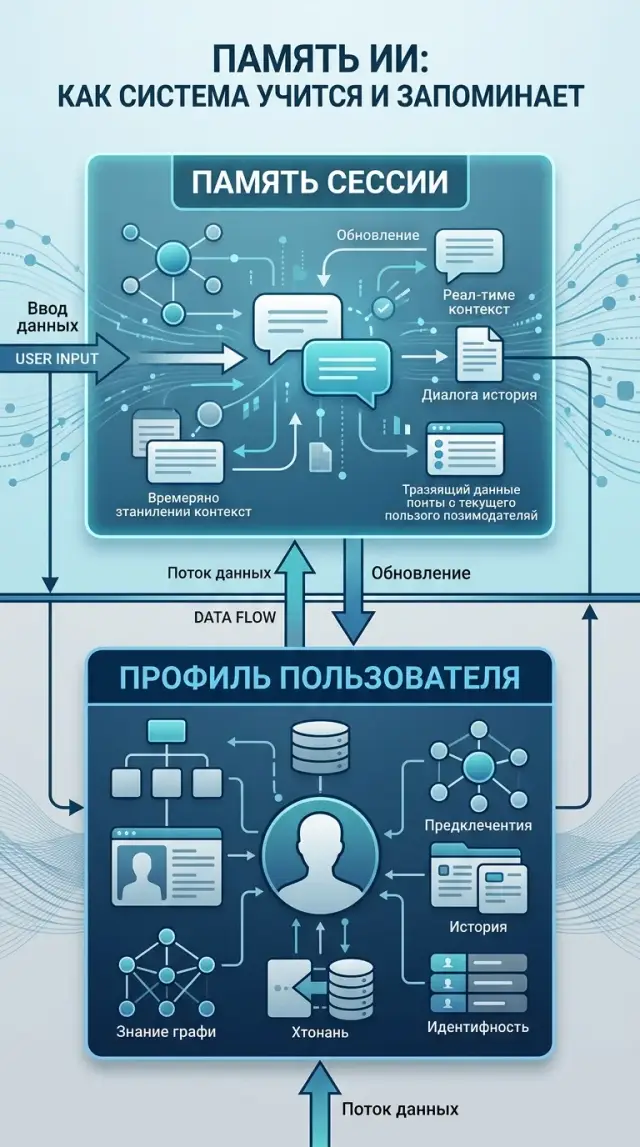
Сессионный контекст и профиль пользователя: как разделить
Сессионный контекст и профиль пользователя нужно хранить отдельно: так ассистент не путает разовые детали, предпочтения, историю и личные данные.
Откуда берется путаница
Проблема начинается, когда команда складывает в одну корзину все, что сказал пользователь. Для модели это просто текст из прошлого диалога. Для продукта это уже два разных слоя: временный контекст сессии и данные, которые можно хранить дольше.
Самый частый сбой выглядит просто. Пользователь пишет: "Сегодня отвечай коротко, я на встречах". Это просьба на один день, а иногда и на один час. Но если система сохраняет ее как постоянное предпочтение, ассистент и через неделю будет обрезать ответы, хотя человек уже ждет нормальную глубину.
Так временная деталь превращается в правило. То же происходит с фразами вроде "я сейчас в Алматы", "готовлю отчет для банка" или "показывай примеры на Python". Внутри конкретной сессии это полезно. В долгой памяти пользователя это чаще шум.
Длинный чат делает ошибку заметно хуже. Модель много раз видит один и тот же временный факт и начинает считать его устойчивым. Если сверху есть суммаризация, нюансы теряются еще быстрее: слова "сейчас", "на этой неделе" и "для этого проекта" исчезают, а голое утверждение остается.
Из-за этого страдает качество ответа. Ассистент тянет в новый диалог старые ограничения, не задает нужный уточняющий вопрос и строит ответ вокруг факта, который уже не актуален. Главная ошибка здесь простая: система запомнила не то и забыла, что это было временно.
Пользователь замечает такие сбои сразу. Ассистент упрямо держится за старый тон, подставляет устаревшую роль или город, советует то, что подходило вчера, и иногда даже спорит с человеком его же старыми словами.
