Нормализация кодов ошибок LLM API для продукта и поддержки
Нормализация кодов ошибок LLM API помогает свести таймауты, лимиты и bad request в один словарь для продукта, логов и поддержки.
Почему один и тот же сбой выглядит по-разному
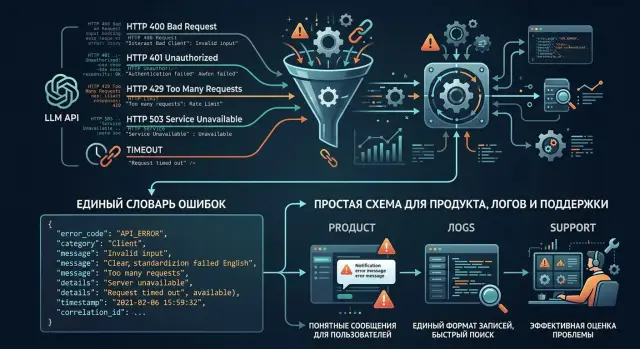
Одна и та же проблема редко приходит в одном формате. Один провайдер при перегрузке вернет 429, другой ответит 503, а третий просто оборвет соединение по таймауту. Для пользователя это одна ситуация: "запрос не прошел". Для продукта, поддержки и аналитики это уже три разных события.
Поэтому нормализация кодов ошибок LLM API - не мелочь и не косметика. Если не свести ответы к общему словарю, команда начинает спорить не о причине сбоя, а о формулировке. Поддержка ищет похожие кейсы вручную, а продукт видит искаженную картину по частоте проблем.
Путаница возникает сразу на нескольких уровнях. Провайдеры по-разному кодируют одну и ту же перегрузку. Модели одного провайдера отдают разный текст ошибки. SDK и прокси иногда подменяют исходный статус своим исключением. Мониторинг дробит похожие сбои на отдельные метрики.
Из-за этого жалоба "генерация зависает" в логах выглядит по-разному. В одной системе вы увидите 504 gateway timeout, в другой 429 rate limit, в третьей - что-то вроде upstream request failed без ясного кода. Хотя источник часто один: провайдер не успел обработать запрос из-за очереди или жесткого лимита.
Текст ошибки тоже ненадежен. Одна модель пишет context length exceeded, другая - too many tokens, третья - invalid request. Если брать эти строки как есть, поддержка получит три сценария для одной причины: запрос слишком большой.
Даже при работе через единый шлюз различия не исчезают сами собой. Шлюз упрощает доступ к нескольким моделям, но продукту все равно нужен свой общий язык ошибок. Иначе смена модели меняет не только качество ответа и цену, но и поведение поддержки.
Самый заметный вред виден в метриках. Ошибки распадаются на десятки мелких серий, и вы уже не можете честно ответить на простой вопрос: что ломается чаще всего - лимиты, таймауты или неверные запросы.
Какие группы ошибок держать в словаре
Хороший словарь не пытается запомнить все ответы всех провайдеров. Он сводит разные формулировки к нескольким понятным группам, чтобы продукт, разработка и поддержка говорили на одном языке. Для большинства LLM-интеграций обычно хватает пяти групп.
Первая группа - таймауты и обрыв соединения. Сюда попадают случаи, когда модель отвечает слишком долго, соединение рвется, поток останавливается на середине или шлюз не дождался ответа. Для пользователя это выглядит как "запрос завис" или "ответ не пришел".
Вторая - лимиты и исчерпанная квота. Один провайдер вернет 429, другой напишет про rate limit, третий сообщит о нехватке кредитов. В словаре это одна группа, но внутри полезно различать короткий всплеск нагрузки и полное исчерпание бюджета.
Третья - неверный запрос. Здесь живут ошибки схемы JSON, неподдерживаемые роли, слишком длинный контекст, неверные параметры генерации и несовместимые поля API. Это частая категория, и она почти всегда требует исправления на стороне клиента, а не повтора запроса.
Четвертая - ошибки авторизации и доступа. Неверный API-ключ, просроченный токен, запрет на конкретную модель, ограничения по проекту или среде лучше держать отдельно. Поддержка в таком случае быстрее идет проверять права, а не ищет проблему у модели.
Пятая - сбои провайдера и временная недоступность. Это ответы класса 5xx, перегруженные кластеры, ошибки маршрутизации и внутренние сбои внешнего сервиса. Их стоит помечать как временные, если запрос можно безопасно повторить.
