RAG или длинный контекст: как выбрать схему для поиска
RAG или длинный контекст: разберём, как эти подходы влияют на поиск по документам, цену и задержку, чтобы выбрать схему под ваш продукт.
В чем выбор
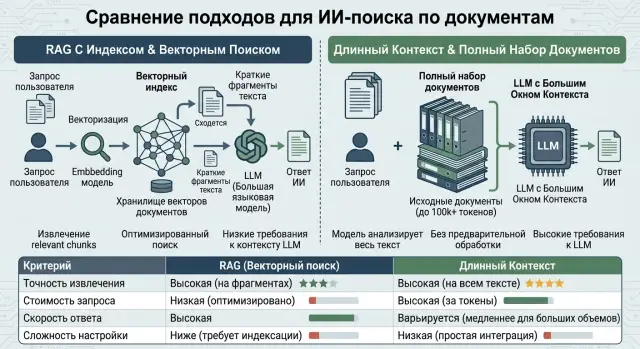
Один и тот же вопрос к документам можно решить двумя путями. Первый - найти нужные фрагменты и отдать модели только их. Это RAG. Второй - передать модели большой кусок текста или весь документ, если окно контекста это позволяет.
Спор о том, что "лучше", обычно быстро уходит в сторону. Пользователю схема не важна. Ему нужен точный ответ за разумные деньги и без долгого ожидания.
Поэтому смотреть стоит сразу на четыре вещи: как часто система находит нужный факт, сколько стоит один ответ и весь поток запросов, как быстро приходит результат и сколько сил команда тратит на поддержку решения.
RAG и длинный контекст дают разный баланс. Если документы большие, часто меняются и запросов много, поиск по фрагментам нередко выигрывает по цене. Модель читает меньше токенов, а индекс можно обновлять без полной переделки логики ответа.
Если документов мало, они понятные и редко меняются, длинный контекст часто проще. Не нужно строить индекс, настраивать разбиение текста и разбираться, почему нужный абзац не попал в выдачу. Для внутренней базы знаний из 30-40 коротких инструкций это может быть самым прямым вариантом.
Тип документов тоже сильно влияет на выбор. Договоры, регламенты и инструкции с четкой структурой обычно нормально работают в обеих схемах. Переписки, сканы, таблицы, старые PDF с шумом и дублями чаще создают проблемы. Поиск по фрагментам начинает путаться, а длинный контекст может утонуть в лишнем тексте и пропустить нужную деталь.
Частота запросов меняет экономику. Если вопрос задают редко, можно смириться с более дорогим вызовом модели ради простой схемы. Если запросы идут тысячами в день, лишние 20-30 тысяч токенов на каждый ответ быстро превращаются в заметную статью расходов.
Лучший способ выбрать - сравнить оба подхода на реальных вопросах, а не на вкусах архитекторов. Такой тест обычно и показывает, что лучше работает для продукта, а не для красивой схемы на доске.
Как RAG решает поиск по документам
RAG не заставляет модель читать весь архив. Сначала система ищет нужные фрагменты, потом отправляет их в LLM вместе с вопросом. На практике документы режут на части, строят индекс, переводят запрос и тексты в векторы и выбирают несколько самых близких фрагментов.
Из-за этого ответ зависит не только от модели, но и от качества поиска. Сильная модель не спасет слабый индекс. Если инструкция разрезана посередине таблицы, старая и новая версии документа смешаны, а PDF загружен с плохим OCR, поиск принесет мусор. Модель просто перескажет его аккуратным языком.
Сильнее всего обычно влияют четыре вещи: как вы делите документ на фрагменты, какие поля и метки храните рядом с текстом, насколько чистый текст попал в индекс и используете ли повторную сортировку найденных кусков.
RAG особенно полезен там, где ответ лежит в нескольких абзацах, а не размазан по сотням страниц. База знаний продукта, внутренние регламенты, договоры, FAQ, инструкции для поддержки - во всех этих случаях поиск быстро находит нужное место. Если сотрудник спрашивает, как считать лимит по тарифу, системе не нужно читать всю документацию. Ей нужен раздел с правилами расчета и соседний фрагмент с исключениями.
