Выбор типа модели для задачи на одном доменном наборе
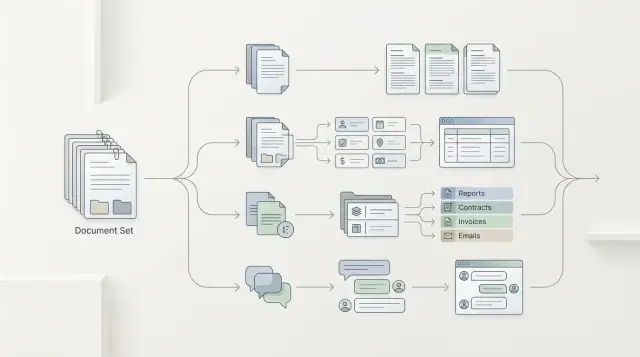
Выбор типа модели для задачи проще, если прогнать один доменный набор через суммаризацию, извлечение, классификацию и чат и сравнить метрики.
Почему бренд модели мешает выбору
Громкое имя часто уводит команду в сторону. Модель может звучать убедительно в чате и писать аккуратные ответы, но путать дату, номер договора или сумму, когда нужно достать поля из документа. Для демо это еще терпимо. В рабочем процессе такая ошибка ломает весь сценарий.
Это и есть частая ловушка: сильный чат принимают за универсальное качество. Но суммаризация, извлечение, классификация и чат требуют разного поведения. Там, где оператору нужен короткий и понятный ответ, одна модель удобна. Там, где нужен строгий JSON без пропусков, она может срываться на каждом пятом примере.
Название провайдера тоже почти ничего не говорит о результате на ваших данных. Общие бенчмарки полезны, но они редко похожи на переписку банка, тикеты телеком-команды или внутренние обращения в ритейле. В доменных текстах много сокращений, местных терминов, кривых формулировок и шума. На таком наборе разница между известным брендом и менее заметной моделью иногда исчезает за один вечер проверки.
Спор о бренде обычно заканчивается быстро, если собрать один общий набор примеров. Достаточно взять несколько десятков реальных фрагментов, скрыть персональные данные и дать моделям одну и ту же задачу. Дальше все становится приземленнее: для чата смотрят, полезен ли ответ человеку; для извлечения считают пропуски и лишние поля; для классификации проверяют метки; для суммаризации оценивают, что модель сохранила, а что потеряла.
Если команда прогоняет такой набор через один шлюз, например AI Router, сравнение получается чище: один и тот же запрос, одни и те же параметры, разные модели. Тогда выбор опирается на поведение в вашей задаче, а не на узнаваемость бренда.
Что положить в доменный набор
Набор разваливается, если в нем только удобные примеры. Для сравнения нужны 50-200 реальных случаев одной и той же задачи, а не смесь из разных сценариев. Если вы проверяете ответы на обращения клиентов, не ставьте рядом договоры, новости и маркетинговые тексты.
Лучше брать данные из живого потока: тикеты, письма, заявки, фрагменты чатов, карточки инцидентов. Тогда выбор опирается на то, что команда действительно видит каждый день, а не на красивую демо-выборку.
Хороший набор почти всегда состоит из нескольких слоев: обычные случаи, которые встречаются чаще всего; редкие формулировки, где смысл тот же, но слова другие; шумные тексты с опечатками, лишними деталями и обрывками фраз; спорные примеры, где даже человеку нужно 10-20 секунд на ответ.
Без этого тест часто врет. Классификация может выглядеть сильной на коротких и чистых текстах, а потом резко просесть на длинных обращениях. Чат, наоборот, иногда держится лучше там, где пользователь пишет сбивчиво и вперемешку.
Одинаковый вход нужен для всех четырех типов моделей. Не сокращайте текст для суммаризации, не подчищайте его для извлечения и не переписывайте запрос для чата. Иначе вы сравниваете не подходы, а подготовку данных.
Ожидаемый ответ тоже лучше держать простым. Для извлечения это одно поле или фиксированный набор полей. Для классификации - одна метка из закрытого списка. Для суммаризации - короткая справка на 2-3 факта. Для чата - ответ по правилам, которые можно сверить по чек-листу.
Как провести честный прогон
Честный тест ломается в двух местах: когда для каждой модели пишут новый промпт и когда сравнивают ответы на разных примерах. В этот момент вы уже меряете не модель, а удачу тестировщика.
Сначала зафиксируйте условия. Один и тот же системный промпт, одинаковая температура, один формат ответа. Если для извлечения вы ждете JSON, все кандидаты должны вернуть один и тот же JSON с теми же полями. Если модель не держит формат, это часть результата, а не повод переписать задачу под нее.
