Маскирование PII перед вызовом модели: где и как делать
Маскирование PII помогает скрыть личные данные до запроса к LLM. Покажем, где ставить редактирование, как мерить потерю смысла и как безопасно вернуть поля.
Почему нельзя отправлять PII в модель как есть
Когда сотрудник вставляет в промпт письмо клиента, заявку или переписку из CRM, туда почти всегда попадают персональные данные. Обычно это не одно поле, а сразу набор: ФИО, телефон, email, ИИН, адрес, номер договора, иногда дата рождения и детали платежа. Для модели это просто текст. Для бизнеса - уже риск.
Проблема не ограничивается самим вызовом модели. Сырой текст часто остается сразу в нескольких местах:
- в логах приложения
- в истории чата или тикета
- в кэше запросов
- в трассировке и APM
- в отладочных дампах
Даже если модель ничего не "запомнила", копии данных уже лежат в вашей инфраструктуре и у внешних сервисов по пути. Иногда одного debug-лога достаточно, чтобы вся схема защиты потеряла смысл.
Риск растет, когда команда меняет модели и провайдеров. Сегодня запрос уходит в один сервис, завтра - в другой. Разработчики часто просто меняют base_url и отправляют тот же промпт. Это удобно, но маршрут данных меняется. У разных провайдеров разные правила хранения, разные регионы обработки и разный набор служебных логов. Если вы параллельно гоняете A/B-тесты, точек риска становится еще больше.
Пилот тоже не спасает. На тестовом этапе команды как раз чаще отключают фильтры, пишут больше логов и просят коллег вставлять реальные кейсы "для проверки качества". Так в тестовую среду попадают настоящие ИИН, адреса и телефоны. Потом пилот вырастает в рабочий сервис, а сырые данные уже успели разойтись по чатам, ноутбукам и системам мониторинга.
Есть и тихая проблема: PII быстро прилипает к данным так, что потом ее трудно убрать. Если оператор отправил в модель фразу вроде "Проверьте заявку Айгерим Садыковой, ИИН 030101...", эти данные могут оказаться в ответе модели, в пересланной переписке и в ручной разметке для оценки качества.
Поэтому редактирование персональных данных нужно ставить до вызова модели, а не после. Лучше потратить минуту на настройку фильтра, чем потом искать, где именно система сохранила чужой ИИН или адрес.
Что считать PII в вашем потоке
PII редко лежит в одном поле с ярлыком "персональные данные". Обычно она размазана по форме заявки, переписке с поддержкой, письмам, PDF, сканам документов и тексту после OCR. Если искать только имя, телефон и email, часть риска вы почти наверняка пропустите.
Сначала соберите все реальные источники входа: формы, чат, почту, выгрузки из CRM, сканы, голосовые расшифровки и результаты OCR. Потом разберите, какие фрагменты модель видит целиком, а какие попадают в промпт по кускам. После такого упражнения список чувствительных полей обычно заметно растет.
Удобно разделить данные на две группы:
- Прямые идентификаторы: ФИО, ИИН, номер телефона, email, точный адрес, номер паспорта, внутренний ID клиента.
- Косвенные идентификаторы: номер заказа, должность, город, место работы, дата приема, редкая жалоба, номер филиала.
Косвенные поля часто недооценивают. По отдельности они могут казаться безобидными. Но фраза вроде "главный бухгалтер в Костанае, заказ 184533, прием 12 мая" уже может указывать на одного конкретного человека.
Отдельно проверьте свободный текст. Именно там люди пишут лишнее: "Меня зовут Айжан, мой ИИН..., я была у врача вчера". OCR дает тот же эффект. В скане могут оказаться имя, подпись, номер документа и адрес, даже если вы не собирались отправлять их в модель.
Не все поля нужно вырезать полностью. Часть данных можно обобщить без заметной потери смысла. Вместо даты рождения часто хватает возрастной группы. Вместо полного адреса - города. Вместо точной суммы - диапазона. Если модели нужен контекст обращения, а не личность клиента, этого обычно достаточно.
