Лимиты запросов на уровне ключа для команд без хаоса
Лимиты запросов на уровне ключа помогают разделить нагрузку по сервисам, окружениям и ролям, чтобы шумный клиент не тормозил остальные команды.
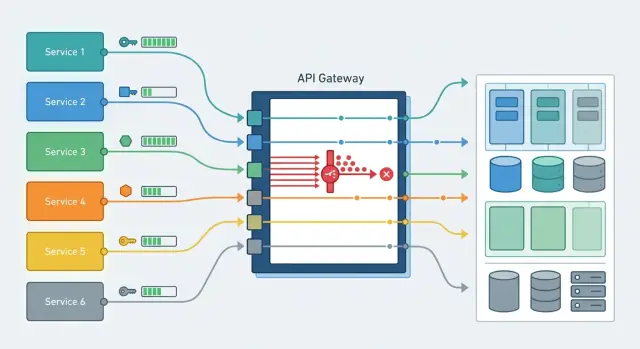
Почему общий лимит ломает работу
Когда прод, тесты и пакетные задачи идут через один API-ключ, они делят один и тот же запас запросов. На схеме это выглядит аккуратно. В работе - почти всегда плохо.
Проблема обычно начинается не в проде, а рядом с ним. Разработчик запускает нагрузочный тест, аналитики отправляют ночную обработку, кто-то проверяет новый промпт на сотнях запросов. Если у всех общий лимит, этот трафик смешивается с боевым. Пользователь видит медленный ответ или 429, хотя сам сервис исправен.
Сильнее всего мешает один шумный клиент или одна шумная задача. Достаточно резко поднять частоту запросов, и общий запас заканчивается на минуту, на час, а иногда и на весь день. Остальные команды в этот момент видят только рост задержки, очередь и сбои в своих сценариях.
Дальше ломается диагностика. График показывает, что лимит исчерпан, но не отвечает на главный вопрос: кто именно его съел. Продовая команда винит интеграцию, интеграция винит тестовый стенд, тестовый стенд молчит, потому что его джобы шли по тому же ключу. Пока люди вручную собирают логи, проблема уже бьет по клиентам.
Поддержка в такой схеме почти всегда работает в пожарном режиме. Вместо понятных правил она вручную отключает доступ, просит команды подождать и ищет виновника по временным меткам. На это уходит больше времени, чем на нормальную настройку лимитов.
Для LLM-приложений это особенно неприятно. Один сервис отправляет короткие запросы, другой - длинные batch-задачи, третий - фоновые ретраи. Если все они сидят под общим потолком, система режет не самый тяжелый поток, а любого, кто попал под лимит. Поэтому лимиты на уровне ключа нужны не для бюрократии, а чтобы каждая часть системы жила в своих рамках и не тормозила соседей.
Как разложить лимиты по слоям
Один общий порог почти всегда приводит к ручному разбору аварий. Рабочая схема строится из нескольких слоев. Обычно хватает четырех:
- отдельный лимит на сервис;
- отдельный лимит на окружение;
- отдельный лимит на роль или тип ключа;
- скромный дефолт для новых ключей, пока по ним нет истории.
Разделение по сервисам убирает самую частую проблему. Чат почти всегда идет рывками, особенно в рабочие часы. Поиск и retrieval обычно дают более ровную нагрузку. Фоновые задачи опаснее всего: один batch на десятки тысяч записей легко занимает весь пул и замедляет ответы для живых пользователей. Если у каждого сервиса свой потолок, сбой остается локальным.
Продакшену нужен свой запас. Не делите его с тестами и песочницей. Разработчик может случайно запустить нагрузочный прогон, QA может начать массовые проверки, и общий лимит закончится в самый плохой момент. Прод должен жить отдельно, даже если трафик в dev кажется маленьким.
Слои по ролям помогают точнее управлять риском. Пользовательский трафик требует стабильного времени ответа. Интеграции обычно могут пережить короткую задержку. Пакетные задачи можно ограничить сильнее или вынести на ночное окно. Админские ключи лучше держать с небольшим, но гарантированным запасом, чтобы команда могла зайти и исправить проблему даже во время пика.
Лимит по умолчанию для новых ключей тоже полезен. Новый сервис редко получает точное значение с первого дня. Дайте ему скромный предел, соберите неделю или две фактической нагрузки, а потом поднимайте. Так вы не душите запуск и не пускаете неизвестный трафик в общий бассейн.
