Таймауты в LLM-цепочке: как разделить лимит времени
Таймауты в LLM-цепочке влияют на ответ не меньше, чем выбор модели. Покажем, как делить общий SLA между шлюзом, поиском, инструментами и моделью.
Где ломается общий таймаут
Общий таймаут почти никогда не срабатывает в удобной точке. Он обрывает цепочку там, где запрос оказался в этот момент: на шлюзе, во время поиска, на вызове инструмента или уже при ответе модели. Для пользователя разницы нет - он видит одну и ту же ошибку.
Проблема в том, что время в LLM-цепочке расходуется неровно. Поиск по базе знаний может внезапно занять 4 секунды вместо одной, и у модели почти не остается времени на генерацию. Снаружи это выглядит так, будто тормозит сама модель, хотя запрос до нее дошел слишком поздно.
С инструментами происходит то же самое. Один зависший HTTP-вызов, медленный SQL-запрос или внешний сервис без собственного лимита держит открытой всю цепочку. Если отмена не проходит через все шаги, система ждет до последнего, а потом роняет ответ целиком.
Обычно сбой выглядит так: шлюз принял запрос, ретривер долго искал документы, инструмент не ответил вовремя, а общий лимит закончился еще до финального ответа модели.
Хуже всего то, что причина часто не видна сразу. В логах остается запись вроде "request timeout" или 504 без разбивки по этапам. Пользователь уже ушел, а инженеры спорят, кто виноват: шлюз, поиск, инструмент или модель.
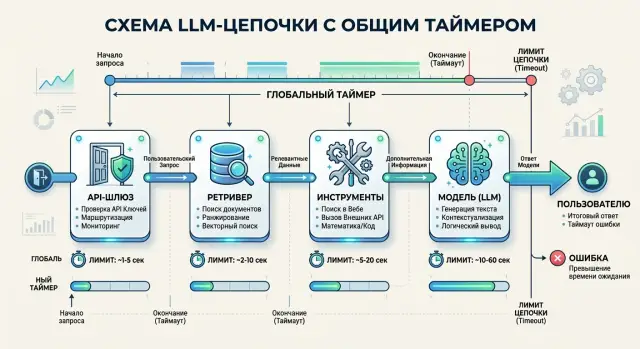
В продакшене это всплывает особенно часто, когда цепочка проходит через API-шлюз и несколько внешних зависимостей. Если запрос идет через шлюз, потом в ретривер и затем в модель, общий таймаут может оборвать его еще до генерации полного ответа. Без замеров по шагам такой сбой легко принять за случайную нестабильность, хотя причина обычно очень приземленная: один этап просто съел чужое время.
Из чего складывается задержка
Лимит времени почти никогда не уходит только на ответ модели. Пока пользователь ждет текст, система уже тратит миллисекунды и секунды на сеть, очереди, поиск данных и вызовы других сервисов. Поэтому лимит в 10-15 секунд на деле часто оставляет модели лишь половину.
Задержка обычно состоит из четырех частей. Сначала запрос доходит до API-шлюза: там есть сетевой путь, проверка ключа, лимиты и иногда короткая очередь, если поток резко вырос. Затем система ищет документы в векторном хранилище, фильтрует результаты и, если нужно, отправляет их на реранк. После этого могут включаться инструменты: CRM, поиск по базе, платежный сервис, внутренний API, SQL-запрос или функция расчета. И только потом модель начинает генерировать ответ.
Даже у модели задержка не одна. Есть время до первого токена и полное время генерации. Для пользователя это два разных ощущения. Если первый токен пришел быстро, ожидание кажется нормальным. Если экран молчит несколько секунд, сервис уже выглядит сломанным.
На практике больнее всего не средняя задержка, а длинный хвост. Один медленный внутренний сервис легко съедает 2-3 секунды. Реранк на большом наборе документов добавляет еще секунду. Если потом модель долго выходит на первый токен, пользователь видит тишину, хотя система формально еще жива.
Простой пример: чат-ассистент банка получил лимит 12 секунд. Около 500 мс ушло на шлюз и сеть, 1,8 секунды на поиск и реранк, еще 2,2 секунды на проверку статуса клиента во внутреннем сервисе. У модели осталось меньше 8 секунд, и это еще без запаса на повторную попытку или отмену зависшего шага.
