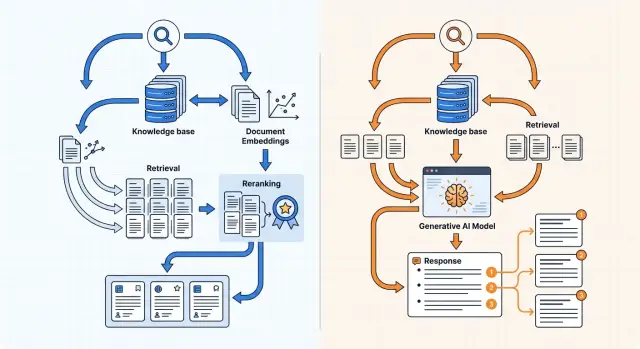
Поиск по базе знаний: эмбеддинги или генеративная модель
Поиск по базе знаний можно строить через эмбеддинги или через генеративную модель. Разберем индексацию, реранжирование и ответы с цитатами.
В чем тут проблема
Поиск по базе знаний редко ломается из-за одной большой ошибки. Обычно мешают сразу несколько мелочей, и вместе они дают слабый результат.
Первая проблема простая: человек спрашивает не теми словами, которыми написаны документы. Сотрудник пишет: "как вернуть доступ после смены телефона", а в базе лежит статья с заголовком "перевыпуск второго фактора". По смыслу это одно и то же. По словам на странице - нет. Поэтому обычный поиск часто пропускает нужный фрагмент даже в хорошо собранной базе.
Вторая проблема в том, что ответ редко живет в одном абзаце. Часть условия может быть в регламенте, шаги - в инструкции, а исключения - в обновлении от прошлого месяца. Если система нашла только один кусок, она дает неполный ответ. Для пользователя это хуже, чем честное "не найдено", потому что ошибка выглядит правдоподобно.
Третья проблема - шум в данных. В базе почти всегда есть дубликаты, старые версии, черновики, пустые шаблоны и страницы, где полезного текста две строки, а служебного - десять. Такой мусор мешает и простому поиску, и более умным схемам. Система начинает поднимать не лучший документ, а тот, где просто чаще встретились похожие слова.
Есть и еще один практический момент. Пользователю мало получить ответ. Он хочет понять, откуда он взялся. Это особенно заметно в банках, телекоме и медицине, где нельзя опираться на "похоже, так и есть". Нужна цитата из источника, а лучше несколько коротких цитат из разных мест. Тогда ответ можно быстро проверить, а спорный случай - открыть в исходном документе и дочитать.
Поэтому поиск по базе знаний - это не только вопрос "что нашлось", но и вопрос "насколько этому можно верить".
Что дает поиск на эмбеддингах
Поиск на эмбеддингах хорош там, где люди задают вопрос одними словами, а ответ в базе написан другими. Система превращает вопрос и каждый фрагмент текста в векторы, а потом ищет, какие фрагменты ближе всего по смыслу. Для базы знаний это часто полезнее обычного поиска по словам.
За счет этого находятся не только точные совпадения формулировок. Если сотрудник пишет "где хранятся данные клиента", а в документе сказано "data residency внутри Казахстана", такой слой все равно может поднять нужный кусок. То же самое работает с парами вроде "журналы аудита" и "audit-логи".
На большой базе это еще и быстро. Векторный индекс не перебирает все документы подряд. Он быстро отбирает небольшой набор кандидатов, с которыми уже можно работать дальше. Поэтому эмбеддинги удобно использовать как первый слой, когда у вас тысячи страниц документации, регламентов или тикетов.
Где он силен, а где нет
Лучше всего такой поиск работает на вопросах с разными формулировками, синонимами и коротким контекстом. Он неплохо тянет FAQ, инструкции и внутренние статьи, если текст заранее разбит на аккуратные фрагменты.
Но близость по смыслу не равна точности ответа. Без дополнительного ранжирования поиск часто поднимает фрагмент, который просто "похож", но не отвечает прямо. Например, вместо точного отрывка про лимиты на уровне API-ключа система может вернуть общий раздел про безопасность или контроль доступа.
