Сроки хранения логов LLM: как разделить записи по классам
Разберем сроки хранения логов LLM: как разделить операционные, отладочные и аудиторские записи и не копить лишние данные.
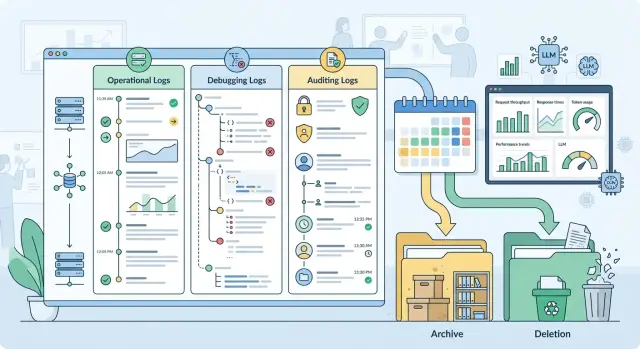
Почему один срок для всех логов создает проблемы
Идея "хранить все 180 дней" выглядит простой, но почти всегда дает плохой результат. У разных журналов разная задача. Операционные логи помогают видеть ошибки, задержки и лимиты. Отладочные записи нужны, когда команда разбирает сбой в промпте, маршрутизации или ответе модели. Аудиторские события живут дольше, потому что по ним проверяют доступ, действия сотрудников и спорные операции.
Если дать всем записям один срок, ошибка почти неизбежна. Либо вы слишком рано удалите то, что нужно для проверки. Либо будете слишком долго держать то, что уже не помогает, но увеличивает риск и расходы.
У LLM-систем эта проблема заметна особенно быстро. Один запрос тянет за собой не только текст, но и служебные поля: токены, ретраи, трассировку, версию промпта, метки безопасности, данные о пользователе. Если система еще ведет историю шагов агента и вызовов инструментов, один диалог превращается в десятки записей.
Через пару месяцев единый срок хранения начинает бить по двум местам сразу. Хранилище распухает, а полезный сигнал тонет в лишних копиях. Параллельно растет риск: в старых сырых логах остаются персональные данные, куски документов, номера заявок, фрагменты переписки и внутренние подсказки для модели.
Подход "оставим на всякий случай" обычно оказывается самым дорогим. Польза лога почти всегда падает со временем, а риск хранения растет. Полное тело запроса может помочь сегодня, когда команда чинит инцидент. Через три недели эта же запись уже вряд ли нужна, но при утечке или внутренней проверке создаст много лишних вопросов.
Это особенно заметно там, где трафик идет через единый LLM API-шлюз. Операционные события копятся постоянно, аудит нужен для контроля доступа и действий, а сырые отладочные данные быстро разрастаются до неразумного объема. Если не разделить сроки заранее, команда сначала собирает все подряд, а потом уже не может аккуратно и безопасно это разобрать.
Как разделить записи на три класса
Логи удобнее делить не по сервисам и не по месту хранения, а по цели. Один запрос к модели вполне может оставить три разных следа. Это нормально. Проблемы начинаются, когда их смешивают в один журнал.
Операционные логи нужны для ежедневной работы сервиса. В них обычно достаточно request_id, времени вызова, имени модели, провайдера, статуса, задержки, числа входных и выходных токенов, стоимости, кода ошибки и числа ретраев. По этим полям видно, где выросла задержка, почему падают запросы и какой маршрут сработал. Полный промпт и полный ответ тут чаще мешают, чем помогают.
Отладочные записи нужны на короткий срок и под конкретную задачу. В них могут быть версия системного промпта, параметры вызова, provider_request_id, стек ошибки, маршрут по фолбэкам, короткий фрагмент промпта или усеченный ответ. Их лучше включать точечно и сразу маскировать чувствительные данные. Иначе отладка быстро превращается в склад лишней информации.
Аудиторский след решает другую задачу. Он нужен не для дебага, а для доказуемой истории действий. Обычно в нем хранят actor_id или service account, тип действия, время, решение политики, факт маскирования PII, метку контента, регион обработки, идентификатор ключа, хеш запроса или ответа и запись о том, кто получил доступ к данным. Такой журнал должен отвечать на вопрос "что произошло и по каким правилам", а не копировать всю переписку.