Когда материалы хорошо структурированы, такой подход часто дает точный ответ быстрее полного чтения документов. Еще один плюс - проще показать, откуда взялся ответ, потому что в запрос попадают конкретные куски текста, а не весь архив.
Но RAG промахивается не так уж редко. Запрос может быть слишком коротким. Термин в вопросе может не совпасть с формулировкой в документе. Нужная мысль может оказаться разбросанной по разным разделам. Тогда поиск приносит почти релевантные фрагменты, и модель строит ответ на чужом контексте. Снаружи это выглядит правдоподобно, но ответ неверный.
Поэтому RAG стоит оценивать по двум отдельным шагам. Сначала - находит ли поиск нужные фрагменты. Потом - попадает ли модель в смысл, когда эти фрагменты уже перед ней. Если первый шаг слабый, второй тоже обычно сыпется.
Что меняется при длинном контексте
При длинном контексте схема проще. Вместо отдельного поиска вы кладете в запрос большой кусок базы знаний, договора или переписки, а модель читает все сразу. Для команды это удобно: не нужно строить индекс, настраивать ранжирование и решать, какой фрагмент достать первым.
Такой подход хорошо работает, когда документов мало, они меняются не слишком часто, а ответ зависит от связи между несколькими частями текста. Модель может сразу увидеть условие в начале регламента, исключение в приложении и срок в конце документа. В RAG эти куски еще нужно правильно найти и собрать вместе.
Длинный контекст часто выбирают для разбора одного большого договора или тендерного пакета, ответов по короткой внутренней базе знаний, анализа цепочки писем, где важен порядок сообщений, и проверки документа на противоречия между разделами.
Но большое окно контекста не делает модель внимательной автоматически. Если в запрос попадает 150 страниц, она все равно может пропустить одну строку с лимитом, датой или исключением. Это похоже на человека, который листает толстую папку в спешке: текст перед глазами есть, а мелкая деталь теряется.
Проблема усиливается, когда в контекст попадает лишнее. Пользователь спрашивает про возврат товара, а вы отправляете весь архив справки, старые правила и документы для партнеров. Модель тратит токены на страницы, которые не помогают ответить. Ответ идет дольше, а цена растет почти прямо вместе с объемом текста.
Есть и другой эффект. Длинный контекст проще для старта и помогает быстро собрать первый рабочий сценарий. Но когда база знаний растет, держать качество на одном уровне сложнее. Каждый запрос начинает нести больше шума. В этот момент выигрывает не подход с самым большим окном, а тот, где в модель попадает только нужный текст.
Если документы компактные и вопрос требует чтения целого пакета, длинный контекст экономит время разработки. Если материалов много, а ответы обычно прячутся в двух-трех абзацах, он быстро становится дорогим и медленным.
Где вы платите больше
У RAG расходы появляются в трех местах. Сначала - эмбеддинги при подготовке документов к поиску. Потом - хранение индекса и его обновление, если документы часто меняются. После этого идет сам запрос к модели, но уже с коротким контекстом, потому что в промпт попадают только найденные фрагменты.
У длинного контекста логика другая. Индекс не нужен, зато модель читает много входных токенов почти при каждом запросе. Если пользователь пять раз спрашивает про один и тот же набор документов, система пять раз оплачивает чтение тех же страниц. Часто к этому добавляется запас по окну: команда берет модель с большим лимитом токенов просто на всякий случай.
На практике счет часто ломает не цена модели сама по себе, а объем текста, который вы отправляете снова и снова. Если поиск по документам отбирает 5 нужных фрагментов вместо 200 страниц, экономия нередко сильнее, чем переход на модель чуть дешевле.
Пример простой. В базе знаний 3 000 статей. Пользователь задает короткий вопрос про одну настройку. RAG отправляет в модель 6-10 фрагментов. Длинный контекст тянет подборку статей или целый раздел. Во втором случае вы платите за лишнее чтение и платите каждый раз.
Но у длинного контекста есть сильная сторона: небольшой набор документов. Если у вас 15 коротких инструкций, которые вместе занимают 30 000-50 000 токенов, отдельный индекс может не окупиться. Нет затрат на эмбеддинги, нет поддержки пайплайна, меньше мест, где что-то ломается. Для внутреннего помощника или пилота это нередко проще и не дороже.
