Квантизация модели: проверки перед переходом на 8-bit и 4-bit
Квантизация модели требует проверки качества на вашем наборе: выберите метрики, найдите сбои и сравните FP16, 8-bit и 4-bit до релиза.
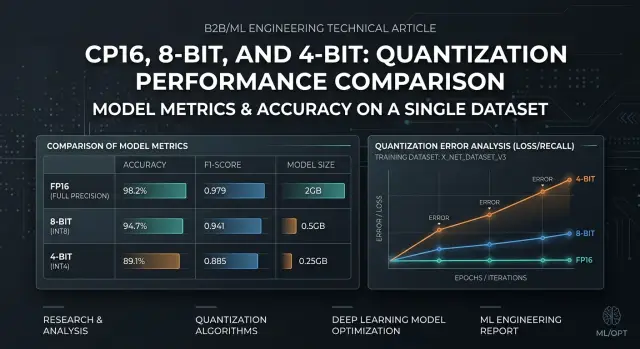
В чем риск при переходе с FP16
Переход с FP16 на меньшую точность редко ломает модель равномерно. Средняя оценка может почти не измениться: задержка ниже, памяти нужно меньше, ответы выглядят похоже. Но часть запросов начинает сбоить заметно чаще, и именно они потом превращаются в жалобы в продакшене.
8-bit обычно держится близко к FP16 на простых задачах: короткие ответы, извлечение фактов, классификация, шаблонные суммаризации. С 4-bit разница видна быстрее. Модель может спокойно пройти бытовые примеры, а потом потерять смысл на длинной инструкции, многошаговой логике, смешении языков, редких терминах или строгом формате ответа. Средний балл это легко прячет.
Пользователь и команда видят разные симптомы. Пользователь замечает сломанный смысл: модель пропустила отрицание, перепутала сумму, отдала неверный класс, потеряла условие в договоре. Команда чаще сначала видит другое: выросла длина ответа, стало больше отказов, поплыл JSON, снизилась повторяемость на одинаковых прогонах. И то и другое опасно, просто бьет по-разному.
Чаще всего просадка проявляется в узких местах:
- длинный контекст с несколькими ограничениями в одном промпте
- таблицы, числа, артикулы, коды, даты
- ответы в строгом JSON или по заданной схеме
- редкие доменные слова и смешение русского, казахского и английского
- задачи, где ошибка выглядит правдоподобно
Последний пункт особенно неприятен. Если модель пишет гладко, но меняет один факт, автоматическая проверка может почти ничего не заметить. Для банка, клиники или службы поддержки одна такая подмена уже создает реальный риск.
Чужие бенчмарки в такой ситуации помогают только как грубый фильтр. У вас другой набор запросов, другой стиль промптов, другие пороги ошибки и другая цена сбоя. Модель, которая хорошо держится на публичных тестах, может просесть именно на ваших документах, коротких командах операторов или диалогах с пропущенным контекстом.
Риск квантизации модели не в самом факте перехода на 8-bit или 4-bit. Риск в том, что поломки сначала выглядят мелкими, а потом всплывают в самых дорогих сценариях.
Как собрать свой набор для проверки
Хороший тестовый набор для модели должен быть похож на обычный трафик, а не на подборку красивых демо-запросов. Если выборка слишком "чистая", переход с FP16 на 8-bit или 4-bit покажется безопасным, а просадка вылезет уже после релиза.
Берите реальные запросы из продакшена, пилота или внутреннего тестового контура. Если команда уже прогоняет модели через единый шлюз, например AI Router, удобно выгрузить обезличенные запросы за несколько недель и собрать живую выборку без смены интеграции. Сразу уберите персональные данные, служебный мусор и технические повторы, которые не меняют смысл.
Не делите выборку случайно, строка за строкой. Лучше разложить ее по сценариям: суммаризация, извлечение полей, классификация, генерация ответа по базе знаний, разбор длинного диалога. Тогда видно, где модель теряет качество по-настоящему, а где разница между FP16 и 8-bit почти незаметна.
Внутри каждого сценария держите примеры разной сложности. Нужны короткие запросы в 1-2 фразы, длинные входы с большим контекстом, пограничные случаи с опечатками и шумом, а еще задачи со строгим форматом ответа. Именно на таких контрастах чаще всего ломается 4-bit качество модели. Короткие запросы она может пройти без проблем, а на длинном документе начнет пропускать поля, путать шаги или хуже держать инструкцию.
