Зависимость от одного вендора: уход без рефакторинга
Разберем, как снизить зависимость от одного вендора через слой абстракции, тесты совместимости и пошаговую миграцию без крупного рефакторинга.
Почему привязка к одному вендору мешает
Зависимость от одного поставщика редко кажется проблемой в начале. Команда быстро подключает одну модель, пишет интеграцию под один API и запускает первый сценарий. Риск появляется позже, когда этот выбор становится единственным путем для всего сервиса.
Самый заметный сбой - отказ провайдера. Если маршрут один, любая просадка сразу бьет по продукту: чат молчит, классификация заявок останавливается, внутренний помощник отвечает с ошибками. Пользователь не разделяет "сломалась модель" и "сломался ваш сервис".
Есть и более тихий риск. Вы почти не управляете ценой, квотами и лимитами. Провайдер поднимает тариф, ужесточает rate limits или меняет доступность модели по регионам, а команда получает лишние расходы, очередь запросов и неприятный разговор с бизнесом о том, почему бюджет внезапно вырос.
Привязка к одному API мешает и тогда, когда вы хотите перейти на другую модель. Даже если она дешевле и отвечает лучше, код уже часто завязан на конкретные поля ответа, формат системных сообщений, потоковую выдачу и обработку ошибок. В итоге простая замена модели превращается в спешную правку сразу нескольких сервисов.
Для банков, телекома, медицины и госсектора в Казахстане добавляется еще один слой ограничений. Там важны хранение данных внутри страны, маскирование PII, аудит-логи и понятный маршрут данных. Если провайдер не закрывает эти требования, проект тормозит не из-за качества модели, а из-за комплаенса.
На практике команда платит сразу в нескольких местах. Она теряет выручку или время сотрудников при сбоях, переплачивает после изменения тарифов, тратит недели на правки вместо быстрой замены модели и откладывает запуск из-за требований безопасности и права. Пока все работает, это почти незаметно. Когда условия меняются, запасного выхода уже нет.
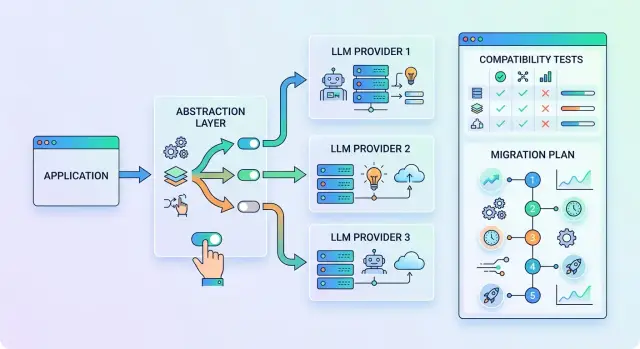
Что вынести в слой абстракции
Если код в десяти местах знает, как вызвать конкретного провайдера, зависимость быстро превращается в архитектурную проблему. Исправлять это лучше не большим рефакторингом, а тонким слоем между приложением и API моделей.
Внутри этого слоя нужен один формат запроса. Приложение отправляет не "вызов OpenAI" или "вызов Anthropic", а обычный объект с понятными полями: алиас модели, массив сообщений, температура, лимит токенов, таймаут, режим ответа и служебные метки. Дальше адаптер переводит этот формат в требования конкретного API.
Сообщения тоже лучше привести к общему виду. Обычно хватает ролей system, user, assistant и tool, плюс одного способа передавать вложения и служебный контекст. Тогда промпты и бизнес-логика живут в одном месте, а отличия провайдеров не расползаются по продукту.
Ошибки нельзя оставлять "родными" для каждого API. Для приложения разница между 429 у одного провайдера и своим кодом rate limit у другого мало что значит. Гораздо удобнее ввести общий набор статусов: таймаут, превышен лимит, ошибка авторизации, недоступен апстрим, слишком длинный контекст, неверный запрос. Тогда ретраи, fallback и алерты работают предсказуемо.
Выбор модели должен идти через конфиг, а не через if в коде. Простой признак здоровой интеграции такой: команда меняет алиас модели или base_url, а сценарий не ломается. Если вход OpenAI-совместимый, слой получается еще тоньше, потому что приложение продолжает работать через тот же SDK и тот же формат вызовов.
