Отказ внешнего LLM-провайдера: план действий на день
Отказ внешнего LLM-провайдера: пошаговый план на день сбоя - как переключить роутинг, ввести лимиты, упростить функции и собрать команды.
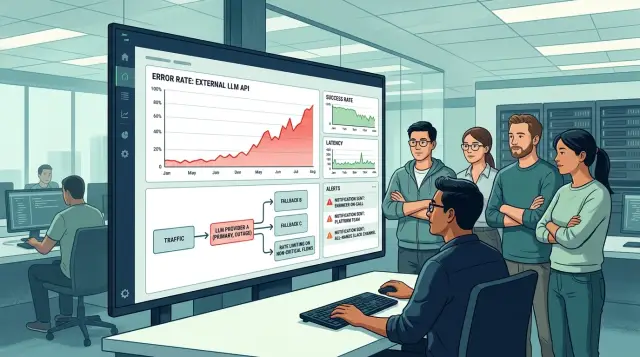
Что ломается в первые минуты
Первыми обычно падают сценарии, где ответ нужен сразу: чат поддержки, подсказки оператору, поиск с генерацией ответа, проверка текста перед отправкой. Пользователь не видит "сбой провайдера". Он видит кнопку, которая крутится слишком долго, или сообщение об ошибке.
Асинхронные задачи поначалу создают ложное ощущение, что все живо. Саммари звонков, пакетная классификация, ночные отчеты и фоновые агенты не останавливаются мгновенно. Они копятся в очереди, и через 10-20 минут проблема добирается до воркеров, брокера сообщений и лимитов на соединения.
Очередь растет сразу в нескольких местах: на входе API, в ретраях, в пуле воркеров и в клиентских таймаутах. Если приложение ждет ответ 30 секунд и делает еще 2-3 повтора, один упавший маршрут быстро забивает ресурсы, хотя приложение формально "работает".
Из-за этого внешний инцидент легко принять за баг в своем продукте. Ошибки приходят неровно: у одного пользователя timeout, у другого 429, у третьего пустой ответ или обрыв на середине текста. Фронтенд смотрит на спиннеры, бэкенд ищет регресс после релиза, а причина снаружи.
Статус-страница провайдера часто запаздывает. У вас уже растут задержка и ошибки, а снаружи все еще "зеленое". Ждать подтверждения опасно: за это время ретраи раздувают трафик, а зависимые сервисы начинают сыпаться следом.
Если у вас уже есть единый шлюз для роутинга моделей, первые минуты проходят спокойнее: видно, что падает один маршрут, а не весь контур. Если такого слоя нет, смотрите на свои метрики. Резкий рост ошибок на одном провайдере при нормальной работе базы, очередей и сети - уже достаточный повод считать инцидент внешним и действовать сразу.
Кто берет управление
Когда падает внешний провайдер, больше всего мешает не сама ошибка, а хаос внутри команды. Если решения одновременно принимают платформа, продукт и поддержка, время уходит на споры и дублирование.
С первой минуты нужен один дежурный по инциденту. Он не чинит все лично. Он расставляет приоритеты, фиксирует текущий статус и назначает следующий шаг. Если мнения расходятся, последнее слово за ним.
Роли стоит развести в первые 10 минут. Платформенная команда проверяет ошибки, квоты, таймауты и запасные маршруты. Продукт решает, какие сценарии надо сохранить любой ценой, а какие можно временно урезать. Поддержка готовит одно понятное сообщение для внутренних команд и собирает реальные кейсы от пользователей, а не слухи из чатов.
Нужен один канал инцидента: один чат, один созвон или одна комната, но не три параллельные ветки. Все обновления идут туда. Там же ведите короткий журнал: время начала, первые симптомы и то, что увидели пользователи. Например: 09:12 - выросли 5xx у одного провайдера; 09:15 - ответы идут дольше 20 секунд; 09:18 - чат поддержки перестал отвечать на длинные запросы.
Одного ответственного, одного канала и короткого журнала обычно хватает, чтобы не потерять первый час на суету.
