Модерация выходных ответов: где ставить фильтры и вторую модель
Модерация выходных ответов помогает не пропускать рискованный текст в чат, почту и CRM. Разберем, где ставить правила, фильтры и второй вызов.
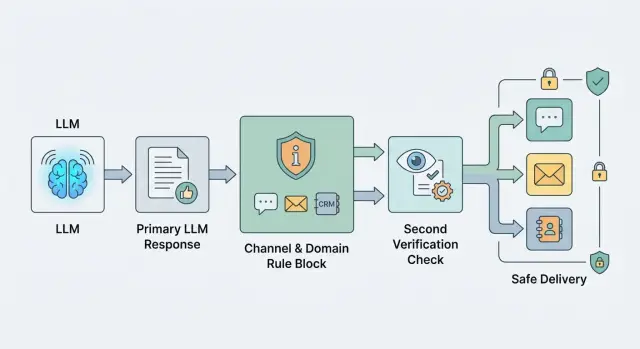
Почему общий фильтр не решает задачу
Один и тот же текст меняет смысл в зависимости от того, где его увидит человек. В чате спорный ответ можно быстро уточнить. В письме тот же текст уже выглядит как официальная позиция компании. В карточке CRM он остается в истории и потом влияет на работу другого сотрудника.
Из-за этого меняется и риск. Ошибка в поддержке интернет-магазина чаще всего просто раздражает клиента и добавляет лишний диалог. Ошибка в банке, страховании или медицине может закончиться жалобой, внутренней проверкой или прямым вредом для человека.
Общий фильтр обычно смотрит на ответ как на один тип текста. Ему без разницы, ушел он в чат, email или внутреннюю систему. На старте это удобно, но потом мешает. Такой фильтр режет полезные фразы там, где риск низкий, и пропускает опасные формулировки там, где цена ошибки выше.
Хороший пример - обещания и рекомендации. В чате фраза "мы точно решим вопрос сегодня" может быть просто неудачной репликой оператора. В письме она уже похожа на обязательство. В банковском или медицинском сценарии такая уверенность без проверки данных вообще не должна уходить клиенту.
Есть и другая проблема. Общий фильтр часто ловит только грубые вещи: токсичность, явные запреты, утечки персональных данных. Но реальный риск обычно сидит в деталях домена. Для банка это может быть совет по продукту без нужных оговорок. Для клиники - намек на диагноз. Для CRM - запись с лишней оценкой клиента вместо сухого факта.
Один порог и один набор правил почти всегда дают перекос в обе стороны. Команда получает ложные срабатывания в безопасных каналах, злится на модерацию и начинает ее обходить. А опасные ответы проходят там, где нужны более жесткие проверки.
Если система работает через единый LLM API-шлюз, соблазн поставить одну проверку на выходе особенно велик. Это и правда упрощает интеграцию. Но рабочая схема обычно другая: канал задает форму ответа, а домен - уровень риска и глубину проверки.
Где ставить фильтры в цепочке ответа
Один фильтр в самом конце почти всегда срабатывает слишком поздно. К этому моменту ответ уже прошел через шаблоны, подстановку данных, сокращение текста и форматирование под канал. Риск растет на каждом шаге, поэтому проверка должна идти по цепочке, а не стоять в одной точке.
Сразу после генерации стоит проверять черновик модели. На этом шаге проще всего поймать опасные советы, утечку персональных данных, токсичный тон или обход ваших инструкций. Если система замечает проблему рано, она может запросить перегенерацию, упростить ответ или передать диалог оператору.
Отдельного внимания требуют поля, которые клиент увидит без правки. Обычно это тема письма, короткий текст для push, SMS, подпись, CTA-кнопка или готовый JSON для внешней системы. Именно такие куски текста часто никто не читает вручную, поэтому правила для них должны быть строже, чем для внутреннего черновика.
Рабочая схема обычно выглядит так: сначала система проверяет сырой ответ модели сразу после генерации, потом отдельно смотрит финальные поля, которые уходят наружу как есть, а перед отправкой в канал проверяет уже собранное сообщение целиком. Если ответ блокируется, система должна сохранить причину, номер правила и этап, на котором это произошло.
