LoRA-адаптеры одной модели: хранение и переключение
Разбираем, как хранить LoRA-адаптеры одной модели, быстро выбирать нужный вариант по запросу и не поднимать отдельный сервер под каждый сценарий.
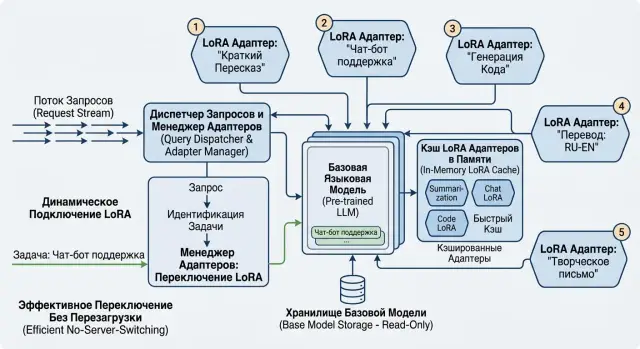
Где начинается проблема
Проблема обычно начинается не с модели, а с роста числа задач. Команда берет одну базовую модель, проверяет ее на одном сценарии и быстро получает новые запросы: отдельный тон для поддержки, свой стиль для юристов, другой вариант для скоринга, еще один для внутреннего поиска. Так и появляются LoRA-адаптеры одной модели. Сначала это и правда удобно.
Первые два или три адаптера редко создают сложности. Потом схема начинает расползаться. У каждого варианта появляется свой конфиг, свои имена файлов, свои права доступа, а иногда и свой способ запуска. Через месяц уже непонятно, какой адаптер нужен для продакшена, какой остался после эксперимента, а какой вообще нельзя показывать другой команде.
Многие решают это самым прямым способом: поднимают отдельный сервер под каждый вариант. На бумаге все выглядит просто. На деле GPU простаивают, бюджет уходит на копии одной и той же базовой модели, а поддержка быстро превращается в рутину. Если у вас шесть адаптеров для одной модели, шесть отдельных инстансов редко оправданы.
Путаница быстро проявляется в мелочах. Один и тот же адаптер лежит в нескольких папках под разными именами. Версии в тесте и проде не совпадают. Права доступа живут отдельно от самих артефактов. Никто не знает, что уже можно удалить, а что еще используется.
Потом приходит вторая проблема - задержка. Если система грузит адаптеры без порядка, каждый новый запрос тянет лишнюю работу: чтение с диска, перенос в память, прогрев, сброс предыдущего состояния. Пользователь видит не аккуратную маршрутизацию, а скачки по времени ответа. Один запрос проходит быстро, другой внезапно ждет еще 2-3 секунды.
Это особенно заметно там, где один сервис обслуживает много внутренних команд. В банке или ритейле одна и та же базовая модель может и классифицировать обращения, и размечать документы, и делать короткие резюме для операторов. Если не навести порядок в хранении LoRA с самого начала, инфраструктура начнет тормозить раньше, чем вырастет модельный стек.
Когда хватает одной базовой модели
Одна базовая модель часто закрывает сразу несколько сценариев. Это работает в случаях, когда вам нужен не новый "мозг", а настройка поверх уже сильной базы. LoRA меняет тон, формат ответа, словарь домена или шаблон вывода, но не превращает модель в совсем другой инструмент.
Полезно сразу отделить новый навык от нового стиля. Если один адаптер делает ответы короче, другой добавляет юридические формулировки, а третий держит формат JSON без лишнего текста, одной базы обычно хватает. Если же новый вариант решает задачу, с которой база без него почти не справляется, границу стоит проверить внимательнее.
Проще всего это видно на небольшом наборе тестов. Возьмите 20-30 запросов и сравните базу с каждым адаптером по точности, формату и стабильности. Если база уже понимает задачу, а LoRA только подправляет поведение, отдельный сервер под каждый вариант чаще всего не нужен.
Отдельный инстанс появляется не из-за самого факта, что у вас есть LoRA, а из-за нагрузки и веса адаптера. Тяжелые и постоянно занятые варианты быстро съедают память и мешают остальным. Если один адаптер нужен почти в каждом запросе, а другой вызывают раз в час, обслуживать их одинаково нет смысла.