Что чаще всего путают
Самая частая путаница - между user_id и персональными данными пользователя. Для операций и аудита обычно достаточно внутреннего идентификатора или хеша. Телефон, ИИН, email и свободный текст туда попадать не должны.
Еще одна ошибка - класть текст ответа модели в аудит. Для проверки обычно хватает хеша, метки политики и факта выдачи ответа. Сам текст, если он вообще нужен, относится к коротким отладочным данным.
В LLM-шлюзе это видно особенно ясно. У чат-помощника банка операционный лог покажет timeout, рост задержки и переключение на другую модель. Отладочная запись поможет найти неудачный retry и проблемный параметр запроса. Аудиторское событие зафиксирует, что система замаскировала PII, обработала запрос в нужном регионе и записала доступ к ответу оператора.
Какие данные не стоит писать в журналы без разбора
Логи почти всегда получают больше данных, чем реально нужно. Если писать в журнал все подряд, туда быстро попадают ИИН, номера документов, телефоны, email, адреса, даты рождения, номера карт, данные полисов и фрагменты медицинских записей. Для команды это не мелочь, а прямой источник риска.
Проблема в том, что такие данные утекают не только из текста запроса. Они прячутся в истории чата, аргументах инструментов, JSON из CRM, OCR-результатах, именах файлов, метаданных вложений и даже в сообщениях об ошибках.
Обычно в логи случайно уезжают четыре группы данных:
- личные данные: ИИН, ФИО, дата рождения, паспортные данные, телефон, email, адрес;
- финансовые и договорные данные: номер карты, IBAN, номер договора, счета, заявки, полиса;
- медицинские и страховые сведения: диагнозы, анализы, выписки, страховые статусы;
- внутренние данные компании: данные сотрудников, фрагменты тикетов и документов.
Отдельная проблема - секреты. В журналах нередко остаются Bearer tokens, API keys, cookies, OAuth-коды, webhook secrets, signed URL, строки подключения к базе и временные пароли. Их часто видно в HTTP-заголовках, query params, stack trace, дампах окружения, отладочных print и сохраненных cURL-запросах. Вложения не менее опасны: PDF, изображения, аудио и base64-строки иногда попадают в лог целиком вместе с извлеченным текстом.
Полный текст стоит хранить только там, где без него нельзя разобрать короткий инцидент. Во многих случаях хватает более безопасной замены. Маска сохраняет форму значения, но скрывает саму строку. Хеш позволяет понять, что один и тот же клиент или токен встречался несколько раз, не раскрывая исходное значение. Идентификатор шаблона или версия промпта часто полезнее полного текста, если команда ищет причину сбоя в конкретной сборке.
Ответы модели тоже нельзя считать безобидными. Модель может повторить персональные данные из запроса, пересказать документ или вернуть кусок внутренней переписки. Вывод инструментов еще опаснее: поиск, SQL, CRM, OCR и файловые коннекторы могут вернуть сырой текст, который журналировать нельзя. Для операционных и аудиторских записей обычно достаточно времени, модели, статуса, задержки, размера ответа, кода ошибки и ID документа без его содержимого.
Если у вас есть шлюз с маскированием PII и аудит-логами, как AI Router, это правило стоит применять до записи события, а не после. Если запись не помогает найти сбой, подтвердить доступ или пройти проверку, ей не место в журнале.
Как задавать сроки по шагам
Сроки хранения лучше назначать не для сервиса целиком, а для конкретных полей и типов событий. У одного запроса может быть десяток следов: время вызова, ID модели, число токенов, код ответа, фрагмент промпта, маскированный user ID, IP, причина блокировки, запись для аудита. У каждого поля своя задача, значит и срок должен быть своим.
Начинать стоит с инвентаризации. Соберите полный список того, что пишут API, фоновые воркеры, прокси, очередь, мониторинг, SIEM и промежуточные сервисы. Часто лишние данные лежат именно там, а не в основном приложении.
Дальше для каждого поля нужна одна понятная цель. Поле помогает чинить сбой? Считать расход? Искать злоупотребление? Проводить аудит? Если цель размыта, поле, скорее всего, не стоит хранить.
