Хранение состояния AI-агента: Redis, БД или журнал
Хранение состояния AI-агента влияет на паузы, одобрение и повторный запуск. Разбираем, когда выбрать Redis, БД или событийный журнал.
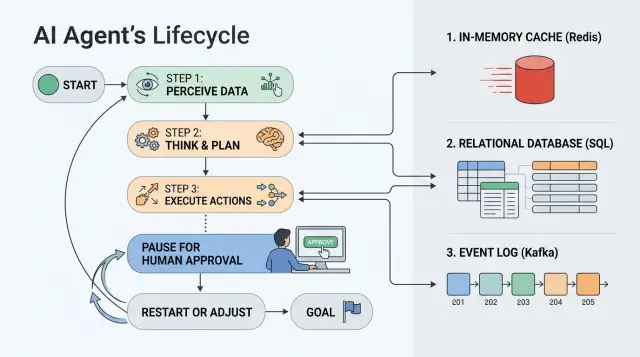
Где теряется состояние между шагами
Проблемы начинаются не тогда, когда агент отвечает на запрос, а когда он должен ждать. Час паузы, ночь, ручное одобрение - и сразу видно, есть ли у процесса нормальное хранилище состояния или все держится на памяти воркера и удаче.
Сценарий обычно простой. Агент собрал данные, отправил заявку на проверку и ждет ответ сотрудника. Пока ничего не происходит, воркер успевает перезапуститься, контейнер переезжает на другой узел, а очередь отдает задачу повторно. Если состояние жило только в памяти процесса, после рестарта агент уже не понимает, на каком шаге остановился.
Окно контекста модели тут не помогает. Модель может "помнить" текст, который вы снова положите в промпт, но она не хранит таймеры, статус одобрения, идентификатор внешней операции и сам факт того, что письмо или платеж уже ушли. Контекст продолжает диалог. Состояние продолжает процесс.
Это особенно заметно в продакшене, где вызовы LLM идут через API-шлюз или обычный OpenAI-совместимый эндпоинт. Вызов модели может пройти нормально, но бизнес-шаг между вызовами все равно должен жить отдельно: в Redis, в базе или в журнале событий.
После рестарта воркера обычно ломаются три вещи. Пропадает текущий шаг, если его не записали в постоянное хранилище. Теряются временные флаги вроде "ждем одобрения до 18:00". Исчезает локальная память о том, был ли уже выполнен внешний вызов.
Дубли после таймаута появляются еще тише. Один сервис отправил запрос, не дождался ответа за 30 секунд и повторил его. Первый запуск мог успеть сделать половину работы, но подтверждение о завершении потерялось. Второй запуск берет ту же задачу и снова отправляет письмо, создает вторую запись или повторно вызывает внешний API.
На практике источник потери состояния почти всегда один: шаг есть в логике кода, но его нет как записи, которую можно перечитать после сбоя. Пока задача живет секунды, это не так заметно. Как только появляются паузы, ручные решения и повторный запуск, дыры быстро выходят наружу.
Что агент должен помнить
Истории чата мало. Агенту нужен рабочий контекст: что он уже сделал, где остановился и что можно повторить без лишних действий.
Сначала сохраните вход задачи в том виде, в котором агент его получил. Рядом положите версию промпта. Через неделю команда может поменять инструкцию или схему ответа модели, и без этой пары будет трудно понять, почему новый результат не совпал со старым.
Дальше идет ход выполнения: текущий шаг, статус задачи и ответственный. Статусы лучше держать простыми: создана, в работе, ждет одобрения, завершена, ошибка. Ответственный тоже нужен явно. Иначе после паузы никто не поймет, кто должен нажать кнопку, проверить документ или разобрать сбой.
Отдельно храните следы внешних действий. Если агент уже отправил запрос во внешнюю систему, загрузил файл или написал сообщение, сохраните их идентификаторы. Это защита от дублей. Без них повторный запуск легко отправит письмо второй раз, создаст еще одну заявку или повторно спишет деньги.
Обычно хватает такого набора: входные данные и версия промпта, текущий шаг и статус, владелец задачи, идентификаторы запросов к внешним API, файлов и сообщений, пользователь или группа для следующего одобрения, причина ошибки и время последней попытки.