Хуже всего не одна неверная реплика, а ощущение, что ассистент "прилип" к случайной детали. После этого доверие падает быстро. Человек либо каждый раз переписывает правила заново, либо просто отключает память.
В LLM-приложениях такая путаница обычно рождается не в модели, а в логике хранения данных. Если система не различает "факт на сейчас" и "факт надолго", длинная память быстро портит даже хороший диалог.
Что хранить только в сессии
Сессия нужна для текущей задачи. Все, что помогает ответить сейчас, но не должно влиять на будущие диалоги, лучше держать только там.
Первое правило простое: цель разговора почти всегда временная. Если человек пишет "сделай краткое резюме звонка для директора" или "сравни два договора и найди риск по пункту 4", это задача на один диалог. В профиле ей не место.
То же касается разовых уточнений и новых вводных. Пользователь может попросить более сухой тон, учесть свежий комментарий юриста или временно не использовать таблицы. Ассистенту это нужно прямо сейчас. Если перенести такие детали в долгую память, следующий разговор легко уйдет в сторону.
Обычно в сессии живут:
- текущая цель диалога
- одноразовые ограничения и уточнения
- файлы, номера заявок, суммы и даты из этого чата
- черновики, рабочие гипотезы и промежуточные выводы
Отдельная группа - факты, привязанные к конкретному разговору. Пользователь загружает PDF, пишет номер заявки 48152, указывает сумму 1 250 000 тенге и просит проверить расхождение с актом. Ассистенту надо помнить это до конца задачи. После завершения эти данные уже не описывают самого пользователя. Это детали кейса, а не часть профиля.
Черновики и допущения тоже нельзя уносить в долгую память. Если ассистент предположил, что документ относится к закупке, или сделал промежуточный вывод по неполному набору данных, это рабочее состояние, а не факт. Иначе старые догадки начнут всплывать в новых ответах.
На практике удобно держать для сессии отдельное хранилище с session_id, коротким TTL и явной очисткой после закрытия задачи. Даже если приложение работает через единый LLM-шлюз, логика не меняется: профиль хранит устойчивые свойства пользователя, а сессия - то, что умрет вместе с текущим запросом.
Хороший тест звучит так: если факт теряет смысл сразу после ответа, оставляйте его в сессии.
Что хранить в профиле пользователя
В профиль попадают факты, которые живут дольше одного диалога и помогают не начинать разговор с нуля. Если информация останется полезной через неделю и не зависит от текущей задачи, ей место в профиле.
Сюда обычно входят имя, форма обращения, роль и язык общения. Если человек просит называть его "Алия", пишет как руководитель поддержки и всегда общается на русском, ассистенту не нужно уточнять это в каждом чате. Роль тоже влияет на ответ: одному нужен короткий итог для решения, другому - пример с API и логами.
Постоянные предпочтения по форме ответа тоже можно хранить, но только если пользователь сам их задал или повторил несколько раз. Разовый запрос вроде "сделай покороче" не стоит сразу превращать в правило на будущее.
Часовой пояс и допустимые каналы связи лучше держать рядом с профилем, а не в сессии. Это влияет на напоминания, отчеты, окна тишины и время эскалации. Если пользователь живет по времени Алматы и согласен получать уведомления только в корпоративный чат, система не должна писать ему в другой канал только потому, что он однажды там ответил.
Отдельный слой профиля - согласия, запреты и рабочие ограничения. Это не вкусы пользователя, а правила, которые нельзя нарушать:
- согласие на обработку и сохранение истории
- запрет на использование персональных данных без маскирования
- разрешенные каналы связи и часы отправки
- лимиты на автоматические действия без подтверждения
- требования к стилю ответа, если они закреплены политикой команды
Для корпоративного помощника профиль может хранить язык пользователя, его роль в компании, часовой пояс, правило маскировать PII и запрет отправлять ответы во внешние мессенджеры. А вот фразы вроде "я сегодня дежурю" или "готовлю отчет до 17:00" должны остаться в сессии.
