Единый API для LLM: когда он лучше отдельных интеграций
Единый API для LLM помогает сравнить общий шлюз и отдельные интеграции по затратам, скорости запуска, контролю доступа и росту команд.
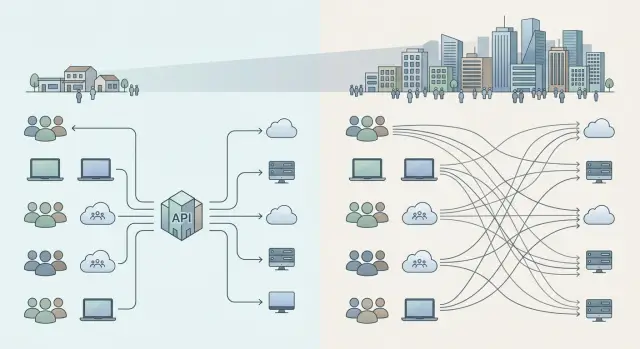
Почему выбор схемы быстро становится проблемой
Почти всегда все начинается спокойно. Одна команда проверяет гипотезу на одной модели, соседняя уже делает клиентскую функцию, третья пробует внутренний поиск. Пока людей мало, прямые интеграции кажутся разумным вариантом: каждая команда сама выбирает провайдера и двигается без лишних согласований.
Через пару месяцев выясняется, что у каждого продукта свой кабинет, свой биллинг, свои лимиты и свой способ хранить ключи. Финансы видят несколько счетов вместо одной картины. Инженерный руководитель не понимает, где расход растет из-за полезной нагрузки, а где деньги уходят на плохие промпты, лишние повторы и неудачные ретраи.
Самое неприятное начинается при смене модели или провайдера. Если интеграции автономны, каждая команда отдельно правит base_url, обработку ошибок, таймауты, лимиты, логирование и форматы ответов. Работа не самая сложная, но утомительная. И она повторяется снова и снова.
Обычно хаос начинается с простых вещей: доступы живут в разных кабинетах, лимиты задают без общих правил, счета приходят из нескольких мест, а логи не складываются в одну картину. После этого разговор быстро перестает быть чисто техническим. Он упирается в контроль: кто видит общий расход, кто может быстро отключить рискованный сценарий, кто понимает, какие команды отправляют персональные данные во внешние сервисы, а какие уже маскируют PII.
Для компаний из Казахстана и Центральной Азии добавляются местные требования. Нужно учитывать хранение данных внутри страны, аудит-логи, метки контента и понятные правила доступа. Если каждая команда решает это отдельно, различия копятся незаметно, а потом превращаются в длинный список ручных проверок.
Поэтому выбор между прямыми интеграциями и единым API редко остается маленьким архитектурным решением. Сегодня у вас один пилот, завтра пять внутренних сервисов, а через квартал продуктовая команда просит подключить еще две модели. В этот момент единый API уже выглядит не как лишняя прослойка, а как способ не чинить одну и ту же проблему в шести местах.
Что дает единый API
Единый API убирает одну из самых скучных и дорогих проблем: все команды работают с моделями одинаково. Вместо пяти разных SDK, токенов и правил подключения у компании появляется один вход и общий порядок работы. Новый сервис запускают быстрее, потому что разработчику не нужно неделю разбираться в чужой интеграции.
Разница особенно заметна после первых удачных пилотов. Пока у вас один чат-бот, отдельное подключение кажется нормой. Когда ботов становится четыре или шесть, начинается путаница: одна команда идет напрямую в OpenAI, другая работает с Anthropic, третья вручную меняет лимиты в коде. Единый API делает подключение новых продуктов предсказуемым и убирает лишний разброс в подходах.
Общие правила тоже проще держать в одном месте. Доступы, лимиты, аудит-логи, маскирование PII и метки контента удобнее задавать централизованно, чем проверять по каждому приложению отдельно. Если компания обязана хранить данные внутри Казахстана, лучше закрепить это на уровне системы, а не надеяться на аккуратность каждой команды.
Еще один плюс виден не сразу. Команды могут менять модель без правок в каждом приложении. Если сегодня для задачи подходит одна модель, а через месяц другая дает тот же результат быстрее или дешевле, переход проходит спокойнее. Для инженеров это меньше рутины. Для бизнеса - меньше зависимости от одного провайдера.
Финансы обычно замечают пользу раньше, чем инженеры ожидают. Когда все вызовы идут через один слой, расходы легче разложить по подразделениям, продуктам и отдельным сценариям. Тогда видно, кто тратит бюджет на поддержку клиентов, кто на внутренний поиск, а кто на эксперименты. Разговор о деньгах становится проще, потому что все смотрят на одну и ту же цифру.
