Идемпотентность запросов к LLM без двойных списаний
Идемпотентность запросов к LLM помогает избежать двойных списаний, повторов ответа и лишних ретраев при таймаутах, сбоях сети и повторных кликах.
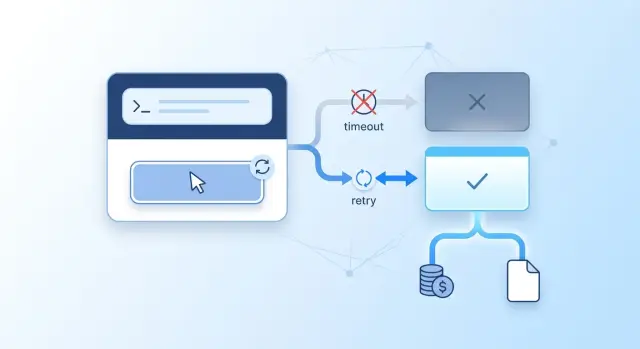
Что ломается без идемпотентности
Без идемпотентности один и тот же запрос легко превращается в две операции. Для этого не нужен редкий баг. Достаточно двух кликов по кнопке "Отправить", автоматического ретрая после таймаута или обрыва сети на последних чанках стрима.
Пользователь видит простую картину: чат завис, он нажал еще раз и получил два почти одинаковых ответа. Для него это мелкий сбой интерфейса. Для команды это уже деньги, логи и спорные списания. Каждый повтор может уйти в модель как новый вызов.
Самый неприятный случай возникает при таймауте. Клиент решает, что запрос не прошел, хотя провайдер уже принял его и начал генерацию. Если приложение без проверки отправляет тот же prompt повторно, модель обрабатывает его еще раз. Один вопрос пользователя превращается в две генерации, а биллинг считает две операции.
На небольшом трафике это раздражает. На большом трафике это видно в счете уже через несколько дней. Еще хуже, когда клиент уверен, что сделал одно действие, а система показывает два списания.
Логи в такой ситуации формально выглядят правильно, но пользы от них мало. Первый запрос, ретрай и повторный клик похожи друг на друга: тот же пользователь, тот же текст, почти то же время. Если у них нет общего идентификатора операции, поддержка не понимает, какой вызов был первым, какой дошел до провайдера, а какой создало приложение повторно.
В чате последствия видны сразу. Повторный ответ попадает в историю диалога, ломает контекст и сбивает пользователя. Если поверх LLM есть действие вроде создания заявки, суммаризации звонка или отправки письма, дубликат затрагивает уже не только текст, но и бизнес-логику.
Простой пример: сотрудник ждет краткое резюме разговора с клиентом. Экран думает 10 секунд, он нажимает кнопку еще раз. Первая генерация уже идет, вторая стартует следом. В итоге система сохраняет два похожих резюме, в логах видно несколько событий вместо одного, а команда потом спорит, где был настоящий сбой.
Именно поэтому идемпотентность нужна не для "красивой архитектуры". Она нужна, чтобы действие, которое пользователь считает одним, и оставалось одним для API, биллинга и логов.
Откуда берутся повторы и лишние списания
Проблема обычно начинается не с модели, а с сети и клиентской логики вокруг нее. Пользователь нажал "Отправить", интерфейс подвис на пару секунд, и он нажал еще раз. Для человека это одна попытка. Для системы - уже два одинаковых запроса.
SDK тоже часто повторяют вызов сами. После 429, 500 или обрыва сети библиотека может сделать ретрай без участия разработчика. Если первый запрос успел дойти до провайдера, а потерялся только ответ, второй вызов выглядит как новый. Так и появляются двойные списания, хотя пользователь ничего нового не просил.
Еще один источник дублей - прокси или API-шлюз с коротким таймаутом. Он ждет ответ 10-15 секунд, считает запрос зависшим и отправляет его заново. Но модель могла все это время спокойно считать первый запрос. Когда обе попытки доходят до конца, команда получает два результата и платит дважды.
Со стримингом путаницы еще больше. Модель уже сгенерировала почти весь ответ, клиент получил часть токенов, потом соединение оборвалось. Пользователь видит обрезанный текст и жмет "Повторить". Система отправляет тот же prompt снова, хотя вычисление уже произошло.