Для Казахстана ИИН лучше добавить в правила с первого дня. Это не редкий случай и не отдельная ветка для пары клиентов. ИИН встречается в анкетах, письмах, договорах, сканах и чатах, часто рядом с именем и телефоном.
Есть простой тест. Возьмите 20-30 реальных запросов и отметьте, какие данные модели действительно нужны для ответа, а какие нужны только вашим системам. Во многих сценариях модели достаточно видеть проблему клиента, статус заказа и продукт. ИИН, полный адрес и телефон ей не нужны.
Где ставить редактирование в потоке
Редактирование персональных данных нужно ставить в самом начале цепочки. Если запрос сначала попадет в логи, кэш или историю агента, а потом пройдет очистку, защита уже дала сбой. Данные успеют разойтись по системам, где их трудно найти и удалить.
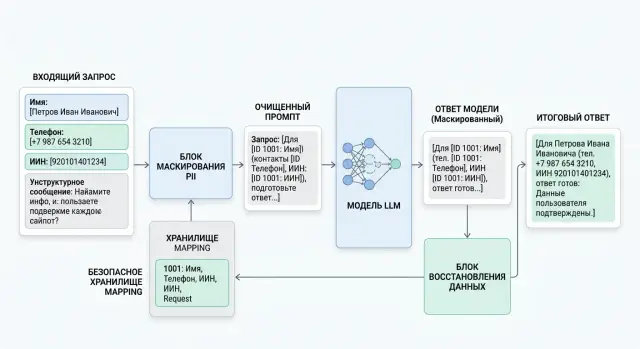
Обычно лучший слой для этого - входной API или шлюз, еще до маршрутизации и до любой работы агента. Текст приходит, сервис находит PII, заменяет фрагменты на метки вроде [EMAIL_1] или [PHONE_1], и только потом передает запрос дальше.
Рабочий порядок выглядит так:
- Сразу после приема запроса выделите чувствительные поля в тексте, метаданных и служебных полях.
- Замените найденные значения на понятные токены: [NAME_1], [PHONE_1], [IIN_1]. Один и тот же фрагмент должен получать один и тот же токен в рамках запроса.
- Сохраните таблицу соответствий отдельно от промпта, только если она действительно нужна. Лучше привязать ее к request_id и держать короткое время.
- Передайте в логи, кэш, агента и модель только очищенный текст.
- После ответа модели возвращайте поля назад только в разрешенные места и только по строгим правилам.
Последний шаг часто ломают. Команда берет ответ модели и просто заменяет все [NAME_1] на исходное имя в любом месте текста. Это опасно. Модель может перенести токен в новый контекст: например, вставить [PHONE_1] в заметку для оператора или в лишний абзац. Безопаснее заранее определить список разрешенных полей, например greeting, contact_block или contract_number. Если токен появился вне этого списка, оставьте его замаскированным и отправьте ответ на проверку.
То же правило действует для вложений. PDF, сканы, фото документов и голосовые расшифровки после OCR часто содержат даже больше чувствительных данных, чем обычный чат. Для файлов не должно быть отдельного пути без фильтра: сначала извлечение текста, потом очистка, и только после этого индексация, суммаризация или вызов модели.
Сырой текст имеет смысл хранить только в отдельном закрытом контуре. Обычно он нужен для спорных случаев, ручной проверки или архивных задач, где без оригинала не обойтись. Тогда храните его отдельно от основного приложения, ограничьте доступ по ролям и задайте короткий срок хранения.
Если у команды единый LLM-шлюз, правило не меняется. Сначала очистка, потом отправка запроса дальше. Это актуально и для AI Router: в api.airouter.kz лучше отправлять уже обезличенный текст, даже если сам шлюз помогает закрывать требования по хранению данных, аудит-логам и маскированию PII.
Хороший признак зрелого процесса простой: промпт, кэш и ответ модели живут без персональных данных, а обратная подстановка происходит только в конце и только по правилам.