На практике внедрение часто выглядит проще, чем кажется. Команда меняет base_url, сохраняет привычный SDK и продолжает работу. По такому принципу работает AI Router: это OpenAI-совместимый LLM API-шлюз, через который компании могут централизовать доступы, лимиты, аудит-логи и биллинг в тенге, не переписывая текущий код с нуля.
Когда прямые интеграции удобнее
Прямые интеграции часто выигрывают на старте, когда команда делает один сервис и хочет проверить идею за пару недель. Если продукт один, поток запросов понятный, а риски пока невысоки, подключение к одному провайдеру обычно быстрее. Разработчики сами выбирают SDK, лимиты и логику ретраев, без ожидания общих правил.
Такой подход особенно удобен для маленькой команды. Если четыре человека запускают внутреннего помощника для поддержки, им не нужен общий каталог моделей и сложная маршрутизация. Им нужно быстро собрать рабочий сценарий, проверить качество ответов и понять, стоит ли развивать проект дальше.
Есть и другой случай: сервис завязан на редкую функцию конкретного провайдера. Это может быть удобный tool calling, особый режим работы с аудио, длинный контекст или специфичный формат логов. Тогда единый API иногда мешает. Он выравнивает интерфейс, но заодно может скрыть то, ради чего команда и выбрала этого провайдера.
Прямые интеграции удобны и там, где продукт живет отдельно от остальных. У него свой владелец, свой бюджет и свои метрики. Команда не хочет делить лимиты, расходы и приоритеты с другими сервисами. Для крупной компании это нормальная ситуация: один продукт уже приносит выручку, а рядом только тестируют новые идеи.
Есть и совсем практичная причина. В компании может не быть людей, которые будут поддерживать единый API. Такой слой не появляется сам. Кто-то должен следить за доступами, тарифами, аудитом, fallback-логикой и правилами для разных команд. Если владельца нет, общий слой быстро превращается в ничейный проект.
Но у этой свободы есть срок годности. Пока сервисов один-два, она почти не мешает. Когда команд становится больше, одинаковая работа начинает повторяться: все по-своему считают расходы, чинят таймауты и решают вопросы с логами и безопасностью. Если рост уже виден, лучше заранее договориться, где прямые интеграции останутся исключением, а где пора переходить на единый API.
Как рост компании меняет требования
Пока у компании один пилот, команда почти всегда выбирает скорость. Нужно быстро подключить модель, проверить сценарий и понять, работает ли идея в реальной задаче. В этот момент прямые интеграции часто удобнее: меньше согласований, меньше общих правил, быстрее первый результат.
Потом пилот перестает быть экспериментом. Появляется второй продукт, затем третий. Один отдел делает чат для поддержки, другой подключает поиск по внутренним документам, третий тестирует голосового помощника. На этом этапе старые решения начинают мешать сильнее, чем кажется.
С тремя командами еще можно жить с ручными настройками. Кто-то хранит свои ключи у себя, кто-то сам выставляет лимиты, кто-то ведет расходы в таблице. Это неудобно, но терпимо. Когда команд становится десять, такая схема съедает время каждую неделю. Люди спорят, какая модель где используется, почему один сервис уперся в лимит и кто вообще отвечает за сбой у провайдера.
Финансы обычно замечают проблему раньше, чем инженеры готовы ее признать. Если каждая команда работает с отдельными провайдерами, расходы расползаются по разным кабинетам, валютам и правилам тарификации. Становится трудно собрать один прогноз на квартал. Для бизнеса в Казахстане это особенно заметно, когда нужен один понятный счет и нормальный B2B-инвойсинг в тенге, а не набор разрозненных платежей.
Безопасность тоже меняет разговор. Пока запросов мало, команды часто договариваются на словах. Когда модели попадают в несколько внутренних систем, этого уже мало. Нужны общие правила для маскирования персональных данных, единые журналы действий, понятные лимиты по ключам и ясный ответ на вопрос, где хранятся данные.
В этот момент единый API начинает окупаться. Не потому что он моднее, а потому что сама задача становится другой. Сначала вы просто подключаете модель. Позже вы управляете доступом, бюджетом, рисками и качеством сразу для нескольких команд.
Хороший ориентир простой: один сервис еще переживет неровные процессы. Восемь продуктов и общий бюджет - уже нет.