Поэтому деньги почти всегда следуют за двумя числами: сколько текста модель читает на один ответ и сколько раз она читает его заново. Если документов мало, длинный контекст часто выигрывает по простоте. Если документов много и вопросы узкие, RAG обычно заметно снижает счет.
Что происходит со скоростью
Скорость зависит не только от модели. Сильнее всего на нее влияет объем текста, который вы кладете в запрос. Поэтому победитель в споре между RAG и длинным контекстом меняется от задачи к задаче.
Если база знаний большая, RAG обычно быстрее. Поисковый слой находит 5-10 нужных фрагментов, и модель читает только их, а не сотни страниц целиком. Время уходит на поиск и иногда на повторную сортировку, но эта добавка часто меньше, чем задержка от чтения большого контекста.
Представьте систему поддержки с тысячами инструкций, регламентов и PDF. Пользователь спрашивает, как вернуть товар по гарантии. RAG достает несколько абзацев про возврат, сроки и нужные формы. Модель отвечает по делу и не тратит время на все остальное.
Длинный контекст может быть быстрее, если цепочка совсем простая: один документ, один запрос, без поиска и без индекса. Если у вас короткий договор на 8 страниц или небольшой бриф, проще отдать текст модели целиком. Меньше шагов - меньше мест, где система тормозит.
Такой вариант хорошо работает и там, где вопрос жестко привязан к формулировкам документа. Юрист просит проверить один контракт, а не искать ответ в архиве из десятков тысяч файлов. Модель сразу читает весь текст и отвечает без промежуточной логики.
Проблемы начинаются, когда документы растут. Большой PDF, таблицы, приложения и повторяющиеся блоки быстро раздувают число токенов. Таблица на несколько экранов может добавить больше задержки, чем десять обычных абзацев. А если один и тот же длинный файл отправляют в модель снова и снова, система каждый раз платит временем за повторное чтение.
При повторных запросах RAG часто ведет себя ровнее. Индекс уже готов, поиск занимает примерно одно и то же время, а объем текста в промпте остается близким. У длинного контекста разброс выше: один запрос проходит быстро, другой внезапно упирается в длинное приложение или плохо сжатую таблицу.
Средняя скорость в отчете выглядит красиво, но пользователи замечают другое - насколько часто ответ "задумывается" дольше обычного. Для продукта это важнее, чем разница в полсекунды на идеальном сценарии. Поэтому полезно смотреть не только на среднее время ответа, но и на p95, p99, поведение на длинных документах и стабильность на повторных запросах.
Как выбрать схему шаг за шагом
Начинать лучше не с модели, а с типа вопроса. Если пользователю нужен точный факт из документа, RAG часто дает более предсказуемый результат. Если нужен общий пересказ большого отчета или сравнение нескольких разделов сразу, длинный контекст может быть проще, потому что модель видит весь материал.
Редкие детали требуют отдельной проверки. Если ответ зависит от одной строки в договоре, сноски в PDF или примечания в таблице, ошибка в поиске фрагмента сразу ломает RAG. Но и длинный контекст не гарантирует успех: модель может просто не заметить нужное место в слишком большом документе.
Дальше посчитайте объем текста. Нужны две цифры: средний размер документа и сколько текста модель реально читает для одного ответа. Если база состоит из коротких инструкций на 2-3 страницы, длинный контекст часто выглядит разумно. Если у вас длинные регламенты, переписки, отчеты и вложения, цена быстро растет, и RAG обычно выходит дешевле.
Посмотрите и на поведение пользователей. Когда люди много раз задают похожие вопросы по одной и той же базе знаний, RAG обычно окупается быстрее. Индекс настраивается один раз, а в модель потом идут только нужные фрагменты. Если запросы каждый раз разные и часто требуют чтения документа целиком, длинный контекст может дать меньше лишней инженерной работы.
Удобно идти по такому порядку:
- Разделите запросы на типы: факт, сводка, сравнение, поиск редкой детали.
- Измерьте средний размер документов и реальный объем текста на один ответ.
- Возьмите 20-30 живых вопросов от пользователей, а не придуманные примеры.