После этого назначайте минимальный срок под задачу, а не "с запасом". Метрики задержки и коды ошибок часто нужны 14-30 дней. Отладочные записи с фрагментами промптов лучше держать считанные дни или не писать вовсе. Аудиторские события живут дольше, потому что по ним проверяют, кто, когда и что сделал.
Отдельно стоит зафиксировать правило продления на время инцидента. Если команда расследует утечку, всплеск ошибок или спорную операцию, она временно продлевает хранение только для затронутых записей и только до закрытия разбора.
И еще один простой, но часто забытый шаг: назначьте владельца. Кто-то должен утверждать сроки, фиксировать исключения и пересматривать матрицу, когда меняется продукт, закон или схема логирования.
Больше всего споров обычно вызывает текст запроса и ответа. Тут полезно резать объем сразу. Для отладки часто хватает короткого фрагмента, шаблона, хеша, ID сессии и технических признаков ответа. Если поле потенциально содержит персональные данные, маскирование должно происходить до записи.
Есть удобный тест для каждого поля: что именно мы потеряем, если удалим его через 7 дней, 30 дней или 180 дней? Если ответ расплывчатый, срок, скорее всего, завышен. Если поле не помогает чинить, считать или доказывать действие, лучше не хранить его вообще.
Где проходит граница между логом и архивом
Лог нужен для текущей работы. Архив держат для редких случаев: разбора инцидента, проверки доступа, спора по счету, внутреннего контроля. Когда команда хранит все в одном слое, поиск замедляется, расходы растут, а удалить что-то становится страшно.
В горячем доступе стоит оставлять только то, что нужно каждый день. Для большинства команд это операционные логи: время запроса, код ответа, модель, число токенов, идентификатор клиента или сервиса, трассировка по цепочке вызовов, факт срабатывания фильтра и признак маскирования PII. Полные тексты промптов и ответов редко нужны с такой же частотой.
Практическая схема хранения обычно выглядит так:
- короткий срок в горячем слое - сырые тексты запросов и ответов, если без них нельзя разбирать ошибки;
- средний срок в холодном слое - отладочные записи по инцидентам и спорным случаям;
- долгий срок - метаданные для контроля, биллинга и проверок;
- после окончания срока - удаление без архива, если запись не попала под отдельное правило.
Холодное хранение не должно превращаться во вторую "живую" базу. Доступ туда медленнее, права уже, поиск грубее. Это нормальная цена за то, что старые записи не мешают ежедневной работе.
Во многих случаях разумно хранить метаданные дольше, чем сырые тексты. Для аудита часто хватает даты, ID запроса, пользователя сервиса, версии модели, длины промпта, статуса ответа, признака редактирования или маскирования и хеша диалога. Такой набор оставляет след события, но не тянет за собой лишние тексты с персональными данными.
Граница между логом и архивом проходит не по возрасту, а по частоте использования и цели хранения. Если запись нужна дежурной команде каждую неделю, это еще лог. Если к ней обращаются раз в квартал, это уже архив. Если она не нужна ни для разбора, ни для сверки, ни для требований регулятора, ее надо удалять.
Момент удаления лучше описывать как правило, а не как ручное решение. Например: запись прожила свой срок в горячем и холодном слоях, не участвует в расследовании, не нужна для финансовой сверки и не подпадает под отдельный норматив. После этого система удаляет ее без архива. Тогда политика хранения работает как политика, а не как склад "на всякий случай".
Пример для чат-помощника банка
Клиент пишет в чат банка: "Проверьте статус заявки, мой ИИН 123456789012". Для сервиса это обычный запрос, но для логов это уже риск. Если команда без разбора пишет весь диалог во все журналы, ИИН быстро расползется по отладке, мониторингу и архивам.
Рабочая схема проще. Один диалог дает несколько разных записей, и у каждой свой срок. Банку не нужен полный текст клиента везде, где нужен только факт обращения к модели.
В операционном логе остается минимум: время запроса, ID сессии, какая модель вызвана, код ответа API, задержка и расход токенов. В отладочном следе команда держит только то, что помогает разобрать сбой: ID ошибки, версию промпта, имя сервиса и короткий маскированный фрагмент вместо полного текста клиента. В аудиторском журнале хранят событие доступа к переписке, смену настроек маршрутизации, выпуск нового ключа, изменение rate limit или правил маскирования.