Если команда работает через единый шлюз, совместимый с OpenAI, такую схему поддерживать проще. В AI Router можно выдать отдельные ключи для сервисов и окружений и не смешивать все правила в одном общем лимите.
Лимиты по сервисам
Если все сервисы ходят в LLM через один ключ, проблемы начинаются быстро. Ночной импорт, массовая проверка документов или неудачный ретрай съедают весь запас, а пользователь в этот момент открывает чат или форму и получает медленный ответ.
Поэтому сервисы лучше делить не по командам и не по владельцам, а по профилю нагрузки и цене ошибки. На практике обычно есть четыре группы: клиентский чат и подсказки в интерфейсе, поиск и классификация в реальном времени, фоновые джобы и импорты, а также внутренние инструменты и тестовые сценарии.
Сервисы, которые пользователь видит сразу, требуют ровного поведения. Для них лучше держать предсказуемый лимит без резких всплесков. Пусть потолок будет чуть ниже теоретического максимума, зато ответы останутся стабильными в час пик.
Фоновые задачи стоит ограничить жестче. Им редко нужен мгновенный ответ, зато они любят забирать все доступные запросы, если очередь выросла или воркер начал повторять ошибки. Для таких задач обычно хватает простой связки: меньший лимит, очередь и понятное правило повтора через паузу. Тогда импорт закончится позже, но не уронит сервис, который видит клиент.
Не стоит брать лимит с запасом по ощущениям. Смотрите на реальный трафик: сколько запросов сервис шлет в обычный день, что происходит в пике, как долго длится всплеск. Если у чата 20 запросов в секунду в пике, а у фоновой сверки короткие всплески по 200, одинаковый предел для них не имеет смысла.
Там, где шлюз уже умеет задавать лимиты на уровне ключа, удобно выдать отдельный ключ на каждый сервис. Тогда шумный обработчик не забирает ресурс у продового сценария, а вы сразу видите, кто именно уперся в лимит и где надо чинить очередь, а не просто поднимать цифры.
Лимиты по окружениям
Одинаковый лимит для всех окружений почти всегда бьет по продакшену. Тесты, отладка и разовые прогоны легко съедают общий запас, а потом боевой сервис получает 429 в самый плохой момент.
У продакшена должен быть свой пул с жестким минимумом, который никто не отнимет. Если у вас есть общий бюджет в запросах или токенах, не держите его в одном ведре. Выделите отдельный лимит для боевых ключей и не давайте stage или dev брать из него даже временно.
Тестовому стенду хватит заметно более низкого предела. Он нужен, чтобы проверить релиз, интеграцию и несколько сценариев нагрузки, а не крутить бесконечные эксперименты. Когда stage получает почти такой же лимит, как prod, команда быстро привыкает запускать там все подряд, и шум из тестов начинает мешать реальным пользователям.
Песочнице для разработки лимит нужен еще ниже. Разработчики часто гоняют много коротких запросов, пробуют разные модели, меняют промпты и забывают выключить скрипт. Небольшой предел в dev не мешает работе, зато хорошо ловит такие случаи. Ошибка одного ноутбука не превращается в проблему для всей команды.
Во время релиза лимиты можно поднимать, но только точечно. Не открывайте весь stage или весь dev на несколько часов. Лучше временно дать больше только той группе ключей, которая участвует в выпуске версии.
Рабочее правило простое: prod получает отдельный пул и неснижаемый минимум, stage живет на умеренном лимите, dev и песочница работают на маленьком лимите, а на релизе команда вручную поднимает предел только нужным ключам. После релиза обычные значения надо вернуть сразу. Это часто забывают, а потом временный повышенный лимит живет неделями и создает новую аварию.
Один практичный пример. У ритейл-команды nightly-тесты на stage внезапно начинают слать в десять раз больше запросов из-за новой проверки каталога. Если stage сидит в общем пуле, боевой поиск начинает тормозить. Если у stage свой низкий потолок, тесты упрутся в него, команда увидит всплеск в логах, а продакшен продолжит работать как обычно.
Лимиты по ролям и типам ключей
Одинаковый лимит для всех ключей почти всегда дает перекос. Один сервис отправляет трафик ровно и часто, партнер внезапно дает всплеск, а личный ключ сотрудника нужен только для тестов и отладки. Если смешать эти сценарии, один источник быстро съест общий запас.
Проще всего делить ключи по тому, кто ими пользуется и зачем: сервисные ключи для внутренних приложений, ключи партнеров и внешних клиентов, личные ключи сотрудников, админские ключи и временные ключи для подрядчиков.