Потом прогоните все варианты на одном наборе. Не делите документы "по ощущениям" и не отдавайте сложные кейсы только чату, а простые только классификации. Возьмите единый срез, например 300 доменных записей с короткими, средними и шумными примерами. Если команда тестирует модели через один OpenAI-совместимый шлюз, проще оставить один SDK и один код, меняя только модель и параметры.
Качество само по себе мало что значит. Рядом с ним считайте цену за весь прогон, цену одного успешного ответа, среднюю задержку, 95-й перцентиль и долю ошибок: пустой ответ, сломанный JSON, отказ, пропуск поля.
Только так видно полную картину. Иногда модель дает результат на 2% лучше, но стоит в 6 раз дороже и отвечает вдвое медленнее. Для боевого сценария это часто плохой обмен.
До полного теста проверьте маленькую выборку вручную. Хватает 20-30 примеров, чтобы заметить грубые сбои: модель путает поля, срезает числа, теряет отрицание, пишет лишний текст вместо схемы. Такой быстрый просмотр экономит часы и не дает запустить длинный прогон с неверной настройкой.
Где выигрывает суммаризация
На одном доменном наборе суммаризация обычно побеждает там, где исходный текст длинный, неровный и человеку нужно быстро понять ситуацию целиком. Это частый случай для писем клиентов, стенограмм звонков, внутренних регламентов, жалоб и разборов инцидентов.
Представьте пакет по страховому случаю: заявление, переписка, правила и комментарий оператора. Извлечение достанет дату, номер полиса и статус. Классификация ответит на узкий вопрос, например нужен ли ручной разбор. А суммаризация может собрать картину целиком: что случилось, какие документы уже есть, какой срок ответа действует и что мешает принять решение.
Смотреть нужно не на гладкий текст, а на то, сохранила ли модель опорные детали. Если в кратком итоге пропали дата события, лимит выплаты, срок ответа или ограничение из правил, такой ответ уже подводит. Он короче, но смысл в нем просел.
Полезно отдельно отмечать слишком аккуратные резюме. Иногда модель убирает повторы и шум, но вместе с ними выбрасывает причинно-следственную связь. В источнике было так: документ отсутствует, поэтому срок сдвинули, а затем кейс отправили на ручную проверку. В слабом summary остается только фраза про задержку, и человек теряет контекст.
Еще один частый сбой - придуманные детали. Если модель дописала обещанный срок, причину отказа или статус согласования, которых не было в тексте, это ошибка.
Суммаризация выигрывает только тогда, когда после нее человек может выбрать следующее действие: одобрить, эскалировать, запросить документ или вернуть кейс на проверку.
Где выигрывает извлечение
Извлечение побеждает, когда на выходе нужен не красивый текст, а набор полей, который система сразу отправит дальше: в CRM, скоринг, поиск или отчет. Если оператору или сервису нужны дата, номер договора, тип обращения и сумма, свободный ответ только мешает.
Схему полей нужно задавать до теста, а не после него. Иначе одна модель вернет "date", другая "request_date", третья напишет все текстом, и сравнение потеряет смысл. Для каждого поля лучше сразу указать формат, допустимые значения и то, что считается пустым ответом.
На доменных данных это видно очень быстро. Возьмем обращения клиентов: модель может хорошо понимать текст, но стабильно пропускать номер счета или канал обращения. Такие пропуски обычно важнее, чем красивый стиль ответа. Если поле нужно для маршрута заявки, один пропуск уже ломает цепочку.
Ошибки полезно разбирать по типам. Их обычно четыре: пусто, хотя значение есть в тексте; лишнее поле, которого нет в схеме; неверный формат; неверное значение при формально правильном формате.
Отдельно проверьте, как модель держит JSON. Это скучный тест, но он быстро отрезвляет. Одна модель может верно извлекать смысл в 9 случаях из 10, но на каждом пятом запросе ломать скобки, менять типы данных или добавлять комментарии. В проде такой ответ часто хуже, чем более простая модель с чуть меньшей полнотой, но с чистой структурой.
Если модель понимает документ, но не держит схему, ей чаще подходит чат или суммаризация. Если она стабильно выдает поля по контракту, извлечение уже выиграло.
Когда лучше работает классификация
Классификация лучше всего там, где системе нужен один ответ из фиксированного набора. Если у вас поток заявок, писем или обращений, и дальше по метке запускается действие, чат часто только мешает. Он пишет развернуто, а бизнес-процессу нужен короткий и однозначный результат.