Типичный сценарий выглядит так:
- браузер отправил сообщение в чат;
- модель закончила ответ;
- стрим оборвался на последних чанках;
- страница обновилась или пользователь нажал повторно;
- приложение создало еще один такой же запрос.
После этого в чате появляются повторы, а в биллинге - лишние расходы. И это не экзотика. Чем больше слоев между приложением и моделью, тем выше шанс, что одна бизнес-операция превратится в две или три технические попытки.
Что считать одной и той же операцией
Для идемпотентности важен не сам факт повтора, а смысл действия. Если система видит несколько попыток как одну операцию, она должна дать один итог: одно списание, один сохраненный результат и понятный след в логах.
У LLM это удобно определять по контексту, который влияет на ответ и цену. Обычно достаточно проверить:
- пользователя, проект или API-ключ;
- модель;
- параметры генерации;
- тело запроса, включая сообщения и системный prompt;
- подключенные инструменты, если они есть.
Если хотя бы один из этих элементов изменился, это уже новая операция. Даже небольшая правка меняет смысл. Пользователь добавил строку в prompt, сменил модель, поднял max_tokens или temperature - значит, нужен новый ключ идемпотентности.
Это правило кажется строгим, но иначе быстро начинаются споры в биллинге. Два запроса могут выглядеть почти одинаково, но один идет на дешевую модель, а второй на более дорогую. Склеивать их нельзя. То же самое с разными пользователями внутри одной компании: текст может совпасть, а операция все равно разная.
Повтор через время тоже не всегда дубль. Если человек вернулся к чату позже и заново отправил тот же текст уже для другой задачи, система не должна автоматически считать это старой операцией. Иначе он увидит старый ответ там, где ждет новый запуск.
Хороший ориентир простой: ретрай сохраняет исходное намерение, новая отправка создает новое намерение. Если запрос повторился из-за таймаута, потери сети или двойного клика, это одна операция. Если человек сознательно запускает задачу заново, нужен новый ключ.
На практике лучше всего привязывать идемпотентность к границе бизнес-действия. Для чата это одна отправка сообщения. Для пакетной обработки - один документ, одна запись в очереди или одна задача воркера. Тогда поведение системы остается предсказуемым.
Как работает ключ идемпотентности
Ключ идемпотентности нужно создавать до отправки запроса, а не после ошибки. Клиент или бэкенд генерирует уникальный идентификатор для одной операции: одного сообщения в чате, одной генерации отчета, одного вызова инструмента. Этот ключ уходит вместе с запросом.
Дальше сервис делает простую вещь. Он сохраняет запись с этим ключом, статусом операции и отпечатком входных данных. Отпечаток обычно считают по полям, которые влияют на результат и стоимость: model, messages, temperature, tools и другим параметрам.
Базовый сценарий выглядит так:
- Клиент создает ключ до отправки запроса.
- Сервер принимает запрос и резервирует запись со статусом
in_progress. - После успешного ответа сервер сохраняет итоговый результат или ссылку на него и переводит запись в
done. - Если приходит тот же ключ снова, сервер не запускает новую генерацию, а возвращает сохраненный ответ или текущий статус.
Именно это спасает от самых дорогих ретраев. Если сеть оборвалась уже после того, как модель отработала, повторный запрос не вызовет вторую генерацию и не даст повторное списание. Пользователь просто получит тот же результат, который сервис уже сохранил.
Есть важное правило: один и тот же ключ нельзя использовать с другим телом запроса. Если клиент прислал тот же idempotency key, но поменял prompt или модель, сервер должен вернуть конфликт. Иначе защита теряет смысл: снаружи это выглядит как повтор, а по факту это новая операция.
Хранить такие записи вечно не нужно. Обычно ставят TTL на часы или дни, в зависимости от длины ретраев и поведения клиентов. Этого хватает, чтобы пережить таймауты, повторные клики и автоматические повторы SDK, а таблица не растет бесконечно.
Хорошее правило короткое: один пользовательский intent, один ключ, один результат.
Как внедрять без гонок
Идемпотентность лучше внедрять не в одной точке, а по всей цепочке запроса. Если закрыть только фронтенд или только вызов к модели, дыры останутся.