Как не потерять смысл после маскирования
Маскирование PII легко ломает смысл запроса, если проверять его на паре удачных примеров. Нужен простой тест: возьмите одну и ту же задачу, один и тот же промпт и сравните ответ модели на сыром тексте и на очищенном.
Для такой проверки не нужен огромный датасет. Хватит набора из реальных запросов, которые часто встречаются в работе: обращения в поддержку, анкеты, заявки, письма, заметки оператора. Редкие и экзотические случаи лучше вынести отдельно, иначе они испортят картину.
Смотреть нужно не только на "качество ответа" в общем виде. Проверьте хотя бы пять вещей:
- поняла ли модель, кто есть кто в тексте
- не перепутала ли даты, суммы и адреса
- не стало ли больше лишних отказов
- не исчезли ли важные детали для решения задачи
- не начал ли ответ звучать слишком общо
Лишние отказы часто пропускают. Исходный запрос может быть понятным, а после замены имени, номера договора и адреса на грубые метки модель вдруг пишет, что данных мало и она не может помочь. Формально это безопасно, но для бизнеса это слабый результат.
Проверяйте типы масок по отдельности. Одна и та же схема по-разному влияет на смысл. Имя редко ломает задачу. Адрес может сломать маршрутизацию заявки. Сумма меняет приоритет обращения. Номер документа иногда нужен, чтобы различить два похожих кейса.
Поэтому лучше тестировать по шагам. Сначала замените только имена. Потом только суммы. Потом только документы. Потом только адреса. Так быстрее видно, что именно портит ответ.
Небольшой пример: в жалобе есть фраза "спишите ошибочно начисленные 12 500 тенге по договору от 14 марта". Если вы замените и сумму, и дату на одинаковые токены вроде [REDACTED], модель может потерять привязку к событию и ответить расплывчато. Если вместо этого использовать разные метки, например [SUM_1] и [DATE_1], смысл обычно сохраняется лучше.
Если вы вызываете модели через шлюз вроде AI Router, тест все равно нужен. Шлюз решает вопросы маршрутизации и инфраструктуры, но именно ваша задача определяет, какая степень маскирования еще оставляет текст понятным.
Пример на обращении клиента
Обычное письмо в поддержку уже дает модели весь нужный контекст. Исходные персональные данные ей для этого чаще всего не нужны.
Здравствуйте. Меня зовут Айгуль Садыкова, мой телефон +7 701 123 45 67, ИИН 930512400123.
У меня второй день не проходит оплата в мобильном приложении. После подтверждения перевода вижу ошибку "операция отклонена", хотя лимит не превышен.
Проверьте, пожалуйста, что не так и как мне завершить платеж.
Перед вызовом модели текст проходит через маскирование PII. Сервис меняет имя, телефон и ИИН на токены, а карту замен хранит отдельно. Лучше держать ее в памяти запроса или в защищенном хранилище с коротким сроком жизни.
Текст для модели:
Здравствуйте. Меня зовут [NAME_1], мой телефон [PHONE_1], ИИН [IIN_1].
У меня второй день не проходит оплата в мобильном приложении. После подтверждения перевода вижу ошибку "операция отклонена", хотя лимит не превышен.
Проверьте, пожалуйста, что не так и как мне завершить платеж.
Карта замен:
[NAME_1] -> Айгуль Садыкова
[PHONE_1] -> +7 701 123 45 67
[IIN_1] -> 930512400123
Смысл письма почти не меняется. Модель по-прежнему видит проблему: сбой оплаты в приложении, повторяемость ошибки и просьбу объяснить следующий шаг. Этого хватает, чтобы классифицировать обращение, предложить проверку и составить черновик ответа.
Потерю смысла лучше проверять на простой паре тестов. Дайте модели исходный текст и замаскированный текст, а потом сравните результат по трем вещам: верно ли определена тема обращения, не пропал ли признак срочности, не изменилась ли рекомендация для клиента. Если ответы совпадают по сути, редактирование персональных данных не ломает задачу.