Есть и еще одна граница. Поиск на эмбеддингах сам по себе не пишет финальный ответ. Он находит кандидатов. Если нужен короткий ответ с цитатой, проверкой формулировки и сборкой нескольких источников, одного векторного слоя мало.
На практике это сильная база, но не вся система. Эмбеддинги быстро сужают поле поиска и хорошо ловят смысл, когда слова не совпали. За точность на последнем шаге отвечают уже другие части пайплайна.
Что дает генеративная модель
Генеративная модель хороша там, где поиск уже нашел материалы, но человеку нужен не список документов, а связный ответ. Она лучше держит длинный вопрос, понимает уточнения из диалога и реже теряет смысл, если пользователь пишет не по шаблону.
Это особенно заметно на сложных запросах. Если сотрудник спрашивает: "Какие условия возврата действуют для корпоративных клиентов и есть ли исключения для предзаказа?", модель может взять кусок из правил возврата, добавить фрагмент из договора для B2B и собрать один ответ вместо двух разрозненных ссылок.
Ее сильная сторона - не поиск любой ценой, а сборка ответа из нескольких найденных фрагментов. Когда факты лежат в разных местах базы знаний, модель умеет свести их в короткий текст, убрать повторы и сохранить ход мысли. Для пользователя это часто удобнее, чем самому читать пять документов подряд.
Но у этой схемы есть слабое место. Если в контексте мало данных, они устарели или плохо подходят к вопросу, модель начинает додумывать. Она заполняет пробелы правдоподобным текстом, и ошибка выглядит уверенно. В базе знаний это опасно: человек видит гладкий ответ и не сразу замечает, что точного основания в документах нет.
Поэтому пускать генеративную модель на весь поиск обычно плохая идея. Если она сама читает слишком много документов на каждом запросе, цена быстро растет, а ответ приходит медленнее. Это заметно даже на средней нагрузке. Намного лучше сначала сузить набор кандидатов поиском и реранжированием, а уже потом давать модели 5-10 лучших фрагментов.
С цитатами нужен жесткий режим. В промпте лучше прямо задать правила:
- отвечай только по переданным фрагментам;
- после каждого важного факта указывай источник;
- если данных не хватает, пиши "не нашел подтверждения в базе";
- не объединяй похожие формулировки в одну "общую" цитату.
Такой подход дает хороший результат: модель пишет по-человечески, но не уходит далеко от документов. Если команда использует шлюз вроде AI Router, удобно быстро сравнить несколько моделей на одном и том же наборе фрагментов и посмотреть, какая аккуратнее работает с цитатами и длинным контекстом.
Как собрать индекс без лишнего шума
Плохой индекс ломает поиск по базе знаний еще до эмбеддингов и реранжирования. Если во фрагменты попали меню сайта, кнопки, подписи к иконкам, футер и дубли из шаблона, поиск начинает тянуть мусор. Потом модель отвечает уверенно, но ссылается не на смысл, а на шум.
Сначала очистите источник. Оставьте только текст, который человек читает ради ответа на вопрос. Уберите навигацию, служебные блоки, дисклеймеры, повторяющиеся заголовки страниц и одинаковые фразы из каждой карточки документа. Если один и тот же абзац встречается в пяти местах, храните один нормальный экземпляр.
Резать текст по 500 или 1000 символов удобно, но это часто портит смысл. Лучше делить по структуре документа: раздел, подпункт, шаг инструкции, отдельное правило, примечание. Тогда фрагмент отвечает на один вопрос целиком, а не обрывается на середине условия.
Рядом с каждым фрагментом храните метаданные: заголовок документа, название раздела, дату, версию и тип источника. Это сильно помогает потом отфильтровать устаревший текст. Для регламентов и инструкций без версии поиск быстро начинает путать старые и новые правила.
Не складывайте все в один общий индекс. FAQ, формальные регламенты и живая переписка решают разные задачи и пишутся разным языком. Проще разделить их хотя бы на три коллекции: FAQ для коротких типовых вопросов, регламенты и политики для точных правил, а переписку и тикеты оставить как вспомогательный слой.
Еще один частый промах - потеря формы данных. Таблицы, списки и вложения нужно помечать отдельно. Таблица с тарифами, список исключений и PDF-приложение не равны обычному абзацу. Если это не отметить, поиск вернет фрагмент без контекста, и цифры или условия поедут.