Для внешних клиентов полезно ставить два порога сразу: на минуту и на день. Минутный лимит режет резкий всплеск, если у партнера сломался цикл ретраев или ушел неудачный релиз. Дневной лимит защищает бюджет и не дает одной интеграции занять всю емкость до вечера.
Пакетные задачи лучше вынести в отдельный класс ключей. У них свой ритм, и он редко похож на живой пользовательский трафик. Ночная переиндексация, массовая разметка или прогон evaluation не должны конкурировать с запросами из продакшена. Им нужен свой предел и, если требуется, свое окно запуска.
Админский ключ без лимита - плохая идея. Именно такие ключи потом живут дольше всех, копируются в несколько сервисов и становятся тихим источником риска. Даже для админов лучше оставить жесткий потолок, узкий набор прав и отдельный журнал действий.
С подрядчиками правило еще проще: выдавайте временный ключ со сроком жизни. Если человеку нужен доступ на две недели, ключ должен отключиться сам, даже если кто-то забыл его отозвать.
На практике схема выглядит довольно буднично. Клиентам дают лимит на минуту и на день, внутреннему сервису - стабильный рабочий коридор, аналитикам - скромный личный предел, подрядчику - временный ключ на срок проекта. В результате один шумный клиент не тормозит остальных.
Как ввести схему по шагам
Начинать стоит не с цифр, а с карты доступа. Во многих командах ключи живут дольше, чем задачи, ради которых их выпускали. В итоге один и тот же ключ используют stage, внутренний бот и клиентский сервис, а его владелец уже давно сменил команду. Пока вы не разберете, какой ключ кто использует и за что он отвечает, новые лимиты только добавят путаницы.
Сначала соберите простой реестр: имя ключа, сервис, окружение, владелец и запасной контакт. Главная цель - убрать безымянные ключи и общие токены, которыми пользуются все подряд.
После этого дайте себе неделю на наблюдение. Не меняйте правила в тот же день. Посмотрите трафик по каждому сервису: обычную нагрузку, пиковые часы, редкие всплески после релиза или массовой рассылки. Часто картина быстро проясняется: прод стабилен, staging шумит по утрам, а внутренний инструмент делает короткие, но резкие всплески.
Дальше можно вводить схему поэтапно:
- Задайте базовый лимит для обычной работы каждого ключа.
- Добавьте отдельный потолок на короткий всплеск, чтобы релиз или пакетная задача не упирались в жесткий барьер мгновенно.
- Включите журнал отказов с причиной: какой ключ, какой сервис и какой лимит сработал.
- Настройте простые оповещения для владельца сервиса, а не для всей платформенной команды.
- Переводите команды на новую схему по одной, начиная с самых предсказуемых сервисов.
Не пытайтесь сразу найти идеальные числа. Достаточно разумного старта и пары корректировок по факту. Если платежный сервис обычно делает 20 запросов в секунду, не ставьте ему 200 просто на всякий случай. Широкие лимиты редко спасают. Они чаще скрывают проблему до первого серьезного перегруза.
Хорошая проверка очень простая: владелец сервиса знает свой лимит, понимает, куда придет алерт, и может быстро запросить изменение. Если этого нет, схема еще сырая.
Пример: один шумный клиент не мешает всем
У компании есть три потока. Первый - чат поддержки, где операторам нужен быстрый ответ каждую минуту. Второй - кабинет менеджера, где сотрудники смотрят карточки клиентов и документы. Третий - ночная сверка, которая пачками прогоняет файлы и проверяет расхождения.
Проблема начинается ночью, когда пакетная задача резко наращивает нагрузку. Если все три потока ходят в API под одним ключом и делят общий лимит, сверка быстро забирает весь запас запросов. Чат начинает отвечать медленнее, а кабинет менеджера ловит задержки, хотя сами пользователи ни в чем не виноваты.
Рабочая схема намного проще. Команда заводит отдельные ключи под каждый поток и дает им разные пределы: "support-chat-prod" получает высокий приоритет и небольшой, но стабильный запас; "manager-cabinet-prod" живет на среднем лимите без резких всплесков; "docs-reconcile-batch" уходит в отдельный класс для ночной обработки.
Теперь, если сверка внезапно шлет слишком много запросов, система режет только этот ключ. Пакетная задача получает 429, снижает темп или уходит в повтор с паузой. Чат поддержки и кабинет продолжают работать в своем ритме, потому что их запас никто не съел.