Есть простой тест: по названию группы человек должен сразу понимать, кто делает следующий шаг. Разработчик правит запрос, платформа повторяет вызов, поддержка проверяет доступ, а продукт видит конкретный тип сбоя, а не абстрактное "сломалась AI".
Если команда ходит в несколько моделей через один шлюз, такой словарь особенно быстро окупается. Например, при работе через AI Router разные провайдеры все равно могут вернуть context length exceeded, bad request или просто 400. Для поддержки это не три разные проблемы, а одна: запрос превысил допустимый размер, и его надо сократить или разбить.
Как описывать ошибку в едином формате
Если у вас несколько провайдеров и моделей, одна и та же проблема быстро превращается в хаос. Один API вернет 429, другой напишет rate limit, третий отдаст 503 с расплывчатым текстом. Для продукта и поддержки это один случай, и описывать его лучше одним внутренним кодом.
Начните с короткого словаря внутренних кодов. Названия должны быть простыми и однозначными: timeout_upstream, rate_limited, invalid_request, auth_failed, model_unavailable. Такой код не зависит от провайдера и сразу отвечает на вопрос, что именно сломалось.
Затем привяжите к каждому коду HTTP-статус, который увидит клиент. Это убирает лишние споры между командами. Например, invalid_request обычно уходит как 400, auth_failed как 401 или 403, rate_limited как 429, а timeout_upstream как 504. Не нужно повторять внешний статус один в один. Клиенту нужен понятный и стабильный контракт.
Отдельно задайте политику повтора. Нужен прямой ответ, а не догадки по логам: запрос можно повторить сразу, нельзя повторять без исправлений или стоит повторить позже, когда спадет нагрузка.
Текст ошибки лучше разделить на два слоя. В интерфейсе нужен короткий и спокойный текст без внутренней кухни: "Сервис не ответил вовремя. Повторите попытку через минуту". Для поддержки нужен другой формат: причина, действие и привязка к словарю. Например: timeout_upstream: провайдер не ответил за 30 секунд, повтор безопасен, проверьте всплеск нагрузки и таймаут маршрута.
В логах держите минимум полей, без которых разбор почти всегда буксует: provider, model, request_id, latency, internal_error_code. Если запросы идут через роутер, полезно добавить еще маршрут, число повторов и сработал ли fallback.
Нормализация работает только тогда, когда один внутренний код связывает сразу четыре вещи: что произошло, какой статус вернуть клиенту, можно ли делать повтор и что увидят интерфейс с поддержкой. Тогда поведение продукта становится предсказуемым, а шум в поддержке заметно падает.
Как собрать словарь из логов
Начинать лучше не с документации провайдеров, а со своих логов. За последние 2-3 недели там обычно уже есть все нужное: таймауты, 429, bad request, обрывы стрима, пустые ответы и редкие 5xx. Сохраняйте не только HTTP-код, но и текст ошибки, провайдера, модель, тип запроса и то, помог ли повтор.
Дальше удобно идти по простому порядку:
- Сначала выгрузите сырые ошибки без ручной чистки.
- Потом объедините дубликаты по смыслу, а не по тексту.
- Для каждой группы назначьте один внутренний код.
- Для каждого кода запишите правило реакции: нужен ли повтор, какой backoff использовать, когда переключать модель и когда открывать инцидент.
- В конце прогоните маппинг на тестовых ответах от всех провайдеров.
Хороший признак простого словаря - одинаковое действие при одинаковом смысле. Если один провайдер вернул 408, а другой 524 через прокси, но в обоих случаях запрос завис и повтор через пару секунд обычно помогает, держите один внутренний код. Поддержке не нужен музей чужих формулировок. Ей нужен ясный ответ: что случилось и что делать дальше.
Отдельно проверьте поля, которые видят продукт и поддержка. Пользователю обычно хватает короткого статуса вроде "модель не ответила вовремя". Оператору уже нужны детали: исходный код, провайдер, trace id, число повторов и сработал ли fallback.
Если вы используете шлюз, который и маршрутизирует запросы, и хостит часть моделей, тестируйте оба типа сбоев отдельно: ошибки внешних провайдеров и ошибки на собственной инфраструктуре. Для продукта они могут выглядеть одинаково, но разбирать их придется по-разному.
Если внутренний код не подсказывает действие, его стоит переделать. Иначе словарь быстро превратится еще в один список непонятных названий.
Что показывать пользователю, поддержке и инженеру
Пользователю, поддержке и инженеру не нужен один и тот же текст. Если всем показать ответ провайдера как есть, пользователь увидит шум, поддержка начнет гадать, а инженер потратит время на расшифровку чужих формулировок.