Последние два поля часто забывают. Зря. Если шаг упал, агент должен помнить не только сам факт ошибки, но и ее причину: таймаут, пустой ответ, отказ внешнего сервиса, неверный формат. Время последней попытки тоже нужно сохранить, иначе легко получить бесконечный цикл повторов каждые пару секунд.
Если команда вызывает модели через шлюз вроде AI Router, полезно хранить идентификатор модельного запроса, выбранную модель и служебные метки для сверки ответа и аудита. Это не украшение схемы, а обычная страховка, когда нужно повторить вызов или разобрать спорный случай.
Хорошее состояние отвечает на три вопроса: что агент знал на старте, что он уже сделал и что должно случиться дальше. Если на любой из них нет точного ответа, пауза и повторный запуск быстро превращаются в ручной разбор.
Когда хватает Redis
Redis подходит для состояния, которое живет недолго и читается часто. Если агент делает несколько шагов подряд, ждет ответ сервиса 30 секунд или ставит паузу на ручное подтверждение на 10-20 минут, этого обычно достаточно.
Такой вариант удобен, когда воркеру нужно быстро взять контекст, обновить его и перейти к следующему шагу без лишних запросов в основную базу. Это хорошо работает там, где задержка важнее, чем подробная история старых действий.
Где Redis удобнее всего
Redis особенно полезен, когда в одном месте у вас уже есть очереди, блокировки и TTL. Там же можно держать текущее состояние шага, временный результат вызова модели, флаг блокировки, таймер жизни состояния и короткий счетчик повторных попыток.
Это подходит для "горячего" состояния, которое должно быть рядом с воркером. Например, агент в контакт-центре собрал данные, отправил запрос в LLM через шлюз, получил черновик ответа и ждет быстрое одобрение оператора. Пока пауза короткая, Redis обычно проще и быстрее, чем отдельная схема в БД.
Еще один плюс - TTL. Можно сразу задать срок жизни для промежуточных данных и не чистить их вручную. Для временных сессий, rate limits, дедупликации задач и коротких ретраев это очень удобно.
Но у Redis есть жесткая граница. Если вы не делаете снимки состояния или не пишете события в постоянное хранилище, история исчезает слишком легко. После сбоя вы часто знаете только текущее значение, а не то, почему агент к нему пришел.
Долгие ожидания тоже быстро создают проблемы. Если задача может зависнуть на день, неделю или требует поиска по старым запускам, Redis становится неудобным. Сложные выборки, аудит, сравнение версий состояния и разбор спорных случаев лучше живут в БД или в событийном журнале.
Простое правило такое: если состояние короткоживущее, часто читается и не требует полной истории, Redis закрывает задачу без лишней сложности.
Когда лучше обычная БД
Обычная БД выигрывает там, где задача живет не минуты, а дни. Агент делает шаг, потом ждет человека, потом снова продолжает работу. Для такого процесса Redis уже слишком временный, а событийный журнал еще может быть лишним.
Если в процессе участвуют сотрудники, таблицы дают понятную модель. Есть запись задачи, статус, ответственный, время последнего шага, причина паузы. Менеджер открывает список и сразу видит, что зависло на согласовании, что вернулось на доработку, а что можно запускать дальше.
Это часто самый спокойный вариант. Вы привязываете состояние к понятному бизнес-объекту: заявке, тикету, заказу, анкете. У объекта есть текущий статус, номер шага, данные для продолжения и связь с тем, кто должен принять следующее решение. После сбоя система читает эту запись и продолжает работу с нужного места.
У БД есть еще один плюс: с ней проще строить интерфейсы и отчеты. Если оператору, менеджеру или службе поддержки нужно видеть текущее состояние процесса, таблицы подходят лучше всего. Там легко показать фильтры по статусам, просроченным одобрениям, ошибкам и владельцам.
Но и здесь есть ограничение. Одна строка с текущим статусом не объясняет, как система к нему пришла. Для многих задач этого хватает. Для спорных решений, повторных запусков и аудита - уже нет. Тогда рядом с БД обычно появляется журнал событий или хотя бы отдельная таблица истории.
Если у вас длинный бизнес-процесс, ручные решения и понятный объект, вокруг которого все строится, обычная БД почти всегда будет хорошим первым выбором.