Хороший индекс скучный. В нем меньше текста, чем в исходнике, зато почти каждый фрагмент можно цитировать без стыда.
Как устроить реранжирование по шагам
Для поиска по базе знаний реранжирование нужно почти всегда. По эмбеддингам вы часто находите смыслово близкие куски, но среди них остаются лишние страницы, общие правила и фрагменты с похожими словами.
Обычно схема выглядит так:
- Сначала векторный поиск достает 20-50 кандидатов. Если взять меньше, нужный фрагмент легко потерять. Если взять слишком много, реранжер начнет тратить время на шум.
- Потом реранжер получает вопрос и найденные куски. Он оценивает каждую пару "вопрос + фрагмент" и ставит счет, который лучше показывает реальную полезность текста для ответа.
- Дальше стоит отрезать все, что набрало низкий счет. Порог лучше подбирать на своих вопросах, а не брать с потолка.
- В финальную модель лучше отправлять 3-8 лучших кусков. Так ей проще собрать ответ с цитатами и не смешать соседние темы.
Это особенно заметно на коротких запросах. Вопрос вроде "лимит на возврат товара" или "перенос отпуска" звучит слишком общо. Поиск по эмбеддингам может поднять наверх и нужный раздел, и похожие документы, где есть те же слова, но другой смысл.
На длинных вопросах картина другая. Когда пользователь пишет детали, эмбеддинги уже работают лучше, но реранжирование все равно убирает лишние куски. Это снижает риск, что модель склеит ответ из разных документов и добавит лишнее.
Простой пример: сотрудник спрашивает, можно ли перенести неиспользованный отпуск на следующий год. Первый проход может вернуть общий регламент отпуска, памятку для HR и раздел про больничный. После реранжирования обычно остаются только куски с правилом переноса, сроками и исключениями.
Если команда уже гоняет LLM-запросы через единый шлюз, например AI Router, такую схему проще проверять на практике. Можно быстро менять реранжер, смотреть задержку и сравнивать качество на коротких и длинных вопросах без переделки клиентского кода.
Как строить ответ с цитатами
Ответ с цитатами работает только тогда, когда модель не "вспоминает" что-то от себя. Для базы знаний это правило лучше сделать жестким: модель отвечает только по тем фрагментам, которые вы передали в запросе. Если в них нет нужного факта, она так и пишет: "в источниках ответа нет".
Каждому фрагменту дайте короткий и заметный ID. Подойдут простые метки вроде DOC-12, FAQ-03 или POL-7. Тогда модель не будет пересказывать источник расплывчато и сможет ставить ссылку на конкретный кусок текста сразу после спорного утверждения.
Хороший формат ответа простой: тезис, затем цитата в скобках. Например: "Срок хранения логов - 90 дней [POL-7]". Если в одном предложении два разных факта, лучше поставить две цитаты, а не одну общую в конце абзаца.
Общий ответ без ссылок лучше запретить прямо в инструкциях. Иначе генеративная модель почти всегда склеит гладкий текст, который звучит уверенно, но не опирается на документы. Это частая поломка: ответ читается хорошо, а проверить его нельзя.
Модели полезно задать четыре простых правила: не использовать знания вне переданных фрагментов, ставить ID источника после каждого проверяемого факта, не объединять в одну цитату несколько несвязанных утверждений и прямо писать, что данных не хватает, если фрагменты не подтверждают ответ.
После генерации нужен еще один фильтр. Он проверяет не стиль ответа, а связь между фразой и цитатой. Если модель написала "договор можно расторгнуть в любой день [DOC-4]", проверка должна убедиться, что в DOC-4 правда есть это условие, а не просто слова про расторжение.
На практике это решает половину проблем. Даже простой постпроверочный шаг убирает самые неприятные ошибки: выдуманные сроки, неверные лимиты и ссылки не на тот документ.
Пример на типовых вопросах
На типовых вопросах разница между эмбеддингами и генеративной моделью видна быстрее всего. Один запрос может упираться в таблицу в приложении, другой - в свежий FAQ, а третий - сразу в два документа.