В этом примере модель может предложить проверить статус карты, повторить платеж позже, уточнить, повторяется ли ошибка в другой сети, и при необходимости передать кейс в платежную команду. Ни имя, ни телефон, ни ИИН для этого не нужны.
Назад возвращайте только те поля, без которых финальный ответ нельзя отправить. Обычно хватает имени для обращения. ИИН в ответ клиенту вставлять не надо. Телефон тоже не нужен, если система и так знает канал связи.
Финальный ответ клиенту:
Айгуль, здравствуйте. Мы видим повторяющуюся ошибку при оплате в приложении.
Попробуйте обновить приложение и повторить платеж чуть позже.
Если ошибка сохранится, мы передадим обращение в профильную команду и свяжемся с вами по текущему каналу.
Такой поток заметно снижает риск утечки и при этом сохраняет смысл запроса для модели.
Как безопасно вернуть поля в ответ
После маскирования PII самый опасный шаг - обратная подстановка. Ошибка здесь быстро ломает всю защиту: модель меняет токен, переносит его в другой фрагмент текста или вставляет личные данные туда, где их не должно быть.
Подставляйте назад только те токены, которые модель вернула без изменений. Если вы отправили [PHONE_1], а в ответе получили тот же [PHONE_1], номер можно восстановить. Если модель написала [PHONE], PHONE_1 без скобок или просто "телефон клиента", замену лучше запретить.
Нужна и проверка типа. Телефон можно вернуть только в поле телефона, email - только в email, ИИН - только в ИИН. Простая строковая замена без проверки типа быстро приводит к нелепым и опасным ошибкам, когда email внезапно попадает в подпись письма, а телефон - в поле имени.
Обычно хватает такого порядка:
- найти в ответе только точные, неизмененные токены
- сверить тип каждого токена с типом целевого поля
- подставить данные только в разрешенные части ответа
- удалить временную карту соответствий сразу после выдачи ответа
Разрешенные части ответа лучше задать заранее. Например, можно возвращать данные в текст для клиента или в конкретные поля CRM. Не стоит возвращать их в служебные заметки, технические журналы, трассировку ошибок и внутренние комментарии. Если у вас есть аудит-логи на уровне шлюза, храните там токены и факт замены, а не исходные значения.
Самой модели не нужна карта соответствий вроде [EMAIL_1] = [email protected]. Она должна видеть только токены. Карту держите на своей стороне: в памяти запроса, в защищенном хранилище с коротким TTL или в отдельном сервисе, который не пишет значения в логи.
Короткий пример: клиент пишет "Позвоните мне на [PHONE_1] и пришлите договор на [EMAIL_1]". Модель отвечает "Мы свяжемся с вами по [PHONE_1] и отправим договор на [EMAIL_1]". Такой ответ можно восстановить автоматически. Если она ответила "Мы позвоним вам" или перенесла [EMAIL_1] в заметку для оператора, подстановка не нужна.
Временные карты соответствий не стоит хранить часами. Для большинства сценариев хватает нескольких минут. Ответ ушел клиенту, окно отката закрылось - карту лучше стереть.
Ошибки, которые ломают защиту
Чаще всего защита ломается не на уровне модели, а раньше. Команда вроде бы добавила маскирование PII, но один неверный шаг в цепочке сводит результат к нулю: сырые данные уже попали в лог, карта замен лежит рядом с промптом, а ответ собирают обратно без проверки.
Самые частые ошибки такие:
- Редактирование ставят слишком поздно. Если API-шлюз, прокси, трассировка или debug-лог успели записать исходный текст до маскирования, защита уже не сработала.
- Всех людей заменяют одним и тем же маркером. В фразе "Иван перевел деньги Ольге" токен [PERSON] быстро ломает роли и смысл. Лучше использовать [PERSON_1], [PERSON_2], [ACCOUNT_1].
- Чистят только обычный текст. На практике PII живет еще и в PDF, скриншотах, таблицах, CSV и тексте после OCR.
- Возвращают скрытые поля в свободную фразу без шаблона. Модель может вставить поле не туда, поменять формат номера или смешать данные двух клиентов.