Отдельно пометьте примеры, где ошибка стоит дорого. Для банка это может быть неверная категория обращения или пропущенная сумма. Для ритейла - спутанный артикул. Для healthcare - потерянный симптом или неверный фрагмент в сводке. Такие запросы не должны теряться среди сотни безопасных примеров, где промах почти ничего не меняет.
В конце уберите дубликаты и почти одинаковые запросы. Если в наборе двадцать похожих обращений, проверка качества LLM даст ложное чувство стабильности. Лучше меньше, но шире по смыслу. Небольшой набор из разных сценариев обычно полезнее, чем большая таблица с повторяющимися строками.
Какие метрики смотреть
Оценка по одной цифре почти всегда обманывает. При переходе на 8-bit или 4-bit модель может отвечать почти так же по смыслу, но чаще ломать JSON, путать числа или добавлять лишний текст. Для рабочего сценария обычно достаточно 2-4 метрик, а не длинной таблицы ради отчета.
Для большинства команд хватает такого набора:
- точность по задаче: правильный класс, верный факт, совпадение с эталоном
- прохождение формата: валидный JSON, нужные поля, порядок, длина ответа
- доля критических ошибок: сбой, после которого ответ нельзя использовать
- задержка и расход токенов: среднее значение и 95-й перцентиль рядом с качеством
Точность считайте в форме, которая ближе к продукту. Для классификации это доля верных ответов. Для извлечения полей - совпадение по каждому полю. Для генерации текста часто полезнее ручная проверка по простому чек-листу на 50-100 примерах, чем абстрактный общий балл. Квантизация модели часто бьет не по всем ответам, а по узким случаям: длинный контекст, таблицы, числа, смешение языков.
Формат ответа проверяйте отдельно. Это частая ловушка. Модель может понимать задачу, но если вместо чистого JSON она добавляет пояснение перед первой скобкой, ваш пайплайн уже ломается. Для таких задач лучше заранее задать порог. Например: валидный JSON не ниже 99%, все обязательные поля не ниже 98%, пустые поля не выше 1%. Ниже этого порога вариант не проходит, даже если общая точность почти не просела.
Критические ошибки считайте в отдельной колонке, без усреднения с обычными промахами. Неверная сумма платежа, перепутанный клиент, пропуск запрета, выдуманная ссылка на документ - это не "минус один балл", а отдельный тип сбоя. Один такой ответ может стоить дороже, чем десять мягких ошибок в стиле.
Скорость и токены смотрите рядом с качеством, а не после него. 4-bit вариант может отвечать быстрее, но чаще ошибаться по формату. Тогда система делает повторный запрос, и итоговая задержка растет. Иногда модель пишет на 15-20% длиннее, и часть экономии на инференсе исчезает.
Как проверять
Если вы меняете только точность, меняйте только точность. Любое другое отличие смазывает результат: другой промпт, другой temperature, и уже непонятно, виновата ли квантизация модели.
- Соберите один фиксированный прогон. Заморозьте system prompt, шаблон пользовательского запроса, few-shot примеры, max_tokens, temperature, top_p, stop-последовательности и обработку ответа после модели. Если стек поддерживает seed, задайте и его. Порядок запросов тоже не меняйте.
- Запустите FP16 и сохраните этот прогон как базу. Не редактируйте ответы вручную, даже если они выглядят "почти правильными". База нужна для честного сравнения.
- На том же наборе прогоните 8-bit, потом 4-bit. Не меняйте модель, провайдера, роутинг и длину контекста между тестами.
- Сохраните сырые ответы целиком. Оставьте и текст, и служебные поля, если они есть: число токенов, stop reason, ошибки, таймауты. Позже именно сырой вывод покажет, где модель начала обрывать ответ, путать числа или уходить в лишние объяснения.
- Разберите расхождения по типам задач, а не по одной общей цифре. Отдельно смотрите извлечение полей, классификацию, суммаризацию, длинный контекст, код и русский или казахский текст, если он есть в продакшене.
После этого ручная проверка обычно дает больше пользы, чем средний балл по всему набору. Если 8-bit почти не меняет ответы, а 4-bit портит только длинные объяснения, решение уже видно. Общая просадка на 2% этого не покажет.