Финальная проверка прямо перед отправкой нужна даже тогда, когда черновик уже был чистым. Причина простая: позже в ответ могут попасть имя клиента, номер заказа, данные из CRM или фрагмент из базы знаний. Сам текст модели был безопасным, а итоговое письмо или чат-сообщение уже нет.
Простой пример - поддержка банка. Модель сгенерировала нейтральный ответ, но шаблон потом добавил полный номер карты в письмо. Ранний фильтр этого не увидел бы, потому что номера еще не было. Последняя проверка перед каналом заметит проблему и остановит отправку.
Логи нужны не для отчета. Они нужны для настройки системы. Если команда видит, что одно правило часто блокирует темы писем, а другое срабатывает только в чате, она может чинить конкретный участок, а не переписывать всю политику.
Как разделить правила по каналу
Один и тот же ответ нельзя проверять одинаково для всех каналов. Короткая реплика в чате, письмо клиенту и запись в CRM живут в разной среде, а значит и риск у них разный. Если оставить один общий фильтр, он либо пропустит лишнее, либо начнет резать полезные ответы.
Для чата обычно важны три вещи: тон, длина и лишние детали. Ответ должен быть спокойным, без резких формулировок и без длинных объяснений, которых клиент не просил. Если бот начинает перечислять внутренние шаги проверки, лимиты системы или детали чужих кейсов, такой ответ лучше остановить и сократить.
Для почты правила строже. Письмо читают дольше, его пересылают внутри компании и нередко воспринимают как обещание со стороны бизнеса. Поэтому проверяйте не только токсичность или утечки данных, но и формулировки про сроки, гарантии, скидки, компенсации и обязательства. Фраза "мы точно решим вопрос сегодня" в чате может пройти почти незаметно, а в письме легко превращается в проблему.
Для CRM задача другая. Там не нужен красивый ответ клиенту, зато нельзя оставлять внутренние пометки, лишние персональные данные и догадки сотрудника. Если модель пишет "клиент, похоже, нервничает" или копирует полный номер документа туда, где хватило бы последних четырех цифр, такой текст лучше очистить до записи.
Удобно держать правила в одной матрице по каналам. Для чата задайте лимит длины, допустимый тон и запрет на лишние подробности. Для почты добавьте проверку обещаний, сроков и юридически чувствительных фраз. Для CRM включите удаление внутренних комментариев и минимизацию персональных данных. И сразу решите, что система может исправить сама, а что должно уйти на ручную проверку.
Пример простой. Бот поддержки банка отвечает клиенту про спорную транзакцию. В чате он пишет коротко: подтверждает прием запроса и не называет точный срок возврата. В письме тот же смысл проходит через отдельную проверку, которая убирает любые обещания по дате решения. В CRM сохраняется только сжатая служебная запись без лишних деталей клиента.
Матрицу правил лучше хранить в одном месте, а не вшивать по кускам в разные сервисы. Тогда команда видит, почему чат режет одно, почта другое, а CRM третье. Если трафик уже идет через единый шлюз, такую матрицу удобно держать рядом с маршрутами, логами и настройками проверки.
Как разделить правила по домену
Один и тот же ответ может быть безопасным для SaaS-сервиса и недопустимым для банка или клиники. Поэтому проверка исходящих ответов лучше работает не как один общий фильтр, а как набор доменных политик. Иначе модель либо говорит слишком сухо везде, либо пропускает то, что нельзя отправлять в чувствительных сценариях.
Для начала соберите отдельные правила хотя бы для четырех доменов: банк, медицина, ритейл и SaaS. Не смешивайте их в один длинный список. Когда правила лежат отдельно, команда быстрее понимает, почему ответ прошел или получил блокировку.
В банке фильтр должен строже проверять обещания по ставкам, срокам, штрафам, лимитам и условиям договора. В медицине он должен сразу резать советы, которые звучат как диагноз, схема лечения или замена врача. В ритейле обычно важны цена, наличие, возврат и условия доставки. В SaaS риск часто ниже, поэтому можно оставить больше технических деталей, если ответ не обещает того, чего продукт не делает.