Утром разбираться тоже проще. В журнале видно не просто "лимит исчерпан", а конкретную причину: какой ключ уперся в потолок, в какое время это случилось и сколько запросов он успел отправить. Вместо общего поиска по всей системе команда сразу понимает, где проблема.
Если шлюз поддерживает лимиты на уровне ключа и аудит-логи, такую схему можно внедрить без переделки клиентского кода. В AI Router это как раз один из практичных сценариев: разные ключи для разных потоков, единый совместимый с OpenAI эндпоинт и понятная картина по журналам.
Ошибки, которые создают пробки
Пробки в API чаще возникают не из-за слишком маленького порога, а из-за плохого деления нагрузки. Команда вводит лимиты на уровне ключа, но оставляет старые привычки: один секрет для всего, одинаковые квоты для всех и ноль наблюдения за отказами. Тогда любой всплеск быстро превращается в очередь.
Самая частая ошибка - один и тот же ключ используют в проде, тестах и на ноутбуках разработчиков. Кто-то запускает нагрузочный сценарий или случайно уходит в бесконечный цикл, а рабочий сервис получает те же ограничения.
Вторая ошибка - всем ролям дают одинаковый предел. У фоновой задачи, админки и публичного API разная нагрузка. Одна цифра для всех приводит к двум крайностям: одни постоянно упираются в потолок, другие держат запас, который им вообще не нужен.
Третья ошибка - команда смотрит только на минутный предел. Он режет резкий всплеск, но не ловит медленный расход квоты в течение дня. Суточный лимит помогает увидеть забытые джобы, длинные циклы и тихие ретраи.
Четвертая ошибка - старые ключи никто не отзывает. После проекта, пилота или работы подрядчика доступ часто остается жить своей жизнью. Иногда именно такой забытый ключ неделями создает лишний трафик.
Пятая ошибка - лимит настроили и забыли про наблюдение. Если никто не смотрит 429, число повторных попыток и самые шумные ключи, затор растет тихо. Хуже всего, когда клиент при отказе сразу шлет новый запрос и сам усиливает проблему.
Есть простой тест, который быстро показывает качество схемы. По логу должно быть видно, какой сервис, какое окружение и какой тип ключа съел квоту. Если ответ на это ищут полчаса, настройка уже плохая.
Быстрая проверка перед запуском
Перед релизом полезно смоделировать простой сбой: один клиент или один сервис резко поднимает трафик в десять раз. Если после этого начинают тормозить все остальные, схема еще не готова. Такой тест показывает слабые места лучше любой красивой диаграммы.
Сами по себе лимиты не спасают, если ключи выданы без порядка. Проблемы обычно начинаются не в цифрах, а в том, что никто не знает, чей это ключ, какой трафик он должен нести и кто получит сигнал при отказе.
Перед запуском проверьте несколько вещей:
- у каждого сервиса есть свой ключ и понятный владелец;
- продакшен живет отдельно от тестового стенда;
- для внешних клиентов заданы свои лимиты;
- отказы пишутся в журнал, а сигнал быстро доходит до ответственного;
- понятен путь для временного увеличения лимита и возврата к обычному значению.
Если хотя бы один пункт провисает, релиз лучше притормозить. Один лишний день подготовки обычно дешевле, чем ночь с ручным разбором отказов и поиском сервиса, который забил общий канал.
Что делать дальше
Сначала назначьте владельца схемы лимитов. Это не формальность. Один человек или небольшая группа должны решать, кто получает ключ, как он называется, какой лимит ему дают и кто отвечает за превышения. Когда владельца нет, исключения копятся очень быстро, и через месяц никто уже не понимает, почему у двух похожих сервисов разные правила.
Правила выдачи лучше сделать короткими и скучными. Обычно хватает четырех полей: какой сервис использует ключ, в каком окружении он работает, кто владелец со стороны команды и какой пик нагрузки ожидается. Этого достаточно, чтобы не смешивать прод, staging, фоновые задачи и ручные тесты в один поток.
Потом введите простой ритм пересмотра. Раз в месяц откройте фактический трафик и посмотрите на три вещи: где часто появляются 429, какие ключи живут почти без нагрузки и какие сервисы резко растут в пиковые часы. Если лимит не нужен, режьте его. Если сервис стабильно упирается в потолок, поднимайте предел только ему, а не всему аккаунту.
