Ретраи для LLM API: как не удвоить счёт при сбоях
Ретраи для LLM API помогают пережить сбои, но без лимитов и идемпотентности они быстро раздувают затраты. Разберём таймауты, паузы и проверки.
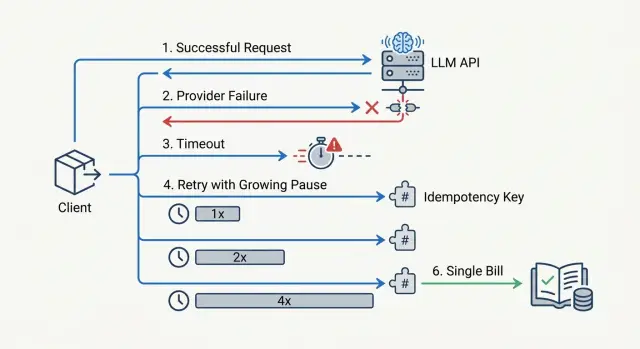
Почему ретраи быстро раздувают счет
У ретрая есть неприятная особенность: таймаут на вашей стороне не доказывает, что провайдер ничего не сделал. Запрос мог дойти до модели, генерация могла уже начаться, а ответ просто не успел вернуться вовремя. Если приложение в этот момент отправляет тот же промпт еще раз, вы получаете два платных вызова вместо одного.
В начале это кажется мелочью. Команда ставит таймаут 15 или 20 секунд, потом добавляет retry=3 "на всякий случай". На бумаге это защита от сбоев. На деле это часто прямой умножитель расходов.
Простой пример: бот отправил запрос на 8 000 входных токенов и ждет ответ. Провайдер отвечает медленно, приложение решает, что запрос завис, и шлет повтор. Первый вызов все же завершается, второй тоже доходит до модели. Пользователю нужен один ответ, а оплачиваются два прогона одного и того же промпта.
Хуже всего, когда повторы идут параллельно. Один воркер не дождался ответа, второй поднял ту же задачу из очереди, а балансировщик еще и перевел часть трафика на запасной маршрут. Один сбой быстро превращается в три или четыре вызова с одинаковым контекстом. Если промпты длинные, счет растет не на проценты, а в разы.
Без жесткого лимита попыток это заражает весь поток. Короткий сбой у провайдера совпадает с пиком нагрузки, и каждое новое сообщение начинает плодить дубли. Через несколько минут система тратит токены не на полезные ответы, а на борьбу с собственной логикой восстановления.
Даже если вы работаете через OpenAI-совместимый шлюз, проблема не исчезает. Решение о повторе почти всегда принимает ваш код, SDK или клиентский слой.
Поэтому ретраи нужно считать частью контроля затрат API, а не просто страховкой от ошибок. Идемпотентность, лимит попыток и аккуратные таймауты нужны не для порядка в конфиге. Они не дают одному сбою тихо удвоить счет в конце месяца.
Когда повторять запрос, а когда остановиться
Повтор нужен не для любой ошибки. Хорошее правило простое: повторяйте то, что похоже на временный сетевой сбой или перегрузку, и не повторяйте то, что сломано в самом запросе.
Обычно имеет смысл повторять обрыв TCP или TLS, сбой DNS, reset соединения, коды 429 и часть серверных ошибок вроде 500, 502, 503 и 504. С кодом 408 и клиентскими таймаутами нужно быть осторожнее. Сначала разберитесь, на каком этапе оборвался запрос. Если вы не знаете, дошел ли он до модели, слепой повтор опасен.
С кодами 400, 401 и 403 логика другая. Такие ответы почти всегда означают неверный JSON, неподдерживаемый параметр, плохой API-ключ, нехватку прав или превышение лимита контекста. Повтор здесь ничего не исправит. Он только сожжет время и, в некоторых случаях, увеличит счет.
С 5xx тоже не стоит ждать чуда. Ошибки 500, 502, 503 и 504 часто можно повторять. А вот 501, несовместимый формат ответа или явная ошибка схемы запроса обычно требуют правки кода, а не новой попытки.
Самый неприятный случай - таймауты и обрывы стрима. Если соединение упало до первых токенов, повтор обычно безопасен. Если стрим оборвался после того, как вы уже получили часть ответа, состояние запроса уже неочевидно. Модель могла сгенерировать почти все, а биллинг мог уже пройти. В такой точке лучше опираться на request_id, idempotency_key и собственные логи, а не отправлять тот же запрос еще раз наугад.