- Хранят карту соответствий рядом с запросом. Если промпт, замены и исходные значения лежат в одной записи и доступны одному сервису без ограничений, риск никуда не исчезает.
Есть хороший быстрый тест: представьте, что кто-то получил доступ только к логам модели. Сможет ли он восстановить человека, счет, телефон или адрес? Если да, маскирование сделали формально.
Полезно проверить и обратную сторону: понимает ли модель смысл после замены. Возьмите 20-30 реальных примеров и сравните результат до и после очистки. Если качество резко падает, проблема часто не в самой идее маскирования, а в слишком грубых токенах без различий между сущностями.
Отдельно проверьте путь возврата данных. Сервис, который делает обратную подстановку, не должен угадывать, куда вставить поле. Он должен работать только с разрешенными слотами, например [CLIENT_NAME] или [PHONE_1], и отклонять любой лишний текст вокруг них. Это скучное правило, но именно оно часто спасает от тихих утечек.
Проверка перед запуском
Перед релизом не нужен аудит на сто страниц. Хватит короткой проверки, но пройти ее надо честно. Если хотя бы на один пункт ответ "нет", лучше остановиться на день и поправить схему.
- Проверьте, видит ли модель хоть одно реальное имя, телефон, ИИН, номер карты, адрес или номер договора.
- Убедитесь, что редактирование срабатывает раньше логов, кэша, очередей, ретраев и трассировки.
- Запустите тесты на потерю смысла на 20-30 реальных обращениях без лишней экзотики.
- Ограничьте места, где можно делать обратную подстановку. Возврат должен идти только в финальном слое ответа и только по белому списку полей.
- Назначьте владельца правил: кто меняет словари, кто одобряет новые типы PII и кто разбирает инциденты.
Один сквозной тест ловит половину проблем. Возьмите обращение клиента вроде "Меня зовут Алия, мой номер 8..." и прогоните его по всему пути: вход, лог, кэш, вызов модели, ответ, подстановка полей. На каждом шаге должно быть ясно, где лежат настоящие данные, а где только маски.
Если вы отправляете запросы через шлюз, проверьте ту же цепочку не только в приложении, но и на уровне интеграции. Иначе можно аккуратно закрыть фронт и оставить сырые данные в служебных слоях, где их никто не ожидал увидеть.
Что делать дальше
Начните с одной точки входа. Все запросы к моделям должны проходить через один и тот же слой, даже если у вас несколько приложений, команд и провайдеров. Иначе одна интеграция будет маскировать данные, а другая случайно отправит в модель телефон, ИИН или номер договора как есть.
После этого зафиксируйте правила в одном документе. Не в чате и не в разрозненных заметках, а в коротком рабочем описании: какие поля вы маскируете, какими токенами заменяете, где храните таблицу соответствий, кто может вернуть исходные значения и в каких ответах это разрешено. Если правило нельзя быстро прочитать и проверить, его начнут трактовать по-разному.
Нормальный стартовый план такой:
- выбрать единый вход для всех вызовов LLM
- описать маски, исключения и возврат полей в одном месте
- запустить пилот на 50-100 реальных запросах
- разобрать ошибки вручную и поправить правила до широкого запуска
Пилот лучше делать на живых сценариях, а не на придуманных примерах. Возьмите обращения клиентов, внутренние запросы сотрудников или типовые документы и проверьте две вещи: утекли ли персональные данные и не потерялся ли смысл после замены. Обычно проблемы видны быстро. Модель путает токены, теряет связь между полями или начинает отвечать слишком общо, если вы скрыли больше, чем нужно.
Ручной разбор здесь обязателен. Смотрите, где маска ломает задачу, а где правила, наоборот, слишком мягкие. Полезно отмечать каждый сбой по простой схеме: что скрыли, что модель должна была понять, что поняла на деле и можно ли вернуть поле безопасно после ответа без повторной отправки исходных данных в модель.