Простое правило такое: профиль хранит устойчивые свойства человека и его границы. Сессия хранит текущую ситуацию.
Как разбирать спорные случаи
Ошибки чаще всего прячутся в серых зонах. Не всегда ясно, что делать с фразами вроде "я сейчас в поездке", "мне удобнее короткие ответы" или "до пятницы я готовлю отчет". Если команда сразу сохранит такие факты в профиль, ассистент начнет путать разовую ситуацию с привычкой.
Полезно проверять каждый спорный факт одними и теми же вопросами:
- Переживет ли этот факт конец диалога? Если человек пишет "сегодня я работаю из дома", это почти всегда часть текущей сессии. Если он просит всегда отвечать на русском, факт может жить дольше.
- Изменится ли он через день? Текущий проект, дедлайн, роль на встрече и настроение меняются быстро. Такие данные лучше держать рядом с диалогом.
- Нужно ли подтверждение пользователя? Имя для обращения, постоянный язык и формат ответа лучше сохранять только после прямого согласия. Догадка ассистента не равна факту.
- Что случится, если система ошибется? Лишний факт в сессии обычно исчезнет сам. Ошибка в профиле вернется в новом разговоре и будет раздражать сильнее.
Если ответ неочевиден, оставьте факт временным. Это безопаснее. Через день ассистент может спросить снова и проверить, остался ли факт актуальным.
Хорошо помогает срок жизни для спорных записей. Например, предпочтение "пиши короче" можно сохранить на несколько дней, а потом попросить подтвердить заново. А заметку "сейчас согласую бюджет" лучше удалить после задачи или в конце суток.
Такие правила заметно упрощают систему. Команды часто винят модель, хотя проблема сидит не в ответах, а в памяти. Для банка, ритейла или внутреннего помощника ошибка выглядит одинаково: ассистент помнит то, что должен был забыть.
Как разделить данные по шагам
Если команда не размечает данные с первого дня, профиль быстро превращается в склад случайных фраз. Чтобы сессионный контекст и профиль пользователя не смешивались, каждому полю нужны три вещи: смысл, срок жизни и владелец обновления.
- Выпишите все поля, которые ассистент видит или может получить из ваших систем. Обычно сюда входят текст текущего диалога, язык, роль пользователя, история заказов, настройки тона, местоположение, статус заявки и заметки оператора.
- Для каждого поля задайте простой вопрос: "это правда только сейчас или почти всегда?" Фраза "хочу ответ покороче в этом чате" живет в сессии. Фраза "предпочитаю русский язык" может жить в профиле.
- Назначьте срок жизни заранее. У сессии это минуты, часы или один диалог. У профиля - недели, месяцы или срок до ручного изменения, если речь о подтвержденных данных.
- Запишите, кто может менять профиль. Лучше, когда профиль обновляет сам пользователь, CRM-событие или явное правило. Ассистент не должен переносить в профиль случайную реплику вроде "сегодня я в Алматы".
- Проверьте профиль на мусор. Уберите все, что быстро стареет: текущую задачу, временный приоритет, разовую скидку, настроение, место из одной поездки.
После такой сортировки удобно завести две отдельные схемы хранения. Сессия держит короткий живой слой, который нужен прямо сейчас. Профиль хранит устойчивые факты и предпочтения, которые не меняются от сообщения к сообщению.
Если поле вызывает спор, не спешите нести его в профиль. Сначала оставьте его в сессии на пару недель и посмотрите, меняется ли оно часто. Это проще, чем потом чистить профиль и объяснять пользователю, почему ассистент запомнил лишнее.
Если вы работаете через AI Router на airouter.kz или другой LLM-шлюз, не делайте шлюз местом, где живет профиль. Профиль лучше держать в вашей системе, рядом с правилами доступа, аудитом и маскированием PII. В запрос к модели отправляйте только тот срез данных, который правда нужен для ответа.
Хороший признак очень простой: инженер смотрит на любое поле и за 10 секунд говорит, где оно хранится, сколько живет и кто может его менять.