Сначала решите, кто создает ключ. В веб-чате и мобильном приложении его удобно генерировать на клиенте в момент отправки сообщения. Если клиентам доверять нельзя или запросы идут из нескольких систем, ключ может выдавать бэкенд. На практике часто работает смешанный вариант: фронтенд присылает свой идентификатор действия, а бэкенд добавляет к нему пользователя, тип операции и другие нужные поля.
Дальше важен порядок. Сначала вы резервируете запись с ключом и статусом in_progress. Только потом идете во внешний LLM API. Если сделать наоборот, между внешним вызовом и записью результата появится окно гонки. Этого окна достаточно, чтобы второй процесс успел отправить тот же запрос еще раз.
После успешного ответа полезно сохранять не только текст. Сохраните usage, модель, код ответа провайдера, время создания и нормализованный хэш входных данных. Это сильно упрощает разбор спорных списаний.
Если первый вызов еще не закончен, повторный запрос по тому же ключу должен получать не новую генерацию, а статус ожидания или уже готовый результат. Без промежуточного состояния in_progress второй воркер решит, что ничего не происходило, и запустит еще один вызов.
Схема простая, но на практике именно ее чаще всего ломают. Команда отправляет запрос в модель, а запись создает потом. На тесте все выглядит нормально. Под нагрузкой начинаются гонки, дубли и лишние расходы.
Пример с чатом и таймаутом
Представьте обычную смену в банке. Оператор отвечает клиенту в чате и просит модель подготовить вежливый текст: объяснить статус заявки, сроки и следующий шаг. Запрос уходит в LLM, модель успевает сгенерировать ответ, но сеть обрывается за секунду до того, как интерфейс получает результат.
Оператор видит ошибку и жмет кнопку еще раз. Для человека это один и тот же запрос. Для системы без защиты - два разных вызова. Так и появляются двойные списания и два почти одинаковых ответа в истории.
При таком сбое происходит следующее: сервер отправил запрос провайдеру, провайдер посчитал токены и вернул ответ, ответ не дошел до интерфейса из-за таймаута, а повторный клик создал новый вызов и новое списание.
Идемпотентность убирает эту ловушку. В момент первого клика система создает ключ и привязывает его к конкретной операции: этому чату, этому сообщению и этому действию оператора. Когда оператор нажимает кнопку снова, бэкенд не воспринимает это как новую задачу. Он ищет запись по тому же ключу.
Если первый вызов уже завершился, система отдает сохраненный результат. Текст будет тем же, что модель сгенерировала в первый раз. Нового запроса к провайдеру нет, нового списания тоже нет. Для оператора это выглядит просто: ошибка исчезла, ответ появился.
Для такого сценария достаточно хранить три вещи: сам ключ идемпотентности, статус операции и финальный ответ вместе с данными по расходу токенов. Все остальное уже детали реализации.
Где LLM ведут себя не так, как обычный API
У обычного API повтор одного и того же запроса часто дает тот же объект и тот же статус. С LLM так бывает не всегда. Даже если prompt не менялся, модель может сгенерировать другой текст, выбрать другую формулировку или вызвать другой tool.
Поэтому проверять идемпотентность по телу ответа нельзя. Одинаковая операция не обязана возвращать одинаковые слова. Важно другое: система должна понять, что это та же попытка выполнить то же действие, и не списать деньги второй раз.
Что меняет стриминг
У LLM ответ часто идет потоком. Клиент уже получил первые токены, но итоговый usage еще не пришел. Если в этот момент сеть подвисла или пользователь нажал кнопку еще раз, сервер может получить повторный запрос, пока первая генерация еще жива.
Здесь ломается привычная логика. Стрим мог начаться, клиент мог увидеть таймаут, а модель в это время уже сгенерировала почти весь ответ. Сравнение по готовому тексту не помогает, потому что полного текста у клиента может не быть.
Еще неприятнее история с внешними действиями. Если function calling запускает создание заявки, отправку SMS или запись в CRM, повторный ретрай может дернуть тот же tool еще раз. Тогда у вас не два похожих ответа в чате, а два реальных действия.
Почему кэш не спасает
Кэш решает другую задачу. Он помогает быстрее вернуть уже готовый результат и иногда сокращает расходы на повторные запросы. Но кэш не отвечает на главный вопрос: выполняли ли вы эту операцию раньше и нужно ли блокировать повтор.
