Фолбэк JSON-схемы: как менять модели и не ломать tool-режим
Фолбэк JSON-схемы нужен, когда запасная модель меняет поля, типы или формат ответа. Разберем выбор резервных моделей, валидаторов и проверок.
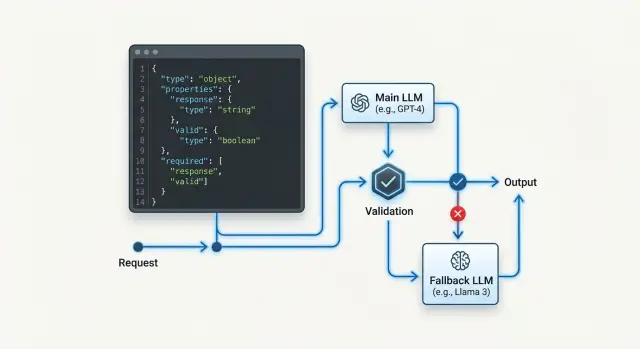
Где ломается схема при фолбэке
Сбой обычно виден не в самом ответе, а в одном поле, которое исчезло или поменяло тип. Пока основная модель отвечает стабильно, tool-режим кажется надежным. Проблемы начинаются, когда маршрутизация переводит запрос на резерв, а тот трактует тот же контракт чуть иначе.
Самый частый случай - пропуск обязательного поля. Первая модель возвращает customer_id, topic и priority, а резервная решает, что priority можно опустить, потому что он и так понятен из текста. Для человека это терпимо. Для кода - уже ошибка: инструмент ждет полный объект и не знает, что делать с неполным JSON.
Не реже ломается тип поля. Одна модель отдает номер заявки как строку "10452", другая как число 10452. На вид разницы почти нет. Но если дальше система сравнивает ID как строку, пишет его в CRM или передает в tool со строгой схемой, запрос падает на ровном месте. Это особенно неприятная ошибка: ответ выглядит почти правильным, а пайплайн все равно разваливается.
Есть и тихая проблема - лишние поля. Допустим, схема разрешает только name, phone и city, а запасная модель добавляет comment, confidence или provider_note. Одни парсеры это проглотят, другие отклонят весь объект. Хуже всего то, что лишние поля часто появляются не всегда, а только на части запросов. Поэтому команда долго ищет причину не там, где нужно.
Отдельная боль - текст вокруг JSON. Одна модель возвращает чистый объект, другая пишет что-то вроде:
{"name":"Алия","phone":"+77010000000"}
Иногда перед ним появляется Готово, вот результат:, иногда после - короткое пояснение. Парсер, который ждет только JSON, падает сразу.
Обычно ломаются четыре вещи:
- исчезает обязательное поле
- меняется тип поля
- появляются лишние поля
- вокруг JSON возникает обычный текст
Поэтому похожее качество текста еще ничего не значит. В tool-режиме важен не красивый ответ, а одна и та же структура на каждом шаге.
Что считать совместимым ответом
Совместимый ответ - это не просто похожий JSON. Это ответ, который ваш код принимает без ветвлений, ручных правок и догадок. Если после смены модели парсер, валидатор и вызов инструмента работают так же, ответ совместим.
При фолбэке смотрите не на стиль текста, а на контракт. Обычно он проще, чем кажется: какие поля обязательны, какой у них тип, какие значения считаются пустыми и какие дополнительные поля допустимы.
Если сказать совсем просто, совместимый ответ проходит три проверки: JSON парсится, схема совпадает, бизнес-смысл не теряется. Все остальное - косметика.
Минимальный контракт
Сначала зафиксируйте поля, без которых следующий шаг не работает. Если инструмент ждет customer_id как строку и amount как число, то "123" и 123 - это уже не одно и то же. Такие вещи нельзя оставлять на усмотрение модели.
Отдельно опишите пустые значения. null, пустая строка, пустой массив и отсутствие поля означают разное. Например, email: null может значить "почты нет", а отсутствие email - что модель вообще не заполнила поле и ответ надо считать ошибкой.
С дополнительными полями тоже лучше определиться заранее. Если одна модель присылает confidence и comment, а другая нет, это не проблема, пока код умеет их игнорировать. Проблема начинается там, где лишнее поле неожиданно меняет логику.