Простой пример: у команды есть 120 тестов. Из них 40 на извлечение реквизитов, 40 на краткий ответ пользователю и 40 на разбор длинного документа. FP16 и 8-bit дают почти одинаковый результат на первых двух группах, но 4-bit начинает пропускать суммы и даты в длинных текстах. В такой ситуации нет смысла спорить о среднем балле. Логичнее оставить 8-bit для общего потока, а 4-bit не пускать в задачи с длинным контекстом.
Хорошая проверка выглядит скучно. Это нормальный признак. Чем меньше случайных отличий в прогоне, тем легче потом объяснить решение команде и тем дешевле обходится ошибка выбора.
Где квантизация бьет сильнее всего
Сильнее всего квантизация модели бьет по задачам, где ответ должен быть не просто похожим, а точным. Чем меньше у модели права на вольность, тем быстрее видна разница между FP16, 8-bit и 4-bit. На обычных диалогах падение может выглядеть умеренным. На рабочих сценариях оно часто всплывает сразу.
Один частый пример - классификация обращений контакт-центра. На похожих темах модель начинает чаще путать классы, особенно если текст короткий, эмоциональный или написан с ошибками. В извлечении полей из договоров и анкет страдают точные значения: номер документа, дата начала и окончания, формат поля. В ответах по базе знаний с жестким форматом сбои видны еще быстрее: вместо JSON модель добавляет пояснение, меняет названия полей или вставляет лишний текст.
Даже короткие суммаризации для операторов не всегда безопасны. Текст остается читабельным, но модель может выбросить деталь, которая меняет смысл. Например, клиент не просто ждет доставку, а уже просит отмену и возврат. В черновиках писем и служебных заметок качество тоже проседает по-своему: формулировки становятся более общими, а обязательные факты начинают теряться.
В банке, телекоме или госсекторе такие ошибки быстро становятся дорогими. Если модель пропустила ИИН, перепутала сумму или выдала лишнюю строку в шаблоне, оператор тратит лишние минуты на ручную правку. На потоке это накапливается очень быстро.
Есть и менее очевидная зона риска. Квантизация сильнее бьет по задачам с длинным контекстом, смешанными языками и редкими терминами. Если в одном запросе есть русский, казахский и фрагмент договора, 4-bit чаще теряет точность, чем на коротком бытовом вопросе.
Если у вас есть хотя бы один такой сценарий, не смотрите только на среднюю оценку по всем тестам. Сравнивайте FP16, 8-bit и 4-bit отдельно по каждому рабочему кейсу. Именно там обычно и прячется неприятный сюрприз.
Какие сбои искать в ответах
После перехода на 8-bit или 4-bit модель часто выглядит "почти такой же". Это опасная иллюзия. На простых запросах разница может быть нулевой, а на рабочих сценариях всплывают сбои, которые средняя оценка легко прячет.
Первый частый сигнал - разрыв между короткими и длинными примерами. На одном абзаце модель держится нормально, а на длинной переписке, договоре или карточке товара начинает терять детали из начала контекста, смешивать факты и отвечать слишком уверенно. Если проверять только короткие тесты, такой провал почти не виден.
Отдельно смотрите на формат. Смысл ответа может оставаться приемлемым, но JSON ломается заметно чаще: пропадает закрывающая скобка, поля меняют тип, числа превращаются в строки, часть ключей исчезает. Для продакшена это обычно больнее, чем небольшая просадка по качеству текста. Приложение падает не потому, что ответ чуть хуже, а потому что парсер не может его прочитать.
Квантизация модели часто сильнее бьет по редким случаям, чем по среднему потоку. Если у вас есть классы, которые встречаются в 2-5% запросов, проверьте их отдельно. Средний балл может просесть совсем немного, а редкий класс - упасть так, что модель начнет путать похожие категории или тянуть ответ к самому частому варианту.
Еще одна слабая зона - точные сущности. Смотрите, как модель обращается с числами, датами, именами, кодами, артикулами и суммами. На FP16 она может верно вытаскивать "15.04.2024" и "12 450", а в 4-bit начать менять порядок цифр, округлять, терять нули или подставлять имя из соседней строки. Для отчетов, заявок и поддержки это уже не мелочь.
Системную инструкцию модель тоже держит хуже. Она чаще забывает ограничения на стиль ответа, язык, длину, запрет на домыслы или требование отвечать строго по документу. Это особенно заметно в многошаговых сценариях, где нужно и понять текст, и не выйти за рамки формата.