Простой пример: пользователь отправил сообщение, модель вызвала tool для оформления заказа, затем клиент не дождался конца стрима и повторил запрос. Кэш может не сработать, потому что второй ответ будет немного другим. Даже если кэш сработает, он не отменит уже выполненный внешний вызов.
Поэтому кэш и идемпотентность нельзя смешивать. Кэш хранит полезный результат. Ключ идемпотентности хранит факт, что конкретную операцию вы уже начали или завершили.
Частые ошибки в реализации
Большинство сбоев появляются не в самой модели, а в мелких решениях вокруг запроса. Один неверный шаг, и система то списывает деньги дважды, то выдает два ответа на один клик, то смешивает чужие операции.
Первая частая ошибка - считать одинаковыми все запросы с одним и тем же prompt. Этого мало. Если не включить в отпечаток модель, temperature, max_tokens, системный prompt, инструменты и другие важные параметры, сервис начнет склеивать разные операции в одну.
Вторая ошибка - сохранять запись только после вызова провайдера. Тогда между отправкой запроса наружу и записью результата остается пустое окно. В этот момент клиент может нажать кнопку еще раз, сеть может оборваться, а ваш бэкенд отправит второй такой же вызов.
Третья ошибка - использовать один и тот же ключ для разных пользователей или тенантов. Ключ должен жить в понятной области: пользователь, проект, операция. Иначе два клиента с одинаковым ключом получат странный обмен ответами.
Четвертая ошибка - слишком ранняя очистка. Если вы удаляете запись через минуту, а мобильное приложение повторяет запрос через две, защита уже исчезла. Срок хранения стоит привязывать к реальному окну таймаутов, ретраев и повторных открытий экрана.
Пятая ошибка - бесконечные автоматические ретраи без проверки тела запроса. Тогда один и тот же ключ начинает прикрывать уже другую операцию, а команда долго не понимает, откуда взялись странные конфликты и повторные расходы.
Полезный минимум для самопроверки такой:
- отпечаток включает модель и все параметры, которые меняют результат или цену;
- запись резервируется до внешнего вызова, а не после него;
- ключ изолирован по пользователю, проекту или tenant;
- TTL дольше, чем возможное окно повторного запроса;
- повтор сравнивает не только ключ, но и тело запроса.
Быстрая проверка перед запуском
Перед релизом полезнее не большой тест нагрузки, а серия злых бытовых сценариев. Именно на них чаще всего всплывают двойные списания и повторы ответа: пользователь жмет кнопку два раза, мобильный клиент ловит таймаут, стрим рвется на середине, а сервер уже успел отправить запрос в модель.
Хороший признак простой: один пользовательский запрос дает один billing event и один итоговый результат, даже если клиент дернулся несколько раз.
Проверьте это вручную и автотестами:
- повторный клик по кнопке "Отправить" не создает второе обращение к модели и не вызывает новое списание;
- если клиент получил таймаут, сервер сначала ищет запись по ключу, а не шлет новый запрос вслепую;
- стрим и обычный ответ идут по одному сценарию учета;
- логи связывают ключ идемпотентности, пользователя, модель, параметры запроса и usage;
- команда видит путь запроса по статусам:
received,sent_to_provider,first_token,completed,failed,expired.
Отдельно проверьте клиентский таймаут. Частая ошибка выглядит банально: фронтенд считает запрос "мертвым" через 15 секунд и отправляет новый, хотя бэкенд еще ждет ответ от модели. В итоге пользователь получает два похожих ответа, а биллинг считает два вызова. Защита работает только тогда, когда проверка ключа стоит перед повторной отправкой.
Если между приложением и моделью есть шлюз, не теряйте эти поля на границе сервисов. В логах должны совпадать ключ, внутренний request_id, внешний request_id провайдера и usage. Тогда дежурный инженер быстро поймет, был ли реальный дубль, обрыв соединения или просто поздний ответ.
Что делать в продакшене
Если эта защита пока живет только в тикете или на схеме, начните с одного сценария, где ошибка сразу бьет по деньгам или по доверию. Обычно это платный вызов модели, создание документа, отправка ответа в чат или любое действие, где повторный запрос ведет к новому списанию.