Как понять масштаб сбоя
Сначала соберите картину по симптомам, а не по ощущениям. Один и тот же сбой может выглядеть по-разному: где-то растет задержка, где-то идут таймауты, а где-то 5xx появляются только на одной модели.
Быстро разложите ошибки по четырем срезам: модель, регион или зона выхода в сеть, тип запроса и время хотя бы с шагом 5-10 минут. Так почти сразу видно, проблема общая или бьет в узкое место. Если падает одна модель у одного провайдера, это совсем не то же самое, что массовые таймауты по всем маршрутам.
Потом отделите отказ провайдера от своих проблем. Проверьте три простые вещи: не истек ли API-ключ, не сломал ли что-то свежий релиз и нет ли сетевой аварии между вашим контуром и внешним API. Ошибаются тут часто: обвиняют провайдера, а потом находят новый rate limit, прокси или неверный base_url.
Смотрите не только на процент ошибок. Если медианная задержка выросла вдвое, а 5xx пока мало, инцидент уже начался. Для LLM это обычный ранний сигнал. Полезно сравнить долю таймаутов, p95 и p99 задержки, долю 5xx и число ретраев на один успешный ответ.
Отдельно проверьте, какие функции уже ушли на запасной маршрут, а какие все еще висят на основном провайдере. Через 15-20 минут у команды должен быть короткий статус: что сломано, где сломано, кого задело и какие сценарии уже держатся на резерве.
Как переключать роутинг
При сбое внешнего LLM-провайдера не переводите весь трафик на первую доступную замену. Так легко сломать уже рабочие сценарии и сжечь квоты. Сначала снимите лишнюю нагрузку: остановите пакетные задачи, переиндексацию, автосводки, ночные джобы и все, без чего продукт проживет несколько часов.
Потом разделите трафик по важности. Критичные сценарии, где ответ нужен пользователю прямо сейчас, переводите первыми. Обычно это чат поддержки, поиск по базе знаний и внутренние помощники для операторов. Генерацию длинных отчетов, переписывание текстов и другие тяжелые операции лучше временно отложить.
Для каждого критичного сценария заранее определите основную запасную модель и второй фолбэк. Смотрите не только на качество, но и на цену, размер контекстного окна и доступный RPM. На новую схему сначала пустите 1-5% живого трафика и только потом расширяйте переключение.
Во время проверки следите не только за кодом ответа. Смотрите на длину ответов, число пустых или оборванных сообщений, стабильность JSON-формата, среднюю задержку и странные срабатывания фильтров. Запасная модель может отвечать "успешно", но хуже держать структуру и сильнее многословить.
И еще один практичный шаг: зафиксируйте временные правила до конца инцидента. Запишите, какие модели активны, какой фолбэк идет первым, какие лимиты действуют и кто может менять схему. Иначе через час команды начнут переключать трафик в разные стороны.
Где вводить лимиты
В день сбоя лимиты нельзя ставить одинаково для всех. Сначала режут то, что ест много токенов и не влияет напрямую на деньги, поддержку клиентов или ежедневные операции. Иначе система быстро упрется в очередь, а полезные запросы будут ждать вместе со второстепенными.
Первый кандидат - длинный контекст. Если у вас есть чаты на 30-50 сообщений, большие вложения, длинные системные промпты или генерация на тысячи токенов, урежьте это сразу. Даже простое снижение максимального размера входа и ответа часто снимает заметную часть нагрузки уже в первые 10-15 минут.
Параллельность тоже лучше снижать выборочно. Внутренние помощники, автоанализ звонков, черновики писем и другие не срочные сценарии могут работать медленнее. А вот платежные проверки, поддержка, антифрод и операционные цепочки должны получить свой запас пропускной способности.
Обычно хватает четырех мер. Снизьте max input tokens и max output tokens для не критичных маршрутов. Уменьшите число одновременных запросов для внутренних сервисов и фоновых задач. Переведите аналитику и переобогащение данных в очередь. И обязательно поставьте жесткий rate limit на каждый API-ключ, чтобы один зациклившийся воркер не выбил всю систему.
Последний пункт недооценивают чаще всего. Ошибка в ретраях или один неудачный воркер за пару минут создают всплеск по одному ключу и забирают весь доступный объем. Отдельные лимиты по ключам, простая квота и circuit breaker в такой день полезнее, чем общий лимит на весь кластер.
