Пакетный инференс или онлайн вызовы для ночных задач
Пакетный инференс подходит для ночной обработки, но не всегда выигрывает у онлайн вызовов. Разберём извлечение, категории и черновики.
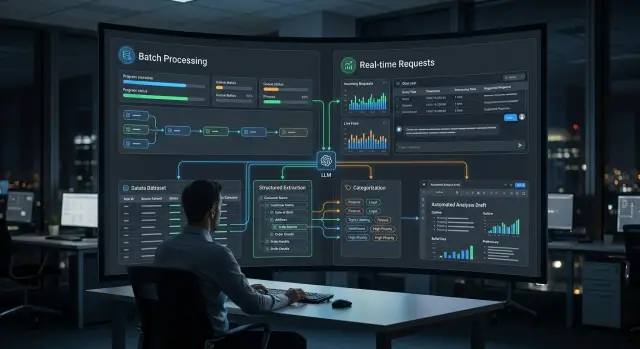
Где возникает выбор
Выбор обычно появляется к вечеру, когда в очереди лежат сотни или тысячи похожих задач. Днём система собирает письма, заявки, карточки товаров, договоры и ответы операторов. Ночью всё это удобно прогнать одним потоком: извлечь поля, разложить по темам, собрать черновики ответов или подготовить утренний отчёт.
Пакетный инференс подходит там, где никто не ждёт ответ через две секунды. Если документ попадёт в отчёт к 8 утра, бизнес ничего не теряет. Так часто обрабатывают входящую почту, архив чатов, счета, отзывы, внутренние сводки и большие наборы документов на категоризацию.
Но часть задач нельзя откладывать. Если клиент пишет в поддержку, сотрудник колл-центра или врач открывает карточку, задержка сразу мешает работе. В таких случаях нужны онлайн вызовы LLM: модель отвечает в момент запроса, а не по ночному расписанию.
До утра обычно не откладывают подсказки оператору во время диалога, проверку текста перед отправкой клиенту, быстрый поиск ответа по базе знаний и маршрутизацию срочного обращения в нужную команду.
Скорость ответа сильно меняет экономику процесса. Для онлайн режима важна каждая секунда: паузу пользователь замечает почти сразу. Для ночной обработки данных важнее другое - сколько задач пройдёт за окно в 4-6 часов, во сколько обойдётся весь прогон и как система переживёт всплеск объёма в конце месяца.
Один режим почти никогда не закрывает весь процесс. Письма можно классифицировать ночью, но срочные жалобы лучше разбирать сразу. Черновики ответов можно готовить пакетно, а финальный вариант показывать сотруднику по запросу. Даже внутри одной цепочки извлечение полей часто уходит в пакет, а короткая генерация для человека остаётся онлайн.
Выбор идёт не между "старым" и "новым" подходом, а между разными частями одной работы. Достаточно ответить на простой вопрос: что должно произойти сразу, а что спокойно дождётся утра. Если команда использует единый API-шлюз вроде AI Router, где можно менять маршрут запросов и не трогать привычные SDK, код и промпты, держать рядом оба режима заметно проще.
Когда пакетная обработка выигрывает
Пакетный инференс лучше там, где результат нужен не сейчас, а к конкретному часу. Если данные копятся весь день, ночной прогон почти всегда проще по цене, контролю и поддержке. Команда один раз ставит задачи в очередь, задаёт лимиты и утром разбирает готовый массив ответов, а не ловит тысячи мелких запросов в рабочее время.
Хороший пример - извлечение полей из большого архива файлов. Допустим, у вас есть 80 000 договоров, актов и писем, и из каждого нужно достать номер, дату, сумму и тип документа. Пользователь у экрана не сидит, поэтому архив можно спокойно разбить на части, чистые PDF отправить в более дешёвую модель, а сканы и сложные таблицы - в более сильную. В таком режиме меньше суеты: проще включить повторы, проверить схему ответа и отловить сбойные файлы.