Полезное правило здесь простое: запрещайте не тему, а тип действия. Фраза "обратитесь в суд и требуйте такую сумму" уже похожа на юридическое указание, даже если разговор начался с поддержки интернет-магазина. Фраза "увеличьте дозировку вдвое" недопустима для любого медицинского сценария, даже если пользователь настаивает.
Проверяйте не только слова, но и структуру ответа. Ошибки часто прячутся не в терминах, а в связках чисел и обещаний. Если модель пишет сумму, срок, процент, штраф или дату, валидатор должен понимать, к чему именно они относятся. Иначе ответ "штраф 0%, срок 90 дней" может пройти как нейтральный текст, хотя это уже почти договорное условие.
Доменные правила удобно задавать в четырех плоскостях: какие утверждения запрещены полностью, какие числа и сроки нужно сверять отдельно, какой уровень конкретики допустим и когда ответ должен звать человека в диалог вместо прямого совета.
Уровень детализации тоже надо делить по домену. Для банка лучше дать общую процедуру без точных обещаний, если система не подтвердила условия по данным клиента. Для медицины лучше ограничиться справочной информацией и советом обратиться к врачу. Для ритейла можно отвечать точнее, если есть актуальные остатки и правила возврата. Для SaaS обычно допустимы пошаговые инструкции, примеры API и разбор ошибок.
Если вы строите LLM-поток через единый шлюз, доменные политики удобно держать рядом с маршрутизацией и логами. Тогда команда видит, какая модель сгенерировала ответ, какое правило сработало и на каком шаге текст стал рискованным.
Когда нужна вторая модель
Второй вызов нужен там, где ошибка в ответе стоит дороже, чем лишние 300-800 мс задержки и еще один запрос. Обычно это ответы клиенту в банке, медицине, страховании, госсервисах и B2B-поддержке, где одна фраза может дать ложный совет, раскрыть персональные данные или нарушить внутренние правила. Для обычного FAQ в чате такой слой часто лишний. Для письма с условиями договора - уже нет.
Во многих командах вторую модель ставят слишком рано и просят ее "проверить все". Тогда она начинает спорить со смыслом, ловить шум и тормозить поток. Гораздо лучше дать ей узкую задачу: найти конкретный риск и вернуть метку. Например: "PII", "медицинский совет", "обещание скидки вне правил", "нужна ручная проверка". Иногда полезно вернуть еще короткую причину и фрагмент текста, который вызвал срабатывание.
Хуже всего работает схема, где вторая модель должна сама переписать ответ "как правильно" без шаблона. В таком режиме она легко меняет смысл, придумывает оговорки и портит тон. Если нужен автоматический правщик, дайте ему жесткие рамки: что можно менять, что нельзя, какой шаблон обязателен и какие поля должны остаться без изменений.
Вторая модель обычно оправдана в четырех случаях: когда ответ уходит в канал с высоким риском, когда домен чувствительный, когда основной модели трудно удерживать строгие правила на длинных ответах и когда у вас уже есть история инцидентов, которые простой набор правил не ловит.
Спорные случаи лучше не отдавать на полный автомат. Если модель не уверена, пусть ставит метку для человека, а не режет весь поток. Это заметно снижает ложные блокировки. На практике часто достаточно отправлять на ручную проверку 1-5% ответов, а не каждый второй.
Если трафик уже идет через шлюз, такой шаг удобно вынести в отдельный вызов: одна модель пишет ответ, другая проверяет его по узкому списку рисков. Тогда можно менять модель проверки по цене, скорости или домену, не трогая основную логику приложения.
Как собрать поток проверки по шагам
Схема работает, когда она похожа на таблицу решений, а не на один общий фильтр. Для исходящих ответов это особенно заметно: один и тот же текст можно пропустить в чате поддержки, но задержать перед отправкой письма клиенту.
Начните с реальных рисков, а не с абстрактных категорий. Обычно хватает 5-10 пунктов: утечка персональных данных, опасные советы, обещания от имени компании, токсичный тон, неверные суммы, запрещенный контент, юридически рискованные формулировки.