Пример на одном диалоге
Разницу проще всего увидеть на живом примере. Один и тот же клиент банка может оставить часть данных только на время чата, а часть настроек держать между разговорами.
Представим диалог с поддержкой по платежу. Клиент уже раньше выбрал русский язык и попросил обращаться на "вы". Это профиль. А сегодня у него другая просьба: отвечать очень коротко, потому что он пишет с телефона между встречами. Это уже сессия.
Диалог может выглядеть так:
"Здравствуйте. Отвечайте, пожалуйста, коротко. Мне нужно проверить платеж по заявке 48127 на 245 000 тенге."
Ассистент отвечает по-русски и на "вы", потому что знает постоянные предпочтения клиента. Но просьбу "коротко" он хранит только внутри текущего разговора. Номер заявки 48127 и сумма 245 000 тенге тоже живут только в сессионном контексте. Они нужны, чтобы довести задачу до конца, и не нужны в следующем чате.
Через десять минут клиент пишет:
"Платеж нашелся?"
Ассистент понимает, о каком платеже речь, потому что сессия еще открыта. Ему не надо заново спрашивать номер заявки и сумму. Это удобно и не захламляет профиль лишними деталями.
Теперь чат закрыли. После этого система удаляет временные факты: номер заявки, сумму платежа и просьбу отвечать короче только сегодня. В профиле остаются устойчивые вещи:
- язык ответа
- форма обращения
- при необходимости часовой пояс или формат даты
На следующий день клиент начинает новый диалог: "Добрый день, хочу узнать статус карты".
Ассистент снова отвечает по-русски и на "вы". Но он уже не должен автоматически писать слишком коротко и не должен помнить старую заявку 48127. Если эти данные всплывают в новом чате без причины, значит сессионный контекст и профиль у вас смешаны.
Это правило работает почти всегда: разовый факт нужен, пока задача не завершена. Повторяющееся предпочтение можно хранить дольше. Такое разделение снижает риск ошибок и помогает аккуратнее обращаться с пользовательскими данными.
Где команды ошибаются чаще всего
Самая частая проблема не в модели, а в том, что команда делает один общий "мешок памяти". Туда попадает и история текущего диалога, и привычки пользователя, и настройки аккаунта. Через пару недель никто уже не понимает, почему ассистент вдруг помнит лишнее.
Первая ошибка проста: в профиль записывают почти все из переписки. Пользователь один раз сказал "я в командировке до пятницы" или "сейчас отвечай короче", а система сохраняет это как постоянный факт. Так временная деталь живет дольше, чем нужно, и ломает следующие разговоры.
Вторая ошибка связана со сроком жизни данных. У временных фактов нет TTL, даты истечения или явного правила удаления. Из-за этого сессия и профиль смешиваются, хотя у них разная работа: один слой помогает вести текущий разговор, второй хранит устойчивые предпочтения и важные настройки.
Еще одна проблема - хранение личных данных без ясной причины. Если задачу можно выполнить без даты рождения, личного номера или адреса, не надо тащить это в память. Это особенно опасно там, где есть аудит-логи и строгие требования к данным: лог для контроля и профиль пользователя - не одно и то же.
Хороший пример ошибки такой. Пользователь пишет: "Я сегодня болею, перенеси напоминание и не звони". Фраза "не звони" может относиться к настройке канала связи, если человек повторяет это не раз. Фразу "сегодня болею" нельзя отправлять в долгую память без очень веской причины. А "перенеси напоминание" вообще относится к текущему действию, а не к профилю.
Часто у пользователя нет и способа исправить профиль. Система что-то запомнила, но человек этого не видит и не может удалить запись. Тогда ошибка живет месяцами, а команда спорит с моделью, хотя сломан обычный слой хранения.
Тревожные признаки обычно такие:
- ассистент вспоминает случайные детали из старых чатов
- одинаково хранит предпочтения, историю и аккаунтные настройки
- не удаляет временные данные автоматически
- копит персональные данные "на всякий случай"
- не показывает пользователю, что именно записано в профиль
Если у вас есть LLM-шлюз, журнал запросов и метки безопасности тоже стоит держать отдельно. В AI Router, например, аудит-логи, маскирование PII и rate limits решают задачи контроля и соответствия правилам. Эти данные не должны тихо превращаться в "память ассистента" о человеке.
