Миграция на OpenAI-совместимый эндпоинт без сюрпризов
Миграция на OpenAI-совместимый эндпоинт кажется простой заменой base_url, но часто ломается на SDK, таймаутах, стриминге и JSON-ответах.
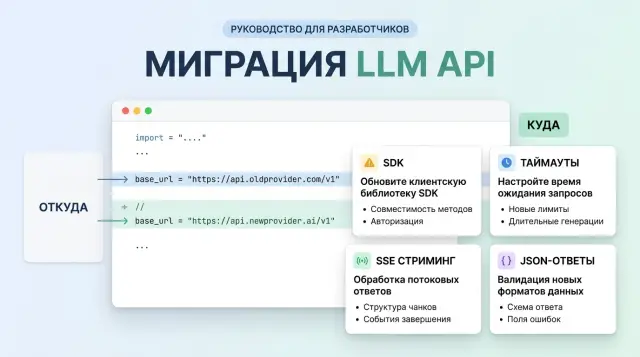
Почему одной замены base_url мало
На бумаге все выглядит просто: меняете адрес API, оставляете тот же SDK, и клиент идет на новый хост. На практике часть логики живет не в вашем коде. Ее прячет библиотека, внутренняя обертка или старый сетевой слой, который никто давно не трогал.
Из-за этого миграция на OpenAI-совместимый эндпоинт чаще ломается не в модели, а вокруг нее. Один SDK сам дописывает путь запроса и версию API. Другой меняет заголовки, формат ошибок или поведение стрима. Внешне вы сделали одну правку, а фактически поменяли цепочку из нескольких мест.
Обычно это проявляется так: клиент доходит до нового хоста, но собирает не тот маршрут; таймаут в SDK короче, чем реальный ответ модели; парсер ждет привычные поля и падает на другом JSON; короткий тест проходит, а рабочий сценарий нет.
Такое особенно часто всплывает, когда команда проверяет только один простой prompt. В тесте модель отвечает за две секунды обычным текстом, и все кажется нормальным. В продакшене тот же сервис просит длинный ответ, включает стриминг, ждет JSON для следующего шага и внезапно получает обрыв соединения или ошибку разбора.
Хороший пример - переход на OpenAI-совместимый шлюз вроде AI Router. Сам принцип замены адреса API там правда сокращает объем работ, потому что можно сохранить текущие SDK, код и промпты. Но это не отменяет проверку клиента: какой путь он строит сам, сколько ждет первый токен, как читает поток, что делает при 429 и какой JSON считает нормальным.
Одного зеленого запроса мало. Нужен хотя бы короткий прогон на реальном сценарии: длинный ответ, стрим, повтор после ошибки и разбор структуры ответа ровно так, как ее читает ваш код. Именно там обычно и сидят сюрпризы.
Что проверить до первого запроса
Если вы меняете только base_url, сначала найдите все места, где код вообще обращается к LLM API. Команда часто помнит только чат, но забывает про embeddings для поиска, images для маркетинга или audio для расшифровки. Потом основной сценарий проходит, а вспомогательный сервис падает в первый же день.
Начните с простого реестра по каждому сервису. Нужны не общие слова, а точные версии: какой SDK стоит, какой HTTP-клиент под ним, какие методы вызываются и как сервис получает ответ.
Проблема часто сидит не в шлюзе, а в старой версии клиента. Один сервис работает на свежем SDK, другой тянет библиотеку двухлетней давности и по-своему собирает заголовки, таймауты или стрим. Если у вас несколько языков в стеке, например Python для бэкенда и Node.js для воркеров, расхождения почти гарантированы.
Перед первым запросом проверьте четыре вещи:
- версии SDK и HTTP-клиента в каждом сервисе
- какие типы запросов реально используются: chat, embeddings, images, audio
- где код читает поток по кускам, а где ждет готовый JSON целиком
- где есть проверки на конкретные поля ответа, а не просто на успех
Даже такой список уже снимает часть риска. Чат-бот может читать stream, а сервис суммаризации ждать один готовый объект. После замены base_url оба идут в один эндпоинт, но ведут себя по-разному.
Где в коде зашиты хрупкие правила
Дальше поищите места, где разработчики когда-то добавили удобные, но ломкие допущения. Самые частые примеры: белый список model, обязательное наличие usage в каждом ответе, ожидание одного значения finish_reason и чтение только choices[0].message.content.