Пример: от одного пилота к восьми продуктам
Обычно все начинается с понятного пилота. Одна команда запускает внутренний чат для операторов колл-центра: ответы по базе знаний, подсказки по скриптам, короткие сводки после звонка. Для такой проверки хватает одного токена, одного провайдера и пары лимитов.
Через месяц пилот показывает нормальный результат, и модель хотят использовать другие отделы. Мобильная команда добавляет помощника в приложение. Маркетинг просит генерацию текстов и A/B-вариантов. Служба риска проверяет обращения и ищет подозрительные формулировки. Каждая команда идет своим путем: заводит свой аккаунт, берет свои токены, выбирает удобного провайдера и настраивает лимиты под себя.
Поначалу это даже нравится. Никто никого не ждет, интеграции идут быстро, эксперименты не тормозят. Но к моменту, когда у компании уже восемь продуктов и несколько внутренних сценариев, появляется другая проблема: никто не видит общую картину.
Финансы видят общий счет, но не понимают, какой продукт съел бюджет. Инфраструктурная команда получает жалобы на сбои, но не может быстро понять, где уперлись в rate limit, а где упал внешний провайдер. Безопасность просит аудит по доступам и данным, а команды присылают скриншоты, таблицы и куски логов из разных мест.
Обычно в этот момент всплывают одни и те же симптомы:
- лимиты живут в разных кабинетах и конфликтуют друг с другом
- токены хранятся по-разному, иногда прямо в сервисах
- расходы считают вручную по нескольким счетам
- при сбое люди долго ищут, чей это провайдер и кто отвечает
Тогда единый API оказывается не про контроль ради контроля, а про порядок. Команды по-прежнему работают со своими промптами, SDK и сценариями, но компания переносит в один слой то, что и так приходится согласовывать вручную: доступы, бюджеты, лимиты, логи и правила на случай сбоя.
Для компаний в Казахстане это часто решает еще и бытовые операционные проблемы. Например, шлюз вроде AI Router дает один OpenAI-совместимый вход, аудит-логи, rate limits на уровне ключа и ежемесячный B2B-инвойсинг в тенге. Для новой команды это обычно означает более короткое подключение и меньше ручных согласований.
Как выбрать схему
Схему стоит выбирать не по тому, как удобно одной команде сегодня, а по тому, сколько команд, продуктов и ограничений появится через год. Если сейчас у вас один пилот, а через 6-12 месяцев будет пять команд и несколько сервисов, раннее решение быстро станет дорогим.
Сначала посчитайте будущую нагрузку в организационном смысле, а не только в токенах. Сколько команд будут подключать модели? Сколько сценариев уйдет в продакшен? Где появятся ночные инциденты, лимиты по бюджету и споры о том, кто отвечает за смену провайдера?
Четыре вопроса перед выбором
- Сколько команд и продуктов будут использовать модели в ближайший год
- Какие сценарии останутся пилотами, а какие потребуют аудита, логов и предсказуемой работы
- Кто владеет доступами, лимитами, бюджетом и правилами смены модели или провайдера
- Что дешевле: поднять единый API сейчас или переезжать на него позже, когда интеграций станет много
После этого разделите use cases на две группы. Для пилотов, внутренних тестов и быстрых экспериментов прямые интеграции часто удобнее. Команда двигается быстрее и не ждет общей инфраструктуры.
Для клиентских сервисов и систем с требованиями по безопасности чаще лучше работает единый API. Там важны общие лимиты, единые логи, понятная схема доступов и одинаковые правила маршрутизации.
Это особенно заметно в банках, телекоме и медицине. Если данные должны храниться внутри Казахстана, а действия с моделями нужно проверять позже, отдельные подключения быстро создают беспорядок: у каждой команды свои ключи, свои логи и свой способ переключать провайдера.
Еще один шаг, который часто пропускают: назначьте владельца. Он не обязан писать код, но должен отвечать за доступы, бюджет, выбор общего слоя и план перехода, если текущий провайдер перестанет устраивать.
Во многих компаниях лучше всего работает гибридный подход. Пилоты живут отдельно, а продакшен идет через единый API. Если нужен OpenAI-совместимый вход, аудит-логи, маскирование PII и хранение данных внутри страны, такой слой снимает много операционной рутины. У AI Router этот сценарий как раз предусмотрен: команды могут сохранить текущие SDK, код и промпты, а правила доступа и контроля собрать в одном месте.
Где чаще ошибаются
Первая ошибка проста: компании строят общий слой слишком рано. У команды один пилот, два разработчика и один понятный сценарий, а они уже вводят сложные правила доступа, общий шлюз, согласования и отдельную маршрутизацию. В итоге люди тратят недели не на продукт, а на схему, которая пока не нужна.