Массовая категоризация писем, заявок и отзывов тоже хорошо ложится в пакет. Когда правило одно и то же для десятков тысяч записей, пакетный запуск даёт ровную картину по всей выборке. Это удобно для саппорта, банковских операций, ритейла и госуслуг, где утром уже нужен список тем, приоритетов и спорных случаев.
С черновиками отчётов логика такая же. Данные за день уже закрыты, метрики собраны, события известны. Значит, можно ночью сгенерировать первый вариант отчёта по филиалам, продуктам или очередям обращений, а утром редактор или аналитик только правит формулировки. Лишние 10-15 минут тут ничего не решают, если текст готов к началу рабочего дня.
Ещё один сильный сценарий для пакетной обработки - повторный прогон после правки промпта или схемы. Добавили новое поле, изменили рубрики, ужесточили формат ответа - и сразу видно, что поменялось на всей исторической выборке. В онлайне такой пересчёт быстро превращается в путаницу: часть данных уже обработана по старым правилам, часть по новым. В ночном пакете версия одна, и сравнивать результаты проще.
Когда лучше онлайн вызовы
Онлайн вызовы нужны там, где ответ меняет действие прямо сейчас. Если оператор ждёт подсказку, клиент смотрит на форму, а менеджер должен принять решение в течение минуты, ночной прогон уже не подходит.
Самый понятный пример - поддержка. Клиент пишет в чат, а оператор получает короткую выжимку письма, тон сообщения и черновик ответа через несколько секунд. Человек тут же правит текст и отправляет его. Если перенести это в пакетный режим, смысл пропадает: ответ нужен во время разговора, а не утром.
То же касается проверки документа в момент загрузки. Пользователь прикрепляет файл, а система сразу видит, что не хватает страницы, файл не читается или в тексте есть признаки другого типа документа. Это особенно полезно в банке, страховании и HR-процессах, где ошибка на входе потом ломает весь маршрут.
Онлайн вызовы LLM нужны и там, где классификация запускает следующий шаг. Допустим, входящее письмо надо сразу отправить в юридический отдел, в продажи или в поддержку. Пока модель не определила тип запроса, процесс стоит. Для таких развилок задержка в 2-5 секунд обычно лучше, чем очередь до ночной обработки.
С генерацией черновиков та же история. Если менеджер открывает карточку клиента и хочет сразу получить основу письма, заметки по звонку или краткий отчёт по переписке, ответ нужен немедленно. Черновик почти всегда правят вручную, и это нормально. Здесь важна не идеальность, а быстрый первый вариант.
Онлайн режим обычно выбирают, когда человек не может двигаться дальше без ответа, система должна проверить данные на входе, от категории зависит маршрут заявки или текст нужен для немедленной правки.
У онлайна есть своя цена: выше требования к задержке, стабильности и лимитам. Зато он хорошо работает в цепочке из нескольких моделей. Например, быструю модель можно поставить на первичную категоризацию документов, а более сильную - на генерацию черновиков. Если всё это идёт через один OpenAI-совместимый эндпоинт, общий поток проще поддерживать.
Как сравнить оба подхода на одной задаче
Сравнение ломается в тот момент, когда команды тестируют разные входные данные. Для честной проверки возьмите один и тот же набор документов: например, 5 000 писем, где нужно вытащить поля, присвоить категорию и собрать короткий черновик ответа. Не меняйте промпт, модель, температуру и правила постобработки между прогонами.
Если вы сравниваете пакетный инференс и онлайн вызовы LLM, неизменным должно остаться всё, кроме режима запуска. Иначе вы проверите не способ обработки, а случайную смесь факторов.
Перед тестом стоит зафиксировать четыре вещи:
- один датасет с понятной разметкой;
- одни и те же промпты и параметры модели;
- одинаковые правила повтора при сбоях;
- единый способ считать ошибки.
Дальше смотрите не только на общее время. Для извлечения важна доля пропущенных полей и неверных значений. Для категоризации нужна точность по классам, а не только средний процент. Для генерации черновиков отдельно отмечайте тексты, которые нельзя отправить без правки: пустые ответы, обрывки, повторы, не тот язык, лишние выдумки.