Обычно одной базы хватает в таких случаях:
- все варианты решают одну и ту же задачу
- адаптеры меняют подачу, формат или терминологию
- база и без адаптера дает приемлемый результат
- редкие адаптеры можно подгружать по мере надобности
Смотрите не только на число запросов, но и на память. База занимает основную часть VRAM, а адаптеры добавляют свой слой расходов в RAM, VRAM или дисковый кэш. Иногда запросов немного, но набор адаптеров большой, и первой ломается именно память, а не QPS.
Ориентир здесь простой: если одна база уверенно решает общий класс задач, а LoRA только доводят поведение до нужной формы, разделять все по разным серверам рано. Гораздо разумнее держать одну базу, аккуратный кэш адаптеров и вынести отдельно только самые тяжелые или самые горячие варианты.
Как хранить адаптеры без хаоса
Беспорядок начинается не в GPU, а в папках. Если команда держит десятки LoRA-адаптеров одной модели без общего правила, через месяц уже трудно понять, какой файл нужен для продакшена, а какой собрали для теста на прошлой неделе.
Самое простое правило - дать каждому адаптеру короткое имя и номер версии. Имя должно отвечать на вопрос, для чего он нужен, а не кто его когда-то обучал. Например, support-ru-v3 намного понятнее, чем final_new_last_ok2.
Одного имени мало. Рядом с каждым адаптером лучше хранить метаданные в отдельном файле и не полагаться на память команды или подписи в чате. Обычно хватает нескольких полей: базовая модель, дата сборки, владелец или команда, задача, язык и ограничения.
Ограничения полезны чаще, чем кажется. Один адаптер пишет ответы для поддержки на русском, другой годится только для короткой классификации, третий нельзя использовать на юридических текстах без ручной проверки. Если это не записано рядом с файлами, команды начинают путать сценарии.
Хорошо работает и простая структура каталогов. Не смешивайте staging и production в одном месте. Иначе тестовая сборка однажды попадет в боевой трафик просто потому, что названия похожи.
lora/
staging/
support-ru-v3/
adapter.safetensors
meta.json
production/
support-ru-v2/
adapter.safetensors
meta.json
В meta.json полезно хранить не только служебные поля, но и короткое описание задачи обычным языком. Пара строк часто экономит часы разбирательств. Например: "Ответы для первой линии поддержки, русский язык, не использовать для финансовых советов".
Старые сборки тоже нужно чистить по правилу, а не по настроению. Часто хватает такой схемы: в production держать текущую и предыдущую версии, в staging - последние 3-5 сборок, архив удалять по сроку, например раз в 30 или 60 дней. Если версия привязана к важному релизу, пометьте ее отдельно и не трогайте.
У такого порядка есть приятный побочный эффект. Когда приходит запрос на переключение адаптера по задаче, серверу не нужно гадать. Он видит короткое имя, версию, среду и метаданные, после чего берет нужный файл без ручной проверки и без отдельного сервера под каждый кейс.
Как переключать адаптер по запросу
Запрос должен сам говорить, какой вариант модели нужен. Если сервер выбирает адаптер по скрытым правилам, команда быстро теряет контроль: сложно повторить ответ, найти сбой и понять, почему один клиент получил не тот стиль или не ту предметную настройку.
Когда вы держите несколько LoRA-адаптеров одной модели, лучше принимать явный adapter_id. Рядом с ним часто нужны еще три вещи: имя базовой модели, версия адаптера или стабильный alias и режим на случай ошибки - вернуть ошибку или отправить запрос по запасному маршруту. Если адаптеры разделены по командам, полезен и идентификатор клиента или сервиса.
Дальше сервер должен проверить совместимость до загрузки. Адаптер, собранный для одного базового чекпойнта, нельзя бездумно цеплять к другому. Сверяйте хотя бы точное имя базовой модели, ее версию и формат адаптера. Если у вас Qwen 3 8B, не стоит подключать к нему адаптер от другой размерности только потому, что названия похожи.