Отдельно нормализуйте наблюдаемость. Минимальный набор полей обычно такой: request_id для трассировки, алиас модели и реальный провайдер, задержка и число ретраев, входные и выходные токены, итоговый статус ответа. Этого достаточно, чтобы сравнить маршруты по цене, скорости и стабильности. Хороший слой абстракции не должен быть большим. Его задача проста: одинаково оформлять запросы, ответы, ошибки и логи.
Что не трогать в первой итерации
Первая миграция редко ломается из-за самой модели. Чаще команда сама раздувает объем работ: меняет промпты, правит интерфейс, перестраивает внутренние сервисы. В итоге проект зависает между "почти готово" и "надо еще немного допилить".
На первом проходе цель проще: отделить поставщика модели от остального продукта и проверить, что замена проходит без сюрпризов. Если у вас уже работает чат, поиск по базе знаний или генерация ответов для операторов, считайте это стабильной частью системы.
Поэтому не трогайте вещи, которые не нужны для самой миграции. Не переписывайте бизнес-логику вокруг LLM в тот же спринт. Не меняйте рабочие промпты, если они уже дают приемлемый результат. Не ломайте формат ответа, если другие сервисы ждут конкретный JSON. И не тащите пользователя в вашу проверку совместимости: экран, кнопки и сценарии лучше оставить как есть.
Такой подход резко упрощает тесты совместимости API. Вы меняете один слой, а не пять сразу. Ошибки становятся видны быстрее: где-то отличается схема ответа, где-то иначе считаются токены, где-то модель строже относится к system prompt.
Сначала добейтесь одинакового поведения на старом и новом маршруте. Качество, цену и скорость удобнее улучшать после этого. Иначе миграция быстро превращается в редизайн всей системы.
Как проверить совместимость до переезда
До переключения трафика соберите не демо-промпты, а 20-30 реальных запросов из продакшена. Нужны разные случаи: короткий ответ, длинный ответ, строгий JSON, вызов инструмента, пустой результат, отказ модели, потоковая выдача. На таких запросах быстрее всего видно, где код молча зависит от старого провайдера.
Затем зафиксируйте, что считается нормальным ответом. Не смотрите только на текст "на глаз". Для каждого запроса сохраните входные параметры и набор простых ожиданий: ответ можно распарсить, нужные поля есть, типы не сломались, имя инструмента совпало, аргументы не потеряли обязательные значения, причина остановки не ломает вашу логику.
Что сравнивать
Обычно хватает пяти проверок:
- JSON остается валидным и проходит вашу схему.
- Вызовы инструментов приходят в том же формате.
- Stop reason не меняет поведение приложения.
- Таймауты укладываются в ваш лимит.
- Повторы и ограничения не создают дублей и ошибок.
После этого прогоните один и тот же набор запросов по старому и новому маршруту. Смотрите не только на смысл ответа, но и на протокол. Один провайдер вернет "stop", другой - "length" или "tool_calls". Если ваш код ждет одно значение, переезд формально пройдет, а в продакшене все начнет сыпаться.
С JSON история та же. Модель может сохранить смысл, но поменять структуру: строка станет массивом, пустое поле превратится в null, аргументы функции переедут в другой объект. Для человека это мелочь. Для парсера - падение на ровном месте.
Отдельно проверьте нагрузочные детали, которые часто пропускают: таймауты, 429, повторные попытки, потоковый ответ, размер контекста и работу при серии параллельных запросов. OpenAI-совместимый эндпоинт снижает объем правок, но не гарантирует побайтовое совпадение поведения.
Хороший тест заканчивается не фразой "вроде работает", а таблицей расхождений. По ней видно, что можно принять сразу, что нужно поправить в слое абстракции, а где пока лучше оставить старый маршрут.
Порядок миграции по шагам
Самая частая ошибка - менять вендора сразу во всем приложении. Так команда сама создает риск, хотя цель обратная. Проще идти поэтапно и менять только точку входа к модели.
Сначала вынесите вызов LLM в один модуль. Не так важно, класс это, пакет или небольшой сервис. Важно, чтобы все части продукта ходили к модели через один интерфейс, а не напрямую через SDK в пяти местах.
Потом вынесите в конфиг адрес API, имя модели, токен доступа, таймауты и число повторов. Тогда переключение не потребует правок в бизнес-логике. Если новый провайдер дает OpenAI-совместимый эндпоинт, переход часто сводится к смене base_url, модели и секрета.