Полезно время от времени устраивать учебный всплеск. Запустите контролируемую волну запросов так, будто один клиент или один воркер вышел из-под контроля. Затем проверьте, кто пострадал первым, дошли ли алерты до нужной команды и сохранил ли прод нормальную скорость.
Если вы ведете запросы к моделям через AI Router, логичный следующий шаг - вынести лимиты на уровень ключа, а не на общий аккаунт, и регулярно смотреть аудит-логи по сервисам. По ним быстро видно, какой поток съедает квоту, где растет 429 и кого пора изолировать отдельным пределом.
План на ближайшую неделю вполне приземленный: назначить владельца, разнести ключи по сервисам и окружениям, включить журнал отказов и один раз проверить, что шумный клиент действительно не может положить всех остальных.
Часто задаваемые вопросы
Почему общий лимит на один API-ключ часто ломает работу?
Потому что прод, тесты и фоновые задачи начинают конкурировать за один и тот же запас запросов. Достаточно одному шумному сценарию резко поднять нагрузку, и живые пользователи увидят задержку или 429, хотя сам сервис работает нормально.
Еще хуже то, что потом сложно понять источник проблемы. В логах видно только общий упор в лимит, а не конкретный сервис или задачу.
По каким слоям лучше делить лимиты в первую очередь?
Обычно хватает трех разрезов: сервис, окружение и тип использования. Отдельно держите прод, stage и dev, а внутри них разделяйте чат, фоновые джобы, интеграции и ручные тесты.
Такой расклад локализует сбой. Если одна batch-задача упрется в потолок, она не потянет за собой чат или боевой поиск.
С чего начать, если сейчас все сервисы сидят на одном ключе?
Начните с карты доступа. Соберите простой реестр: какой ключ к какому сервису относится, в каком окружении он живет и кто за него отвечает.
Потом посмотрите реальный трафик хотя бы неделю. После этого уже ставьте первые значения, а не наоборот.
Нужно ли отделять продакшен от stage и dev?
Нет, не стоит. У продакшена должен быть свой отдельный пул с запасом, который тесты и песочница не тронут.
Даже если dev кажется тихим, один забытый скрипт или массовый прогон QA легко съедает общий лимит в самый плохой момент.
Какой лимит ставить для нового ключа, если истории еще нет?
Дайте новым ключам небольшой безопасный предел. Этого обычно хватает, чтобы сервис запустился, а команда собрала фактическую нагрузку без риска для соседей.
Через неделю или две поднимайте лимит по данным, а не по ощущениям. Так проще избежать лишнего запаса и случайных всплесков.
Зачем ставить лимиты и на минуту, и на день?
Минутный лимит режет резкие всплески. Он полезен, когда у клиента ломается ретрай или кто-то внезапно шлет слишком много запросов за короткое время.
Дневной лимит держит под контролем общий расход. Он помогает заметить тихие фоновые джобы и длинные циклы, которые медленно съедают квоту до вечера.
Что делать с batch-задачами и ночными джобами?
Лучше вынести их в отдельный класс ключей и дать им более жесткий предел. Им редко нужен мгновенный ответ, зато они быстро занимают весь доступный запас, если очередь выросла или воркер начал повторять ошибки.
Добавьте паузу перед повтором и очередь. Тогда задача закончит позже, но не повредит сервисам, которые видят пользователи.
Нужно ли ограничивать админские и личные ключи сотрудников?
Да, иначе они часто становятся скрытым источником риска. Такие ключи копируют между сервисами, забывают отозвать и потом долго не замечают лишний трафик.
Админу лучше дать отдельный ключ с понятным потолком, узкими правами и журналом действий. Этого хватает, чтобы исправлять сбои без лишней дыры в доступе.
Какие логи и алерты нужны, чтобы быстро найти виновника 429?
Пишите не просто факт отказа, а причину. В журнале должны быть видны сам ключ, сервис, окружение, время и лимит, который сработал.
Тогда команда сразу понимает, кто уперся в потолок. Без этого люди тратят время на ручной разбор вместо того, чтобы чинить очередь или менять настройки.
Можно ввести лимиты на уровне ключа без переделки клиентского кода?
Да, если вы используете шлюз, совместимый с OpenAI. Тогда обычно достаточно выдать разные ключи для сервисов и окружений, а клиентский код и SDK можно не трогать.
В AI Router такой сценарий как раз удобен: меняются правила доступа и лимиты на уровне ключа, а интеграция остается прежней.