После проверки ищите адаптер по простому порядку: сначала в памяти, потом на локальном диске, и только потом во внешнем хранилище. Такой путь обычно дает самую низкую задержку. Популярные адаптеры имеет смысл держать прогретыми в RAM, а редкие подгружать по мере запросов. Иначе сервер начнет тратить время не на генерацию, а на чтение файлов.
Когда сервер нашел адаптер, он должен загрузить нужную версию и записать выбор в логи. Лог без версии почти бесполезен. Через неделю никто не вспомнит, какой именно вариант отвечал пользователю. Полезно сохранять adapter_id, версию, базовую модель, источник загрузки, время подгрузки и request id.
Если адаптер не найден, не молчите. Есть два нормальных варианта: вернуть понятную ошибку или отправить запрос по запасному маршруту, который вы заранее описали в правилах. Тихая подмена одного адаптера другим почти всегда выходит боком.
Простой пример: у команды есть один базовый LLM для поддержки, а поверх него два адаптера - для банка и для ритейла. Если запрос банка случайно уйдет в ритейл-адаптер, ответ может быть вежливым, но неверным по терминам и внутренним правилам. Поэтому переключение должно быть строгим, а ошибка - читаемой. Если сегодня у вас два адаптера, проектируйте схему так, будто через месяц их станет пятьдесят.
Как держать задержку под контролем
Задержка в схеме с LoRA чаще растет не из-за самой генерации. Обычно тормозит загрузка адаптера: его нужно прочитать с диска или из хранилища, положить в память и привязать к базовой модели. Если этот шаг занимает 400-800 мс, пользователь все равно видит медленный ответ, даже когда сама модель работает быстро.
Самый простой способ убрать резкие скачки - держать в памяти те адаптеры, которые приходят чаще всего. Не все подряд, а только "горячий" набор по реальному трафику. На практике 3-5 адаптеров часто закрывают большую часть запросов, и этого уже хватает, чтобы заметно сгладить p95.
Не давайте системе грузить слишком много адаптеров одновременно. Когда сервер получает пачку запросов к разным редким вариантам, он начинает дергать память, очередь растет, а GPU тратит время не на токены, а на постоянные переключения. Обычно лучше разрешить 1-2 одновременные загрузки на один инстанс и поставить остальные запросы в короткую очередь.
Что смотреть в метриках
Смотрите отдельно на время загрузки адаптера и на время генерации. Это две разные проблемы, и лечатся они по-разному. Если генерация держится на одном уровне, а общая задержка плавает, почти всегда виноваты холодные старты, промахи кэша или слишком частые вытеснения.
Для начала достаточно четырех метрик:
- среднее и p95 для загрузки адаптера
- среднее и p95 для генерации
- доля запросов, пришедших в кэш
- число вытеснений за час
Если видеть только общее время ответа, причина быстро теряется.
Перед пиковым трафиком популярные варианты лучше прогревать. Допустим, у команды поддержки утром с 9:00 до 11:00 почти всегда идут запросы к одному и тому же адаптеру для классификации обращений. Загрузите его заранее в 8:55, и первые пользователи не заплатят за холодный старт.
У кэша должен быть жесткий лимит по памяти. Без лимита сервер рано или поздно упрется в OOM, а с слишком маленьким лимитом начнется постоянная перезагрузка одних и тех же адаптеров. Сложная логика тут редко нужна. Обычный LRU-кэш часто достаточно хорош, если вы еще отдельно закрепите 1-2 самых нужных адаптера и не дадите их вытеснять.
Следите не только за размером кэша, но и за тем, кого он выталкивает. Если один и тот же адаптер загружается по 20 раз в день, это уже не редкий случай, а ошибка настройки. В таком режиме сервер тратит ресурсы впустую, а задержка становится непредсказуемой.
Если вы уже сводите внешние модели и свои инстансы в общий контур, удобнее держать одну точку входа и общие правила маршрутизации. В этом месте AI Router на airouter.kz может быть практичным вариантом: один OpenAI-совместимый эндпоинт, общие аудит-логи, rate limits и единые правила доступа без смены SDK и существующего кода.