Если вы работаете через единый шлюз вроде AI Router, картина не меняется. Один OpenAI-совместимый эндпоинт упрощает интеграцию, но бюджет задержки все равно нужно считать по шагам. Иначе общий таймаут выглядит щедрым только на бумаге.
Полезно смотреть хотя бы на три отметки: когда запрос пришел на шлюз, когда система получила контекст и когда модель отдала первый токен. По этим точкам обычно сразу видно, где уходит время.
Как выбрать общий лимит времени
Начинать лучше не с модели, а с терпения пользователя. В чате люди ждут меньше всего. Если экран молчит 2-3 секунды, сервис уже кажется зависшим. Если первый токен пришел быстро, тот же пользователь спокойно дочитает ответ еще 5-8 секунд.
Поэтому лимит лучше делить на две части: время до первого токена и время до полного ответа. Для интерфейса важнее первая цифра. Для бэкенда и SLA важны обе, потому что длинный хвост портит опыт не меньше, чем медленный старт.
Стартовые рамки можно задать по типу сценария:
- чат: 1,5-2,5 секунды до первого токена и 8-12 секунд на полный ответ;
- поиск с RAG: 2-4 секунды до первого токена и 10-15 секунд на полный ответ;
- агентный сценарий с инструментами: 3-5 секунд до первого токена или быстрый промежуточный статус и 20-40 секунд на весь цикл.
Не отдавайте весь бюджет модели и ретриверу. Оставьте запас на сеть, отмену запроса, запись логов и хвосты шлюза. Если у вас есть маскирование PII, аудит-логи или маршрутизация через единый API-шлюз, резерв в 10-20% часто спасает от ложных таймаутов.
Рабочее правило простое: сначала возьмите лимит, который человек считает приемлемым, потом вычтите служебные расходы, а остаток разделите между шагами цепочки. Например, если команда поддержки хочет получать ответ не дольше 12 секунд, можно сразу зарезервировать около 1 секунды на сеть и служебные операции, отдельно держать цель в 2 секунды до первого токена, а все остальное отдать на поиск, инструменты и генерацию.
И не пытайтесь жить с одним лимитом для всех маршрутов. Короткий FAQ, поиск по базе знаний и агент, который ходит в CRM, работают по разным правилам. Один общий потолок для всего обычно бьет либо по скорости, либо по качеству ответа.
Как разложить лимит по шагам
Сначала зафиксируйте SLA для одного запроса. Не среднее время, а предел, после которого ответ уже бесполезен. Если чат должен ответить за 8 секунд, именно от этой цифры и нужно считать бюджет.
Потом разберите путь запроса на отдельные ступени. Чаще всего это API-шлюз, ретривер, внешние инструменты и модель. Иногда добавляются постобработка, проверка политики или запись в лог. Пока эти части не видны по отдельности, таймауты почти всегда настраивают на глаз.
У каждого шага должен быть жесткий предел. Это время, после которого этап останавливается без споров. Полезен и мягкий порог: если шаг еще не уперся в жесткий таймаут, но уже выбился из нормального окна, система может перейти на запасной вариант.
Для общего лимита в 8 секунд расклад может быть таким:
- шлюз и маршрутизация - до 300 мс;
- ретривер - до 1,2 секунды;
- один внешний инструмент - до 1,5 секунды;
- модель - до 4,2 секунды;
- резерв на сеть, сериализацию и неожиданные задержки - около 800 мс.
Мягкий порог особенно полезен там, где есть fallback. Если ретривер не уложился за 700 мс, можно отдать ответ без части контекста. Если инструмент тормозит дольше 1 секунды, можно показать черновой ответ и пометить, что данные неполные. Пользователь чаще прощает чуть менее точный ответ, чем пустой экран.
Есть еще одна простая проверка: сумма всех лимитов должна быть меньше общего таймаута, а не равна ему. Иначе любой сетевой скачок сломает весь запрос. Для продакшена запас в 10-15% - это обычная гигиена, а не перестраховка.
Если вы держите модели и маршруты через общий шлюз, удобно хранить такой бюджет рядом с правилами маршрутизации и rate limits. Так вся цепочка живет по одним правилам, а не по отдельным настройкам в разных местах.
Как настроить ретривер и инструменты
Ретривер и внешние инструменты чаще ломают ответ не из-за одной большой аварии, а из-за мелких задержек. Поиск тянется на 400 мс дольше обычного, CRM отвечает с третьей попытки, калькулятор цен ждет очередь, и модель уже получает слишком мало времени на финальный ответ.