Дальше задайте контекст для каждого риска. Где он опаснее: в чате, email, голосовом канале или CRM-комментарии? В каком домене он критичен: финансы, медицина, возвраты, HR, госуслуги? Ошибка в дружелюбном чате про статус заказа и ошибка в письме про кредитный лимит - это разный уровень риска.
После этого назначьте действие системы. У каждого правила должен быть один понятный исход: пропустить ответ, переписать фрагмент, скрыть часть текста или отправить на ручную проверку. Если у правила два или три варианта без явного приоритета, команда начнет спорить уже в продакшене.
Небольшая матрица может выглядеть так:
- PII в чате поддержки - маскировать и отправлять
- PII в email - блокировать и отдавать оператору
- Финансовый совет без обязательной оговорки - переписать
- Уверенный ответ при низкой уверенности модели - ручная проверка
Потом прогоните поток на старых диалогах и письмах. Не берите только хорошие примеры. Нужны спорные случаи, где модель отвечала резко, путала политику возврата или вставляла лишние детали о клиенте. На таком наборе быстро видно, какие правила молчат, а какие режут слишком много.
Порог поднимайте только после разбора ложных срабатываний. Иначе вы просто делаете фильтр мягче, не понимая, что именно он ловит. Полезно отдельно смотреть три группы: что блокируется зря, что проходит зря и что вторая модель переписывает без пользы.
Если ответы идут через единый шлюз, общие проверки удобно держать в одном месте: маскирование PII, аудит-логи и базовые лимиты. Но правила по каналу и домену все равно лучше хранить отдельно. Тогда чат не наследует ограничения email, а сценарии банка не мешают рознице.
Пример с разным риском в чате и письме
Один и тот же ответ может быть допустимым в чате и опасным в письме. В чате клиент банка ждет быстрый ответ, и оператор или бот часто отвечает за несколько секунд. Письмо живет дольше, его пересылают и потом разбирают уже как официальный текст.
Представим запрос: клиент спрашивает, почему банк отклонил заявку. Базовая модель старается быть полезной и пишет вежливо, но добавляет фразу вроде "возможно, система увидела высокий кредитный риск по внутреннему скорингу". Формально это звучит аккуратно. По сути это домысел о причине отказа.
Такой ответ лучше резать на уровне домена, а не только общим фильтром. Доменный фильтр для банковских сценариев должен убирать любые предположения о скоринге, внутренних правилах, антифроде и лимитах, если система не получила это из проверенного источника. Иначе модель быстро начнет сочинять правдоподобные объяснения.
Дальше включается фильтр по каналу. Для чата он сокращает ответ до двух коротких фраз без лишних деталей. Для письма можно оставить чуть больше текста: общую формулировку об отказе, безопасное объяснение, что внутренние параметры не раскрываются, и понятный следующий шаг для клиента.
Сам поток здесь простой: базовая модель готовит черновик ответа, фильтр по домену удаляет догадку о скоринге, фильтр по каналу сжимает текст под чат или письмо, а вторая модель проверки ищет обещания, которых банк не должен давать.
Вторая модель тут нужна не для красоты. Она ловит фразы вроде "после уточнения данных мы пересмотрим решение" или "отказ можно быстро отменить после проверки". Даже если первая модель не придумала причину, она может случайно пообещать действие, на которое у поддержки нет права.
В итоге чат получает короткий ответ: банк не раскрывает внутренние параметры проверки по заявке, но клиент может обратиться в поддержку за дальнейшими шагами. В письме текст может быть чуть шире, но без догадок и без обещания пересмотра.
Если вы строите такую модерацию через шлюз с аудит-логами, полезно сохранять причину правки. В журнале стоит писать прямо: "удалена неподтвержденная причина отказа", "ответ сокращен для чата", "убрано обещание пересмотра". Потом команде проще понять, где модель ошибается чаще и какое правило надо менять.
Где команды чаще ошибаются
Чаще всего команды ломают модерацию не на сложных кейсах, а на базовой настройке. Они берут один универсальный проверяющий промпт и пускают через него все: чат, email, личный кабинет, внутренний инструмент. Для исходящих ответов это плохая идея, потому что риск зависит от того, где человек увидит текст и что он сделает дальше.
