую модель. Потом приходит счет, и выясняется, что деньги съел не вход, а выход.
Так часто бывает в задачах, где модель пишет много: отвечает клиенту, готовит письмо, разбирает документ. Если у одной модели дешевый вход, но она в среднем выдает ответ в два раза длиннее, сравнение только по input не дает почти никакой пользы.
Вторая частая ошибка - забытый контекст. В цену запроса входят не только слова пользователя, но и системный промпт, история диалога, шаблоны, схемы инструментов и служебные инструкции. Если системный промпт весит 1200 токенов и вы отправляете его при каждом вызове, он очень быстро превращается в заметную статью расходов.
Среднее значение тоже обманывает. Допустим, в 8 запросах из 10 модель отвечает на 150 токенов, а в 2 случаях уходит на 2500. На бумаге средний ответ выглядит нормально, но бюджет ломают именно длинные хвосты. Поэтому полезно смотреть не только на среднее, но и на верхний диапазон.
Часто пропускают и кэш промптов. Если у вас повторяется большая часть префикса, например один и тот же системный блок, каталог товаров или шаблон проверки, реальная стоимость входа падает. Без учета кэша модель может казаться дорогой, хотя на живом трафике она выйдет дешевле.
Есть и совсем грубая ошибка: команды подменяют сценарий. Одну модель тестируют на коротких вопросах, другую - на длинных документах, а потом сравнивают цифры как будто это один и тот же поток. После такого любой вывод будет случайным.
Чтобы расчет не развалился, достаточно держать одинаковыми сценарий, системный промпт, объем истории, лимит на длину ответа и правила учета кэша и повторов. Остальное уже вторично.
Когда дорогая модель обходится дешевле
Низкая ставка за вход и выход не гарантирует низкий счет в конце месяца. Иногда модель с более высокой ценой за миллион токенов тратит меньше денег на ту же работу, потому что отвечает короче, реже ошибается и не требует лишний ход.
Самый частый случай - длина ответа. Одна модель пишет 800 токенов там, где другая укладывается в 200 и не теряет смысл. Если у вас тысячи запросов в день, разница в цене выхода быстро съедает выгоду от "дешевого" тарифа.
Есть и более неприятный сценарий - повторный вызов. Если модель ломает JSON даже в 5-10% случаев, вы платите не только за еще один ответ. Вы снова отправляете инструкцию, историю, примеры и часто большой контекст. Один лишний ретрай иногда стоит дороже, чем разница в тарифе между двумя моделями на десятках успешных запросов.
То же происходит, когда модель часто переспрашивает. Формально она может быть дешевой, но каждый уточняющий вопрос растягивает диалог. В службе поддержки, разборе документов и внутренних copilot-сценариях это бьет по бюджету почти незаметно: растет вход, растет выход, а кэш помогает не всегда.
Отдельная история - длинный контекст. Более сильная модель часто лучше держит большой документ, находит нужный абзац и не теряет ограничения из системного промпта. Более дешевая может пропустить важный фрагмент, и команда начинает компенсировать это длинными инструкциями, повтором правил или вторым прогоном. На бумаге тариф ниже. По факту расход выше.
Небольшой пример: модель A вдвое дешевле по прайсу, но в среднем пишет на 500 токенов больше, в 7% случаев требует повторный вызов из-за сломанного JSON, чаще просит уточнение и хуже работает с длинным контекстом. В таком сценарии модель B с более высоким тарифом вполне может дать меньшую цену за завершенную задачу. Считать нужно не цену токена как таковую, а цену полезного результата без лишних повторов.
Быстрая проверка перед выбором
Перед сравнением моделей полезно собрать один короткий набор контрольных вопросов.
Запишите три ставки отдельно: за входные токены, за токены из кэша и за выходные токены. Затем посчитайте полный контекст: system prompt, историю диалога, найденные документы и служебные инструкции. После этого добавьте не только среднюю длину ответа, но и верхнюю границу, чтобы длинные ответы не потерялись в среднем значении. В конце обязательно внесите долю повторных вызовов: регенерации, ретраи, повторные вопросы и промахи по кэшу.
С кэшем важно не рисовать идеальный сценарий. Если системный промпт и часть истории повторяются, вход действительно стоит дешевле нового текста. Но кэш редко покрывает 100% одинаковых токенов. Лучше сразу задать реалистичную долю, например 60%, чем строить расчет на слишком красивой гипотезе.
И еще одно простое правило: сравнивайте модели на одном и том же наборе запросов. Не на двух удачных примерах, не на коротком демо, а на одинаковой корзине реальных задач. Только тогда разница в цене за миллион токенов перестает шуметь, а расчет начинает показывать, что вы действительно заплатите.