Какие функции урезать
Во время инцидента не пытайтесь сохранить весь продукт в прежнем виде. Это почти всегда бьет сразу по задержке, счету и стабильности. Быстрее работает другой подход: оставить только те сценарии, где ответ влияет на деньги, заявку, заказ или срок ответа клиенту.
Сначала уберите все, без чего пользователь все еще может завершить действие. Повторные генерации, кнопки "попробовать еще раз", альтернативные версии ответа и автоматический перефраз съедают много запросов и редко спасают день. В обычное время это приятно. Во время сбоя - лишняя роскошь.
Старые диалоги тоже стоит тронуть первыми. Если сервис сжимает длинную историю в фоновой суммаризации, временно отключите ее. Намного дешевле хранить несколько последних сообщений и работать с коротким контекстом, чем тратить лимиты на обслуживание длинных веток, которые никто не читает целиком.
LLM стоит оставить там, где действительно нужен разбор свободного текста. FAQ, статусы заказа, проверку полей формы и маршрутизацию обращений по тегам на один день можно вернуть на правила, поиск и обычную логику приложения.
В чате поддержки просите модель отвечать короче. Не нужен длинный дружелюбный текст на 2 000 знаков. Нужны статус, следующий шаг и список того, что надо приложить. Часто ответ на 300-400 знаков решает задачу лучше и снимает нагрузку быстрее.
Как сообщить командам без шума
В день сбоя хуже самой поломки только поток противоречивых сообщений. Один человек пишет, что "все упало". Другой отвечает, что проблема только у части клиентов. Третий уже обещает восстановление через 15 минут. Так команды теряют время и начинают спорить вместо работы.
Первое сообщение должно быть коротким и точным. Назовите затронутые продукты и уровень риска для бизнеса. Например: не работает чат поддержки, ответы во внутреннем помощнике идут с большой задержкой, пакетные задачи поставлены на паузу, риск высокий для клиентских сценариев и средний для внутренних.
Дальше дайте один понятный статус: что сломалось, что команда уже сделала, что проверяет сейчас и когда будет следующее обновление. Этого хватает для первого касания. Если трафик уже ушел на резервный маршрут, лимиты снижены, а дорогие функции отключены, напишите это прямо. Людям нужен факт, а не длинное объяснение.
Хороший ритм сообщений гасит шум лучше любого длинного отчета. Назначьте конкретное время следующего обновления, даже если новостей пока мало: через 15 минут, в 12:30, после проверки очереди запросов. Тогда инженеров не будут дергать каждые две минуты в личных чатах.
Поддержку и аккаунт-команды предупредите отдельно. Им не нужен технический разбор. Им нужен рабочий текст для клиентов: что недоступно, у кого проявляется проблема, есть ли обходной путь и чего нельзя обещать. Если чат отвечает медленнее, но не полностью недоступен, они должны говорить именно так.
Со сроками лучше быть сухими. Не пишите "починим через 15 минут", если это пока догадка. Лучше написать "следующее обновление в 12:30".
Пример: чат поддержки в день сбоя
Клиент пишет в чат банка: "Не проходит платеж, что делать?" Обычно бот отвечает за 4-6 секунд, но сейчас пауза тянется до 20. Для пользователя это уже сбой, даже если система еще не легла полностью.
Команда не ждет полной остановки. Она сразу переводит поток на запасную модель и делит запросы по сложности. Простые вещи вроде статуса заявки, лимитов, часов работы и сброса пароля остаются у бота. Сложные случаи, где нужна длинная цепочка рассуждений или точная работа с контекстом, уходят на второй маршрут.
Чтобы снять нагрузку, бот меняет режим ответа. Он пишет короче, не добавляет лишнюю персонализацию и не предлагает необязательные подсказки в конце. Если раньше ответ занимал 8-10 предложений, теперь это 3-4 короткие фразы и одно действие для клиента. Такой шаг часто экономит токены и снижает очередь уже в первые минуты.