Простой пример для одной команды
У команды поддержки есть один сервис с одной базовой моделью. Поверх нее лежат три LoRA: для обычных обращений, для финансовых вопросов и для внутреннего help desk. Случай простой, но на нем хорошо видно, зачем нужны адаптеры одной модели. Команда не поднимает три одинаковых сервера под три сценария. Она держит одну базовую модель в памяти и меняет только адаптер.
Маршрут запроса смотрит на поле channel или department. Если запрос пришел из клиентского чата, сервис чаще берет адаптер для массовой поддержки. Если тикет помечен как billing, включается финансовый вариант. Если обращение идет от сотрудников через внутренний портал, подключается help desk LoRA. Логика выбора короткая и понятная, без лишней оркестрации.
На практике поток выглядит так: запрос приходит в общий API, сервис читает метаданные, находит нужный адаптер и подключает его к уже загруженной базе. Через секунду следующий запрос может пойти с другим адаптером, но база останется той же. За счет этого сервер для LoRA не разрастается в парк почти одинаковых машин, где каждая занята своим редким сценарием.
Ночью редкий вариант можно выгрузить из памяти. Допустим, help desk почти не нужен после полуночи. Сервис оставляет в RAM только два частых адаптера, а третий убирает в хранилище. Если утром приходит новый внутренний тикет, процесс снова поднимает этот адаптер, добавляет его в кэш и пишет событие в лог: какой адаптер загрузили, сколько заняла операция, кто вызвал прогрев.
Такой режим обычно дешевле и спокойнее в поддержке. Команда следит не за тремя отдельными окружениями, а за одной базой, правилами маршрута и тем, как устроено хранение адаптеров LoRA. Если трафик вырастет, она сначала расширит кэш и прогрев, а не станет копировать весь стек для каждого отдела.
Ошибки, которые быстро ломают схему
Первая частая поломка проста: команда обучила адаптер на одной ревизии базовой модели, а в продакшене подключила его к другой. На бумаге это все еще "та же" модель. На деле меняются веса, поведение, а иногда и токенизация, и ответы начинают плыть. Ошибка выглядит случайной, поэтому ее долго ищут.
С LoRA-адаптерами лучше жить жестко: каждый адаптер должен знать точный ID базы, ее ревизию и параметры запуска. Если этого нет, вы не переключаете адаптеры по запросу, а играете в лотерею.
Не меньше путаницы создают названия вроде final, new2 или prod_fix. Через месяц никто не помнит, что внутри. Один инженер грузит final, другой уверен, что рабочий вариант лежит в final_new, а ночью откатывают вообще не ту версию.
Нормальное имя скучное, зато полезное: продукт, задача, дата, ревизия базы. Например, support-kz-2025-04-12-base-r17. Красоты в этом мало, зато часы на разбор сбоев такая схема экономит отлично.
Еще одна частая ошибка - дать приложению возможность вызвать любой адаптер по строке из запроса. На старте это удобно, но через неделю становится опасно. Один сервис случайно дергает тестовый адаптер, другой получает модель для чужого домена, третий открывает доступ к черновику, который никто не проверял.
Лучше держать явный список разрешенных адаптеров. Приложение выбирает не произвольное имя, а понятный режим: "поддержка", "суммаризация", "анализ жалоб". Уже сервер маппит этот режим на конкретный адаптер и его версию.
Многие считают среднюю задержку и забывают про холодный старт. А он бьет больнее всего. Если адаптер лежит в объектном хранилище или на медленном диске, первый запрос может ждать секунды, пока веса попадут в память и на GPU.
SLA без учета холодного старта почти всегда рисует слишком красивую картину. Считайте отдельно теплый и холодный путь. Популярные адаптеры прогревайте заранее, а редкие держите в более честном классе сервиса.
Плохая идея и хранить только сами веса без контекста. Тогда через два месяца уже неясно:
- на какой базе обучали адаптер
- какой датасет или срез данных использовали
- проходил ли он smoke test
- какие метрики он показал
- кто одобрил выкладку
Без метаданных и тестов любой каталог адаптеров быстро превращается в склад файлов. У каждого адаптера должен быть короткий паспорт: ревизия базы, хеш, формат, дата сборки, автор, статус, минимальный набор тестов и результат проверки.