Средняя стоимость тоже легко вводит в заблуждение. Считайте цену на 1 000 документов и на весь ночной прогон. Если часть запросов уходит в повтор, итог быстро растёт. Таймауты и пустые ответы лучше считать отдельно, а не прятать внутри общего процента ошибок. Именно они обычно мешают отчёту выйти вовремя.
Проверьте два режима нагрузки. Первый - обычный объём, который система видит почти каждый день. Второй - ночной пик, когда документов в 5-10 раз больше: конец месяца, закрытие смены, пакет писем после выходных. На малом объёме онлайн режим часто выглядит быстрее и удобнее. На пике картина меняется: растёт очередь, увеличивается число повторов, и окно ночной обработки может не закрыться.
Небольшой пример: 2 000 писем проходят онлайн за 40 минут, а пакетно за 55. Но на 20 000 писем онлайн уже даёт много таймаутов и заканчивает работу почти к полудню, а пакетный прогон укладывается в ночь с предсказуемой ценой. Это уже рабочий вывод, а не спор о вкусах.
Если команда использует единый шлюз, сравнение провести проще: можно оставить один SDK и один эндпоинт, а менять только маршрут и режим запуска. Тогда легче понять, где разница вызвана архитектурой, а где самой моделью.
Сценарий: ночной разбор писем и утренний отчёт
Представьте банк или крупный ритейл, где за день накапливаются тысячи писем, вложений и заявок из формы на сайте. Днём сотрудники отвечают на срочные случаи, а основной массив разбирается ночью, когда нет пиковых очередей и никто не ждёт ответ за секунды.
Ночной прогон обычно начинается после закрытия операционного дня. Система забирает новые письма из почты, PDF и сканы из вложений, а также заявки из CRM или веб-форм. Дальше модель делает вполне приземлённую работу: вытаскивает номер обращения, тему, имя клиента, тип проблемы, срок и нужный отдел. Если данные чувствительные, команда может заранее маскировать PII и вести аудит-логи. Для компаний в Казахстане это часто обязательное требование, а не лишняя формальность.
После извлечения полей модель ставит рубрику каждому обращению. Например, она отделяет жалобы на платёж, вопросы по доставке, запросы на закрывающие документы и письма, которые вообще не требуют ответа. На этом шаге хорошо видна разница между чистыми и спорными случаями. Если письмо похоже сразу на две темы или во вложении плохой скан, системе лучше не гадать, а пометить запись для ручной проверки утром.
Следом можно собрать короткую сводку для руководителя смены или аналитика: сколько обращений пришло за ночь, какие рубрики выросли сильнее обычного, какие случаи ушли в ручную проверку и где уже готов черновик ответа.
Утром сотрудник открывает не сырые данные, а готовую рабочую ленту. Он быстро просматривает спорные письма, правит рубрики, удаляет явные ошибки распознавания и утверждает сводку. На практике это экономит не абстрактное "время вообще", а вполне заметные 20-40 минут на старте дня у каждой смены.
Если делать тот же сценарий через онлайн вызовы LLM, каждое письмо пришлось бы обрабатывать сразу после получения. Для срочных заявок это полезно, но для ночной отчётности чаще лишнее. Пакетный инференс лучше работает там, где итог нужен к утру, объём большой, а человеку всё равно надо проверить только пограничные случаи, а не весь поток.
Что считать в деньгах и времени
Цена ночного прогона почти всегда выше, чем кажется по тарифу за токены. Сначала посчитайте расход на один документ: входной текст, системный промпт, служебный контекст и ответ модели. Для извлечения полей ответ обычно короткий, для категоризации ещё короче, а генерация черновика чаще всего съедает больше всего из-за длинного вывода.
Если документы сильно отличаются по размеру, не берите одно среднее число. Лучше замерить 100-200 реальных примеров и посмотреть обычный случай и верхние 5% по объёму. Иначе ночной прогон легко выйдет за лимит по времени, хотя расчёт на бумаге выглядел нормально.