Во многих задачах это самый практичный вариант. Классификатор обычно дешевле, быстрее и стабильнее на больших объемах. Это особенно заметно в банке, телекоме или ритейле, где за день проходят тысячи похожих сообщений.
Классы лучше задать заранее и описать простыми примерами. Для очереди клиентской поддержки это может выглядеть так:
- "Блокировка карты" - "карту украли, срочно остановите операции"
- "Спорная операция" - "не узнаю этот платеж"
- "Смена лимита" - "увеличьте лимит на переводы"
- "Техническая ошибка" - "приложение не пускает в личный кабинет"
Хуже всего работают расплывчатые метки вроде "прочее" или "вопрос по счету". Модель начинает путать соседние категории, а команда потом вручную разгребает очередь. Если две метки звучат похоже, проверьте эту пару отдельно. Например, "спорная операция" и "мошенничество" часто пересекаются по словам, но это не одно и то же с точки зрения процесса.
Полезно разделять очевидные и спорные случаи. На очевидных примерах почти любая сильная модель покажет хороший результат. Ошибки прячутся в коротких фразах, смешанных намерениях и редких формулировках. Поэтому отдельный набор спорных примеров обычно полезнее, чем еще тысяча простых.
Одной точности мало. Если модель дает 94% верных меток, но стоит в пять раз дороже другой модели с 92%, выбор уже не так очевиден. Смотрите на цену одного решения, задержку и долю ошибок в похожих классах.
Когда чат полезнее
Чат нужен там, где человек уточняет задачу по ходу разговора. Он хорош не для жесткого ответа по шаблону, а для случаев, когда запрос сначала расплывчатый, потом сужается: "Покажи условия", "А если клиент ИП?", "Только для новых договоров". В такой работе суммаризация и классификация быстро упираются в один ход.
Смотрите не на красивый первый ответ, а на 2-3 хода подряд. Модель должна помнить ограничения из прошлого сообщения, не терять сущности и не менять термин в середине диалога. Если на втором ходе она уже путает продукт, тариф или статус клиента, доверять ей рано.
Хороший чат не просто отвечает, а уточняет, когда запрос двусмысленный. Если пользователь пишет "мне не пришел документ", модель может сначала спросить тип документа, канал отправки и срок. Это полезнее, чем уверенный, но случайный совет.
Еще один простой тест: умеет ли модель признать, что ей не хватает данных. На доменных текстах это видно сразу. Если в базе нет правила, хорошая модель так и скажет или попросит фрагмент регламента. Слабая начнет выдумывать исключения и звучит убедительно ровно до первой проверки.
У чата есть цена. Он часто тратит лишние токены на вежливые перефразирования, повтор контекста и длинные подводки. Если задача сводится к метке, полю или точному факту, такой формат только замедляет ответ и повышает стоимость.
Поэтому чат стоит оставлять там, где диалог действительно меняет результат. Во всех остальных случаях полезно сначала проверить, не решает ли задачу более строгий формат.
Простой пример из поддержки банка
Один и тот же текст клиента можно прогнать через четыре типа моделей, и результат будет отличаться по смыслу, а не по качеству бренда. Это особенно заметно в поддержке банка, где сообщение часто длинное, сбивчивое и написано на эмоциях.
Представим жалобу: "12 мая с карты списали 48 900 тенге за покупку, которую я не делал. Платеж прошел через приложение, а я в это время был на работе. Ранее уже звонил в поддержку, номер обращения 18427, но ответа пока нет". Для оператора это один кейс. Для системы - сразу несколько задач.
Если взять тот же текст без изменений, выходы будут разными. Суммаризация сожмет сообщение до 1-2 фраз: спорная операция по карте, клиент ждет ответ по уже открытому обращению. Извлечение достанет поля: 48 900 тенге, 12 мая, канал "приложение", номер обращения 18427. Классификация отправит кейс в очередь по спорным транзакциям, а не в общую линию поддержки. Чат не станет угадывать детали и задаст один точный вопрос, например: "Вы подтверждаете, что не передавали карту и коды третьим лицам?"
Разница видна сразу. Суммаризация помогает оператору быстро понять суть и не читать весь текст дважды. Извлечение нужно там, где поля уходят в CRM, антифрод или форму расследования. Классификация экономит время на маршрутизации. Чат полезен, когда без одного ответа нельзя двигаться дальше.
На практике команды часто ждут, что одна чат-модель закроет все сразу. Обычно так не выходит. Чат может красиво пересказать жалобу, но пропустить сумму или перепутать канал операции. Извлечение, наоборот, хорошо держит структуру, но не объяснит контекст для оператора.