Если через один API-шлюз идут разные продукты и каналы, ошибка быстро становится дорогой. В чате можно попросить модель уточнить ответ через 10 секунд. Письмо клиенту живет дольше, его пересылают, а спор потом разбирает юрист или служба качества.
Самые частые промахи довольно приземленные. Команда ставит один и тот же проверяющий промпт на все каналы, хотя в живом чате допустим мягкий и неполный ответ с просьбой уточнить детали, а в письме тот же текст уже выглядит как обещание. Или в одном списке смешивают безопасность, тон, запреты бизнеса, требования закона и редактуру. Тогда проверяющая модель путает приоритеты и блокирует стилистическую мелочь как серьезный риск.
Еще одна типичная ошибка - резать весь ответ, хотя проблема только в одной строке. Если модель случайно раскрыла кусок PII или добавила лишнюю фразу с обещанием, систему обычно лучше научить маскировать, удалять или переписывать конкретный фрагмент. Полная блокировка нужна там, где весь ответ уже построен на неправильном допущении.
Бывает и обратный перекос. Команда слишком надеется на промпт самой модели и забывает про финальную проверку после шаблонов и подстановки данных. В итоге черновик проходит фильтр, а риск появляется уже на последнем шаге, когда в письмо добавились имя клиента, номер договора или формулировка, похожая на обязательство.
И еще один частый сбой: правила живут в голове у нескольких людей, а не в конфигурации системы. Пока объем трафика небольшой, это почти незаметно. Как только каналов и команд становится больше, начинается хаос: один сервис режет сроки, другой их пропускает, третий вообще не пишет причину блокировки.
Краткая проверка перед запуском
Перед первым релизом проверьте не только качество ответа, но и последний барьер перед отправкой. Команды часто ставят модерацию рядом с моделью и на этом успокаиваются. Это слишком рано: шаблон письма, вставка из базы знаний или постобработка могут добавить новый риск уже после первой проверки.
Перед запуском полезен короткий список, который легко пройти за один созвон и так же легко проверить в логах:
- Финальная проверка стоит прямо перед отправкой клиенту. После нее канал уже не меняет текст.
- Модерация получает канал и домен как отдельные поля. Она не угадывает их по промпту, имени бота или тексту ответа.
- Система пишет причину блокировки, ID правила и фрагмент ответа, который вызвал срабатывание.
- Команда видит долю правок, блокировок и ручных разборов по каждому каналу и домену.
- Спорные случаи уходят в очередь на ручную проверку, а не к клиенту.
Это кажется мелочью, но именно на таких деталях система ломается чаще всего. Один и тот же текст может быть допустим в чате поддержки и недопустим в письме. В банке короткое уточнение в чате еще может пройти, а в исходящем письме тот же смысл уже требует более строгого правила из-за обещаний, персональных данных или формулировок, похожих на совет.
Смотрите не только на сами блокировки. Если их почти нет, а ручных разборов много, система пропускает спорные ответы слишком далеко. Если правок слишком много, фильтры начинают портить тон и смысл, и пользователи это быстро замечают.
Если хотя бы один пункт пока держится на договоренности в чате команды, а не на явном правиле, поле в запросе и записи в логах, запуск еще сырой. Ошибка здесь обычно стоит дороже, чем лишний день на проверку.
Что сделать дальше
Если система уже отвечает клиентам, не пытайтесь сразу закрыть все риски. Возьмите один канал и один домен, где ошибка стоит дороже обычного. Например, чат поддержки для банка или письма с медицинскими рекомендациями. Так вы быстро увидите живые сбои: лишнюю уверенность, пропуск запрета, неверный тон, утечку персональных данных.
Хороший первый шаг простой. Выберите один сценарий с заметным риском, опишите 5-10 правил, которые нельзя нарушать, включите логирование всех срабатываний и ручную разметку спорных ответов, а потом прогоните поток на реальных примерах за последние 2-4 недели.
Если у вас несколько моделей, держите генерацию и проверки на одном маршруте. Иначе команда быстро теряет контроль: одна модель пишет ответ, другая стоит за отдельным прокси, третья проверяет уже в другом окружении. Потом трудно понять, где именно сломалась логика, почему выросла задержка и какой провайдер дал спорный результат.