Тип операции меняет решение сильнее, чем кажется. Для обычной генерации текста повтор после 429 или 503 часто оправдан. Если тот же вызов запускает tool call, создает заявку в CRM или отправляет сообщение, повтор всего пайплайна может выполнить действие дважды. Здесь лучше разделять шаги: отдельно запрос к модели, отдельно внешнее действие со своим идентификатором операции.
Если сомневаетесь, задайте себе один вопрос: запрос точно не выполнился или вы просто не успели увидеть результат? Повторять стоит только в первом случае.
Как выставить таймауты без лишних дублей
Один общий таймаут на все запросы почти всегда ведет к лишним повторам. Короткие задачи начинают зря ретраиться, а длинные обрываются за пару секунд до готового ответа. В итоге провайдер еще считает токены по первому вызову, а клиент уже отправил второй.
Проблема обычно не в самих ретраях, а в том, что клиент слишком рано решает: "запрос умер".
Сразу разделяйте два лимита: время на установку соединения и время на ответ модели. Для соединения обычно хватает короткого окна. Если TCP или TLS не поднялись за 1-3 секунды внутри нормальной сети, ждать еще 20 секунд редко есть смысл.
С ожиданием ответа все иначе. Его стоит привязывать к типу задачи и длине генерации. Классификация, извлечение поля из документа или короткий JSON-ответ живут в одном диапазоне. Развернутый отчет, длинный чат-ответ или генерация на сотни токенов - в другом.
Даже если вы ходите в один OpenAI-совместимый endpoint, например через AI Router, задержка все равно меняется по модели и провайдеру. Поэтому таймаут лучше задавать не на весь клиент сразу, а по сценарию вызова.
Стартовые значения
- Короткие ответы: соединение 2 секунды, ответ 10-20 секунд.
- Обычный чат: соединение 2 секунды, ответ 30-45 секунд.
- Длинная генерация: соединение 2-3 секунды, ответ 60-90 секунд.
- Streaming: соединение 2 секунды, первый токен 10-15 секунд, дальше отдельный лимит между чанками.
Эти числа не универсальны, но они лучше, чем один таймаут в 30 секунд для всего. Начните с них и посмотрите логи по реальной длине ответов, отменам и повторным вызовам.
Ориентир простой: таймаут должен быть чуть длиннее обычного успешного ответа, а не вдвое короче редкого медленного ответа. Если 95% коротких запросов укладываются в 8 секунд, ставьте 12-15 секунд, а не 5.
Не смешивайте в одну группу модерацию, поиск по базе знаний и длинную генерацию письма. Эти задачи ведут себя по-разному. Когда вы делите их на отдельные профили таймаутов, ложных дублей становится заметно меньше.
Как выбрать паузы между повторами
Слишком короткая пауза между повторами почти всегда бьет по кошельку. Если провайдер уже перегружен, новый запрос через 200 миллисекунд редко помогает. Он просто добавляет еще одну попытку в ту же очередь и повышает шанс получить второй оплаченный вызов, когда сервис оживет.
Для большинства сценариев хватает двух, максимум трех попыток. Больше обычно имеет смысл только для фоновых задач, где задержка не критична. В чате, поиске по базе знаний или операторском интерфейсе четвертая и пятая попытка чаще вредят, чем спасают.
Пауза должна расти после каждого сбоя. Самый практичный вариант - exponential backoff с небольшим случайным разбросом. Так тысячи клиентов не ударят по провайдеру одновременно в одну и ту же секунду после короткого сбоя.
Для интерактивных запросов часто хватает такой схемы:
- первая пауза: 500-800 мс;
- вторая пауза: 1.5-2.5 с;
- третья пауза: 3-5 с.
К каждой паузе лучше добавить случайный разброс 15-30%. Тогда две одинаковые сессии не пойдут по одной траектории.
Ограничивайте и общий бюджет ожидания на запрос. Если ответ нужен пользователю на экране, держите все вместе, включая паузы и сетевые таймауты, в пределах 8-12 секунд. Для фоновой обработки можно дать 30 секунд или чуть больше, но верхний предел все равно нужен. Иначе один проблемный запрос зависнет надолго и потянет за собой очередь.
Есть еще одно практичное правило: чем дороже модель и длиннее ответ, тем осторожнее должны быть повторы. Если сервис отправляет большой промпт в дорогую модель, лишняя попытка может стоить заметно больше, чем сама ошибка. В таких случаях лучше меньше повторов, но с нормальной паузой.