На старте обычно хватает прямой интеграции, если команда понимает риски и оставляет себе путь на замену провайдера. Проблемы начинаются позже, когда пилот превращается в несколько сервисов, а код уже плотно завязан на одном API, одном формате логов и одном наборе ограничений. Тогда любая замена бьет по срокам.
Обратная крайность встречается не реже. Руководитель оставляет полную автономию всем командам, даже когда компания уже выросла. У одного продукта OpenAI, у другого Anthropic, у третьего локальная модель, у четвертого свой прокси. Через пару месяцев финансы не могут быстро сверить счета, безопасность не понимает, где лежат логи, а платформенная команда не видит общую нагрузку.
Тревожные признаки здесь довольно понятны: команды по-разному считают токены и расходы, логи лежат в разных местах или не хранятся вовсе, персональные данные маскируют по-разному, лимиты по ключам задают вручную, а смена провайдера требует правок в нескольких сервисах.
Еще одна частая ошибка связана не с кодом, а с правилами. Команды спорят о выборе модели, но не договариваются, кто отвечает за аудит-логи, маскирование данных, лимиты и метки контента. Потом приходит первый серьезный клиент, аудит или внутренний риск-комитет, и оказывается, что техническая схема куда слабее, чем казалось.
Отдельно мешает ранняя покупка платформы без внутренних договоренностей. Сам по себе единый API не исправит беспорядок, если внутри не решены простые вопросы: кто подключает новые команды, кто утверждает провайдеров, кто раз в месяц смотрит на счета. Даже если шлюз позволяет сменить только base_url и сохранить SDK, код и промпты, процессы он за вас не выстроит.
Рабочая последовательность простая: сначала договоритесь о правилах, потом закрепите их в общей точке входа. Иначе вы получите либо дорогую надстройку над одним пилотом, либо набор интеграций, который уже никто толком не контролирует.
Быстрая проверка перед решением
Архитектура обычно ломается не в день запуска, а через полгода. К моделям подключаются новые команды, бюджеты расползаются, а провайдер внезапно начинает отвечать медленнее обычного. Поэтому перед выбором схемы полезно смотреть не только на текущий пилот, но и на ближайшие 12 месяцев.
Сначала посчитайте будущие сервисы, а не только текущие. Если сегодня моделью пользуется один продукт, а через год добавятся поддержка, поиск, внутренний помощник и аналитика, единый API часто убирает много лишней ручной работы. Если же у вас один узкий сценарий и один владелец, прямая интеграция может жить спокойно.
Потом проверьте, кто видит общий расход по всем продуктам. Когда каждая команда платит и следит за токенами отдельно, компания слишком поздно замечает, что один сценарий уже съедает заметную часть бюджета. Нужна точка обзора, где видно, какие модели используют команды и где расход резко вырос.
Полезно отдельно смоделировать сбой провайдера в обычный рабочий день. Если для переключения нужно менять код в нескольких сервисах, заново раскатывать ключи и вручную проверять лимиты, схема уже хрупкая. Нормальный вариант позволяет перевести трафик быстро и без аврала.
Заранее решите, где будут лежать логи, промпты и чувствительные данные. Для банка, клиники или госкоманды это не формальность. Нужно понимать, кто увидит PII, где хранится история запросов, какие аудит-логи нужны и есть ли требование держать данные внутри Казахстана.
И наконец, оцените объем ручной работы при росте. Если для каждой новой команды вы отдельно заводите доступы, лимиты, правила маскирования и отчеты, скоро люди начнут поддерживать саму схему вместо продукта.
Есть простой мысленный тест. Представьте, что через шесть месяцев у вас уже не один пилот, а восемь рабочих сценариев в разных отделах. Если текущий подход в этой картине требует много ручных действий, плохо показывает бюджет и мешает быстро менять провайдера, единый API почти наверняка даст меньше боли.
Для компаний в Казахстане этот выбор часто упирается еще и в хранение данных внутри страны и внятный аудит. Если эти требования уже на столе, их лучше учитывать сразу, а не после первого инцидента.
Что делать дальше
Не пытайтесь сразу выбрать схему на три года вперед. Гораздо полезнее описать два ближайших сценария роста: что будет, если у вас останется один продукт, и что будет, если через полгода появятся еще две команды с другими задачами. Такой взгляд быстро показывает, где единый API даст меньше боли, а где прямые интеграции пока проще.