Обычно достаточно считать четыре вещи:
- токены на один документ по каждому шагу;
- общий объём документов за ночь;
- долю повторов после таймаутов, лимитов по скорости и неудачных ответов;
- окно, в которое задача должна уложиться, например с 01:00 до 05:00.
Простой пример: у вас 40 000 писем. На извлечение уходит 900 входных токенов и 120 выходных, на категоризацию 300 и 20, на черновик ответа 1 100 и 350. Итого 2 790 токенов на письмо, или 111,6 млн токенов за ночь. Если 3% запросов придётся повторить, объём вырастет почти до 115 млн.
Дальше смотрите не только на цену за миллион токенов, а на реальную скорость. При эффективной пропускной способности 8 000 токенов в секунду такой прогон займёт около 4 часов. Если окно у вас 3 часа, задача уже не проходит, даже если бюджет по деньгам устраивает.
На больших партиях пакетный инференс обычно выгоднее. Можно взять модель подешевле для извлечения и категоризации, а сильную оставить только для черновиков. Если команда работает через AI Router, это удобно проверять на одном OpenAI-совместимом API: онлайн поток можно держать на одной модели, а ночной прогон отправлять на другой без переделки кода и с ежемесячным B2B-инвойсингом в тенге.
На мелких задачах картина меняется. Если за ночь приходит 300 документов, разница в цене между батчем и онлайн вызовами может быть небольшой. Тогда больше денег съедают повторы, проверка результатов и разбор сбоев. В таких случаях удобство и предсказуемое время ответа иногда важнее экономии на токенах.
Хороший расчёт выглядит скучно, и это нормально. Если в нём есть токены, повторы, лимиты и жёсткое окно запуска, он почти всегда ближе к жизни, чем сравнение двух прайсов в таблице.
Ошибки, которые ломают ночной прогон
Ночной прогон чаще ломается не из-за модели, а из-за очереди, логики повторов и плохих тестовых данных. Днём система выглядит нормально, а утром команда видит пустой отчёт, дубли или часть документов без категории.
Самая частая ошибка - свалить срочные и несрочные задачи в одну очередь. Тогда извлечение полей из архива, категоризация старых документов и генерация черновиков писем начинают спорить за одни и те же лимиты. В итоге срочный поток ждёт вместе со всем остальным. Если утром нужен отчёт по новым письмам, он не должен стоять за ночной переработкой старого архива.
Не менее часто команды теряют прогресс из-за отсутствия промежуточного сохранения. Допустим, пайплайн сначала извлекает данные, потом ставит категорию, потом пишет черновик ответа. Если последний шаг падает в 4:30, не нужно заново прогонять все три этапа для каждой записи. Сохраняйте результат после каждого шага, версию промпта и статус задачи. Тогда повторный запуск доберёт только то, что не дошло до конца.
Ещё одна дорогая ошибка - каждую ночь гонять весь массив данных, хотя реально изменились только новые или обновлённые записи. Это быстро съедает бюджет и окно обработки. Хуже другое: повторный прогон старых документов может дать другие ответы, если команда поменяла промпт или модель, и утром цифры в отчёте уже не сходятся с прошлой ночью.
Тесты тоже часто подводят. В песочнице всё выглядит чисто: один язык, ровный текст, понятная структура. В реальной почте и документах всё иначе: пересланные цепочки, сканы плохого качества, смесь русского и казахского, пустые поля, лишние подписи, таблицы из PDF. Если в тестовом наборе нет такой грязи, ночной прогон почти наверняка споткнётся.
Перед запуском полезно проверить четыре вещи: разделены ли очереди по срочности, сохраняется ли результат каждого шага, обрабатываете ли вы только новые и изменённые записи, и есть ли набор сложных примеров для проверки.
Если команда запускает пакетный инференс через единый шлюз, стоит логировать модель, версию промпта, число ретраев и расход токенов по шагам. Тогда утром видно не только сам факт сбоя, но и его точное место.