Пользователю лучше дать короткую причину и понятное действие. Например: "Сервис временно занят. Повторите запрос через 30 секунд" или "Запрос слишком большой. Сократите текст и попробуйте снова". Формулировки вроде upstream 429 или provider validation error только путают.
В API держите стабильный внутренний код, который не зависит от провайдера. Сегодня один пишет rate limit exceeded, другой вернет 429 с другим текстом, третий назовет это quota error. Для продукта это должен быть один код, например RATE_LIMIT. То же самое с UPSTREAM_TIMEOUT, INVALID_INPUT, AUTH_ERROR, CONTENT_BLOCKED. Тогда аналитика, алерты и правила повтора не ломаются от смены модели или маршрута.
При этом сырой ответ провайдера терять нельзя. Сохраняйте статус, тело ответа, заголовки, request_id провайдера, модель, маршрут и время ответа. Если инфраструктура уже поддерживает аудит-логи и маскирование PII, как это делает AI Router, такие данные можно хранить аккуратнее и быстрее отдавать инженерам на разбор.
Один и тот же инцидент удобно раскладывать на три слоя:
- Пользователь видит короткое сообщение без жаргона и лишних деталей.
- Поддержка видит внутренний код, вероятную причину и следующий шаг.
- Инженер видит полный технический след, включая сырой ответ провайдера.
Для поддержки полезен не только код, но и подсказка к действию. Если пришел RATE_LIMIT, система может сразу показать: "Проверьте всплеск трафика, retry-after и запасной маршрут". Если пришел INVALID_INPUT, поддержка должна видеть: "Попросите пользователя сократить контекст или убрать неподдерживаемый параметр".
Такое разделение хорошо работает там, где запросы идут через один OpenAI-совместимый слой к нескольким моделям. Снаружи продукт говорит просто и спокойно. Внутри API и логов остается вся нужная точность.
Пример для команды с несколькими моделями
У банка есть чат поддержки в мобильном приложении. Днем нагрузка скачет: утром клиенты спрашивают про переводы, вечером - про карты и лимиты. Команда не держит весь трафик на одной модели. Она отправляет запросы сначала в быструю модель, а если та не справляется, переводит часть нагрузки в резервную.
Проблема начинается в тот момент, когда оба провайдера говорят об одном и том же разными словами. Первая модель возвращает обычный HTTP 429. Вторая отвечает текстом rate_limit_exceeded, хотя смысл тот же: запросов слишком много, нужно немного подождать.
Если продукт читает эти ответы как есть, пользователи видят разный текст, а поддержка тратит время на догадки. Один оператор пишет, что это "ошибка API", другой считает, что сломалась интеграция, хотя причина одна.
Решение простое: поставить между приложением и моделями общий слой маппинга. Он не спорит с форматом провайдера и не тащит каждую мелочь в интерфейс. Он переводит разные ответы в один внутренний код, например limit_retry_later.
После этого продукт показывает короткое сообщение: сервис временно перегружен, попробуйте еще раз через минуту. Для клиента этого достаточно. Ему не нужен код 429 и не нужен текст провайдера.
Поддержка, наоборот, получает больше деталей: какого провайдера вызвала система, какую модель выбрал роутер, какой исходный код вернул провайдер, какой внутренний код присвоила система и когда лучше повторить запрос.
Такой подход убирает путаницу. Для команд, которые маршрутизируют трафик через один шлюз к нескольким провайдерам, это особенно полезно: одинаковые сбои перестают выглядеть как разные инциденты.
Где команды ошибаются чаще всего
Чаще всего проблемы начинаются не в самой интеграции, а в мелочах вокруг ошибок. Один провайдер пишет сухой код, другой присылает длинный текст, третий меняет формат от модели к модели. Если пустить это в продукт без перевода, поддержка получает хаос вместо понятной картины.
Первая частая ошибка - показывать пользователю сырой текст провайдера. Такой текст шумный, местами пугающий и почти никогда не объясняет, что делать дальше. В интерфейсе лучше оставить короткое сообщение, а полный ответ хранить в логах и карточке инцидента.
Вторая ошибка - сваливать 400 и 422 в одну корзину только потому, что оба кода выглядят как "ошибка запроса". На деле смысл разный. 400 обычно означает, что запрос собран неверно, а 422 чаще указывает, что формат верный, но данные не проходят проверку: слишком длинный ввод, неподдерживаемый параметр, конфликт полей.