Где эмбеддинги попадают точно
Вопрос "Какой срок хранения логов?" часто ломает простой поиск по словам. В базе обычно лежат регламент по логированию и отдельное приложение с таблицей сроков. Эмбеддинги нередко находят приложение лучше, потому что запрос и фрагмент близки по смыслу, даже если в таблице стоит формулировка вроде "срок хранения audit-логов" или "ретенция".
Но одного найденного куска мало. Пользователю нужен не просто фрагмент таблицы, а короткий ответ: какой срок, для каких логов и где это закреплено. Тут генеративная модель полезнее. Она берет срок из приложения, добавляет условие из регламента и собирает один связный ответ с двумя цитатами.
С вопросом "Можно ли платить в тенге?" картина другая. Поиск часто находит FAQ, страницу с условиями оплаты и старую страницу, которая уже неактуальна. Эмбеддинги могут принести все три документа сразу. Потом реранжирование опускает старую страницу вниз и оставляет наверху тот текст, где есть прямой и свежий ответ.
Где модель полезнее, а где ошибается
Вопрос "Что делать при ошибке в счете?" редко живет в одном месте. Один документ описывает порядок проверки, второй хранит шаблон письма, третий объясняет срок ответа. Эмбеддинги обычно достают нужные куски по отдельности. Генеративная модель выигрывает на последнем шаге: она собирает действия в правильном порядке и ставит цитату после каждого пункта.
Ошибка выглядит тоньше. Модель может дать цитату из близкого, но не того раздела. Например, взять абзац про "исправление реквизитов" вместо раздела про спорную сумму в счете. Текст похож, ссылка формально есть, но ответ уводит не туда. Поэтому цитаты нужно проверять не только по близости текста, но и по заголовку раздела, типу документа и смыслу самого действия.
Когда лучше взять гибридную схему
Гибридная схема нужна тогда, когда базе нельзя доверять вслепую и цена ошибки выше пары лишних миллисекунд. Так бывает в банках, телекоме, медицине и в любой внутренней базе, где много похожих инструкций, версий регламентов и почти одинаковых ответов.
В таком случае лучше разделить работу на части. Эмбеддинги пусть быстро находят 20-50 кандидатов. Это дешево, быстро и хорошо работает даже на большой базе. Но они часто тянут рядом лежащие по смыслу фрагменты, хотя в них другой тариф, другой срок или старая версия правила.
Если документов много и тексты похожи друг на друга, после первого поиска нужен реранжер. Он не строит ответ, а просто переставляет найденные фрагменты в более точном порядке. На практике это заметно снижает число "почти верных" попаданий. Для базы знаний это важнее, чем кажется: пользователь не видит разницы между неточным ответом и ошибкой.
Генеративную модель лучше подключать в самом конце. Пусть она берет уже отобранные фрагменты и собирает короткий ответ с цитатами. Так модель меньше фантазирует, реже смешивает документы и не тратит токены на перебор всей базы.
Отдельный режим "показать только найденные фрагменты" тоже стоит оставить. Он нужен, когда сотрудник хочет сам проверить источник, когда ответ должен пройти внутреннюю проверку или когда модель не уверена и лучше ничего не пересказывать.
Одна модель не должна делать весь конвейер сразу. Если она и ищет, и ранжирует, и пишет ответ, вы теряете контроль над ошибкой. Потом трудно понять, где именно сбой: в индексе, в отборе фрагментов или уже в генерации.
Для поиска по базе знаний гибрид обычно выигрывает в реальной работе. Быстрый первичный поиск на эмбеддингах дает скорость, реранжирование добавляет точность, а генеративная модель делает удобный финальный ответ. У каждого шага одна задача, и это почти всегда надежнее, чем просить одну модель угадать все сразу.
Где команды чаще ошибаются
Большая часть проблем начинается не в модели, а в том, как команда готовит базу знаний. Даже хороший поиск быстро теряет смысл, если документы попали в индекс в сыром виде, без структуры, версий и нормальных границ фрагментов.