Быстрый фильтр перед решением выглядит так:
- сравните короткие и длинные примеры отдельно
- считайте поломки JSON отдельно от смысла
- выделите редкие классы в свой срез
- проверьте даты, суммы, имена и идентификаторы
- отметьте случаи, где модель нарушает системную инструкцию
Ошибки, которые портят выводы
Самый частый промах простой: команда берет удобный набор из 20-30 запросов, которые модель и так решает без труда. После этого FP16 и 8-bit выглядят почти одинаково, а 4-bit кажется "почти без потерь". Потом модель выходит в продакшен, получает длинный диалог, таблицу в тексте или цепочку правил и начинает срезать углы.
Такой тест обманывает не потому, что метрики плохие. Он обманывает потому, что набор слишком чистый. Если в нем нет спорных случаев, редких формулировок, длинных входов и задач на точность, вы меряете не реальную нагрузку, а демо-версию своей системы.
Еще одна ошибка - сравнивать варианты при разных параметрах генерации. Один запуск делают с temperature 0, другой с 0.7, где-то меняют top_p, а где-то max_tokens. После этого люди спорят о квантизации, хотя на деле они сравнили два разных режима генерации. Параметры, промпт, шаблон ответа и stop-последовательности должны совпадать до мелочей.
Длинный контекст проверяют реже, чем нужно. А именно там 4-bit часто ведет себя хуже всего. Модель может нормально отвечать на короткий вопрос, но терять часть инструкции на 8-10 тысячах токенов, путать ограничения из начала диалога или забывать формат вывода.
Хороший тест почти всегда включает:
- короткий простой запрос
- длинный документ с точным извлечением
- многослойную инструкцию с правилами и исключениями
- многоходовый диалог, где важна память
- задачу, где ошибка стоит дорого
Есть и более приземленная ошибка: команда идет в 4-bit только ради цены. Экономия понятна, особенно если запросов много. Но без заранее заданного порога качества это решение быстро превращается в спор на вкус. Лучше до теста зафиксировать правило: например, 4-bit подходит только если не ломает ответы на критичных сценариях и не дает роста ручных проверок.
Короткий чек-лист перед решением
Решение о переходе на 8-bit или 4-bit лучше принимать после короткой, но жесткой проверки. Квантизация модели часто дает нормальный средний результат, а потом ломается на редких и дорогих ошибках. Поэтому смотрите не только на общий балл, но и на случаи, где промах реально бьет по работе.
- Прогоните 100-200 своих примеров. Этого обычно хватает, чтобы увидеть общий тренд.
- Соберите отдельный набор для дорогих ошибок. Для банка это может быть неверная сумма или перепутанный лимит, для поддержки - опасный совет, для поиска по базе - пропуск нужного документа.
- Сравнивайте FP16, 8-bit и 4-bit при одинаковых условиях: один и тот же промпт, temperature, top_p, system message, длина контекста и правила постобработки.
- Отложите спорные ответы в отдельную выборку и просмотрите их вручную. Автоматическая метрика не всегда ловит момент, когда модель стала чаще терять числа, уходить в туманную формулировку или додумывать детали.
- Заранее задайте порог для решения. Например, 8-bit можно брать, если просадка укладывается в 1-2% и не растет число опасных ошибок, а 4-bit - только если он проходит тот же тест на рискованном наборе.
Опираться на впечатление опасно. На обычных примерах 4-bit может выглядеть почти так же, как FP16, но на двух десятках сложных запросов внезапно дать несколько лишних ошибок. Этого уже хватает, чтобы откатить идею или оставить 4-bit только для части сценариев.
Ручная проверка нужна даже тогда, когда цифры выглядят спокойно. Если команда за полчаса просмотрела спорные ответы и договорилась, где ошибка допустима, а где нет, решение получается намного чище.
Что делать после проверки
Если тесты показали разницу не везде, не переводите все сразу. После проверки квантизация модели должна идти по сценариям, а не одной кнопкой на весь стек. Сначала разделите задачи по цене ошибки.
Там, где модель отвечает клиенту, извлекает данные из договора, заполняет поля для следующего шага или пишет текст без ручной проверки, лучше оставить FP16. В таких местах даже редкая ошибка бьет больно. Один пропуск суммы, даты или части отрицания быстро съедает всю выгоду от экономии памяти и стоимости.