Поэтому сравнивать стоит не "какая модель лучше вообще", а какой тип модели дает нужный выход на каждом шаге обработки обращения.
Где команды ошибаются
Чаще всего тест ломается еще до первого вывода. Команда берет один и тот же набор документов, но для суммаризации пишет подробный промпт, для извлечения короткий, а для чата добавляет подсказки и примеры. После этого кажется, что выиграла модель, хотя на деле выиграли условия теста.
Поэтому сравнивать нужно не только модели, но и режим работы: один шаблон инструкций, одинаковый контекст, одинаковые ограничения по длине ответа и одна схема оценки.
Еще одна частая ошибка - слишком чистый набор. В тест попадают аккуратные письма, ровные тикеты и документы без шума. В проде так почти не бывает: люди пишут с опечатками, пересылают куски переписки, вставляют номера договоров в середину абзаца и путают даты. На таком наборе суммаризация и чат часто выглядят лучше, чем потом работают в реальном потоке.
Хороший тест почти всегда должен включать неполные сообщения, лишний текст и повторы, противоречивые детали, редкие но важные кейсы, примеры с разной длиной и стилем.
Третий сбой встречается у сильных команд не реже. Они смешивают несколько задач в одном тесте: просят модель и классифицировать обращение, и достать поля, и написать ответ клиенту. Потом трудно понять, что именно сработало плохо. Возможно, классификация точная, а чат просто маскирует пропуски в извлечении.
На практике лучше разделить прогон на отдельные дорожки. Сначала проверить каждую задачу сама по себе, а уже потом смотреть на связку. Так проще понять, нужен ли один тип модели на весь поток или лучше отдать разные шаги разным классам моделей.
Последняя ошибка выглядит безобидно: команда смотрит только на средний балл. Среднее скрывает дорогие провалы. Если классификация дает 94% точности, но путает жалобу на мошенничество с обычным вопросом в 3 случаях из 100, этот хвост важнее красивой общей цифры.
Поэтому рядом со средним баллом стоит держать список критичных промахов. Для банка, телеком-команды или госсервиса это обычно важнее, чем разница в один-два пункта в общей таблице. Один пропущенный номер договора или неверный статус заявки потом стоит дороже, чем весь спор о том, какая модель "умнее".
Быстрая проверка перед выбором
Перед тем как обсуждать бренд модели, соберите короткий, но честный тест. Возьмите один и тот же доменный набор, дайте всем вариантам один промпт и потребуйте один формат ответа. Иначе вы сравните не типы моделей, а разницу в формулировках.
Обычно хватает 10-20 примеров, если команда сама их просмотрела и согласилась, где ответ хороший, спорный или плохой. Такой ручной просмотр почти всегда полезнее, чем красивая средняя метрика без контекста.
Смотрите сразу на три вещи: качество ответа, цену запроса и задержку. Бывает, что чат пишет приятно и по делу, но тратит больше токенов и отвечает дольше. А извлечение или классификация решают ту же задачу быстрее и дешевле, потому что не пытаются "разговаривать" там, где нужен точный результат.
Мини-проверка
- Один набор примеров для всех прогонов
- Один текст инструкции без правок под каждую модель
- Один формат ответа: JSON, метка класса или короткая сводка
- Отдельная пометка для цены и задержки
- Ручная проверка 10-20 ответов командой
После такого прогона обычно быстро видно, где нужна строгая схема. Если вы извлекаете номер договора, дату, сумму или статус обращения, свободный чат только мешает. Если оператору нужна краткая сводка разговора или черновик ответа клиенту, диалоговый формат часто выигрывает.
Если вы сравниваете модели через AI Router, задача становится проще: меняется модель, а код и точка входа остаются теми же. Для команд в Казахстане и Центральной Азии это еще и удобный способ держать единый LLM API-шлюз без пересборки интеграции под каждого провайдера. Так в тесте остается меньше лишнего шума.
Что делать дальше
Начните с одной понятной бизнес-задачи. Не с идеи "проверим все сценарии сразу", а с узкого набора примеров по одному процессу. Подойдет 80-150 реальных случаев, где команда может быстро сказать, ответ хороший или нет. Тогда выбор будет опираться на факты, а не на бренд.
Дальше лучше идти короткими циклами. Возьмите один доменный набор и один формат оценки для всех типов моделей. Сравните по 2-3 модели в каждом типе, а не десятки вариантов сразу. Смотрите не только на средний балл, но и на провалы в сложных примерах. И заранее выберите не только победителя по качеству, но и запасной вариант по цене.
Запасной вариант нужен почти всегда. Лучшая по качеству модель может оказаться слишком дорогой для полного потока или давать лишнюю задержку в часы пик. Если отрыв небольшой, более дешевая модель часто выигрывает в реальной работе.