Ошибки в индексации
PDF часто загружают как сплошной текст. В итоге заголовки, таблицы, сноски и примечания слипаются в один поток. Поиск находит слова, но теряет смысл документа. Если в инструкции есть раздел "Исключения", а рядом в таблице лежат старые лимиты, модель легко соберет ответ из кусков, которые никогда не должны были стоять рядом.
Другая крайность - слишком мелкая нарезка. Когда команда режет текст по 100-150 символов, фрагмент уже не несет законченной мысли. Вопрос про возврат товара может попасть в кусок с фразой "в течение 14 дней", а условие "только для онлайн-заказов" останется в соседнем куске и потеряется.
Еще одна частая ошибка - индекс не обновляют после правок. Документ уже изменили, а поиск все еще тянет старую версию. Для банка, ритейла или телеком-команды это быстро превращается в неверные ответы для клиентов и лишние проверки вручную.
Ошибки в ответе
Даже при хорошем поиске команды часто кладут в промпт слишком много фрагментов. Модель видит 15-20 кусков, часть из них спорит друг с другом, и ответ становится мутным. Обычно лучше дать меньше, но чище: несколько сильных кандидатов после реранжирования почти всегда работают лучше, чем длинная свалка текста.
С цитатами тоже ошибаются постоянно. Цитатой нельзя считать любой соседний абзац или кусок с похожей темой. Цитата должна прямо подтверждать конкретную фразу в ответе. Если в ответе есть сумма, срок или условие, рядом должна быть точная строка из источника, а не общий абзац из того же раздела.
Нормальная система держится на простых вещах: аккуратный парсинг, разумный размер фрагмента, свежий индекс и строгая проверка цитат. Без этого спор между эмбеддингами и генеративной моделью теряет смысл.
Быстрая проверка перед запуском
Запускать поиск по базе знаний без короткого теста - плохая идея. На демо почти все выглядит убедительно, а на живых вопросах быстро всплывают пустые ответы, неверные цитаты и лишние траты на модель.
Для первой проверки хватает 30-50 реальных вопросов от сотрудников или клиентов. Лучше брать не "идеальные" формулировки, а обычные: с ошибками, короткими уточнениями и расплывчатыми словами. Так вы увидите, как система ведет себя в нормальной работе, а не в лаборатории.
Перед запуском стоит проверить пять вещей:
- у каждого вопроса есть эталонный источник: конкретный документ, раздел и версия;
- вы отдельно смотрите поиск, реранжирование и финальный ответ, а не только общий результат;
- вы считаете цену одного ответа, включая поиск, реранжирование и генерацию;
- система умеет молчать, если не нашла достаточно сильное подтверждение в базе;
- в команде заранее решено, кто обновляет индекс после новых файлов, правок и удаления старых версий.
Особенно важен пункт с "молчанием". Если модель отвечает наугад, ошибка выглядит правдоподобно и дольше живет в проде. Для базы знаний безопаснее ответ вроде "подтверждение не найдено", чем уверенная выдумка с чужой цитатой.
Еще один частый промах - тестировать только точность и забывать про цену. Один и тот же вопрос можно решить условно за 2 цента и за 20. На сотнях тысяч запросов разница уже неприятная. Если команда сравнивает несколько моделей через OpenAI-совместимый шлюз вроде AI Router, проще прогнать один набор вопросов без смены SDK и сразу увидеть, где переплата не дает заметного прироста качества.
Если после правки документа индекс обновляется через неделю, весь тест теряет смысл. До запуска нужен простой и ясный процесс: кто загружает новую версию, как помечают старую и когда система перестает на нее ссылаться.
С чего начать на практике
Возьмите 30-50 реальных вопросов, которые уже задают люди. Смешайте обращения из поддержки, частые вопросы от продаж и выдержки из внутренних регламентов. Так вы проверите не красивое демо, а живую нагрузку: короткие фактологические запросы, длинные вопросы с условиями и спорные формулировки.
Удобно разбить набор на несколько типов: простой факт вроде "Какой срок ответа по заявке?", пошаговый вопрос вроде "Что сделать, если клиент просит удалить данные?", вопрос с исключением вроде "Когда правило не действует?" и разговорный запрос, где слова пользователя не совпадают с текстом документа.