Операторы поддержки тоже получают простой шаблон для ручного перехвата. В нем всего четыре вещи: признать задержку без длинных объяснений, дать один следующий шаг, назвать срок следующего ответа и передать диалог человеку, если бот ошибся два раза подряд.
Через час картина обычно яснее. Если очередь спала, команда постепенно возвращает функции: сначала персонализацию, потом более длинные ответы и только после этого сложные сценарии вроде суммаризации истории обращения. Это безопаснее, чем резко вернуть все сразу и снова уткнуться в лимиты.
Частые ошибки в такой день
Чаще всего команда теряет время не на сам сбой, а на резкие движения. Самая дорогая ошибка - отправить весь поток в одного запасного провайдера и считать, что вопрос закрыт. Через 10-20 минут вы получаете ту же проблему в другом месте: очередь растет, ответы дорожают, а часть функций ведет себя непредсказуемо.
Вторая ошибка - оставить старые лимиты, когда задержка уже выросла. Если до сбоя система спокойно держала 50 запросов в секунду, это не значит, что после переключения она выдержит тот же объем. Когда время ответа выросло в три раза, прежние лимиты только добивают сервис.
Третья ошибка - менять маршрут и промпт в одном релизе. Если качество ответа просело, вы уже не поймете причину: новый провайдер, другой системный промпт или урезанный контекст. В аварийный день меняйте по одному параметру. Сначала маршрут, потом лимиты, и только после этого текст промпта, если без этого нельзя.
Еще одна типичная проблема - забыть про фоновые процессы. Ночные пакетные задачи, eval-прогоны, автотесты и песочницы аналитиков едят тот же запас запросов, что и продакшен. Их нужно быстро притормозить, иначе продакшен спорит за ресурсы с тем, что спокойно подождет до завтра.
И наконец, молчание. Бизнесу не нужен полный разбор, чтобы узнать о проблеме. Уже через 15 минут нужен короткий статус: что затронуто, что работает в урезанном виде и когда будет следующее обновление.
Короткий чек-лист на день сбоя
- Сначала проверьте источник ошибки: это 5xx, таймауты, 429, рост задержки или сбой только в одном регионе.
- Назначьте одного ответственного и один канал для обновлений.
- Переведите критичный трафик на запасной маршрут, а второстепенные задачи поставьте на паузу.
- Снизьте лимиты, урежьте длинные ответы и отключите дорогие функции.
- Сразу назначьте время следующего статуса, даже если новостей пока мало.
К концу первого часа у команды уже должен быть понятный ответ на четыре вопроса: что сломалось, какой трафик удалось спасти, где стоят лимиты и кто дает следующий апдейт.
Что сделать после инцидента
Разбирать такой день лучше по цифрам, а не по впечатлениям. Соберите три группы данных: сколько запросов упало, как выросла задержка и где бизнес реально потерял деньги, заявки или пользователей. Если чат поддержки отвечал на 40 секунд дольше, а доля ошибок выросла с 1% до 12%, это уже материал для решений, а не общая формулировка вроде "все тормозило".
Потом пересмотрите правила роутинга. Часто сбой показывает, что схема была хрупкой: один провайдер забирал слишком много трафика, запасной маршрут включался поздно, а лимиты не сдерживали всплеск. Исправьте пороги переключения, долю трафика на резерв и ограничения по командам, функциям или типам запросов.
Полезно прогнать тот же сценарий на стенде: вручную отключить основного провайдера, проверить время переключения, рост ошибок, состояние очередей и расход бюджета. Если тест снова валит систему, план еще сырой. Нормальный сценарий падения должен быть скучным: трафик уходит на запасной маршрут, часть функций отключается по правилам, команды получают понятные сигналы.
И еще один вывод лучше сделать заранее, а не в разгар следующего сбоя. Если вам нужен один слой для маршрутизации, фолбэков, лимитов по ключам и локального размещения моделей внутри страны, это стоит решить до нового инцидента. Для команд в Казахстане таким слоем может быть AI Router: один OpenAI-совместимый эндпоинт, маршрутизация между провайдерами и свои модели на локальной GPU-инфраструктуре. Но даже с таким инструментом инцидент не проходит сам собой - дисциплина, метрики и простые правила важнее любой удобной панели.