Поиск лучше держать коротким и предсказуемым. Если базе обычно хватает 3-5 фрагментов, не стоит просить top-k=20 "на всякий случай". Лишние документы редко делают ответ умнее. Зато они растят задержку и добавляют шум в контекст.
Базовые правила тут скучные, но рабочие: задайте ретриверу жесткий лимит по времени, ограничьте top-k до числа, которое реально помогает, каждому инструменту дайте отдельный таймаут, а после дедлайна возвращайте частичный результат или пропускайте шаг.
Один общий таймаут на все вызовы почти всегда заканчивается плохо. Для поиска по базе знаний это может быть 150-300 мс, для CRM или биллинга 500-800 мс, для редкого внешнего API чуть больше, если без него ответ теряет смысл.
Не все инструменты одинаково важны. Разделите их на обязательные и желательные. Если ассистент поддержки уже нашел нужную статью и видит номер заказа в сообщении, нет смысла ждать еще два медленных вызова, чтобы пересказать те же данные.
Лишние запросы лучше отменять сразу, как только ответ уже можно собрать. Если один инструмент дал достаточный факт, оркестратор должен прервать остальные вызовы, а не ждать их "для полноты". Это особенно заметно в системах, где путь до модели проходит быстро, а весь отклик портят медленные инструменты перед ней.
Нужна и понятная деградация. Если ретривер не успел, модель может ответить без поиска и честно сказать, что точные данные не подтянулись. Это заметно лучше, чем тишина через 12 секунд.
Что отдать модели
Модель не должна съедать весь бюджет. Сначала отнимите время на шлюз, ретривер и инструменты, а модели отдайте остаток плюс небольшой запас на отмену запроса и возврат аккуратной ошибки. Если общий лимит 8 секунд, модели часто хватает 4-5 секунд, а не всех 8.
Отдельно измеряйте время до первого токена и время до конца ответа. Для пользователя это разные вещи. Одно дело увидеть первый токен через 700 мс и потом спокойно дочитать длинный ответ. И совсем другое - смотреть на пустой экран 5 секунд. Рост времени до первого токена часто говорит о перегруженной модели, очереди у провайдера или слишком тяжелом промпте.
До вызова модели полезно жестко ограничивать max_tokens. Это самый простой способ не сжечь лимит на задаче, где достаточно короткого ответа. Классификации может хватить 20-50 токенов, краткому резюме - 120-200, а длинный черновик письма уже требует другого бюджета. Если не задать потолок заранее, модель легко уйдет в многословие и заберет лишние секунды.
Стоит и разделять запросы по сложности. Простые задачи лучше сразу отправлять в более быструю модель, а медленную оставлять для случаев, где она действительно нужна.
- Извлечение полей, метки и короткие ответы - быстрая модель и маленький лимит токенов.
- Ответ с несколькими источниками или сложной проверкой - модель сильнее и бюджет чуть больше.
- Длинный текст для человека - включенный стриминг, чтобы пользователь видел начало ответа сразу.
- Длинная очередь или медленный первый токен - запасной маршрут на другую модель или другого провайдера.
Стриминг особенно полезен там, где итоговый ответ длинный. Он не ускоряет саму генерацию, но заметно улучшает ощущение скорости. Для чата это почти всегда хороший выбор.
Запасной маршрут нужно готовить заранее, а не после инцидента. Если время до первого токена превысило ваш порог, запрос можно перевести на более быструю модель с чуть более простым качеством ответа. В AI Router это удобно делать через тот же OpenAI-совместимый эндпоинт, не меняя SDK, код и промпты.
И еще одно правило, которое часто упускают: ориентируйтесь не на среднюю задержку модели, а на худшие 5-10% запросов. Именно они ломают SLA чаще всего.
Пример с реальным сценарием
Представьте чат-бот банка. Клиент пишет: "Где моя заявка на кредитную карту?" Бот не может сразу звать модель и ждать сколько получится. Сначала он ищет ответ в базе знаний, потом пытается проверить статус заявки через внутренний сервис, и только после этого собирает финальный ответ.
Команда дала на весь запрос 8 секунд. Это уже не абстрактная цифра, а жесткий бюджет, который нужно раздать по шагам так, чтобы ответ пришел вовремя даже при плохой сети.