Третья ошибка - автоматически повторять любой неуспешный запрос. Для bad request это бесполезно: система тратит время, квоту и иногда деньги, а результат не меняется. Повтор имеет смысл для таймаутов, части 429 и части 5xx, но не для сломанных параметров.
Четвертая ошибка - терять request_id провайдера. Это кажется мелочью до первого серьезного инцидента. Потом поддержка видит жалобу, инженер открывает логи, а связать конкретный запрос с ответом провайдера уже нельзя. Если у вас несколько моделей и несколько провайдеров, такой след нужен всегда.
Пятая ошибка - придумывать слишком много внутренних кодов. Когда их становится двадцать или тридцать, люди перестают помнить разницу, а новые сотрудники открывают таблицу как словарь редких терминов. Лучше держать короткий набор категорий и добавлять новый код только тогда, когда он меняет действие продукта, поддержки или дежурного инженера.
Хороший словарь ошибок не должен выглядеть умно. Он должен быстро отвечать на три вопроса: что случилось, нужно ли повторять запрос и кто может это исправить.
Быстрая проверка перед релизом
Перед релизом стоит проверить не только успешный сценарий. Один неясный 429 или таймаут быстро превращает обычный сбой в длинную переписку с клиентом, где продукт, поддержка и разработка называют одну и ту же проблему разными словами.
Ниже короткий список, которого обычно хватает:
- У каждого внутреннего кода есть простое имя.
- Каждый код ведет к одному действию.
- Поддержка видит не только код, но и пример реального сообщения с первым ответом клиенту.
- Дашборд считает ошибки по внутреннему словарю, а сырой ответ провайдера хранит рядом.
- Автотесты и ручная проверка покрывают хотя бы 429, таймаут, 400, 401 и 503.
Есть еще одна деталь, о которой часто забывают: один и тот же класс ошибки должен одинаково называться в логах, в панели поддержки и в отчетах продукта. Если в логе написано RATE_LIMIT, а в интерфейсе поддержки - "временная проблема провайдера", путаница начнется уже на первой неделе.
Полезно проверить схему на коротком примере. Провайдер A вернул 504, провайдер B отдал текстовую ошибку без статуса, а ваш шлюз в обоих случаях пометил событие как UPSTREAM_TIMEOUT. Поддержка сразу понимает, что говорить клиенту: "Запрос завис на стороне модели, система уже пробует повтор, вернитесь через минуту".
Если после этой проверки любой человек в команде может посмотреть на код и сразу понять причину, следующее действие и текст ответа клиенту, словарь готов к релизу.
Что делать дальше
Не пытайтесь описать весь мир ошибок за один раз. Лучше взять 10-15 сбоев, которые команда видит чаще всего: таймауты, rate limit, bad request, отказ провайдера, проблемы с авторизацией, пустой ответ. Если эти случаи получают одинаковые коды и одинаковые объяснения, продукт и поддержка начинают говорить на одном языке почти сразу.
У словаря должен быть владелец. Обычно это backend lead, платформенный инженер или человек, который отвечает за интеграции. Он решает, куда отнести новый код, следит за именами групп и не дает команде плодить похожие статусы вроде provider_timeout, model_timeout и request_expired, если для продукта это один и тот же сбой.
Полезное правило простое: новый код сначала попадает в нормализованную группу, а детали вы добавляете позже. Продукту и поддержке нужны стабильный код, понятный текст и понятное действие. Поля для аналитики, вроде провайдера, модели, числа повторов и задержки, можно наращивать после того, как базовая схема перестанет прыгать.
Если команда работает с несколькими моделями и провайдерами, слой нормализации лучше держать рядом с единым эндпоинтом. Тогда различия между ответами провайдеров вы ловите в одном месте, а не в каждом сервисе отдельно. Если для этого уже используется OpenAI-совместимый шлюз вроде AI Router, где можно сохранить существующие SDK, код и промпты и просто сменить base_url, поддерживать маршрутизацию и словарь ошибок рядом друг с другом заметно проще.
Раз в месяц полезно пересматривать свежие логи и смотреть на четыре вещи: какие коды появились впервые, какие ошибки попали не в ту группу, где текст для поддержки слишком общий и какие сбои уже пора разбить на более точные подтипы.
Не гонитесь за идеальной аналитикой в первый месяц. Стабильные коды для продукта и поддержки дают больше пользы, чем подробный, но плавающий каталог на сотни строк. Если на ближайший спринт выбрать владельца, зафиксировать правило для новых кодов и описать первые 15 ошибок, хаоса в логах станет заметно меньше, а разбор инцидентов пойдет быстрее.