Фиксированная пауза в 1 секунду для всех случаев выглядит аккуратно только на бумаге. Под реальной нагрузкой она часто и создает тот снежный ком расходов, которого вы пытались избежать.
Как защититься от двойного списания
Если один и тот же запрос уходит дважды, провайдер может посчитать его как две отдельные генерации. Для LLM это особенно неприятно: длинный промпт и большой ответ быстро превращают мелкий сбой в заметный перерасход.
Самая надежная защита - считать идемпотентность не на уровне HTTP-запроса, а на уровне бизнес-операции. Пользователь нажал "сформировать ответ клиенту", система создала одну операцию, и все повторы работают только внутри нее.
Один ключ на одну операцию
Сгенерируйте один idempotency_key в момент, когда возникло действие, и привяжите его к пользователю, типу действия и объекту, с которым работаете. Например: user_42:reply_ticket:9182. Формат может быть любым, если он стабилен и не меняется между ретраями.
Новый повтор не должен создавать новый ключ. Это частая ошибка. Приложение получает таймаут, думает, что запрос не дошел, и отправляет тот же промпт заново уже с другим идентификатором. Для биллинга это часто выглядит как две разные операции.
У себя нужно хранить не только ключ, но и итог операции: статус, идентификатор пользователя, хеш промпта или payload, финальный ответ или ссылку на него в вашей базе. Если провайдер уже вернул успешный результат, система должна отдать его повторно и не звать модель второй раз.
Это правило не меняется и при работе через шлюз. Защита от двойного списания должна жить в приложении, а не только на стороне провайдера.
Простой тест выглядит так. Менеджер просит сгенерировать summary звонка. Модель уже отработала, но сеть оборвалась до того, как ваш сервер получил ответ. Если вы сохранили ключ операции и умеете проверять его повторно, система либо достанет готовый результат из своей базы, либо аккуратно покажет, что первая попытка уже завершилась. Новую генерацию запускать не нужно.
Как настроить ретраи по шагам
Ретраи лучше настраивать не с кода, а с экономики. Если одна генерация стоит заметно дороже обычного запроса, лишний повтор быстро съедает бюджет. Особенно это видно на длинных ответах, где модель уже начала считать токены, а клиент решил, что запрос завис.
- Сначала посчитайте цену лишней попытки. Возьмите средний размер входа и ответа, умножьте на тариф модели и добавьте частоту ошибок. Если сервис делает 10 000 запросов в день, даже 2% лишних повторов могут заметно увеличить счет.
- Затем разделите ошибки на две группы. Повторяйте сетевые сбои, 429 и часть 5xx. Не повторяйте 4xx из-за неверного формата, слишком длинного промпта, ошибки авторизации и других финальных случаев.
- После этого задайте разные таймауты. Таймаут соединения должен быть коротким. Таймаут чтения ставьте длиннее, потому что модель может отвечать медленно, особенно на больших промптах или при стриминге. Общий дедлайн запроса тоже нужен.
- Затем добавьте паузы между повторами и лимит попыток. Обычно хватает 2-3 попыток с ростом паузы и небольшим случайным разбросом.
- В конце проверьте схему на искусственном сбое. Отключите одного провайдера, замедлите ответы или верните 500 в тестовой среде. Смотрите не только на успешность, но и на число повторов, рост токенов и итоговую цену.
Если у вас несколько маршрутов или провайдеров, такой тест особенно полезен. Нормально настроенная схема дает умеренный рост задержки при сбое, но не превращает один запрос в три платных.
Пример из рабочей нагрузки
Вечером в чат поддержки приходит много сообщений сразу. Пользователь банка пишет: "Не могу войти в приложение". Бэкенд отправляет запрос в LLM, чтобы быстро собрать ответ для оператора и подсказать следующий шаг.
Проблема начинается не в модели, а в клиентских настройках. Провайдер в этот момент перегружен и отвечает за 18 секунд. Ваш сервис ждет только 10 секунд, считает запрос упавшим и сразу шлет повтор.
Картина получается такой:
- 00:00 - первый запрос уходит к провайдеру;
- 00:10 - срабатывает клиентский таймаут, сервис запускает повтор;
- 00:18 - провайдер завершает первый запрос и возвращает ответ;
- 00:28 - приходит ответ на второй запрос.
Если у запроса нет защиты, система получает два нормальных ответа на один вопрос. Один уже мог уйти оператору, а второй прилетит позже и перетрёт состояние диалога, задвоит запись в логах или испортит метрики. Хуже всего то, что вы, скорее всего, заплатите дважды за одну и ту же работу.