Один рабочий расклад может быть таким:
- 300 мс уходит API-шлюзу на прием запроса, проверку ключа, маршрутизацию и старт трассировки;
- 1,2 секунды получает поиск по базе знаний;
- 2 секунды получает инструмент, который ходит в систему заявок;
- 4 секунды остается модели на сбор ответа;
- 500 мс команда держит в запасе на отмену зависшего шага, сетевые скачки и отправку результата клиенту.
Смысл такого бюджета в том, что каждый шаг знает свой предел. Если поиск не уложился в 1,2 секунды, бот не ждет дальше и идет по сокращенному сценарию. Если сервис статусов завис дольше 2 секунд, система отменяет вызов и не тратит еще пару секунд впустую.
Как это выглядит в ответе
Допустим, поиск нашел статью про сроки рассмотрения заявки, а внутренний сервис статусов не ответил. Тогда бот не пишет расплывчатый текст. Он честно сообщает обычный срок проверки, объясняет, где клиент увидит обновление статуса, и предлагает повторить запрос позже.
Это лучше, чем держать пользователя в ожидании все 8 секунд, а потом вернуть ошибку. В банке такой компромисс обычно выигрывает: человек получает полезный ответ сразу, пусть и без точного статуса в эту секунду.
Запас в 500 мс тут не роскошь. Без него красивый расчет на бумаге ломается в проде. Отмена инструмента, закрытие соединения и отправка текста клиенту тоже занимают время. Если резерв не заложить, SLA начинает плавать даже при нормальной работе остальных частей.
Что смотреть в логах и метриках
Среднее время ответа почти всегда успокаивает зря. Один и тот же запрос может проходить за 2 секунды в половине случаев, но каждый сотый упираться в дедлайн и ломать весь сценарий. Поэтому смотрите не только на общее время, а на хвосты задержки: p50, p95 и p99 отдельно для шлюза, ретривера, инструментов и модели.
Если p95 у поиска нормальный, а p99 резко растет, уже понятно, где пропадает бюджет. То же самое работает для модели: у нее может быть хороший медианный ответ, но редкие долгие генерации будут съедать весь лимит и вызывать отмену уже на уровне шлюза.
Связать все шаги помогает один trace id. Без него логи выглядят как шум: отдельно вызов модели, отдельно поиск, отдельно таймаут шлюза. С trace id видно полную цепочку конкретного запроса и легко понять, где он начал тормозить и кто первым выбрал весь свой лимит.
Для записи запроса обычно хватает нескольких полей:
- trace id для всей цепочки;
- имя шага и его длительность в миллисекундах;
- причина остановки: успех, таймаут, ошибка или ретрай;
- общий дедлайн и остаток времени перед каждым шагом;
- кто отменил запрос: пользователь или система по дедлайну.
Причину таймаута лучше писать явно на каждом этапе. Запись "request timeout" почти бесполезна. Гораздо полезнее видеть что-то вроде "retriever timeout after 180 ms" или "model canceled because 320 ms remained and tool used 900 ms".
Отмены тоже стоит разделять. Пользователь закрыл чат, сеть оборвалась, фронтенд отменил запрос, шлюз остановил цепочку по дедлайну - это разные события, и чинятся они по-разному. В логах их часто смешивают, а потом команда тратит дни не на ту проблему.
Зрелая система выглядит просто: по одному trace id вы за минуту понимаете путь запроса, остаток лимита на каждом шаге и точную причину сбоя.
Частые ошибки
Чаще всего проблема не в модели, а в правилах вокруг нее. Команда ставит один и тот же лимит на шлюз, ретривер, инструменты и сам вызов модели, а потом удивляется, почему запрос иногда живет дольше общего дедлайна. Если у каждого шага свои 10 секунд, вся цепочка легко уходит в 20-30.
Та же ошибка появляется с повторами. Ретрай сам по себе нормален, но он должен смотреть на остаток времени. Если первый вызов ретривера уже съел 700 мс из лимита в 1 секунду, второй запуск на те же 700 мс почти всегда бессмысленен. Он не спасает ответ, а только добивает SLA и держит занятыми ресурсы.
Параллельные инструменты ломают картину еще сильнее. На схеме все выглядит быстро: три вызова идут одновременно. На деле один инструмент зависает, второй отвечает с хвостом задержки, а оркестратор ждет их дольше, чем может себе позволить. У параллельных веток должен быть общий дедлайн, а не просто отдельные таймауты на каждый вызов.