Дальше подключите второй маршрут рядом со старым. Не удаляйте текущий путь, пока не соберете цифры. Старый маршрут нужен как контрольная группа: он показывает, где новая цепочка ведет себя хуже, а где уже можно переключаться.
Рабочая последовательность обычно такая:
- Оставьте старый маршрут основным.
- Добавьте новый маршрут через конфиг и тот же интерфейс.
- Прогоните одинаковые запросы по двум путям.
- Переведите на новый путь 1-5% трафика.
- Увеличивайте долю только после нормальных метрик.
Смотрите на три группы сигналов: ошибки, цена и задержка. Ошибки покажут несовместимость по параметрам или формату ответа. Цена быстро вскроет скрытый перерасход на длинных промптах. Задержка важна даже там, где качество уже устраивает: лишние 800 мс пользователи замечают сразу.
Когда малая доля трафика проходит без сюрпризов, переведите основной поток на новый маршрут, но старый оставьте в резерве еще на какое-то время. Тогда откат займет минуты, а не неделю.
Простой пример: чат для сотрудников банка
Оператор в контакт-центре банка открывает внутренний чат и спрашивает: какие документы нужны для перевыпуска карты, как оформить спорную транзакцию, какой срок ответа по обращению клиента. Чат ищет ответ в регламентах и выдает короткую подсказку, чтобы сотрудник не листал десятки страниц вручную.
Если сервис ходит только в один API, любая просадка провайдера сразу бьет по очереди звонков. Оператор ждет дольше, клиент висит на линии, контакт-центр теряет время на каждом обращении.
Чтобы снять этот риск, команда не переписывает весь продукт. Она добавляет слой абстракции между приложением и моделью: один метод для чата, единый формат ответа и отдельный конфиг для маршрута. Интерфейс оператора, поиск по регламентам, системный промпт и логика диалога при этом почти не меняются.
После этого модель можно переключать через конфиг. Сегодня основной маршрут идет в одного провайдера, завтра - в другого. Если интеграция уже построена вокруг OpenAI-совместимого входа, часто хватает смены base_url и имени модели, а SDK и текущий код остаются прежними.
При сбое основной модели трафик уходит на резервный маршрут по простому правилу. Например, сервис ждет ответ 4 секунды. Если получает 5xx, таймаут или пустой JSON, он повторяет запрос на запасную модель. Оператор чаще всего даже не замечает переключение, потому что интерфейс не меняется.
Перед полным запуском команда проверяет совместимость на реальных вопросах сотрудников: частые вопросы по регламентам, длинные диалоги с уточнениями, случаи со строгим JSON для CRM и запросы на русском и казахском. Если новый маршрут держит формат ответа, не ломает промпты и укладывается в нужную задержку, миграция проходит спокойно.
Где команды чаще ошибаются
Большая часть проблем начинается еще до миграции, когда код слишком плотно срастается с API одного провайдера. В одном месте оказываются и бизнес-правила, и параметры модели, и разбор ответа. Такая связка удобна только до первой смены поставщика.
Вторая частая ошибка - тестировать один удачный сценарий и считать, что все готово. Запрос "ответь на вопрос пользователя" проходит, и команда расслабляется. Но сбои обычно прячутся в другом: пустой tool call, длинный контекст, обрезанный JSON, таймаут на втором ретрае, неожиданный отказ по лимиту.
Еще один промах - смотреть только на цену за токен. На практике бюджет ломают не только тарифы, но и квоты, rate limits, длинные промпты, дневные пики и резервный маршрут. Пилот может выглядеть дешевым, а после запуска очередь запросов и число повторов быстро съедают экономию.
Самый рискованный ход - переключить весь трафик в один день. Намного спокойнее перевести сначала малую долю запросов, сравнить ответы, стоимость и задержку, а потом расширять поток. Такой план скучный, но именно он обычно работает.
Перед запуском проверьте и базовые вещи. Один клиент должен отвечать за все вызовы модели. Адрес API и имя модели должны меняться через конфиг. Логи должны показывать request_id, модель, токены, стоимость запроса, тип ошибки и причину повтора. Откат на старый маршрут нужно не просто держать "на бумаге", а один раз проверить руками на стенде.