Что делать дальше
После всех расчетов не выбирайте модель по одной цифре в прайсе. Возьмите реальные логи хотя бы за неделю и соберите базу для сравнения: входные токены, выходные токены, попадания в кэш, длину контекста и повторы запросов. Без этих данных цена за миллион токенов почти всегда рисует слишком красивую картину.
Полезно сразу разделить трафик на три режима: обычный, длинный и проблемный. Среднее значение часто скрывает лишние расходы. На обычных запросах модель может выглядеть дешевой, а на длинных документах или ретраях счет вырастет совсем по-другому.
Рядом с ценой держите еще два числа: качество и задержку. Иначе сравнение снова собьется. Модель может стоить на 10% меньше, но отвечать на 2 секунды дольше или чаще давать результат, который команда потом правит вручную. Тогда экономия на токенах просто исчезает.
Дальше нужен короткий пилот на 2-3 моделях. Возьмите один и тот же набор реальных задач, например классификацию обращений, суммаризацию документа и ответ по базе знаний. Прогоните этот набор через кандидатов, а потом сверяйте прогноз из формулы с фактическим счетом. Уже через несколько сотен запросов обычно видно, где расчеты были слишком оптимистичны.
Если команда тестирует много моделей через один OpenAI-совместимый endpoint, AI Router помогает не менять SDK, код и промпты при переключении между провайдерами. За счет этого проще держать один формат логов и одну схему расчета для всех прогонов.
Через 7-10 дней такой проверки у вас будет не абстрактная цена за миллион токенов, а понятная цена рабочего запроса в вашем продукте. На этой цифре уже можно принимать решение спокойно и без самообмана.
Часто задаваемые вопросы
Что сравнивать у моделей, кроме цены за миллион токенов?
Смотрите на цену типового запроса, а не на ставку за миллион токенов. Сложите новый ввод, повторяющийся контекст с учетом кэша, длину ответа и долю повторных вызовов. Тогда вы увидите расход в живом сценарии, а не красивую цифру из прайса.
Какая формула показывает реальную цену одного запроса?
Возьмите такую схему: (новый ввод × ставка input) + (кэшируемый контекст × ставка cache) + (ответ × ставка output). Потом умножьте результат на (1 + среднее число повторов), если часть запросов уходит на ретрай или регенерацию.
Что считать новым вводом, а что кэшированным контекстом?
К новому вводу относите текст, который модель видит впервые: сообщение пользователя, свежие поля формы, новый кусок документа. В кэш обычно попадают системный промпт, шаблоны, часть истории и общий префикс, который вы отправляете снова и снова.
Почему длинный контекст так сильно меняет итоговый счет?
Контекст быстро растет: системные инструкции, история чата, фрагменты базы знаний и служебные подсказки идут в счет вместе с вопросом пользователя. В задачах с RAG или длинными документами контекст часто стоит дороже самого ответа.
Как учитывать ретраи, регенерации и пустые ответы?
Добавьте в расчет среднюю долю повторов на запрос или число вызовов на один завершенный сценарий. Если 10% запросов вы отправляете заново, умножайте цену на 1,10, потому что вы снова платите и за вход, и за ответ.
Когда модель с более высоким тарифом обходится дешевле?
Так бывает, когда более дорогая модель отвечает короче, реже ломает JSON и не тянет диалог на второй ход. В итоге она тратит меньше выходных токенов и реже заставляет вас повторно слать длинный контекст.
Хватит ли среднего числа токенов для расчета?
Нет, одного среднего мало. Проверьте еще верхний диапазон по длине ответа и контекста, иначе редкие длинные запросы спрячут лишние расходы и сломают прогноз по бюджету.
За какой период лучше брать логи для оценки?
Берите логи хотя бы за 7 дней. Такой период обычно захватывает обычные запросы, длинные диалоги, ошибки формата и другие дорогие случаи, которые короткое демо просто не покажет.
Как честно сравнить две модели между собой?
Прогоните один и тот же набор реальных задач через обе модели и держите одинаковыми системный промпт, историю, лимит ответа и правила учета кэша. Если вы меняете хоть одно из этих условий, сравнение теряет смысл.
Поможет ли единый OpenAI-совместимый шлюз в сравнении моделей?
Да, такой шлюз упрощает тесты, потому что вы не меняете SDK, код и промпты при переключении между провайдерами. Например, через AI Router можно прогнать одинаковую нагрузку через разные модели и собрать логи в одном формате для расчета цены.