Такой сбой часто выглядит почти безобидно. В мониторинге виден один таймаут и один успешный повтор. Но счет растет именно из-за таких мелочей. При большой нагрузке несколько лишних дублей в минуту быстро превращаются в заметную сумму.
Здесь и помогает идемпотентность. Исходный вызов и повтор должны идти с одним и тем же idempotency_key. Тогда приложение понимает, что это не новая задача, а попытка завершить старую, и не создает вторую бизнес-операцию поверх первой.
Практический вывод простой: проверяйте не только число повторов. Смотрите на связку из трех вещей - таймауты, паузы между повторами и идемпотентность. Если хотя бы одно звено выпадает, контроль затрат быстро ломается даже в обычном чате поддержки.
Частые ошибки в настройке
Ретраи чаще ломаются не из-за одной плохой настройки, а из-за двух слоев логики, которые спорят друг с другом. Команда добавляет повторы в свой код, а потом выясняет, что SDK уже делает то же самое. Один сбой превращается в 4-6 одинаковых запросов, и счет растет быстрее, чем это видно в логах.
Еще одна частая ошибка появляется при стриминге. Если модель уже отдала первые токены, запрос нельзя считать неуспешным только потому, что соединение оборвалось позже. Автоповтор в такой точке часто создает дубль ответа и дубль затрат.
На практике чаще всего ошибаются так: включают ретраи и в SDK, и в своем сервисе; повторяют стрим после начала ответа; считают любой таймаут ошибкой модели; не записывают request_id и ключ идемпотентности; держат почти бесконечные повторы для 429. Каждая из этих ошибок неприятна сама по себе, а вместе они дают хаос.
Хуже всего, когда все это собирается в одну цепочку. Клиент получил 20 токенов, затем соединение упало, SDK сам отправил повтор, а ваш код сделал еще один. Если при этом в логах нет request_id, разбор инцидента превращается в гадание.
Нормальная практика куда проще: один слой ретраев, отдельные правила для стрима, жесткий лимит попыток для 429 и обязательная запись request_id. Этого уже хватает, чтобы большая часть дублей просто исчезла.
Короткая проверка перед запуском
Перед запуском полезно сделать короткий стоп-чек. Пять минут на настройку часто экономят заметную сумму, особенно если модель отвечает медленно, а ошибки приходят волнами.
Проверьте четыре вещи.
Во-первых, разделите правила по кодам ответа. Для 429 нужен повтор с паузой и ростом задержки. Для части 5xx тоже можно повторять, но с более жестким лимитом. Для большинства 4xx повторять не нужно: такой запрос уже сломан.
Во-вторых, ограничьте число попыток. Один пользовательский запрос не должен уходить дальше трех попыток, включая первую. Если дать пять или семь, сбой одного провайдера быстро превращается в снежный ком расходов.
В-третьих, храните идемпотентный ключ дольше, чем живет окно ретраев. Если клиент может повторять запрос 2 минуты, а сервер забывает ключ через 30 секунд, вы сами открываете дверь для дублей.
В-четвертых, смотрите не только на ошибки, но и на деньги. В метриках должны быть видны доля дублей, лишние токены на повторах, среднее число попыток на запрос и расходы по кодам ошибок.
Есть и простой тест. Возьмите один и тот же запрос, искусственно вызовите таймаут клиента, затем отправьте его повторно с тем же ключом идемпотентности. Сервис должен либо вернуть тот же результат, либо ясно показать, что первый вызов уже обработан. Если система создает два отдельных биллинговых события, конфигурация еще сырая.
Что делать дальше
Не меняйте политику ретраев сразу на всем трафике. Сначала выберите один маршрут с понятной нагрузкой, где легко посчитать цену ошибки. Подойдет внутренний чат для сотрудников, support-бот или один RAG-сценарий с устойчивым объемом запросов.
Такой узкий запуск почти всегда лучше большой миграции за один день. На одном маршруте быстрее видно, какие таймауты режут живые ответы, какие повторы создают дубли и где счет растет без пользы.
Дальше нужен короткий цикл проверки: включите новые правила только на части трафика, сравните стоимость дублей до и после изменения, проверьте аудит по request_id и API-ключам, а затем посмотрите, не упирается ли один ключ в rate limit и не запускает ли он лишние повторы в соседних сервисах.