Один хорошо закрытый поток полезнее, чем абстрактная "поддержка идемпотентности" без проверки на реальной нагрузке.
После этого соберите минимальный набор контроля:
- логируйте ключ идемпотентности, статус запроса и финальный результат;
- считайте долю таймаутов, повторных попыток и реальных дублей;
- отдельно смотрите, сколько ответов вы вернули из сохраненного результата, а не отправили в модель заново;
- сверяйте число клиентских запросов с числом списаний у провайдера;
- ставьте алерт, если доля дублей или таймаутов резко растет.
Эти метрики быстро показывают, где течет система. Часто проблема не в приложении, а в том, что ретраи уже включены где-то ниже: в SDK, в очереди, в API-прокси или в балансировщике. Один запрос пользователя легко превращается в два или три вызова, если каждый слой повторяет его по своим правилам.
Полезно один раз пройти путь запроса целиком и честно ответить на вопрос: кто и сколько раз может повторить его. Если команда не может назвать точный список мест, лишние списания почти неизбежны.
Если запросы идут через единый OpenAI-совместимый шлюз вроде AI Router, трассировка обычно становится проще: у команды есть одна точка входа, единые аудит-логи и лимиты на уровне ключа. Но сам ключ идемпотентности все равно должен жить на уровне вашего бизнес-действия, а не только на уровне внешнего провайдера.
Такую защиту не стоит откладывать. За несколько дней можно закрыть один дорогой сценарий, добавить метрики и проверить все ретраи по пути запроса. После этого идемпотентность перестает быть теорией и начинает экономить деньги уже в текущем релизе.
Часто задаваемые вопросы
Зачем вообще нужна идемпотентность для LLM-запросов?
Чтобы один клик, один ретрай или один таймаут не превращались в две генерации и два списания. Идемпотентность держит в одной рамке API, биллинг и логи, поэтому повторный запрос возвращает тот же результат или текущий статус, а не запускает модель заново.
Откуда обычно берутся дубли и лишние списания?
Чаще всего дубли рождают двойной клик, автоматический ретрай в SDK, короткий таймаут у прокси или обрыв стрима в конце ответа. Пользователь делает одно действие, а система отправляет один и тот же prompt несколько раз.
Что считать одной и той же операцией?
Считайте одной операцией одно пользовательское намерение. Если совпадают пользователь или проект, модель, сообщения, системный prompt, параметры генерации и tools, это тот же запуск; если что-то из этого изменилось, это уже новый запрос.
Когда нужно создавать новый ключ идемпотентности?
Новый idempotency key нужен при любой правке того, что влияет на ответ или цену. Достаточно поменять модель, temperature, max_tokens, текст сообщения, системный prompt или tools, и старый ключ уже не подходит.
Что делать, если клиент получил таймаут?
Сначала ищите запись по idempotency key, а не шлите запрос заново. Если первый вызов уже завершился, верните сохраненный результат; если он еще идет, верните статус ожидания и не запускайте вторую генерацию.
Что стоит сохранять по ключу идемпотентности?
Держите запись по ключу в хранилище до обращения к провайдеру. В ней обычно хватает статуса in_progress или done, хэша входных данных, финального ответа, usage и идентификатора запроса у провайдера.
Как убрать гонки при ретраях?
Сначала резервируйте запись с уникальным ключом и статусом in_progress, и только потом вызывайте внешнюю модель. Тогда второй процесс увидит, что операция уже идет, и не отправит тот же запрос еще раз.
Поможет ли кэш вместо идемпотентности?
Нет, кэш решает другую задачу. Он может вернуть готовый текст быстрее, но не доказывает, что вы уже выполнили именно эту операцию, и не защищает от повторного вызова tool или второго списания.
Как идемпотентность работает со стримингом?
При стриме используйте тот же ключ на весь ответ и храните состояние запроса до конца. Если соединение порвалось на последних чанках, повтор должен вернуть уже готовый результат или статус, а не снова запускать генерацию.
Что проверить после запуска в продакшене?
Сверяйте число пользовательских запросов с числом списаний у провайдера и смотрите долю таймаутов, ретраев и реальных дублей. Если еще логировать idempotency key, внутренний request_id, внешний request_id и usage, вы быстро найдете место, где система повторяет запросы.