Такие проверки долго живут незаметно. Миграция вскрывает их сразу, потому что совместимость обычно относится к интерфейсу запроса, а не к каждой мелочи в ответе. Если сервис считает отсутствие usage ошибкой или не принимает новый идентификатор модели, он упадет еще до нормального теста качества.
Если вы используете AI Router, лучше проверить это до первого вызова в api.airouter.kz, а не после. Самая скучная работа перед стартом часто экономит день на разбор логов и ночной откат.
Как пройти миграцию без лишней боли
Самый безопасный путь - переключить не весь трафик, а один небольшой сервис с понятной нагрузкой. Лучше взять внутренний сценарий, где ошибка не остановит бизнес-процесс: например, генерацию кратких ответов для операторов или черновиков писем.
Если вы переходите на OpenAI-совместимый эндпоинт через AI Router, начните с простой замены base_url на api.airouter.kz только в этом сервисе. Дальше важен не масштаб, а порядок проверки. Один успешный запрос почти ничего не доказывает. SDK может пройти короткий вызов и сломаться на стриминге, длинном ответе или ретрае после таймаута.
Идите по шагам:
- Отправьте короткий запрос без стриминга. Проверьте, что клиент действительно ходит в новый эндпоинт, получает ожидаемый статус-код и не теряет заголовки.
- Прогоните длинный запрос. Он быстро показывает проблемы с таймаутами, размером тела ответа и разницей в обработке
usage,finish_reasonи ошибок. - Включите стриминг. Смотрите не только на текст, но и на то, как SDK читает чанки, закрывает соединение и собирает финальный ответ.
- Сравните ответы попарно: старый провайдер и новый. Сверяйте статус-коды, заголовки, JSON и поля, на которые завязан ваш код.
На этом этапе полезно сохранить несколько сырых ответов целиком. Часто проблема сидит не в основном тексте, а в мелочи: пустом поле, другом типе значения или неожиданном сообщении об ошибке.
Когда тестовый сервис проходит эти проверки, дайте на новый маршрут малую долю боевого трафика. Обычно хватает 5-10% на несколько часов. Смотрите не только на процент успешных запросов. Важнее логи ретраев, длительность ответа, обрывы стриминга и случаи, где приложение получило 200, но не смогло разобрать тело.
Если на этом шаге все чисто, переносите следующий сервис. Так вы потратите чуть больше времени на раскатку и гораздо меньше - на инциденты.
Где SDK ломаются чаще всего
Проблемы обычно появляются не в первом запросе, а во втором или третьем сценарии. Команда меняет base_url, получает успешный ответ на chat completions и решает, что миграция уже закончена. Потом приходят 404, пустой стрим и ошибки парсинга, которые на первый взгляд никак не связаны с одной настройкой.
Старые версии SDK часто читают новый адрес не везде. Основной клиент может ходить в новый шлюз, а отдельные методы для models, files или embeddings берут старый хост из значения по умолчанию. То же бывает и во внутренних обертках: разработчик передал base_url в один конструктор, а часть вызовов создает новый клиент со старыми настройками.
Еще один частый сбой - лишний путь в base_url. Если библиотека сама добавляет /v1, а вы уже указали адрес с этим суффиксом, запрос уходит на /v1/v1/... и получает 404. Бывает и наоборот: SDK ждет полный путь до API, а команда передает только домен. Выглядит как мелочь, но на поиск такой ошибки легко уходит полдня.
Типичные симптомы обычно такие:
- обычный ответ приходит, а стрим обрывается через несколько секунд
- chat completions работают, а embeddings или models падают с 404
- обертка видит пустой
content, хотя в JSON данные есть - часть запросов уходит не в тот хост, хотя
base_urlвроде бы задан
Отдельная проблема - старые обертки над SDK. Они жестко ждут формат OpenAI прошлой версии: строку в choices[0].message.content, usage в одном месте, одинаковую структуру ошибок. Как только ответ приходит с content как массивом частей, с tool_calls или с чуть другим полем ошибки, код ломается не на сети, а на разборе ответа. Снаружи это выглядит как "провайдер сломан", хотя на деле сломан клиент.
Со стримингом все еще неприятнее. Endpoint может работать нормально, но библиотека режет SSE по read timeout, если первый токен идет 15-30 секунд. Некоторые HTTP-клиенты еще и буферизуют поток вместо того, чтобы отдавать события по мере прихода. На совместимом шлюзе вроде AI Router это видно быстро: базовый запрос проходит, а длинный стрим внезапно замирает из-за настроек клиента.