Когда нужен событийный журнал
Событийный журнал нужен там, где текущее состояние само по себе ничего не объясняет. Важна вся цепочка действий: когда агент получил задачу, какой шаг выполнил, где остановился, кто вмешался вручную и что случилось после повторного запуска.
Вместо одной строки со статусом вы храните последовательность событий: заявка создана, документ проверен, задача ушла на одобрение, оператор изменил решение, агент повторно запустил шаг. Для процессов с паузами это часто удобнее, чем пытаться угадать прошлое по последнему значению в записи.
Если после сбоя нужно восстановить задачу, журнал сильно упрощает работу. Система может проиграть события заново и собрать состояние на любой момент. Это полезно и в спорных случаях. Когда команда разбирает ошибку или жалобу, ей не приходится верить последнему статусу на слово.
Где журнал оправдан
Журнал особенно полезен, когда в процессе есть ручное одобрение или отклонение, один и тот же шаг иногда запускают повторно, нужно разбирать спорные решения по истории действий или важны аудит-логи с точным временем каждого изменения.
Пример простой. Агент обрабатывает заявку, запрашивает данные из внешнего сервиса и ставит задачу на ручную проверку. Через 8 часов сотрудник меняет решение, а ночью внешний сервис присылает исправленный ответ. Если хранить только текущее состояние, вы увидите финал. Если есть журнал, вы увидите весь маршрут заявки и поймете, почему агент пошел именно так.
У этого подхода есть цена. Если читать состояние только из журнала, каждая загрузка со временем дорожает. У длинного процесса могут накопиться сотни или тысячи событий, и собрать объект с нуля станет медленно. Поэтому рядом почти всегда нужен снимок состояния. Журнал хранит историю, а снимок дает быстрый доступ к текущей версии.
Объем тоже растет быстро. Это особенно заметно в LLM-сценариях, где агент пишет много промежуточных шагов, ответов моделей и служебных отметок. Срок хранения лучше задать заранее: что держать месяц, что полгода, а что можно убрать в архив.
Событийный журнал стоит брать для задач, где важны replay после сбоя, проверяемая история и точное восстановление состояния. Для короткого процесса он часто слишком тяжелый.
Как выбрать схему без лишней сложности
Выбирать хранилище состояния лучше не по моде, а по сроку жизни задачи и цене ошибки. Если процесс живет 30 секунд, требования одни. Если заявка может ждать одобрения два дня и потом продолжиться, схема уже нужна другая.
Сначала ответьте на три вопроса: сколько живет один запуск, кто может остановить или одобрить шаг и нужно ли потом точно восстановить ход работы. Эти ответы быстро отсеивают лишние варианты.
Простой порядок выбора
Если задача живет минуты или часы, а после сбоя вам достаточно продолжить с последнего шага, часто хватает Redis. Он удобен для горячего состояния: текущий шаг, таймаут, счетчик попыток, временные данные.
Если задача живет днями, в нее смотрят люди, а статусы нужны в интерфейсе и отчетах, обычно лучше обычная БД. Там проще хранить заявки, решения менеджера, время одобрения, комментарий и автора действия.
Если вам нужно знать не только текущее состояние, но и каждое изменение по порядку, нужен событийный журнал. Он полезен там, где важен точный replay. В банке, телекоме или госсекторе это не редкость.
На практике часто побеждает не один инструмент, а разделение ролей. Горячее состояние держат отдельно от истории. Тогда агент быстро читает текущее состояние, а аудит и разбор инцидентов идут по отдельной записи событий.
Если нужно совсем короткое правило, оно выглядит так:
- Redis - для коротких пауз, блокировок и быстрого resume.
- БД - для долгих процессов, ручного одобрения и рабочих экранов.
- Журнал событий - для точного replay и аудита.
- Смешанная схема - когда нужен и быстрый доступ, и полная история.
Начинать лучше с малого. Часто хватает полей run_id, status, current_step, updated_at, retry_count, approved_by и версии записи. Важнее не число таблиц, а понятные правила обновления: кто меняет статус, как агент понимает, что шаг уже выполнялся, и что делать при повторном запуске.
Если вы гоняете запросы через AI Router и можете менять провайдера или модель без смены SDK и кода, состояние процесса все равно лучше хранить вне слоя модели. Тогда смена маршрута не ломает паузы, одобрение и повторный запуск.