Когда интеграция не меняется на каждом прогоне, сравнение чище. Это одна из практических причин, почему командам удобно тестировать через airouter.kz: можно менять модели и провайдеров, не переписывая SDK, код и промпты. В таком режиме проще сравнивать ответы, цену и стабильность, а не разницу в обвязке.
После такого прогона у вас обычно остается не "лучшая модель вообще", а понятная таблица решений под конкретные шаги процесса. Например, классификация идет в прод по умолчанию, чат остается для сложных диалогов, а извлечение включается там, где важна точность полей. С этого уже можно запускать пилот и считать эффект в деньгах и времени команды.
Часто задаваемые вопросы
Как понять, какой тип модели мне нужен?
Если системе нужны дата, сумма, номер договора или другой набор полей для CRM, поиска или отчета, берите извлечение. Если оператору нужно быстро понять длинный текст и решить, что делать дальше, чаще подходит суммаризация.
Чат нужен там, где человек уточняет вопрос по ходу диалога. Классификация лучше работает, когда на выходе нужна одна метка из закрытого списка.
Сколько примеров нужно для первого теста?
Для быстрого отбора обычно хватает 10–20 примеров. Такой прогон помогает убрать явные сбои: пропуски полей, выдуманные детали, сломанный JSON и лишний текст.
Для более честного сравнения лучше собрать 50–200 реальных случаев одной задачи. Тогда уже видно, как модель держится на шумных и спорных примерах.
Можно ли давать каждой модели свой промпт?
Нет, так сравнение быстро теряет смысл. Когда вы меняете и модель, и промпт, вы уже не понимаете, что именно дало разницу.
Лучше зафиксировать один системный промпт, одну температуру и один формат ответа. Если модель не держит условия, это и есть результат теста.
Что должно быть в хорошем доменном наборе?
Берите живые тексты из того потока, который хотите автоматизировать: письма, тикеты, чаты, заявки, карточки инцидентов. Не смешивайте в одном наборе разные задачи, если хотите честное сравнение.
Полезно добавить обычные случаи, редкие формулировки, тексты с опечатками и спорные примеры. На слишком чистой выборке почти любая сильная модель выглядит лучше, чем в реальной работе.
Какие метрики смотреть кроме качества?
Смотрите не только на качество ответа. Считайте цену всего прогона, цену одного успешного ответа, среднюю задержку, 95-й перцентиль и долю ошибок.
На практике модель с чуть лучшим качеством часто проигрывает, если она заметно дороже, отвечает дольше или часто ломает формат.
Когда суммаризация выигрывает у других вариантов?
Она полезна, когда исходный текст длинный, неровный и человеку нужно быстро понять ситуацию. Это частый случай для писем клиентов, стенограмм звонков, жалоб и разборов инцидентов.
Проверяйте не гладкость текста, а сохранность фактов. Если summary потеряло дату, срок, лимит или причину решения, такой ответ уже не помогает.
В каких задачах лучше сразу брать классификацию?
Классификация лучше всего подходит для потока однотипных обращений, где дальше по метке запускается действие. Она обычно дешевле и быстрее чата, если системе нужен один короткий ответ из фиксированного набора.
Хорошо работает заранее заданный список классов с простыми примерами. Чем расплывчатее метки, тем чаще модель путает соседние категории.
Что делать, если модель понимает текст, но ломает JSON?
Не пытайтесь спасать результат ручными правками после каждого сбоя. Если по задаче нужен строгий JSON, умение держать схему — часть качества, а не мелочь.
Обычно есть два пути: упростить схему и проверить снова или взять модель, которая стабильно возвращает нужную структуру. Если схема постоянно разваливается, такой вариант плохо подходит для продакшена.
Почему бренд модели часто сбивает с выбора?
Громкое имя часто хорошо продает демо, но не гарантирует результат на ваших данных. Доменные тексты почти всегда полны сокращений, шума, местных терминов и кривых формулировок.
Поэтому спор о бренде лучше закрывать коротким тестом на реальных примерах. Иногда менее заметная модель за один вечер проверки показывает такой же или лучший результат.
Как упростить сравнение нескольких моделей в одной интеграции?
Проще всего держать один и тот же код, SDK и формат запроса, а менять только модель и параметры. Тогда вы сравниваете ответы, цену и задержку, а не разницу в обвязке.
Если команда использует один OpenAI-совместимый шлюз, такой прогон делать заметно проще. В случае с AI Router это еще удобно для команд, которым нужен единый API и тест без лишней пересборки интеграции.