Если ответ модели вернулся с кодом 200, операционный лог уже закрывает большую часть вопросов поддержки. Он показывает, что вызов был, когда он ушел, сколько занял и какой сервис его обработал. Для этого не нужны ни ИИН, ни полный текст диалога.
Если запрос упал с ошибкой, разработчики могут на короткое время включить более подробный отладочный след. Но и тут не стоит хранить лишнее. Вместо фразы "Проверьте статус заявки, мой ИИН 123456789012" в журнале должно остаться что-то вроде "Проверьте статус заявки, мой ИИН [MASKED]". Такую запись часто достаточно держать 24-72 часа, пока команда не закроет инцидент.
Аудит живет дольше. Ему нужен не разговор клиента, а ответ на другой вопрос: кто и когда получил доступ к данным, кто поменял настройки и кто отключил защиту. Именно эти события обычно просят на внутренней проверке.
Если банк отправляет LLM-запросы через единый OpenAI-совместимый шлюз вроде AI Router, такую схему проще удерживать в одном месте. Можно отдельно задать сроки для операционных, отладочных и аудиторских событий, а PII маскировать до записи в журналы.
Где чаще ошибаются
Проблемы обычно начинаются не со срока хранения, а с лишних копий. Команда задает правило для одной системы, а данные уже лежат в пяти местах: в приложении, в gateway, в APM, в очереди и в выгрузке для аналитики. После этого политика хранения существует только на бумаге.
Самая частая ошибка - писать полный промпт и ответ сразу в несколько систем. Так делают ради удобства отладки, но потом один и тот же диалог живет дольше, чем планировалось. Намного безопаснее хранить полный текст в одном контролируемом месте, а в остальных оставлять request_id, время, модель, статус и пару технических меток.
Еще одна типичная история - включили подробный debug после инцидента и забыли выключить. Через неделю это уже не временный режим, а новая норма. Логи быстро разрастаются, в них попадают пользовательские данные, а работа со старыми записями становится дорогой и неудобной.
Путают и сами типы журналов. Аудит доступа отвечает на вопрос, кто и когда открыл данные или вызвал действие. Техническая трассировка нужна, чтобы найти сбой, timeout или лишний retry. Отладочные записи помогают разработчику понять конкретную поломку здесь и сейчас. Отдельно живут резервные копии, очереди и выгрузки, о которых часто просто забывают.
Когда аудит смешивают с трассировкой, начинается хаос. Аудит хотят хранить дольше и строже контролировать. Технические записи, наоборот, часто нужны недолго. Если все лежит в одной таблице или одном индексе, побеждает самый длинный срок, и мусор копится месяцами.
Есть и скрытые копии: бэкапы, dead-letter очереди, CSV-выгрузки для поддержки, тестовые дампы. Они часто живут дольше основных логов. Если в проде включено маскирование PII, а в резервной копии лежит сырой текст, правило по сути не сработало.
Поэтому удаление нужно проверять на практике. Возьмите один test request_id, дождитесь конца срока и попробуйте найти его в основном хранилище, в бэкапе, в очереди и в выгрузках. Если вы используете шлюз вроде AI Router, полезно отдельно описать, что хранит само приложение, что хранит шлюз и что уходит в вашу SIEM. Иначе дубликаты быстро возвращаются.
Кто утверждает сроки и как их менять
Матрицу сроков не должен подписывать один человек. Если продукт сам решит хранить логи дольше, он почти всегда оставит лишнее. Если срок задаст только ИБ, команде может не хватить данных для разбора сбоев.
Рабочая схема обычно простая. Продукт отвечает за смысл данных: зачем нужен лог, кто им пользуется и как часто. ИБ смотрит на риск: есть ли в записи персональные данные, токены, текст запросов, ответы модели, служебные идентификаторы. Юристы и комплаенс сверяют сроки с договором, внутренними правилами и требованиями регулятора. Платформенная команда внедряет это в системе: выделяет классы логов, настраивает удаление по расписанию, включает маскирование и запрещает ручные копии там, где это возможно.