Что делать дальше
Не растягивайте переход на квартал. Возьмите один понятный сценарий и прогоните его за неделю. Лучше всего подходит поток с низким риском: внутренний поиск по базе знаний, суммаризация писем или черновик ответа оператору. Так команда быстро увидит, где у нее реальная привязка к одному вендору, а где хватает замены конфигурации.
Начните с чтения, где модель только отвечает на запрос и ничего не меняет во внешних системах. Потом подключайте запись: генерацию текста, который уходит пользователю или сохраняется в CRM. Вызовы инструментов и агентные цепочки оставьте на конец. Там чаще всего всплывают скрытые отличия между провайдерами: формат tool calls, лимиты, таймауты и обработка ошибок.
Простой план такой:
- Выберите один сценарий и зафиксируйте набор входов и ожидаемый результат.
- Прогоните этот набор через двух провайдеров с одинаковыми промптами, температурой и ограничениями.
- Сравните качество ответа, задержку, формат JSON, длину ответа и частоту ошибок.
- Переведите на нового провайдера небольшой процент трафика и посмотрите на реальные логи.
Если нужен единый OpenAI-совместимый вход без смены SDK и промптов, для пилота можно посмотреть на AI Router. Он работает как один API-шлюз к разным моделям, а для команд в Казахстане еще закрывает практические требования вроде хранения данных внутри страны, маскирования PII, аудит-логов и ежемесячного B2B-инвойсинга в тенге.
Смысл миграции простой: сначала вернуть себе выбор, а потом уже улучшать качество, цену и скорость. В таком порядке переход остается управляемым и не превращается в большой рефакторинг.
Часто задаваемые вопросы
Чем реально опасна зависимость от одного LLM-провайдера?
Потому что один сбой сразу бьет по всему сервису. Если провайдер дал таймаут, поднял тариф или ужал лимиты, у вас нет простого запасного пути, и команда тушит пожар прямо в рабочем потоке.
Что лучше сразу вынести в слой абстракции?
Вынесите в него единый формат запроса, общий формат ошибок и конфиг маршрута. Приложение должно отправлять алиас модели, сообщения, температуру, лимит токенов и таймаут, а адаптер уже переведет это в API нужного провайдера.
Нужно ли переписывать промпты при первой миграции?
Нет, в первой итерации этого лучше не делать. Сначала отделите поставщика модели от остального кода и добейтесь того, чтобы старый и новый маршрут вели себя почти одинаково.
Как понять, что код уже слишком привязан к одному вендору?
Смотрите на простой признак: если смена модели требует правок в нескольких сервисах, интеграция уже завязана слишком плотно. Еще один сигнал — код ждет конкретные поля ответа, stop reason или формат tool calls только от одного API.
Как проверить совместимость до переключения трафика?
Возьмите 20–30 реальных запросов из рабочего потока, а не красивые демо. Потом прогоните их по старому и новому маршруту и сравните не только смысл ответа, но и JSON, tool calls, stop reason, таймауты и ошибки.
Какие запросы стоит включить в тестовый набор?
Берите разные случаи: короткие и длинные ответы, строгий JSON, вызовы инструментов, пустой результат, потоковую выдачу и ошибки по лимитам. На таком наборе быстро всплывают скрытые зависимости от старого провайдера.
Как перейти на другого провайдера без большого риска?
Сначала соберите один модуль для всех вызовов модели и вынесите base_url, модель, токен и таймауты в конфиг. Затем подключите новый маршрут рядом со старым, дайте ему 1–5% трафика и повышайте долю только после нормальных метрик.
Какие метрики и логи нужны для такой миграции?
Смотрите на ошибки, задержку, токены, число повторов и цену запроса. В логах держите request_id, алиас модели, реального провайдера и итоговый статус, чтобы команда быстро видела, где маршрут ломается или дорожает.
Как настроить fallback на резервную модель?
Задайте простое правило переключения. Например, если основной маршрут вернул 5xx, таймаут или пустой JSON, сервис сразу повторяет запрос на резервной модели в рамках того же интерфейса.
Когда есть смысл использовать единый API-шлюз вроде AI Router?
Если вам нужен один OpenAI-совместимый вход без смены SDK и кода, такой вариант имеет смысл для пилота. Для команд в Казахстане это особенно полезно, когда нужны хранение данных внутри страны, маскирование PII, аудит-логи и B2B-инвойсинг в тенге, как у AI Router.