- Сравните две схемы по трем метрикам: точность, цена и задержка.
- Оставьте гибрид, если один подход лучше отвечает на факты, а другой лучше справляется со сводками.
Тесты лучше делать на коротком наборе, но проверять качество вручную. Смотрите не только на общий процент верных ответов, но и на цену ошибки. Для внутренней базы знаний промах в одном факте может быть терпимым, а для банка или клиники уже нет.
Гибрид нередко оказывается самым спокойным вариантом. Система сначала определяет тип вопроса: для точного поиска идет через RAG, для обзора документа отправляет больше текста в модель. Если команда уже работает через единый API, совместимый с OpenAI, вроде AI Router, такие сравнения проще прогонять на реальных вопросах без переделки клиентского кода.
Пример для базы знаний продукта
Представьте базу знаний для службы поддержки. В ней лежат инструкции, тарифы, шаблоны ответов, внутренние регламенты и PDF от партнеров. На бумаге это один массив документов, но по факту люди задают два разных типа вопросов.
Первый тип - короткие и точные запросы. Например: "Какой лимит у тарифа B?", "Какая форма ответа нужна для возврата?", "Что обещано партнеру в приложении 2?" В таких случаях поиск по фрагментам обычно дает более чистый ответ, потому что модель получает 2-5 нужных кусков текста, а не сотни страниц сразу.
Если в базе нормально настроены разбиение документов и поиск, RAG работает аккуратнее. Он реже тащит в ответ старые условия из соседнего PDF и меньше путает похожие формулировки из шаблонов поддержки.
Второй тип - разбор одного большого документа. Сотрудник открывает договор на 120 страниц или квартальный отчет партнера и спрашивает: "Где тут штрафы за просрочку?" или "Сравни разделы про ответственность и SLA". Здесь длинный контекст может быть проще. Вы кладете документ целиком или почти целиком в окно модели и не тратите время на сложную цепочку поиска.
Для базы знаний продукта редко побеждает только один подход. Обычно разумнее разделить сценарии. Короткие фактологические вопросы отправлять в цепочку с поиском по фрагментам, а вопросы по одному большому файлу - в цепочку с длинным контекстом. Шаблоны ответов и тарифы лучше хранить как отдельные, хорошо размеченные документы. Партнерские PDF лучше заранее чистить от мусора, колонтитулов и дублей.
Такой расклад особенно полезен, когда в системе есть и публичная справка, и внутренние документы поддержки. Оператору не нужен полный договор, если он ищет одну ставку или одно правило. Юристу или аккаунт-менеджеру, наоборот, удобнее получать ответ в рамках всего документа, а не по кускам.
Если продукт решает обе задачи, не стоит втискивать их в одну цепочку. Один маршрут пусть отвечает быстро и дешево на короткие вопросы. Второй пусть спокойно разбирает длинные договоры и отчеты. Так база знаний ведет себя предсказуемо, и команда лучше понимает, за что она платит токенами и временем ответа.
Ошибки, которые встречаются чаще всего
Чаще всего команда ошибается не в общей идее, а в деталях проверки. Схема выглядит разумно на бумаге, но в работе ломается из-за плохих фрагментов, лишнего контекста, слабого тестового набора и неверной оценки нагрузки.
У RAG типичная ошибка простая: индекс уже собрали, а качество фрагментов никто не проверил руками. Документ режут по фиксированным 1000 символам, таблицы распадаются, заголовки теряют связь с абзацами, метаданные пустые или слишком общие. В итоге поиск находит "что-то рядом", но не тот раздел. Модель отвечает уверенно, а источник не помогает.
С длинным контекстом ошибка другая. В окно модели отправляют весь архив, хотя пользователю нужен один раздел инструкции, один тариф или одна версия договора. Это быстро раздувает стоимость и нередко ухудшает ответ. Когда рядом лежат старые и новые версии текста, модель легко смешивает их в один ответ.
Плохое сравнение тоже встречается постоянно. Команда берет пять удобных вопросов, на которых обе схемы выглядят хорошо, и делает вывод. Такой тест почти бесполезен. Нужны трудные случаи: похожие документы с разными версиями, вопросы с редкими терминами, запросы, где ответ спрятан в сноске или таблице, длинные вопросы с лишними деталями и ситуации, где ответа в базе нет.