Продлевать срок хранения лучше только по заявке и на ограниченный период. Не "пока пригодится", а, например, на 14 или 30 дней под конкретный инцидент, спор по операции или проверку.
В такой заявке достаточно четырех вещей: какой набор записей нужно держать дольше, кто запросил продление, зачем это нужно и когда данные удалят или переведут в архив.
Право на продление тоже не стоит раздавать всем подряд. Обычно запрос подает владелец сервиса, ИБ согласует его, юрист подключается, если лог затрагивает персональные данные или спорные операции, а платформа исполняет решение. Это заметно снижает число просьб сохранить "все на всякий случай".
Журнал исключений полезен даже там, где сроки уже утверждены. В нем хранят не сами логи, а историю решений: что продлили, по какой причине, кто одобрил и когда срок истекает. Такой журнал хорошо помогает на внутренней проверке и при разборе старых инцидентов.
Пересматривать матрицу стоит не ради галочки, а после изменений в продукте. Новый канал общения, интеграция с CRM, prompt caching, другой провайдер модели, запуск новых аудиторских событий или новый способ маскирования меняют состав данных. После таких изменений старые сроки часто уже не подходят.
Если команда использует единый LLM-шлюз, например AI Router, пересмотр особенно нужен при подключении новых моделей, провайдеров и маршрутов. Сам факт маршрутизации не решает политику хранения. Ее все равно задают люди внутри компании, письменно и с понятными ролями.
Короткая проверка перед запуском
Перед релизом логи стоит проверять так же строго, как права доступа и rate limits. Ошибка тут обычно банальна: команда пишет в журнал "на всякий случай", а потом месяцами хранит лишние данные и не может быстро показать, кто и зачем читал записи.
Перед запуском полезно пройтись по короткому списку:
- у каждого поля есть одна причина хранения и понятный срок жизни;
- PII маскируется до записи в журнал;
- подробный debug включается только на время диагностики;
- удаление проверено не только в основном хранилище, но и в копиях;
- доступ к аудиторским записям прозрачен и сам тоже журналируется.
На практике этого хватает, чтобы отсечь большую часть проблем. Например, у чат-помощника банка можно хранить операционные события дольше, чем подробные отладочные записи, но только если в событиях нет сырых сообщений клиента и лишних идентификаторов.
Если команда работает через LLM-шлюз вроде AI Router, правила не меняются. Один endpoint не отменяет дисциплину: срок нужен для каждого класса логов, маскирование должно происходить до записи, а удаление должно доходить до всех копий.
Хороший признак перед релизом простой: инженер открывает схему логов и за пару минут отвечает на три вопроса - что мы пишем, зачем пишем и когда удаляем. Если на любой из них начинается долгий спор, лучше ненадолго остановиться и привести правила в порядок.
Что сделать дальше
Начните с одной рабочей таблицы. Без нее сроки хранения быстро превращаются в набор исключений, о которых помнят два человека в команде. В таблице стоит зафиксировать поле, класс записи, цель хранения, срок, место хранения, кто имеет доступ и что происходит после истечения срока.
Обычно хватает шести колонок: имя поля или события, класс записи, наличие PII, срок хранения, способ удаления или обезличивания и владелец правила.
Потом проверьте не документ, а реальное поведение систем. Команды часто настраивают удаление в основной базе, но забывают про тестовую среду, экспорт в объектное хранилище и резервные копии. Из-за этого данные вроде бы "удалены", но на деле лежат еще месяцами. Лучше один раз прогнать тест: создать запись, дождаться срока и убедиться, что она исчезла из всех мест, где команда может ее найти.
Отдельно согласуйте продление сроков на время расследования. Это правило лучше описать заранее, а не в день инцидента. Укажите, кто может поставить запись на hold, по какому основанию, на какой срок и кто снимает продление. Иначе операционные логи очень быстро начинают жить вечно.
Если команда использует AI Router, полезно сверить свою матрицу хранения с тем, как у вас устроены аудит-логи, маскирование PII и требования к хранению данных внутри страны. Для банков, телекома и госсектора спор обычно идет не о самом факте логирования, а о составе полей и сроке жизни каждой записи.
Финальный тест простой: любой инженер, аналитик или сотрудник ИБ должен за пять минут ответить на три вопроса. Что мы пишем в журнал, зачем это храним и когда именно удаляем. Если четкого ответа нет хотя бы на один пункт, политика хранения еще не готова.