Пример с заявкой и ручным одобрением
Представьте заявку на кредитный лимит или корпоративную закупку. Агент принял форму, проверил обязательные поля, нашел пустой ИИН или неверный формат телефона, попросил исправление и сохранил чистую версию данных. После этого он отправил заявку менеджеру на ручное одобрение.
Дальше процесс может зависнуть на несколько часов. Менеджер занят, ушел на встречу или отвечает только в конце дня. Если в этот момент держать все состояние только в памяти процесса, агент после перезапуска забудет, на чем остановился. Тогда он начнет путь заново, снова проверит форму и может повторно отправить уведомления.
В рабочей схеме роли разделены. Redis держит то, что живет недолго: таймер ожидания, блокировку на обработку, очередь на отправку напоминания. БД хранит текущее состояние заявки: статус, номер шага, нормализованные поля формы, того, кто должен одобрить заявку. Журнал событий пишет историю: "форма проверена", "заявка отправлена менеджеру", "одобрение получено", "скоринг завершился с ошибкой".
Когда менеджер нажимает "одобрить", система читает запись из БД и продолжает не с начала, а с нужного шага. Если следующий этап - скоринг, агент берет уже проверенные поля, вызывает скоринговый сервис и двигается дальше. Повторная валидация формы не нужна, потому что она уже зафиксирована.
Если скоринг упал из-за внешнего сервиса, команде не нужно прогонять весь сценарий заново. Они повторяют только этот шаг. БД показывает, что заявка уже одобрена и ждет результат скоринга. Журнал событий помогает понять, что именно случилось перед сбоем, и аккуратно перезапустить один участок процесса.
Этот пример хорошо показывает простую мысль. Redis удобен для быстрого ожидания и координации, БД держит текущее "где мы сейчас", а журнал нужен там, где важны разбор ошибок, аудит и точный повтор шага.
Ошибки, которые ломают повторный запуск
Проблемы редко начинаются в день запуска. Они всплывают позже, когда шаг упал, человек задержал одобрение на сутки, а процесс нужно поднять с того же места, а не запускать заново.
Чаще всего ломает не сама логика агента, а способ записи данных. Команда складывает все в один большой JSON, и поначалу это кажется удобным. Потом нельзя быстро понять, на каком шаге остановился процесс, кто дал одобрение, какой вход получил шаг и что именно надо пересчитать. Еще хуже то, что при смене схемы старые JSON-объекты превращаются в лотерею.
Надежнее хранить поля отдельно: статус процесса, номер шага, вход шага, итог шага, время обновления, версию схемы. Тогда повторный запуск идет по понятным правилам, а не по догадкам.
Еще одна частая ошибка - свалить состояние, кеш и аудит в одно место. Кеш живет недолго и может устареть. Аудит нужен для истории. Состояние нужно для текущего решения: продолжать, ждать или откатывать шаг. Если все это лежит в одной записи, агент легко принимает старый кеш за факт, а журнал превращается в мешанину из служебных и бизнес-событий.
На практике это выглядит так: агент видит статус "готово", хотя это был временный кеш ответа модели; повторный запуск берет старые данные одобрения, хотя пользователь уже отменил заявку; команда не может восстановить цепочку действий, потому что аудит перезаписали новым состоянием; после обновления кода старые процессы читаются неверно, потому что никто не сохранил версию схемы; один и тот же шаг срабатывает дважды, потому что у запроса нет идемпотентного ключа.
Без версии схемы и идемпотентного ключа повторный запуск быстро становится опасным. Агент может второй раз отправить письмо, повторно списать деньги или снова создать задачу в CRM. В системах с ручным одобрением это особенно неприятно: оператор уверен, что подтвердил действие один раз, а система делает его дважды.
TTL тоже часто используют не по делу. Если запись должна пережить паузу в несколько часов или дней, TTL нельзя считать архивом. Он годится для кеша, но не для состояния процесса. Иначе заявка просто исчезнет до того, как человек вернется к одобрению.
Есть и отдельная ловушка у событийного журнала. Команда пишет событие "шаг выполнен", но не фиксирует итог шага в текущем состоянии. В журнале все выглядит завершенным, а в рабочей записи пусто. После сбоя система уже не понимает, продолжать ли дальше, повторять шаг или ждать оператора.