Еще одна частая ошибка связана с деньгами. Многие смотрят только на среднюю цену одного запроса. Но в реальной системе больнее бьют пики. Если в 10 утра приходят тысячи запросов, длинный контекст начинает стоить заметно больше, а задержка растет. У RAG свои пики: эмбеддинги, переиндексация, повторные поисковые проходы. Считать нужно оба режима.
Есть и тихая проблема: сменили модель, а остальную систему не тронули. После этого качество поиска и цитирования может просесть даже при той же базе. Одна модель лучше держит длинный контекст, другая хуже работает с найденными фрагментами, третья иначе ссылается на источник. Поэтому этот выбор нельзя делать один раз и навсегда. После смены модели, способа разбиения документов или ретривера тесты нужно прогонять заново.
Самые дорогие ошибки почти всегда появляются там, где команда доверяет интуиции больше, чем проверке на сложных вопросах.
Минимальный набор проверок
Спор между двумя схемами лучше закрывать не мнением команды, а коротким набором замеров. Если этих цифр нет, выбор почти всегда делают по ощущению, а потом месяцами чинят цену, задержку и пропуски в ответах.
Перед запуском обычно хватает пяти проверок:
- Соберите контрольный набор вопросов и документов. Для каждого вопроса нужен эталонный ответ или хотя бы список фактов, которые модель обязана вернуть.
- Посчитайте средний расход токенов на один ответ. Смотрите отдельно на короткие запросы, длинные запросы и сложные случаи со сравнениями, выдержками и цитатами.
- Измерьте задержку в двух режимах: обычный день и пиковая нагрузка. Один быстрый тест почти ничего не показывает.
- Посмотрите, как часто поиск промахивается. Нужны две разные метрики: система не нашла нужный документ вообще и система нашла документ, но пропустила важный факт в ответе.
- Зафиксируйте правило переключения сценария. Например, короткие вопросы идут через RAG, а длинный договор или регламент целиком уходит в модель с большим окном контекста.
Этого уже хватает, чтобы отсечь слабый вариант. Если один и тот же шлюз дает доступ к разным моделям и маршрутам, сравнение становится проще: можно гонять одинаковую нагрузку и смотреть не только на качество, но и на цену реального пользовательского сценария.
Если хотя бы два пункта из этого списка пока пустые, спорить про схему рано. Сначала доберите замеры, потом выбирайте.
Что делать дальше
Не пытайтесь выбрать один подход для всей базы сразу. Возьмите один живой сценарий: поиск по базе знаний, ответы для поддержки или работу с договорами. Если пилот не держится на одном понятном кейсе, на полном массиве документов он сломается еще быстрее.
Когда обсуждают RAG и длинный контекст, разговор часто уходит в теорию. Полезнее собрать небольшой, но честный тестовый набор и сравнить подходы на одинаковых вопросах. Добавьте в него простые запросы, редкие термины, длинные документы и пару похожих по смыслу ответов, где модель легко ошибается.
Прогоните на этом наборе три схемы: RAG, длинный контекст и гибрид. Смотрите не только на средний результат. Бывает, что длинный контекст хорошо отвечает на коротком наборе, но резко дорожает на реальных документах. А RAG показывает хорошие цифры, пока ретривер не сталкивается с плохой разметкой или старыми версиями файлов.
До запуска зафиксируйте пороги, которые команда не готова нарушать: цену одного ответа или одной сессии, задержку первого токена и полного ответа, долю правильных ответов на тестовом наборе, поведение на длинных и шумных документах и стабильность под реальной нагрузкой.
Без таких рамок выбор почти всегда делают по впечатлению от демо. Это плохой способ принять решение.
Если вам нужно быстро прогонять такие тесты на разных моделях и у разных провайдеров, это удобно делать через AI Router. У сервиса один API, совместимый с OpenAI: команде достаточно сменить base_url на api.airouter.kz, чтобы сравнивать варианты без переписывания SDK, кода и промптов.