Часто задаваемые вопросы
Зачем вообще делить логи на классы?
Потому что у записей разные задачи. Операционные логи помогают ловить ошибки и считать расход, отладка нужна на короткое время, а аудит хранит историю действий и решений. Один срок для всех либо удалит нужное слишком рано, либо оставит лишние тексты и персональные данные слишком надолго.
Какие классы логов стоит завести для LLM-сервиса?
Чаще всего хватает трех классов. Операционный лог хранит время запроса, модель, статус, задержку, токены и ошибки. Отладочный след держит версию промпта, stack trace, маршрут retry и короткие фрагменты текста. Аудит пишет, кто сделал действие, когда это произошло, с каким правилом и в каком регионе прошла обработка.
Нужно ли хранить полный промпт и ответ модели?
В большинстве случаев нет. Для поддержки и мониторинга обычно хватает метаданных: request_id, кода ответа, задержки, числа токенов и имени сервиса. Полный текст оставляйте только на короткий срок и только для разбора конкретного сбоя, если без него команда не найдет причину.
Какие данные нельзя писать в лог без разбора?
Сначала уберите из логов ИИН, телефоны, email, адреса, номера документов, карты, договоры, медицинские данные и любые секреты вроде API keys, cookies и Bearer tokens. Эти значения часто приезжают не только из текста, но и из JSON, OCR, истории чата, headers и сообщений об ошибках.
Если поле нужно для анализа, маскируйте его до записи. Когда достаточно связать события, храните хеш или внутренний ID вместо исходной строки.
Сколько держать операционные и отладочные логи?
Для операционных логов часто хватает 14–30 дней. Этого обычно достаточно, чтобы увидеть всплески ошибок, рост задержки и проблемы с маршрутом. Если команда редко возвращается к старым данным, не тяните срок дольше просто из привычки.
Подробные отладочные записи лучше держать заметно меньше. Часто хватает 24–72 часов или нескольких дней до закрытия инцидента.
Когда имеет смысл продлить срок хранения?
Продлевайте срок только под конкретный случай: инцидент, спор по операции или внутреннюю проверку. Сразу укажите, какие записи вы держите дольше, кто это запросил, зачем это нужно и когда система удалит данные.
Не сохраняйте весь массив «на всякий случай». Лучше продлить хранение только для затронутых request_id, сессий или периода сбоя.
Чем аудит отличается от отладочных записей?
Аудит отвечает на вопрос «кто и что сделал». Отладка отвечает на вопрос «почему сломалось». Поэтому аудит хранит actor_id, тип действия, решение политики, факт маскирования и доступ к данным, а не полный разговор клиента.
Если смешать эти журналы, победит самый длинный срок хранения. В итоге сырые тексты и лишние копии будут лежать там, где им не место.
Как понять, что запись уже пора считать архивом?
Лог нужен дежурной команде для ежедневной работы. Архив нужен редко: для спора, проверки или старого инцидента. Если к записи обращаются каждую неделю, оставляйте ее в горячем слое. Если к ней смотрят раз в квартал, переносите в архив или удаляйте после срока.
Сырые тексты запросов и ответов редко стоят места в горячем хранилище дольше короткого периода. Метаданные для биллинга и контроля можно держать дольше.
Как проверить, что удаление логов реально работает?
Возьмите один test request_id и дождитесь конца срока. Потом попробуйте найти его в основном хранилище, в backup, очередях, APM, выгрузках и тестовой среде. Если запись всплывает хоть в одном месте, правило не сработало.
Такую проверку стоит повторять после изменений в логировании, маршрутизации и интеграциях. Лишние копии чаще всего живут именно в соседних системах, а не в основной базе.
Кто должен утверждать сроки хранения логов?
Сроки лучше утверждать вместе. Владелец сервиса объясняет, зачем нужен каждый тип записи, ИБ смотрит на риск, юристы и комплаенс сверяют требования, а платформа настраивает маскирование, удаление и доступ.
Если решение принимает только одна сторона, почти всегда выходит перекос. Либо команда хранит лишнее, либо ей не хватает данных для разбора сбоев.