Самая здравая схема обычно скучная: сессия живет отдельно, профиль отдельно, настройки аккаунта отдельно, логи отдельно. Чем меньше серых зон между этими слоями, тем реже ассистент ведет себя странно.
Быстрый чек-лист перед запуском
Перед релизом проверяйте не только модели, но и правила памяти. Странные ответы чаще появляются не из-за промпта, а из-за того, что сессия и профиль смешаны в одной схеме данных.
Сначала разберите каждое поле, которое ассистент читает или записывает. У любого поля должны быть понятный источник и срок жизни. Если источник неясен, ассистент не должен опираться на такой факт. Если срок жизни не задан, временная информация почти всегда остается дольше, чем нужно.
- Разовые факты храните только в сессии. Фразы вроде "сегодня я в Алматы", "ответь короче" или "помоги выбрать тариф на этот месяц" не должны попадать в профиль.
- Постоянные данные держите отдельно. Имя, язык общения, часовой пояс, рабочую роль или согласие на формат уведомлений можно хранить дольше, если пользователь это подтвердил.
- Очистку сессии задайте простым правилом: после 30 минут бездействия, после завершения задачи или после явного сброса чата.
- Дайте пользователю место, где он видит постоянные данные и может их исправить или удалить.
- В журналах должно быть видно, почему ассистент сделал вывод: факт пришел из текущего диалога, из профиля или из внешней системы.
Есть простой тест перед запуском. Возьмите один реальный диалог и спросите: если человек вернется через неделю, что ассистент имеет право помнить без нового запроса? Все, что неловко показать на отдельном экране профиля, лучше не хранить как долгую память пользователя.
Если вы строите LLM-приложение на нескольких моделях, правило не меняется. Даже если API-шлюз помогает с маршрутизацией запросов, аудитом и хранением данных внутри страны, разделение памяти все равно нужно задавать в самом приложении.
Еще один полезный тест делает поддержка или QA. Человек открывает журнал ответа и пытается восстановить цепочку: какой факт откуда взят, кто его записал и когда он истечет. Если это нельзя понять за минуту, после запуска начнутся лишние споры и ручные разборы.
Что делать дальше
Начните с простого: разделите память на два хранилища. Одно держит только то, что нужно для текущего диалога, второе хранит профиль пользователя и живет дольше. Пока сессионный контекст и профиль лежат в одном месте, ошибки будут повторяться.
На первом этапе не нужна сложная схема. Достаточно ввести явные поля, срок жизни записей и правило, кто может читать и менять каждую часть памяти. Даже такое базовое разделение обычно убирает большую часть странных ответов.
Минимальный план
- Заведите отдельное хранилище для сессии и отдельное для профиля.
- Включите логи чтения и записи, чтобы команда видела, откуда ассистент взял факт.
- Добавьте простые правила очистки: сессия удаляется по TTL или после завершения задачи, профиль обновляется только после подтвержденного сигнала.
- Проверьте, какие поля нельзя хранить в открытом виде, и замаскируйте PII до записи.
Логи нужны не только для разбора ошибок. Они быстро показывают, когда модель записывает в профиль случайную фразу из переписки или тянет в новый диалог старую деталь, которая уже не нужна. Хорошее правило простое: если факт нельзя объяснить одним предложением, почему он должен жить дольше сессии, не пишите его в профиль.
С требованиями к данным лучше разобраться до запуска, а не после первого инцидента. Проверьте, где физически хранятся записи, кто имеет к ним доступ, как вы удаляете данные по запросу и как маскируете персональную информацию в логах. Для банков, телекома, госсектора и healthcare это обычная часть архитектуры.
Если вы выводите LLM в продакшен, полезно сразу продумать слой маршрутизации и контроля, а не только саму модель. Для команд в Казахстане и Центральной Азии в этом месте часто используют AI Router: он дает единый OpenAI-совместимый API, а также помогает с аудит-логами, маскированием PII и требованиями к хранению данных внутри страны. Но саму границу между сессией и профилем все равно должно задавать ваше приложение.