Ошибка с fallback обычно выглядит так: основную модель держат почти до конца, а запасную запускают, когда времени уже не осталось. В итоге система делает два дорогих вызова и все равно не успевает. Fallback нужно включать раньше, пока у запасного пути еще есть шанс вернуть полный ответ.
Есть и тихая, но дорогая проблема: клиентский запрос уже закрыт, а бэкенд продолжает работать. Шлюз, инструменты и модель крутятся дальше, хотя ответ уже некому отправлять. Для OpenAI-совместимого API-шлюза это особенно неприятно: тратятся токены, GPU и квоты на работу, которую никто не увидит.
Правило тут прямое: каждый шаг должен знать не свой максимальный таймаут, а остаток общего бюджета. И как только клиент отменил запрос, вся цепочка должна остановиться сразу.
Быстрая проверка перед запуском
Перед релизом полезно сделать короткую проверку по цифрам, а не по ощущениям. Сбои часто возникают не из-за одного очень медленного шага, а из-за небольшого перерасхода на каждом этапе.
Сначала проверьте математику. Если общий лимит ответа 12 секунд, сумма лимитов на шлюз, ретривер, инструменты и модель должна быть меньше этого числа. Оставьте хотя бы 5-10% запаса на сетевые скачки, повторные попытки и сериализацию ответа. Если вы распределили все 12 секунд без остатка, система уже живет на грани.
Потом проверьте диагностику. У каждой ступени должен быть свой код ошибки, чтобы команда сразу видела, где именно цепочка уперлась в лимит. Один общий "timeout" тут почти ничего не дает.
Минимальный набор выглядит так:
- шлюз возвращает свой код таймаута;
- ретривер возвращает отдельный код;
- каждый инструмент помечает свой таймаут отдельно;
- модель имеет свой код превышения лимита;
- оркестратор пишет, на каком шаге запрос остановился.
После этого нужны три простых теста с искусственной задержкой. Отдельно замедлите поиск и проверьте, укладывается ли цепочка в лимит и получает ли команда понятную ошибку. Затем так же проверьте медленный инструмент. Потом отдельно замедлите модель и убедитесь, что система не ждет дольше разрешенного.
Полезно задать себе два вопроса. Увидит ли дежурный инженер причину за 30 секунд? Сохранит ли продукт понятный ответ пользователю, если один шаг зависнет? Если на любой из них ответ "нет", запуск лучше отложить на день и дочистить схему.
Что сделать дальше
Не пытайтесь сразу перестроить все таймауты разом. Возьмите одну рабочую цепочку, где задержка уже заметна: например, поиск по базе знаний с одним вызовом модели и одним внешним инструментом. На таком маршруте проще увидеть, кто съедает время и где запросы обрываются слишком рано.
Дальше соберите реальные замеры. Не ставьте лимиты на глаз. Посмотрите p50, p95 и долю таймаутов по каждому шагу: шлюз, ретривер, инструмент, модель. Если ретривер обычно отвечает за 120 мс, а иногда за 900 мс, этого уже достаточно, чтобы собрать нормальный бюджет.
Дальше можно идти по короткому плану:
- выбрать одну цепочку с понятным сценарием;
- снять замеры по шагам за несколько дней;
- задать лимиты с небольшим запасом;
- проверить, где срабатывает отмена и кто не успевает завершиться;
- через неделю пересмотреть цифры на живом трафике.
Неделя реального трафика часто меняет картину. В тестах модель может укладываться в лимит почти всегда, а в проде выясняется, что инструмент поиска иногда тормозит, а длинные промпты сдвигают весь бюджет. После такой проверки обычно хорошо видно, что стоит ужать, а что пока оставить с запасом.
Если команде нужно быстро сравнить лимиты у разных моделей и провайдеров, удобно тестировать их через один и тот же интерфейс. Для этого можно использовать airouter.kz: он позволяет менять только base_url на api.airouter.kz и гонять те же SDK, код и промпты через один OpenAI-совместимый эндпоинт. Это полезно, когда вы хотите сравнить не теорию, а поведение цепочки под одинаковой нагрузкой.
Смысл всей настройки довольно приземленный. Таймауты должны не просто останавливать запросы, а защищать ответ от лишнего ожидания. Если каждый шаг знает свой предел, умеет отменяться и оставляет время следующему этапу, цепочка начинает вести себя предсказуемо. А это в продакшене ценится сильнее любой красивой схемы.