Если вы работаете с несколькими провайдерами, не стоит дублировать эту логику в каждом сервисе. Проще вынести маскирование, аудит-логи и контроль возврата полей в один слой. Для команд из Казахстана и Центральной Азии таким слоем может быть AI Router: это единый OpenAI-совместимый API-шлюз, который помогает централизовать маршрутизацию моделей и требования по хранению данных внутри страны. Но даже в этом случае безопаснее считать одно правило базовым: сначала очистка текста, потом вызов модели.
Хороший итог на этом этапе выглядит просто: любой запрос проходит через один фильтр, правила лежат в одном месте, а после пилота у вас есть список конкретных правок вместо ощущения, что "вроде все безопасно".
Часто задаваемые вопросы
Почему нельзя просто отправить письмо клиента в модель как есть?
Потому что риск появляется не только в самой модели. Сырой текст часто попадает в логи, кэш, историю чата, трассировку и отладочные дампы. Даже если модель не хранит запрос, копии данных уже остаются в вашей системе и у сервисов по пути.
Что считать PII, кроме имени и телефона?
Смотрите шире, чем на имя, телефон и email. В поток часто попадают ИИН, адрес, номер договора, внутренний ID, дата рождения, детали платежа, а еще косвенные признаки вроде города, должности, номера заказа и редкой жалобы. В связке такие поля тоже могут указывать на человека.
Где лучше ставить маскирование в потоке?
Ставьте фильтр в самом начале, до логов, кэша, очередей, ретраев и вызова модели. Обычно для этого подходит входной API или LLM-шлюз. Если текст сначала увидела другая часть системы, а потом вы его очистили, защита уже дала трещину.
Нужно ли чистить PDF, сканы и текст после OCR?
Не делайте для файлов отдельный путь. Сначала извлеките текст из PDF, скана или аудио, потом найдите и замените чувствительные фрагменты, и только после этого отправляйте данные в индекс, суммаризацию или модель. OCR почти всегда приносит больше лишних данных, чем кажется на старте.
Как заменять данные, чтобы модель не теряла смысл?
Используйте понятные токены с типом и номером, например NAME_1, PHONE_1, IIN_1. Не заменяйте все одним маркером вроде REDACTED, иначе модель теряет роли и связи в тексте. Если в запросе два человека, дайте им разные токены, чтобы не спутать действия и контекст.
Как проверить, что после маскирования качество не упало?
Возьмите 20–30 частых реальных запросов и сравните ответы на сыром и очищенном тексте. Проверьте, правильно ли модель поняла тему, не пропала ли срочность и не стала ли рекомендация слишком общей. Если качество просело, обычно проблема в грубых масках, а не в самой идее очистки.
Где хранить карту соответствий и как долго?
Храните ее отдельно от промпта и как можно меньше по времени. Лучше привязать карту к request_id, держать в памяти запроса или в защищенном хранилище с коротким TTL и не писать значения в логи. Если промпт и исходные данные лежат рядом, риск почти не снижается.
Как безопасно вернуть поля в финальный ответ?
Возвращайте только те токены, которые модель сохранила без изменений, и только в разрешенные поля. Если вы отправили PHONE_1, а в ответе получили другой формат или новый контекст, подстановку блокируйте. Имя можно вернуть в приветствие, но не стоит вставлять ИИН или телефон в свободный текст без строгого шаблона.
Какие ошибки чаще всего ломают защиту?
Чаще всего команды ставят очистку слишком поздно, чистят только обычный текст и хранят карту замен рядом с запросом. Еще одна частая ошибка — подставлять исходные данные обратно простой заменой по строке, без проверки места и типа поля. В итоге утечка происходит не в модели, а в служебных слоях.
Если у нас уже есть LLM-шлюз, маскирование все равно нужно?
Нет, шлюз не отменяет очистку на вашей стороне. Он помогает централизовать маршрут, логи и правила доступа, но именно вы решаете, какие поля модель вообще должна видеть. Безопасный порядок один: сначала обезличивание, потом отправка запроса дальше, даже если вы работаете через единый слой вроде AI Router.