Для команд в Казахстане такой контур удобно собирать через AI Router и endpoint api.airouter.kz: можно оставить текущие SDK, код и промпты почти без изменений, а маршрутизацию, аудит-логи и маскирование PII держать в одном месте. Это особенно полезно там, где важны хранение данных внутри страны и разбор спорных кейсов по журналам.
Правила не живут долго в исходном виде. То, что казалось разумным на старте, через месяц либо мешает полезным ответам, либо пропускает новый тип ошибки. Поэтому пересматривайте правила по инцидентам, а не по ощущениям. Раз в месяц откройте журнал, соберите повторяющиеся случаи и решите три вещи: что убрать, что уточнить и что перенести во вторую проверку.
Если нужен простой план на ближайшие две недели, он такой: сначала включите базовые фильтры для одного канала, потом добавьте доменные правила, после этого отправляйте спорные ответы на ручную проверку. Когда увидите частые промахи одного типа, тогда и подключайте вторую модель проверки. Такой порядок обычно экономит время и не ломает продукт на старте.
Часто задаваемые вопросы
Почему одного общего фильтра обычно мало?
Потому что смысл ответа меняется вместе с каналом. В чате спорную фразу можно сразу уточнить, а в письме тот же текст уже выглядит как позиция компании. Один общий фильтр обычно дает перекос: в одних местах режет лишнее, в других пропускает риск.
Где лучше ставить фильтры в цепочке ответа?
Ставьте проверку минимум в трех точках: сразу после генерации черновика, после сборки полей вроде темы письма или CTA и прямо перед отправкой. Так вы ловите риск и в тексте модели, и в данных, которые добавили позже из шаблонов или CRM.
Зачем нужна финальная проверка перед отправкой клиенту?
Потому что опасный фрагмент часто появляется в самом конце. Модель могла написать безопасный текст, а шаблон потом добавил имя клиента, номер договора или слишком уверенную формулировку. Последняя проверка останавливает такие случаи до отправки.
Чем правила для чата отличаются от правил для email?
Для чата обычно важны короткий спокойный тон и отсутствие лишних деталей. Для email правила строже: там нужно отдельно ловить обещания, сроки, скидки, компенсации и формулировки, похожие на обязательство компании.
Что отдельно проверять в записях CRM?
В CRM лучше хранить сухой факт, а не красивый ответ. Убирайте догадки сотрудника, внутренние пометки и лишние персональные данные. Если хватает последних четырех цифр документа или карты, не сохраняйте полное значение.
Как разделить правила по домену?
Разделяйте политики по реальному риску. Для банка строже проверяйте ставки, сроки, лимиты и штрафы; для медицины режьте диагнозы и схемы лечения; для ритейла следите за ценой, возвратом и доставкой; для SaaS можно оставить больше технических деталей, если ответ не обещает того, чего продукт не делает.
Когда вторая модель действительно нужна?
Подключайте вторую модель там, где ошибка стоит дороже лишней задержки. Обычно это банк, медицина, страхование, госсервисы и письма с чувствительными условиями. Для обычного FAQ в чате такой слой часто не нужен.
Нужно ли второй модели самой переписывать ответ?
Лучше не давать ей полную свободу. Пусть она ищет конкретный риск и возвращает метку вроде PII, обещание или ручная проверка. Если вы просите ее переписать ответ без жестких рамок, она легко меняет смысл и портит тон.
Как снизить ложные блокировки и не ломать полезные ответы?
Сначала сократите число правил до понятных действий и разберите старые диалоги с ошибками. Потом отправляйте сомнительные случаи человеку, а не режьте весь поток. Обычно хватает небольшой доли ручной проверки, если правила привязаны к каналу и домену, а не ко всему сразу.
Что проверить перед первым релизом такой модерации?
Перед запуском проверьте три вещи: модерация получает канал и домен как отдельные поля, последняя проверка стоит прямо перед отправкой, а логи сохраняют причину срабатывания и фрагмент текста. Если хотя бы один из этих пунктов держится только на договоренности команды, систему лучше сначала довести до явных правил.