Если коротко, порядок такой: сначала разделите хранилища, потом включите наблюдаемость, затем проверьте правила хранения. После этого ошибки памяти перестают быть загадкой и становятся обычной инженерной задачей.
Часто задаваемые вопросы
Чем сессионный контекст отличается от профиля пользователя?
Сессия хранит то, что нужно для текущего разговора: задачу, временные ограничения, файлы, суммы, номера заявок. Профиль хранит то, что полезно и через неделю: язык, форму обращения, роль, часовой пояс, согласия и запреты.
Если факт теряет смысл сразу после ответа, оставляйте его в сессии. Если он помогает в новых диалогах и не зависит от текущей задачи, храните его в профиле.
Что не стоит сохранять в профиль пользователя?
Не сохраняйте в профиль временные детали: «сегодня отвечай коротко», «я сейчас в Алматы», «готовлю отчет до вечера», номер заявки, сумму из текущего кейса, черновые выводы и догадки ассистента.
Такие данные быстро стареют. Если они попадут в профиль, ассистент начнет тянуть их в новые диалоги и будет ошибаться.
Когда можно записывать в профиль просьбу вроде «пиши короче»?
Сохраняйте такое предпочтение только после явного подтверждения или повторения в нескольких чатах. Один раз человек мог попросить короткий ответ просто потому, что писал с телефона или был на встрече.
Без подтверждения лучше держать это в сессии с коротким сроком жизни. Через несколько дней можно спросить заново.
Нужно ли ставить TTL для сессионных данных?
Да, без срока жизни временные факты почти всегда остаются дольше, чем нужно. Задайте простое правило: очищать сессию после завершения задачи, после явного сброса чата или через период бездействия.
Даже короткий TTL уже снижает число странных ответов. Ассистент реже тащит в новый диалог старые детали.
Как разбирать спорные случаи, когда неясно, сессия это или профиль?
Если сомневаетесь, оставьте факт временным. Потом проверьте три вещи: переживет ли он конец диалога, изменится ли через день и согласился ли пользователь хранить его дольше.
Смотрите и на цену ошибки. Лишняя запись в сессии обычно исчезает сама, а ошибка в профиле будет раздражать человека в каждом новом чате.
Где хранить номер заявки, сумму платежа и файлы из чата?
Такие данные живут в сессии до конца задачи. Они описывают текущий кейс, а не самого пользователя.
После закрытия чата удаляйте их или переносите только в те системы, где им место по процессу. В память ассистента на будущее их лучше не тащить.
Можно ли использовать аудит-логи как память ассистента?
Нет. Логи нужны для аудита, отладки и контроля доступа, а не для долгой памяти о человеке. Если смешать логи и память, ассистент начнет вспоминать лишнее.
Держите логи отдельно от профиля и отдельно от сессии. В памяти оставляйте только данные, которые правда нужны для ответа.
Кто должен обновлять профиль пользователя?
Лучше, чтобы профиль менял сам пользователь, CRM-событие или явное правило в приложении. Ассистент не должен сам записывать в профиль случайную фразу из переписки.
Так вы снижаете риск, что разовый факт станет постоянным. Заодно проще объяснить, откуда взялась каждая запись.
Как проверить перед запуском, что память настроена правильно?
Проведите простой тест на одном реальном диалоге. Спросите себя: что ассистент имеет право помнить через неделю без нового запроса?
Потом откройте журнал и проверьте, можно ли быстро понять источник каждого факта, кто его записал и когда он истечет. Если это неясно, схема памяти еще сырая.
Что делать, если ассистент уже запомнил лишнее?
Сначала очистите профиль от временных записей и отделите его от сессии. Потом введите правила записи: что живет только в чате, что требует подтверждения и что удаляется по TTL.
После этого дайте пользователю экран или настройку, где он видит постоянные данные и может их исправить. Если вы используете LLM-шлюз, профиль все равно храните в своей системе, а не в шлюзе.