Перед запуском стоит прогнать три отдельных теста: обычный chat completions, SSE-стрим длиной хотя бы 60 секунд и любой вторичный метод вроде models или embeddings. Такой набор быстро показывает, где у вас правда совместимый клиент, а где остались старые допущения.
Что делать с таймаутами, ретраями и стримингом
Одинаковый формат API не значит одинаковое сетевое поведение. Команда меняет base_url, первый запрос проходит, а через день прод ловит обрывы стрима, повторные POST и ответы через 65 секунд там, где старый провайдер укладывался в 20.
Сразу разделите таймаут на соединение и таймаут на чтение. Соединение показывает, как быстро клиент вообще достучался до сервера. Чтение показывает, сколько вы готовы ждать первый байт и следующие чанки. Если оставить один общий таймаут на все, вы не поймете, где именно проблема: сеть, прокси, модель или просто длинный ответ.
Полезно смотреть хотя бы на четыре числа:
- время установки соединения
- время до первого токена
- время между чанками в стриме
- полное время ответа
Время до первого токена часто важнее общей длительности. Пользователь нормально воспринимает длинный ответ, если видит, что модель начала писать через секунду или две. Если первый токен приходит через 15 секунд, интерфейс уже кажется сломанным.
С ретраями у POST-запросов ошибок больше всего. Многие SDK сами повторяют запрос при 429, 500, обрыве сокета или read timeout. Для chat completions это опасно: модель может уже начать обработку, а повтор создаст второй такой же запрос и лишние расходы. Лучше отключить слепые ретраи на POST и вернуть их только там, где у вас есть защита от дублей, например request_id или собственная дедупликация.
Если вы переводите клиента на OpenAI-совместимый шлюз, отдельно проверьте обычный ответ и stream=true. Эти режимы ломаются по-разному.
Что чаще всего режет стрим
SSE-канал живет дольше обычного JSON-ответа, и именно его чаще всего ломают промежуточные узлы. Фронтенд может ждать один формат события, а прокси - буферизовать поток вместо мгновенной передачи.
Проверьте несколько мест:
- не закрывает ли ingress или reverse proxy долгие соединения по idle timeout
- не включает ли прокси буферизацию SSE
- не ждет ли фронтенд полный JSON вместо обработки чанков
- не теряется ли событие завершения потока
Один простой тест быстро показывает проблему: запустите длинный стрим на 2-3 минуты и снимите логи на клиенте, прокси и бэкенде. Если сервер отправил первый чанк сразу, а браузер получил его через 20 секунд, модель тут ни при чем. Чинить нужно цепочку доставки.
Где на практике расходятся форматы ответов
Одинаковый текстовый ответ еще не значит, что JSON тоже одинаковый. После замены base_url команда часто смотрит только на поле content, а проблемы прячутся рядом: в usage, служебных метаданных и структуре вызова инструментов. Из-за этого ломаются биллинг, логи, аналитика и автоматические тесты.
Чаще всего расхождения выглядят так:
usageприходит в другом месте или только в финальном событии стримаfinish_reason,refusal,modelиidлежат не там, где ждет ваш кодtool_callsприходит массивом, а старый код ждет одинfunction_call- аргументы инструмента приходят строкой JSON, а не готовым объектом
- пустые массивы и
nullменяют логику обработчика
С usage путаница встречается постоянно. Один провайдер возвращает его сразу в основном ответе, другой - только после завершения стрима, третий не отдает детали по кэшированным или внутренним токенам. Если сервис пишет стоимость запроса сразу после первого чанка, он легко посчитает ноль или сохранит неполные цифры.
Служебные поля тоже разъезжаются. Где-то finish_reason лежит внутри choices[0], где-то часть метаданных идет отдельно, а где-то их нет при ошибке фильтрации. Поэтому на старте лучше сохранять сырой ответ целиком хотя бы в тестовой среде. Это быстро показывает, где схема уже ушла в сторону.
Отдельная боль - tool_calls и старый function_call. Новые реализации чаще отдают массив вызовов, даже если вызов один. Поле arguments при этом может быть обычной строкой, JSON-строкой с экранированием или уже распарсенным объектом. Если рантайм ждет только один вариант, сбой появится не сразу, а в тот момент, когда модель впервые решит вызвать инструмент.
null и пустые массивы тоже нельзя считать мелочью. content бывает null, если модель вернула только вызов инструмента. tool_calls может отсутствовать совсем, а может прийти как пустой массив. Для кода это разные случаи. Проверка вида if tool_calls часто скрывает ошибку, а потом команда долго ищет, почему оркестратор молча пропускает шаг.