Часто задаваемые вопросы
Как быстро понять, что проблема у провайдера, а не у нас?
Смотрите на свои метрики, а не на статус-страницу. Если у одного провайдера резко растут таймауты, 5xx и p95, а база, сеть и очереди у вас ведут себя нормально, считайте это внешним инцидентом и начинайте переключение.
Сразу проверьте три вещи у себя: срок API-ключа, свежий релиз и сетевой путь до внешнего API. Эти проверки занимают минуты и часто снимают ложную тревогу.
Что делать в первые 10 минут после сбоя?
Сначала остановите все, без чего продукт проживет несколько часов: пакетные задачи, ночные джобы, автосводки и переиндексацию. Потом назначьте одного дежурного, откройте один канал связи и зафиксируйте первый статус с временем и симптомами.
Не ждите официального подтверждения от провайдера. Пока вы ждете, ретраи и длинные таймауты забивают очередь.
Кто должен принимать решения во время инцидента?
Один дежурный по инциденту. Он принимает спорные решения, ставит следующий шаг и следит, чтобы команды не тянули трафик в разные стороны.
Платформа проверяет ошибки и маршруты, продукт решает, что сохранять в работе, поддержка готовит один текст для внутренних команд и клиентов.
Какой трафик нужно переводить на резерв первым?
Первыми переводите сценарии, где пользователь ждет ответ прямо сейчас. Обычно это чат поддержки, помощник для операторов и поиск с генерацией ответа.
Тяжелые и не срочные задачи лучше поставить на паузу. Длинные отчеты, переписывание текстов и фоновый анализ подождут до стабилизации.
Нужно ли сразу отправлять весь трафик на запасную модель?
Нет, весь трафик сразу переводить опасно. Вы можете перегрузить запасной маршрут, сжечь квоты и получить новую очередь уже у второго провайдера.
Пустите сначала 1-5% живого трафика, проверьте задержку, формат ответа и длину текста, а потом расширяйте долю. Так вы увидите проблему раньше, чем она заденет всех пользователей.
Где лучше всего вводить лимиты в день сбоя?
Сначала режьте длинный контекст и длинный ответ у не срочных сценариев. Это быстро снимает часть нагрузки и почти не ломает продукт.
Потом снижайте параллельность для внутренних сервисов и фоновых задач. На каждый API-ключ поставьте жесткий rate limit, чтобы один зациклившийся воркер не выбил весь доступный объем.
Какие функции можно временно урезать без большого вреда?
Отключайте то, без чего пользователь все еще может завершить действие. Повторные генерации, альтернативные версии ответа, лишняя персонализация и фоновая суммаризация истории обычно дают много расхода и мало пользы в аварийный день.
Там, где можно, верните правила и обычную логику приложения. FAQ, статусы заказа и проверку полей формы часто можно закрыть без LLM.
Как сообщить о сбое командам и поддержке без лишней паники?
Напишите коротко и без догадок: что сломалось, кого это задело, что команда уже сделала и когда придет следующий статус. Такой формат снижает шум лучше длинного объяснения.
Поддержке дайте отдельный текст для клиентов. Им нужен не технический разбор, а точная формулировка: что недоступно, где есть задержка и что можно обещать прямо сейчас.
Что делать, если статус-страница провайдера ничего не показывает?
Не ждите, пока она сменит цвет. Если ваши метрики уже показывают рост задержки и ошибок, действуйте по своему плану и считайте инцидент реальным.
Статус-страницы часто отстают. В такие минуты больше пользы дают ваши графики, журнал событий и проверка запасных маршрутов.
Что нужно разобрать после инцидента, чтобы следующий сбой прошел легче?
Соберите цифры по трем зонам: сколько запросов упало, как выросла задержка и где бизнес потерял заявки, деньги или время ответа. Эти данные помогут поправить пороги переключения, лимиты и долю трафика на резерв.
Потом вручную повторите тот же сценарий на стенде. Если система снова захлебывается, план еще сырой. Если у вас есть единый шлюз вроде AI Router, проверьте и правила роутинга, и лимиты по ключам, и работу локальных моделей.