Дальше прогоните один и тот же набор через три схемы. Первая - поиск на эмбеддингах с реранжированием. Вторая - гибрид: обычный поиск по словам плюс векторный поиск, а потом реранжирование. Третья - генеративный ответ по найденным фрагментам с цитатами. Не меняйте выборку по ходу теста, иначе сравнение быстро потеряет смысл.
Результаты удобно свести в одну таблицу:
| Схема | Точность | Цена | Задержка | Качество цитат |
|---|---|---|---|---|
| Эмбеддинги | ||||
| Гибрид | ||||
| Генеративный ответ |
Смотрите не только на долю верных ответов. Часто система пишет правдоподобно, но ссылается не на тот документ или тянет цитату из соседнего абзаца. Для базы знаний это плохой признак. Если источник плавает, пользователи быстро перестают верить и поиску, и ответу.
Если команда гоняет один и тот же сценарий через несколько моделей и провайдеров, не стоит переписывать интеграцию под каждый тест. Через AI Router на airouter.kz можно сменить base_url на api.airouter.kz и сравнивать варианты без переделки SDK, кода и промптов. Это особенно удобно на этапе замера, когда важна честная проверка, а не новая сборка окружения.
После теста оставьте самый простой вариант, который стабильно находит верный источник. Если эмбеддинги уже дают точный документ и нормальные цитаты, не надо усложнять схему. Если они часто промахиваются на синонимах, длинных вопросах или исключениях из правил, тогда есть смысл добавлять гибридный поиск и генеративный слой.
Часто задаваемые вопросы
Что лучше для базы знаний: эмбеддинги или генеративная модель?
Эмбеддинги ищут фрагменты по смыслу, даже если слова в вопросе и документе не совпадают. Генеративная модель не ищет лучше сама по себе, зато умеет собрать из найденных кусков короткий ответ с нормальной формулировкой и цитатами.
Почему обычный поиск по словам часто промахивается?
Потому что люди спрашивают разговорно, а документы пишут канцелярским или техническим языком. Запрос про восстановление доступа может не совпасть по словам со статьей про перевыпуск второго фактора, хотя смысл один.
Когда уже нужен гибридный поиск, а не один векторный слой?
Берите гибрид, если у вас много похожих документов, старых версий и исключений из правил. Сначала поиск быстро достает кандидатов, потом реранжирование убирает лишнее, а модель пишет финальный ответ только по лучшим фрагментам.
Сколько фрагментов стоит отдавать модели на финальный ответ?
Обычно хватает 3–8 сильных фрагментов после реранжирования. Если положить 15–20 кусков, модель чаще смешивает темы, цепляет старые версии и пишет мутный ответ.
Как правильно резать документы на фрагменты?
Не режьте текст по голым символам, если не хотите терять смысл. Делите по разделам, шагам инструкции, отдельным правилам и примечаниям, чтобы один фрагмент отвечал на один вопрос целиком.
Что делать с дублями и устаревшими версиями в индексе?
Сначала уберите навигацию, шаблонные блоки, пустые страницы и повторы. Потом храните у каждого фрагмента дату, версию и тип источника, чтобы поиск не путал свежий регламент со старым черновиком.
Зачем вообще нужны цитаты в ответе?
Без цитат человек не понимает, откуда взялся ответ и можно ли ему верить. Удобнее всего ставить короткий ID фрагмента сразу после проверяемого факта, чтобы спорный момент можно было открыть и проверить за минуту.
Что делать, если модель не нашла прямого подтверждения?
Попросите модель отвечать только по переданным фрагментам и прямо писать, что подтверждения нет в базе. Такой отказ полезнее, чем гладкий, но выдуманный ответ, который потом уйдет в работу как будто он верный.
Как проверить систему до запуска в прод?
Для первого прогона хватит 30–50 живых вопросов от сотрудников или клиентов. Смотрите не только на точность, но и на цену ответа, задержку, качество цитат и на то, умеет ли система молчать, когда данных мало.
Можно сравнить несколько моделей без переделки интеграции?
Да, если вы уже работаете через OpenAI-совместимый шлюз вроде AI Router. Достаточно сменить base_url на api.airouter.kz и прогнать один и тот же набор вопросов через разные модели без правки SDK, кода и промптов.