С response_format и structured output нужна проверка на живых примерах, а не только на happy path. Даже если API принимает JSON schema, модель может вернуть обычный текст при отказе, обрезке по длине или проблеме с валидацией. Если вы переходите на единый совместимый эндпоинт, полезно прогнать несколько реальных сценариев: успешный ответ, вызов инструмента, отказ, длинный ответ и стрим.
Как это выглядит в рабочем сервисе
Команда переводит внутренний чат-ассистент на новый эндпоинт и сначала делает то, что кажется самым логичным: меняет только base_url. Если сервис использует OpenAI-совместимый шлюз вроде AI Router, этот шаг часто и правда позволяет быстро поднять первый успешный запрос.
Проверка выглядит обнадеживающе. Короткий вопрос вроде "сделай сводку письма" проходит, ответ приходит быстро, статус 200, в логах все спокойно. На этом месте многие решают, что миграция почти закончена.
Проблемы начинаются на длинном диалоге. Сотрудник открывает старую переписку на 30-40 сообщений, просит ассистента продолжить разговор, и интерфейс зависает примерно через минуту. Бэкенд не видит явной ошибки, потому что запрос не всегда падает по сети. Чаще срабатывает таймаут в SDK, в reverse proxy или в клиенте браузера, который ждет полный JSON вместо потока чанков.
Потом всплывает вторая странность: в логах снова 200, но UI падает на разборе ответа. Причина обычно скучная, но неприятная. Фронтенд ждет один формат chat.completions, а получает чуть другой: пустой content в одном чанке, tool_calls в другом, поле usage только в финале стрима или текст с переводами строк, который код пытается парсить как готовый JSON-объект.
Обычно команда чинит это в несколько ходов: увеличивает таймауты для длинных ответов и стриминга, проверяет, что клиент умеет читать SSE по частям, ослабляет слишком жесткие проверки схемы ответа и добавляет тесты для длинного диалога, tool calls и пустых промежуточных чанков.
После правок уже не гоняют один удачный prompt. Берут около двадцати типовых запросов: короткий вопрос, длинный контекст, ответ со структурированным JSON, вызов инструмента, потоковый режим, отмена запроса, повтор после таймаута. Если все это проходит стабильно, трафик переводят по частям.
Такой подход скучнее, чем простая замена base_url, зато он быстро показывает, где ломается реальный сервис, а не демо-скрипт в локальной консоли.
Ошибки, которые всплывают слишком поздно
Чаще всего миграция выглядит удачной до тех пор, пока команда гоняет только "hello world". Короткий запрос проходит, простой ответ приходит, и все считают, что замена base_url готова. Потом в проде прилетает длинный диалог, ответ идет 40-60 секунд, SDK режет соединение по таймауту, и сервис внезапно начинает отвечать ошибками.
Такие сбои особенно неприятны, потому что тесты их не ловят. Команда проверила один сценарий на 200 токенов, а реальный пользователь просит сводку на несколько страниц, таблицу или длинный разбор документа. На коротких ответах все спокойно. На длинных всплывают таймауты, лимиты на размер тела ответа, проблемы со стримингом и отличия в структуре данных.
Еще одна частая ошибка - менять SDK и эндпоинт в один релиз. После этого никто уже не понимает, что именно сломало поведение: новый клиент, новый парсер ошибок, другие настройки ретраев или сам шлюз. Если старый код работал с одним SDK, сначала оставьте его как есть и замените только адрес.
Отдельно бьет плавающая версия клиента. Один стенд тянет свежий релиз SDK, другой живет на версии месячной давности, локальная машина разработчика вообще ставит пакет без фиксации. В итоге один и тот же запрос ведет себя по-разному: где-то парсится tool call, где-то нет, где-то стриминг собирается корректно, а где-то библиотека ждет другой формат события.
С логами команда тоже часто ошибается. Когда интеграция начинает сбоить, разработчики включают подробный debug и пишут в логи весь prompt целиком. Так в логах быстро оказываются телефоны, адреса, номера договоров и другие персональные данные. Если вы работаете через шлюз вроде AI Router, лучше заранее проверить маскирование PII и аудит-логи, особенно если у вас есть требования по хранению данных внутри страны.