8-bit обычно становится первым кандидатом на переход. Если на вашем наборе качество держится ровно, туда можно перевести устойчивые задачи: краткие сводки, черновики писем, простую классификацию, поиск похожих фрагментов. Начните с части трафика, посмотрите на реальные ответы несколько дней и только потом расширяйте долю запросов.
С 4-bit лучше не спешить. Прогоните его отдельно на рисковых кейсах, где просадка видна раньше всего: длинный контекст, числа, таблицы, строгий JSON, смешанные языки, редкие термины. Если именно там начинаются пропуски, выдуманные детали или ломается формат, не пытайтесь закрыть это общим промптом. Проще оставить такие маршруты на FP16 или 8-bit.
Базовое правило выглядит так:
- FP16 - для чувствительных сценариев
- 8-bit - для задач с устойчивым качеством
- 4-bit - только после отдельной проверки на сложных примерах
Не убирайте тестовый набор после первого решения. Любая замена модели, системного промпта, провайдера или шаблона ответа может дать новый результат. Один и тот же запрос у двух провайдеров нередко ведет себя по-разному, даже если модель называется похоже. Поэтому повторяйте прогон после каждого заметного изменения.
Если вы сравниваете несколько моделей и форматов сразу, удобно держать один и тот же код и менять только маршрут вызова. В этом плане AI Router полезен как единый OpenAI-совместимый шлюз: можно прогнать один набор через разные модели и провайдеров, не переписывая SDK, код и промпты. Это упрощает честное сравнение и помогает быстрее увидеть, где 8-bit уже достаточно, а где 4-bit пока рано пускать в продакшен.
Часто задаваемые вопросы
Можно ли смотреть только на среднюю оценку модели?
Нет. Средний балл часто прячет редкие, но дорогие сбои. Смотрите результаты по сценариям отдельно: длинный контекст, извлечение полей, классификация, строгий JSON, смешанные языки и редкие термины.
8-bit уже безопасен, а 4-bit нет?
Обычно 8-bit держится близко к FP16 на простых задачах и дает выигрыш по памяти. 4-bit требует более жесткой проверки, потому что чаще сыпется на длинных инструкциях, числах, таблицах и строгом формате ответа.
Какие запросы лучше брать в тестовый набор?
Берите реальные обезличенные запросы из обычного трафика, а не красивые демо-примеры. Добавьте короткие и длинные входы, шумные формулировки, дорогие ошибки и задачи, где ответ должен точно совпадать по схеме.
Сколько примеров нужно для проверки?
Для первого решения часто хватает 100–200 примеров, если они покрывают разные сценарии. Отдельно соберите небольшой набор случаев, где ошибка стоит дорого, иначе они потеряются на фоне простых запросов.
Какие метрики смотреть в первую очередь?
На практике хватит четырех вещей: точности по задаче, прохождения формата, доли критических ошибок и задержки вместе с расходом токенов. Если модель пишет чуть быстрее, но чаще ломает JSON или делает повторные запросы, выгода быстро исчезает.
Нужно ли проверять JSON отдельно от качества ответа?
Да, и отдельно от смысла. Модель может понять задачу, но добавить лишний текст перед первой скобкой, сменить тип поля или пропустить обязательный атрибут. Для пайплайна это уже поломка, даже если сам ответ выглядит разумно.
Почему длинный контекст и числа ломаются первыми?
Потому что там модель должна держать больше ограничений сразу. На длинном входе она чаще теряет детали из начала контекста, а при работе с числами и датами начинает путать порядок, округлять или пропускать часть значения.
Как честно сравнить FP16, 8-bit и 4-bit?
Зафиксируйте все условия и меняйте только точность. Оставьте один и тот же prompt, temperature, top_p, max_tokens, порядок запросов, длину контекста и постобработку, а потом сохраните сырые ответы и сравните их по одинаковым правилам.
Когда можно пускать квантизированную модель в рабочий трафик?
Сразу переводить весь трафик не стоит. Сначала задайте порог по качеству, затем пустите вариант на часть запросов и посмотрите на реальные ответы несколько дней. Для 4-bit такой этап особенно нужен, даже если офлайн-тест выглядел спокойно.
Что делать после проверки и первого релиза?
Не выбрасывайте тестовый набор после первого решения. Любая смена модели, провайдера, системного промпта или шаблона ответа может дать другой результат, поэтому прогон лучше повторять после каждого заметного изменения.