Даже срез за 2-3 дня уже дает ясную картину. Если раньше из 1000 запросов 70 уходили в лишние повторы, а после правки осталось 15, эффект виден сразу и по бюджету, и по времени ответа.
Если у вас несколько провайдеров, единая точка входа сильно упрощает такую проверку. Например, в AI Router можно сменить base_url на api.airouter.kz, оставить те же SDK и промпты и смотреть аудит-логи и лимиты на уровне ключа в одном месте. Это удобно, когда вы сравниваете маршруты, следите за дублями и не хотите разносить логику по каждому сервису.
Когда один маршрут покажет стабильный результат, переносите те же правила на соседние сценарии. Но не раскатывайте их вслепую. Сначала добейтесь предсказуемого счета и чистой трассировки запросов, потом расширяйте охват.
Часто задаваемые вопросы
Почему ретраи могут быстро увеличить счёт?
Потому что таймаут у клиента не значит, что провайдер ничего не сделал. Запрос мог дойти до модели, и она уже начала считать токены.
Если в этот момент приложение шлёт тот же промпт ещё раз, вы получаете два платных вызова вместо одного результата.
Какие ошибки можно повторять без лишнего риска?
Обычно повторяют временные сетевые сбои и перегрузку: обрыв соединения, сбой DNS, 429, 500, 502, 503, 504.
Смысл простой: если проблема похожа на краткий сбой, повтор может помочь. Если проблема в самом запросе, повтор только тратит время и деньги.
Когда лучше остановиться и не делать повтор?
Не повторяйте 400, 401, 403, ошибки схемы, слишком длинный контекст и неподдерживаемые параметры. Такие ответы говорят, что запрос надо исправить, а не отправить заново.
Отдельно проверьте вызовы, которые запускают tool call, CRM-действие или отправку сообщения. Повтор всего пайплайна может выполнить действие дважды.
Сколько попыток ставить по умолчанию?
Для интерактивных сценариев обычно хватает двух, максимум трёх попыток вместе с первой отправкой. Больше попыток редко спасают чат или поиск, зато часто плодят дубли.
Если задача фоновая и задержка не важна, можно дать чуть больше времени. Но даже там нужен жёсткий предел.
Как выбрать таймауты, чтобы не плодить дубли?
Не ставьте один общий таймаут на всё. Разделите время на установку соединения и ожидание ответа модели.
На практике соединению часто хватает 1–3 секунд. Для ответа берите диапазон по типу задачи: короткий ответ 10–20 секунд, обычный чат 30–45, длинная генерация 60–90. Таймаут должен быть чуть длиннее нормального успешного ответа, а не слишком коротким.
Что делать, если стрим оборвался на середине ответа?
Сначала смотрите, успели ли вы получить первые токены. Если соединение упало до начала ответа, повтор обычно безопасен.
Если стрим оборвался после части текста, не шлите тот же запрос вслепую. Сверьте request_id, idempotency_key и свои логи, потому что модель могла уже закончить работу, а биллинг мог уже пройти.
Как idempotency_key защищает от двойного списания?
Создайте один idempotency_key в момент, когда возникла бизнес-операция, и используйте его во всех повторах. Не генерируйте новый ключ на каждый ретрай.
У себя храните статус операции, хеш payload и итоговый результат. Тогда при повторе система сможет вернуть уже готовый ответ и не звать модель второй раз.
Нужно ли включать ретраи и в SDK, и в своём коде?
Нет, так делать не стоит. Если и SDK, и ваш сервис повторяют один и тот же сбой, один запрос легко превращается в несколько одинаковых вызовов.
Оставьте один слой ретраев и сделайте его видимым в логах. Так проще держать под контролем и расходы, и разбор инцидентов.
Какие метрики помогут заметить, что ретраи уже вредят?
Смотрите не только на число ошибок. Нужны метрики по доле дублей, среднему числу попыток на запрос, лишним токенам на повторах и расходам по кодам ответов.
Ещё полезно писать request_id, idempotency_key и маршрут запроса. Без этого вы увидите рост счёта, но не поймёте, откуда он взялся.
Решит ли OpenAI-совместимый шлюз проблему ретраев автоматически?
Сам по себе шлюз не отменяет проблему, потому что решение о повторе чаще всего принимает ваш код или SDK. Если клиент отправил дубль, шлюз его тоже увидит как новый вызов.
Зато единая точка входа упрощает контроль. В AI Router можно оставить те же SDK и промпты, сменить base_url на api.airouter.kz и смотреть аудит-логи, лимиты и поведение по ключам в одном месте.