Часто задаваемые вопросы
Почему одного общего таймаута мало?
Потому что он рвет цепочку в случайной точке и почти ничего не объясняет. Пользователь видит одну ошибку, а команда потом гадает, кто съел время: шлюз, поиск, инструмент или модель.
Гораздо лучше дать предел каждому шагу и смотреть остаток общего бюджета перед следующим вызовом. Тогда сбой видно сразу, и система не ждет до последней секунды впустую.
С чего начать настройку таймаутов в LLM-цепочке?
Начните не с модели, а с ожиданий человека. Если в чате экран молчит дольше 2–3 секунд, сервис уже кажется сломанным, даже если полный ответ пришел бы позже.
Сначала выберите приемлемое время до первого токена и полный лимит ответа, потом вычтите сеть, служебные операции и запас. Только остаток делите между поиском, инструментами и моделью.
Какие лимиты подойдут для чата на старте?
Для обычного чата можно взять стартовую цель в 1,5–2,5 секунды до первого токена и 8–12 секунд на полный ответ. Этого хватает, чтобы интерфейс не выглядел зависшим и у модели оставалось время дописать мысль.
Дальше подгоняйте цифры по живому трафику. Если первый токен приходит поздно, урежьте промпт, ускорьте маршрут или включите стриминг.
Как разложить общий лимит по шагам?
Берите общий SLA и раскладывайте его сверху вниз. Если весь запрос должен уложиться в 8 секунд, заранее отдайте часть времени шлюзу, поиску, инструментам и только потом модели.
Рабочая схема выглядит просто: короткий лимит на шлюз, отдельный лимит на ретривер, свой предел на каждый внешний вызов и остаток на генерацию. Сумма должна быть меньше общего дедлайна, иначе любой сетевой скачок сломает ответ.
Нужно ли оставлять запас времени?
Да, без запаса расчет живет только на бумаге. Отмена запроса, сериализация ответа, скачок сети и запись логов тоже тратят время.
Обычно хватает резерва в 10–15%, а если у вас есть аудит-логи, маскирование PII или лишний сетевой переход через шлюз, лучше держать 10–20%. Этот буфер часто спасает от ложных таймаутов.
Что делать, если ретривер съедает слишком много времени?
Сначала сократите сам поиск. Если вам обычно хватает 3–5 фрагментов, не тяните top-k=20 ради перестраховки: это добавляет задержку и шум в контекст.
Потом поставьте ретриверу жесткий предел и мягкий порог. Если поиск не уложился в нормальное окно, лучше отдать ответ с неполным контекстом, чем потерять весь запрос.
Как ставить таймауты для внешних инструментов?
Не вешайте один таймаут на все инструменты сразу. CRM, биллинг, SQL и внешний HTTP-сервис ведут себя по-разному, значит и лимиты у них должны быть разными.
Разделите инструменты на обязательные и желательные. Если без вызова ответ теряет смысл, дайте ему чуть больше времени. Если инструмент только уточняет детали, отменяйте его раньше и собирайте ответ без него.
Когда запускать fallback на другую модель?
Не ждите до самого конца. Если время до первого токена ушло за ваш порог или провайдер явно тормозит, переключайте маршрут раньше, пока запасная модель еще успеет вернуть нормальный ответ.
Такой переход лучше готовить заранее. Для простых задач можно сразу держать быстрый маршрут, а более сильную и медленную модель оставлять только для сложных запросов.
Что нужно логировать, чтобы быстро найти источник таймаута?
Пишите длительность каждого шага, общий дедлайн, остаток времени перед следующим вызовом и точную причину остановки. Запись вроде request timeout почти бесполезна, потому что она ничего не объясняет.
Один trace id сильно упрощает разбор. По нему вы быстро увидите, где запрос начал тормозить и кто первым выбрал свой лимит.
Что проверить перед релизом такой схемы?
Проверьте математику, а потом сломайте цепочку руками. Сумма лимитов по шагам должна быть меньше общего дедлайна, и у каждого этапа должен быть свой код ошибки.
После этого искусственно замедлите поиск, инструмент и модель по отдельности. Если система в каждом случае вовремя останавливает шаг, отдает понятную ошибку или частичный ответ и не продолжает работу после отмены клиента, схему уже можно выпускать.