После пилота оставьте не ту схему, которая лучше смотрелась на презентации, а ту, которая держит качество на вашей обычной нагрузке. Если база знаний обновляется каждый день и пользователи задают точные вопросы по фрагментам документов, RAG часто выигрывает по цене. Если документов мало, а ответ зависит от широкого контекста, длинный контекст может оказаться проще.
Сначала докажите пользу на одном сценарии. Потом расширяйте охват.
Часто задаваемые вопросы
Когда RAG лучше длинного контекста?
RAG чаще выигрывает, когда база большая, вопросы узкие, а ответ лежит в нескольких абзацах. В этом случае система находит нужные куски и не заставляет модель читать весь архив.
Такой вариант обычно лучше держит цену и задержку под нагрузкой. Но он работает хорошо только тогда, когда поиск реально находит нужные фрагменты.
Когда длинный контекст выглядит разумнее?
Если документов мало, они короткие и редко меняются, длинный контекст часто проще. Команда сразу отдает текст модели и не тратит время на индекс, разбиение и настройку поиска.
Для пилота или внутренней базы из нескольких десятков инструкций этого часто хватает. Потом, когда база разрастается, схему уже стоит пересмотреть.
От чего чаще всего ломается качество в RAG?
Больше всего на точность влияет не сама модель, а качество поиска. Если вы плохо почистили текст, неровно нарезали фрагменты или смешали старые и новые версии документов, модель получит неверную основу для ответа.
Сначала проверьте, находит ли система нужные куски руками. Только потом смотрите на качество самого ответа.
Почему длинный контекст не гарантирует точный ответ?
Потому что наличие текста в окне не значит, что модель заметит нужную строку. На длинных документах она тоже пропускает даты, лимиты, сноски и исключения.
Ситуацию портит лишний шум. Если вы кладете в запрос старые версии, приложения и лишние разделы, модель тратит внимание не туда.
Что обычно дешевле при тысячах запросов в день?
При большом потоке запросов чаще дешевле RAG. Модель читает меньше токенов на каждый ответ, и эта разница быстро становится заметной в счете.
Длинный контекст может выйти дешевле только на маленьком наборе документов, где индекс просто не окупается. Поэтому считайте не цену модели, а объем текста на один ответ и число повторов.
Что обычно быстрее для пользователя?
На большой базе знаний RAG нередко быстрее, потому что модель читает 5–10 фрагментов, а не сотни страниц. Поиск тоже занимает время, но эта добавка часто меньше, чем чтение длинного текста.
Если у вас один короткий документ и один вопрос, длинный контекст может дать ответ быстрее. Тут побеждает не теория, а размер реального входа.
Как честно сравнить RAG и длинный контекст?
Возьмите 20–30 живых вопросов, а не удобные примеры из головы. Для каждого вопроса заранее запишите верный ответ или хотя бы факты, которые система обязана вернуть.
Потом прогоните один и тот же набор через RAG и длинный контекст и сравните точность, цену и задержку. Отдельно посмотрите трудные случаи: таблицы, сноски, похожие версии документов и вопросы без ответа в базе.
Имеет смысл сразу делать гибридную схему?
Да, во многих продуктах гибрид работает спокойнее всего. Короткие фактологические вопросы можно отправлять через поиск по фрагментам, а разбор одного большого договора или отчета — через длинный контекст.
Так вы не пытаетесь одной схемой закрыть все задачи сразу. Обычно это дает более ровкое качество и понятнее управляет расходами.
Какие ошибки при запуске встречаются чаще всего?
Часто команда плохо готовит документы к работе. В RAG она режет текст на случайные куски, теряет заголовки и таблицы, а в длинном контексте просто отправляет в модель весь архив без отбора.
Еще одна частая ошибка — слабый тест. Если вы проверили систему на пяти простых вопросах, вы почти ничего не узнали о реальной работе.
С чего начать пилот, если времени мало?
Начните с одного сценария, где боль уже понятна: поддержка, поиск по регламентам или разбор договоров. Не берите сразу всю базу и все типы запросов.
Соберите небольшой набор вопросов, измерьте точность, цену и задержку, а потом выберите схему под этот сценарий. Если пилот не держится на одном кейсе, на полном объеме он только сломается сильнее.