Перед запуском
Ночной прогон выглядит простым только на бумаге. На деле он работает хорошо, когда у команды есть чёткие рамки: к какому времени должен прийти результат, кто проверит спорные ответы и что делать, если часть данных не обработалась.
Пакетный инференс подходит не для любой задачи. Если человек ждёт ответ в интерфейсе, лучше оставить онлайн вызовы LLM. А вот для разбора документов, писем, заявок и подготовки черновиков к утру пакетный режим часто удобнее и дешевле.
Перед запуском полезно пройтись по короткому списку:
- есть ли понятный дедлайн, а не просто формула "ночью обработаем";
- не требует ли задача мгновенного ответа;
- умеет ли команда мерить качество по понятным метрикам;
- есть ли план на сбои и сомнительные случаи.
Чаще всего ломается именно последний пункт. Модель обработала 92% массива, а оставшиеся 8% застряли из-за длинных вложений, плохого OCR или спорной формулировки. Если команда не решила это заранее, утренний отчёт получится дырявым.
Полезно заранее выбрать и небольшой контрольный набор. Например, 200 писем за прошлую неделю: часть на извлечение полей, часть на категоризацию документов, часть на генерацию черновиков ответа. На таком наборе быстро видно, где модель путает темы, где пропускает реквизиты, а где пишет слишком общий текст.
Если вы работаете в банке, телекоме или госсекторе, добавьте ещё один практический вопрос: где будут лежать данные и логи. Для команд в Казахстане это часто обязательное условие. В таких сценариях заранее смотрят на хранение данных внутри страны, маскирование PII, аудит-логи и лимиты по ключам, чтобы ночной прогон не превратился в утреннюю проблему.
Если хотя бы на два пункта ответ расплывчатый, запуск лучше отложить на день и закрыть пробелы.
Что делать дальше
Не пытайтесь сразу перестроить весь контур. Возьмите одну повторяемую задачу, где легко увидеть результат: извлечение полей из писем, категоризацию документов или генерацию черновиков для утреннего отчёта. Этого достаточно, чтобы понять, где пакетный инференс даёт выигрыш, а где лучше оставить онлайн путь.
Пилот лучше делать на одинаковых данных. Возьмите один и тот же набор писем или документов за 5-7 дней, зафиксируйте промпт и сравните два режима без поблажек. Если в одном тесте модель лучше, а в другом ей просто дали более лёгкий набор, выводы будут пустыми.
Смотрите не только на качество ответа. Для ночного прогона обычно важнее общая длительность, число повторных запросов, цена на тысячу документов и доля случаев, которые всё равно уходят на ручную проверку. Иногда онлайн вызовы LLM дают чуть более быстрый отклик на одном документе, но сильно проигрывают, когда ночью нужно прогнать 40 000 писем подряд.
После такого теста решение обычно становится простым. Срочное оставляют в онлайне: ответы оператору, подсказки в интерфейсе, быстрые проверки по одному документу. Массовое уводят в batch: ночную обработку, переоценку архива, черновики отчётов и разбор больших очередей.
Если у вас смешанный сценарий, не спорьте о "правильной" архитектуре. Разделите поток. Пусть онлайн обслуживает то, что человек ждёт сейчас, а пакетная обработка забирает всё, где допустима задержка до утра. Такой расклад обычно спокойнее в эксплуатации и проще для бюджета.
Командам в Казахстане часто мешает не сама логика пайплайна, а зоопарк провайдеров, ключей и биллинга. В таком случае можно использовать единый шлюз вроде AI Router: один OpenAI-совместимый эндпоинт, доступ к разным моделям, хранение данных внутри страны и оплата в тенге. Для пилота это удобно, потому что один и тот же сценарий можно прогнать через разные модели без переписывания интеграции.
Хороший следующий шаг совсем простой: запустите маленький ночной прогон на этой неделе, а утром разберите цифры с командой. Через несколько дней у вас будет не мнение, а нормальное сравнение по цене, времени и качеству.