Практичный подход тут очень простой: не загружать адаптер в реестр, пока он не прошел маленький тестовый набор. Даже 20-30 запросов уже ловят грубые ошибки. Это особенно полезно, когда весь трафик идет через одну точку входа: сам шлюз упрощает маршрутизацию, но не спасает от беспорядка в версиях.
Если схема начинает шататься, причина обычно не в GPU и не в сети. Чаще всего проблема в дисциплине версий, имен и доступа.
Короткая проверка перед запуском
Перед стартом полезно проверить не железо, а порядок вокруг адаптеров. Большая часть сбоев появляется не из-за самой LoRA, а из-за путаницы в именах, версиях и правилах загрузки.
Если у адаптера нет владельца и версии, через месяц никто не поймет, что именно работает в проде. Один и тот же файл быстро окажется в трех папках с именами вроде final, new и final2. Рабочая схема проще: у каждого адаптера есть стабильный adapter_id, номер версии и команда или сервис, который за него отвечает.
API тоже не должен угадывать. Клиент явно передает adapter_id в каждом запросе. Иначе сервер начнет выбирать похожий адаптер по умолчанию, а это почти всегда плохая идея. Если адаптер не указан, лучше сразу вернуть понятную ошибку или отправить запрос по заранее заданному запасному правилу.
Перед запуском обычно хватает пяти проверок:
- у каждого адаптера есть владелец, версия и короткое описание назначения
- API принимает явный
adapter_id, а не имя файла или неявный флаг - логи пишут базовую модель,
adapter_id, версию и время загрузки - мониторинг показывает hit rate кэша, число холодных стартов и среднюю задержку загрузки
- есть запасной путь, если адаптер не загрузился или оказался битым
Логи стоит проверить руками на реальном запросе. После одного вызова вы должны увидеть, какая базовая модель ответила, какой адаптер подключился и сколько миллисекунд заняла загрузка. Без этого сложно понять, тормозит сеть, диск, кэш или сам инференс.
С запасным путем лучше определиться заранее, а не в момент сбоя. Для внутреннего черновика можно временно уйти на базовую модель. Для банковского или медицинского сценария чаще безопаснее вернуть контролируемую ошибку, чем молча сменить поведение модели.
Если такие вызовы идут через общий API-шлюз, правило не меняется: маршрут должен быть явным, а состояние - наблюдаемым. Тогда одна базовая модель с набором LoRA-адаптеров не превращается в набор случайных конфигураций.
Что сделать дальше
Не расширяйте схему сразу на десятки адаптеров. Сначала возьмите 2-3 самых частых кейса и проверьте их на живой нагрузке, а не только на локальном тесте. Так быстрее видно, где у вас слабое место: в памяти, в загрузке весов или в маршрутизации запроса.
Для первого прогона лучше выбрать разные профили. Например, один LoRA для коротких классификаций, второй для длинных ответов, третий для узкой доменной задачи. Такой набор быстрее покажет, как адаптеры одной модели ведут себя при разной длине контекста и разной частоте вызовов.
Дальше смотрите не только на качество ответа. Если адаптер дает хороший результат, но грузится 2-3 секунды на холодном старте, в продакшене это быстро станет проблемой. То же самое с памятью: один удачный тест еще не значит, что сервер выдержит вечерний пик.
Проверьте четыре вещи:
- сколько памяти съедает базовая модель вместе с каждым адаптером
- сколько длится холодный старт и догрузка адаптера в кэш
- как меняется p95 задержки при частом переключении
- во сколько обходится один запрос с учетом GPU-времени и простоя
Эти цифры полезнее любой красивой схемы. После них уже понятно, сколько адаптеров держать в горячем кэше, какие выгружать первыми и где проходит предел нагрузки на один сервер для LoRA.
Еще один шаг, который часто зря откладывают: сразу ввести правило именования и версий. Простая запись вроде base-model / task / locale / v3 экономит много часов, когда каталог вырастает с 5 адаптеров до 50. Там же стоит задать порядок выпуска: кто публикует новую версию, как она проходит проверку, кто и когда переводит трафик, как откатывать назад.