Например, сегодня у вас один сервис с генерацией ответов для клиентов. Через несколько месяцев к нему могут добавиться поиск по внутренним документам, голосовой бот или модуль проверки заявок. Если эти продукты делят бюджеты, политику доступа и требования к логам, единый API обычно экономит время. Если продукт один, команда маленькая, а модель уже выбрана надолго, прямое подключение может быть быстрее.
Лучше не спорить на словах, а сделать короткий тест. Возьмите один продукт и пустите его через единый API. Второй оставьте на прямой интеграции с провайдером. Для этого не нужен большой проект. Достаточно пилота на 1-2 недели с одинаковыми задачами и похожей нагрузкой.
Сравнивайте не только качество ответов. Посмотрите на более приземленные вещи: сколько дней ушло на запуск, сколько счетов и договорных точек появилось, кто и как выдает доступы командам, сколько раз пришлось править код при смене модели или провайдера.
Если разница небольшая, не усложняйте архитектуру заранее. Но если единый API уже на пилоте убирает лишние правки в коде, упрощает доступы и делает расходы понятнее, это сильный аргумент в пользу централизации.
Для команд в Казахстане и Центральной Азии есть практичный способ проверить такой сценарий без большой миграции. Например, AI Router позволяет сменить base_url на api.airouter.kz и продолжить работу с теми же SDK, кодом и промптами. Заодно можно оценить, насколько полезны локальное хранение данных, маскирование PII, аудит-логи и ежемесячный B2B-инвойсинг в тенге.
Итог теста лучше закрепить письменно. Часто хватает одной страницы: какой вариант вы проверяете, по каким четырем метрикам сравниваете и при каком результате переходите на следующую стадию. Тогда решение примет не самый громкий голос в комнате, а факты.
Часто задаваемые вопросы
Когда лучше оставить прямую интеграцию с провайдером?
Прямое подключение подходит, когда у вас один сервис, маленькая команда и короткий пилот. В такой ситуации проще быстро проверить идею и не тратить время на общий слой, если вы заранее оставили себе путь на смену провайдера.
Как понять, что компании уже нужен единый API?
Единый API обычно нужен тогда, когда моделей и команд стало больше двух-трех, а расходы, лимиты и логи разъехались по разным кабинетам. Если смена модели уже требует правок в нескольких сервисах, вы почти дошли до точки, где общий вход экономит время каждую неделю.
Нужно ли переписывать код при переходе на единый API?
Часто нет. Если шлюз совместим с OpenAI API, команда меняет base_url и продолжает работать с тем же SDK, кодом и промптами. У AI Router это как раз базовый сценарий.
Что дает единый API при смене модели или провайдера?
С общим слоем вы меняете маршрут в одном месте, а не проходите по каждому приложению отдельно. Это сокращает ручные правки, снижает риск ошибок и позволяет быстрее перевести трафик на более дешевую или быструю модель.
Помогает ли единый API лучше видеть расходы?
Он собирает вызовы в одной точке, поэтому расходы проще разложить по продуктам, командам и сценариям. Финансы получают одну картину вместо набора разрозненных счетов, а инженерные команды быстрее видят, где бюджет уходит на полезную нагрузку, а где на лишние повторы и неудачные ретраи.
Как единый API упрощает аудит и разбор инцидентов?
Логи, лимиты и доступы лучше держать в одном месте, особенно когда с LLM работают несколько команд. Тогда проще разбирать сбои, проверять действия по ключам и отвечать на вопросы безопасности без скриншотов и ручной сверки.
Что делать, если нужно хранить данные в Казахстане и скрывать PII?
Если у вас есть требования по хранению данных внутри страны, их лучше закрепить на уровне общей системы, а не надеяться на аккуратность каждой команды. Для Казахстана это особенно удобно, когда шлюз сразу поддерживает локальное хранение, маскирование PII, аудит-логи и метки контента.
Можно ли совмещать пилоты на прямых интеграциях и продакшен через единый API?
Да, это часто самый здравый вариант. Пилоты и быстрые эксперименты можно оставить на прямых интеграциях, а клиентские и чувствительные сценарии пустить через единый API, где легче держать правила доступа, логи и бюджеты.
Кто должен отвечать за общий LLM API в компании?
Нужен конкретный владелец, даже если он сам не пишет код. Этот человек отвечает за доступы, лимиты, бюджет, правила подключения новых команд и план действий, если провайдер или модель перестанут устраивать.
Как проверить, какая схема подойдет нам, без большой миграции?
Не спорьте на словах — сделайте короткий тест на одну-две недели. Один продукт пустите через единый API, второй оставьте на прямом подключении и сравните время запуска, число ручных правок, понятность расходов и то, как команда переживает смену модели или сбой провайдера.