Надежнее работает простая схема: отдельное текущее состояние, отдельный аудит, отдельный кеш, версия схемы в каждой записи и идемпотентный ключ на каждом шаге с внешним эффектом. Тогда повторный запуск не гадает, а делает ровно одно понятное действие.
Быстрая проверка перед запуском
Перед продакшеном не спорьте о схеме хранения на уровне идей. Ее проверяют простыми сбоями и повторами. Пять коротких тестов обычно показывают больше, чем длинная диаграмма.
- Перезапустите воркер посреди задачи и посмотрите, вернется ли агент на нужный шаг, а не начнет все сначала.
- Остановите сценарий на ручном одобрении и проверьте, кто именно видит статус: оператор, сервис, админ-панель, лог задач.
- Запустите один и тот же шаг два раза подряд с тем же входом и проверьте, создались ли дубли.
- Просмотрите историю состояния глазами безопасника: где лежат персональные данные, кто видит аудит, когда записи удаляются.
- Посчитайте объем хранения заранее: число задач в день, средний размер шага, вложения, логи, снимки состояния.
Первый тест быстро показывает, можно ли вообще доверять вашему источнику правды. Если после перезапуска задача теряет прогресс, Redis у вас, скорее всего, работает как временная память, а не как надежное хранилище. Для очереди это нормально. Для долгой заявки с паузой на одобрение - уже нет.
Пауза на согласовании часто ломает процесс тише всего. Агент ждет решения, но разные люди видят разную картину: у оператора шаг "на проверке", у воркера таймаут, в базе пусто. Если статус нельзя найти за 10 секунд, в бою начнется ручной разбор.
Повтор шага дважды нужен не для галочки. Он сразу ловит отсутствие идемпотентности. Если один и тот же шаг создает две заявки, два письма или два списания, проблема не в модели. Проблема в том, что система не умеет отличать повторный запуск шага от новой работы.
С данными лучше быть скучным и строгим. Даже если вызовы к моделям идут через AI Router, где есть хранение данных внутри страны, маскирование PII, аудит-логи и rate-limits на уровне ключа, свое хранилище все равно нужно проверять отдельно. Часто сырые поля остаются в таблице состояния, в payload события или в отладочном логе воркера.
Оценка объема тоже быстро отрезвляет. Журнал событий растет очень быстро, если писать каждый промпт, ответ модели и промежуточный снимок. Разница между "храним все" и "храним только смену статуса плюс итог" иногда дает не проценты, а кратный рост счета за месяц.
Если эти проверки проходят без ручных костылей, схема уже похожа на рабочую. Если хотя бы один тест падает, лучше чинить это до запуска, а не после первой зависшей заявки.
Что делать дальше
Не пытайтесь сразу собрать память для всего агента. Возьмите один сценарий, где ошибка дорого стоит, но объем еще можно держать в голове. Хороший стартовый вариант - заявка, которая ждет ручного одобрения, а потом продолжает работу с того же места.
До первой строчки кода опишите состояние на бумаге или в таблице. Не общими словами, а по полям: статус, текущий шаг, входные данные, кто одобрил, когда истекает пауза, что уже отправили во внешние системы, что можно запускать повторно. Если поле не названо заранее, потом оно почти всегда появляется в спешке и ломает повторный запуск.
Для старта обычно достаточно пяти действий:
- выбрать один пилотный сценарий, а не весь агент сразу;
- перечислить поля состояния и события, которые меняют задачу;
- решить, где лежит быстрое состояние, а где история решений и действий;
- отметить, что должно пережить сбой, паузу и ручное одобрение;
- проверить, какие данные нужны для аудита.
Часто хватает простой схемы. Текущее состояние задачи, статус и связи с бизнес-объектом лучше держать в обычной БД. Быстрое временное состояние, блокировки и короткие таймауты можно вынести в Redis. Полную историю стоит хранить там, где ее легко проверить при споре, сбое или внутреннем разборе.
Для команд в Казахстане есть еще один практический фильтр: сразу проверьте, где будут лежать данные, нужны ли аудит-логи, как вы маскируете PII и какие записи нельзя выносить за пределы страны. Эти требования лучше встроить в схему состояния в самом начале, чем прикручивать потом поверх уже работающего процесса.