Если у вас в одном контуре уже смешаны внешние модели, свои GPU-инстансы и несколько LoRA поверх open-weight моделей, заранее решите, где будет жить логика выбора маршрута. Держать ее внутри каждого сервиса можно, но такая схема быстро расползается. В этом месте единый шлюз действительно упрощает жизнь, особенно если нужно свести провайдеров, свои инстансы, аудит и правила доступа в одну точку.
Хороший следующий шаг очень простой: возьмите один сервер, одну базовую модель и 2-3 адаптера, затем дайте на них реальный поток запросов хотя бы на день. После этого у вас будут не догадки, а числа, по которым уже можно строить нормальную схему.
Часто задаваемые вопросы
Когда одной базовой модели действительно хватает?
Да, если база уже решает общий класс задач, а LoRA только меняет тон, формат ответа, язык или доменную лексику. В таком случае держите одну базовую модель в памяти и переключайте адаптер по запросу.
В каком случае лучше вынести LoRA в отдельный инстанс?
Отдельный инстанс нужен, когда адаптер очень тяжелый, получает почти постоянный трафик или заметно мешает другим запросам по памяти и задержке. Если редкий адаптер вызывают раз в час, обычно проще подгружать его по мере надобности, а не держать целый сервер под него.
Как лучше называть LoRA-адаптеры, чтобы не запутаться?
Начните с короткого и понятного имени, которое описывает задачу, а не историю файла. Формат вроде support-ru-v3 или billing-kz-v2 работает лучше, чем final_new_last.
Отдельно разделите staging и production. Так тестовая сборка не попадет в боевой трафик из-за похожего названия.
Что обязательно хранить рядом с адаптером кроме самих весов?
В meta.json держите минимум, без которого команда не сможет безопасно использовать адаптер. Обычно хватает имени базовой модели, ее ревизии, даты сборки, владельца, задачи, языка, ограничений и статуса.
Полезно добавить короткое описание обычным языком. Одна фраза вроде «для первой линии поддержки, русский язык, не использовать для финансовых советов» сильно упрощает жизнь.
Как правильно выбирать адаптер в API?
Лучше передавать явный adapter_id в каждом запросе. Рядом можно передать имя базовой модели, версию или стабильный alias, если у вас несколько веток одного адаптера.
Не давайте серверу угадывать по скрытым правилам. Явный выбор проще отладить, повторить и проверить по логам.
Что делать, если нужный адаптер не загрузился или его нет?
Если адаптер не найден, верните понятную ошибку или отправьте запрос по заранее описанному запасному правилу. Не подменяйте один адаптер другим молча.
Тихая замена быстро дает неверные ответы по терминам, формату или внутренним правилам. Потом такой сбой тяжело найти.
Как уменьшить задержку при частом переключении LoRA?
Быстрее всего помогает кэш горячих адаптеров. Держите в памяти те варианты, которые приходят чаще всего, а редкие подгружайте по запросу.
Еще ограничьте число одновременных загрузок на инстанс. Иначе сервер начнет тратить время на постоянные переключения вместо генерации.
Какие метрики реально нужны для такой схемы?
Смотрите отдельно на время загрузки адаптера и на время генерации. Если общая задержка плавает, а генерация стабильна, проблема обычно в холодных стартах, промахах кэша или вытеснениях.
На старте хватит hit rate кэша, среднего и p95 времени загрузки, среднего и p95 генерации, а также числа вытеснений за час.
Как не потерять контроль над версиями и совместимостью?
Жестко связывайте каждый адаптер с точной базовой моделью и ее ревизией. Не подключайте LoRA к похожему чекпойнту только потому, что названия совпадают.
Храните текущую и предыдущую версии в production, несколько последних в staging, а старые сборки удаляйте по понятному сроку. Тогда откат занимает минуты, а не полдня.
С чего начать, если у нас пока только несколько LoRA?
Для старта возьмите один сервер, одну базовую модель и 2–3 адаптера с разным профилем нагрузки. Пропустите через них живой поток хотя бы день и посмотрите на память, холодный старт, p95 и стоимость запроса.
После этого уже видно, кого держать в горячем кэше, кого выгружать первым и нужен ли вам отдельный инстанс для самого занятого варианта.