Обычно поздно замечают четыре вещи:
- тесты не гоняют длинные ответы и долгие сессии
- релиз меняет сразу несколько переменных
- версия SDK не зафиксирована для всех стендов
- логи собирают чувствительные данные без фильтрации
Если эти места проверить до запуска, миграция проходит скучно. Это хороший знак. Самые дорогие инциденты почти всегда начинаются с фразы "у нас же уже был успешный тест".
Короткая проверка перед запуском
Если вы уже поменяли только base_url, этого мало. Перед запуском нужен короткий прогон, который ловит не теоретические, а самые дорогие ошибки: обрыв стриминга, лишние ретраи, пустые поля и неожиданные 429 под нагрузкой.
Начните с двух запросов. Первый - короткий, на 20-50 токенов, без стриминга. Он покажет, что аутентификация, маршрут и базовый формат ответа живы. Второй - длинный, с большим ответом или генерацией на 1-2 минуты. Именно он обычно вскрывает таймауты на прокси, буферизацию у балансировщика и разницу между локальной проверкой и боевым трафиком.
Если вы переводите клиента на OpenAI-совместимый шлюз, проверяйте не только код приложения. Смотрите весь путь ответа: SDK, backend, reverse proxy, фронтенд и логи. Часто backend получает стрим нормально, а браузер видит куски с задержкой в 10-20 секунд или вообще ждет весь ответ целиком.
Минимальный прогон
- отправьте один короткий и один длинный запрос тем же SDK и с теми же настройками, что пойдут в прод
- включите стриминг и убедитесь, что чанки доходят без обрывов и не склеиваются в один большой блок
- отдельно проверьте 429 и 500: код должен повторить запрос там, где это безопасно, и не уйти в бесконечный цикл
- подайте ответ с пустым
content, отсутствующимusageили неожиданнымfinish_reasonи проверьте, не падает ли парсер
Хороший тест занимает полчаса. Слабый тест занимает пять минут, а потом съедает полдня у дежурной команды.
До выката договоритесь, кто и как откатывает изменение. Нужен простой план: вернуть старый base_url, отключить стриминг флагом или временно перевести часть трафика назад. Если откат требует ручных правок в трех сервисах, это уже не план.
На первые часы после запуска держите перед глазами четыре метрики: долю ошибок, p95 по времени ответа, число ретраев и долю оборванных стримов. Если 429 резко растут, а задержка прыгает, не спорьте с графиками. Снижайте нагрузку, режьте параллелизм или откатывайте маршрут сразу.
Что делать после переключения
Не убирайте старый маршрут сразу. На время раскатки оставьте его как запасной вариант и дайте сервису быстрый способ отката. Когда новый путь начнет сбоить под реальной нагрузкой, это сэкономит часы, а иногда и целый релиз.
Сравнивайте не по ощущениям, а на одном и том же наборе запросов. Возьмите 50-100 типовых prompt: короткие, длинные, со стримингом, с tool calls, с большим контекстом. Прогоните их через старый и новый маршрут и смотрите на задержку, долю ошибок и цену.
Для такой проверки достаточно короткого чек-листа:
- считайте среднее время ответа и отдельно медленные запросы
- фиксируйте таймауты, 429, 5xx и ошибки парсинга
- сравнивайте итоговую стоимость на одинаковом объеме трафика
- проверяйте, меняется ли качество ответа на одних и тех же prompt
Есть одна тонкость, которую часто пропускают: стоимость нельзя оценивать только по тарифу модели. Если новый маршрут чаще ретраит запросы, дольше держит соединение или ломает стриминг, итоговая цена для сервиса растет даже при той же ставке за токены.
Если вам нужен один OpenAI-совместимый шлюз для разных моделей, разумно пустить через него сначала небольшой кусок трафика. В этом сценарии AI Router выглядит как удобный вариант для пилота: он дает единый OpenAI-совместимый эндпоинт, совместим с текущими SDK и позволяет не переписывать клиент при смене маршрута. Для команд из Казахстана и Центральной Азии еще важны практические вещи вроде хранения данных внутри страны, маскирования PII, аудит-логов и B2B-инвойсинга в тенге. Их лучше включить в сравнение сразу, а не после релиза.
Хороший финал миграции выглядит скучно: новый путь держит нагрузку, старый остается как временная страховка, а у команды есть цифры вместо догадок.