Если агент ходит в разные LLM через шлюз вроде AI Router, сохраняйте рядом с задачей идентификатор каждого модельного запроса. Если команда работает через OpenAI-совместимый endpoint вроде api.airouter.kz и меняет только base_url, это не отменяет базового правила: источник правды о процессе должен жить отдельно от модели. Тогда проще менять провайдера, разбирать сбои и безопасно перезапускать отдельные шаги.
Если нужен первый рабочий вариант без лишней сложности, начните с БД как главного источника правды и добавьте Redis только там, где без него уже больно. После одного пилота станет ясно, нужен ли вам событийный журнал или пока рано.
Часто задаваемые вопросы
Чем состояние агента отличается от контекста модели?
Контекст помогает модели продолжать диалог, но не хранит статус задачи, таймеры, одобрение и факт внешнего действия. Состояние процесса держите отдельно, чтобы после паузы или перезапуска агент вернулся на нужный шаг, а не начал все заново.
Что нужно сохранять в состоянии в первую очередь?
Сначала сохраните вход задачи, версию промпта, status, current_step и того, кто отвечает за следующий шаг. Рядом запишите идентификаторы внешних запросов, причину ошибки и время последней попытки, чтобы агент не дублировал действия и не зацикливал ретраи.
Когда Redis действительно хватает?
Redis берите для коротких пауз, частых чтений, блокировок и быстрых повторов. Он хорошо держит горячее состояние на минуты или десятки минут, но плохо подходит для долгой истории, аудита и задач, которые живут днями.
Когда лучше выбрать обычную БД?
БД лучше работает там, где процесс живет долго и в него смотрят люди. Если у вас есть заявка, тикет или заказ со статусом, владельцем и ручным одобрением, таблицы дают понятную точку правды и упрощают интерфейсы, отчеты и поддержку.
В каких случаях без журнала событий уже не обойтись?
Журнал нужен, когда одного текущего статуса мало и вам важна вся цепочка действий. Он помогает восстановить ход процесса после сбоя, разобрать спорный случай и точно понять, кто и когда изменил решение.
Обычно журнал держат рядом со снимком текущего состояния. Так система быстро читает текущее значение и не пересобирает объект с нуля при каждом запросе.
Можно ли хранить все состояние в одном JSON?
Для прототипа это пережить можно, но в рабочем процессе один большой JSON быстро мешает. Команда теряет быстрый ответ на простые вопросы: где остановился процесс, кто одобрил шаг, что уже ушло во внешнюю систему и какую схему читает текущий код.
Надежнее хранить важные поля отдельно и добавлять версию схемы в каждую запись.
Как избежать дублей после таймаута или рестарта?
Сохраняйте идентификатор внешнего действия до повтора шага и проверяйте его перед новым вызовом. Если письмо, платеж или запись в CRM уже получили свой идентификатор, повторный запуск должен забрать старый результат, а не делать второе действие.
Зачем хранить версию промпта и версию схемы?
Версия промпта помогает понять, почему вчера агент дал один результат, а сегодня другой. Версия схемы нужна не меньше: без нее новый код легко неверно прочитает старую запись и сломает повторный запуск.
Если я работаю через AI Router, отдельное хранилище состояния уже не нужно?
Нет, не заменяет. Шлюз решает вызовы моделей, маршрутизацию и учет модельных запросов, но не хранит статус вашей заявки, ручное одобрение и внешние бизнес-действия.
Держите источник правды о процессе отдельно, а рядом сохраняйте идентификатор модельного запроса. Так команда спокойно меняет модель или провайдера и не ломает сам процесс.
С чего начать, если не хочется строить сложную схему сразу?
Начните с одного сценария, где есть пауза и цена ошибки заметна, например с заявки на ручное одобрение. Возьмите БД как главный источник правды, добавьте Redis только для блокировок и коротких таймаутов, а журнал подключайте после пилота, если вам уже не хватает истории.
Перед запуском перезапустите воркер посреди задачи, задержите одобрение и повторите один и тот же шаг с тем же входом. Эти проверки быстро покажут, держит ли схема сбой и не создает ли дубли.