Минимальный контракт должен отвечать на четыре вопроса:
- какие поля обязательны всегда
- какой тип у каждого поля
- какие пустые значения допустимы
- какие дополнительные поля не ломают обработку
Еще один частый источник сбоев - формат значений. Дату лучше держать в одном виде, например YYYY-MM-DD. Деньги лучше передавать либо в минорных единицах, либо как число с четким правилом округления. Идентификаторы не смешивайте: если request_id у вас строка, не позволяйте модели иногда отдавать число, а иногда UUID.
Если вы меняете модели через один шлюз, приложение вообще не должно замечать смену провайдера. У ответов может отличаться стиль, но не структура.
Как выбрать основную и резервную модель
Основную модель для tool-режима выбирают не по тому, насколько умно она пишет текст. Смотрите на другое: как часто она отдает JSON, который проходит вашу схему с первого раза. Если модель дешевле, но ломает типы, пропускает обязательные поля или добавляет лишний текст вокруг объекта, такая экономия быстро исчезает.
У всех кандидатов должен быть один и тот же набор проверок. В него стоит включить простые вызовы, длинные схемы, поля с enum, вложенные объекты, пустые значения и запросы с шумом в формулировке. Один промпт, один tool contract, один валидатор. Иначе вы сравниваете не модели, а случайность.
Для каждой модели полезно измерить пять вещей: долю ответов, которые проходят JSON Schema без исправлений, долю корректных вызовов инструмента на длинных схемах, среднюю задержку и разброс по времени, поведение на таймаутах и обрезанном выводе, а уже потом цену успешного ответа.
Длинные схемы ломают даже сильные модели. Одна спокойно держит 8 полей, но путается на 20 и начинает портить вложенные массивы. Другая хорошо заполняет обязательные поля, но срывается на enum и возвращает близкое по смыслу значение вместо допустимого. Это видно только на реальных tool-вызовах.
Я бы не ставил в primary модель, которая дает меньше 95% валидных ответов на вашем наборе, если инструмент запускает действие в системе. Для справочных сценариев порог может быть ниже. Для заявок, платежей, статусов заказа или KYC лучше быть строже.
Резервов обычно хватает 2-3. Не берите три почти одинаковые модели от похожих провайдеров. Лучше собрать набор с разным поведением: один резерв ближе к основной по точности, второй быстрее и дешевле, третий подходит для сценариев, где важны data residency и стабильная схема.
Если вы гоняете тесты через OpenAI-совместимый шлюз, отбор идет быстрее, потому что не нужно менять SDK, код и промпты для каждого провайдера. У AI Router это как раз так: достаточно переключить base_url на api.airouter.kz и прогнать один и тот же пакет проверок по нескольким моделям. Но критерий остается прежним - побеждает не та модель, что красиво отвечает в демо, а та, что неделями держит ваш контракт без сюрпризов.
Как задать контракт для tool-режима
Если модель должна вызвать функцию, одного понятного промпта мало. Нужен жесткий контракт, который переживет смену провайдера. При фолбэке слабое место обычно не в самой модели, а в расплывчатых полях, похожих enum и лишних параметрах.
Каждой функции дайте одно назначение и короткое описание. Не нужен абзац про бизнес-логику. Достаточно двух вещей: когда вызывать функцию и что она должна вернуть. Если функция создает заявку, так и пишите: создает заявку в CRM и возвращает ticket_id.
С enum лучше быть строгим. Список из 3-5 значений обычно работает лучше, чем длинный набор похожих вариантов. Если в коде потом все равно остаются только new, pending и closed, не добавляйте waiting, in_progress и on_hold. Похожие значения путают даже сильные модели.
Уберите необязательные поля, без которых код и так работает. Каждое лишнее поле дает новый шанс получить null, пустую строку или текст вроде "не указано". Если система ищет клиента по customer_id, не просите у модели еще и имя, регион и комментарий просто на всякий случай.
Отдельно запретите свободный текст там, где вы ждете код, ID или дату. Поле order_id должно принимать order_78421, а не "заказ клиента на прошлой неделе". Поле delivery_date должно быть датой в одном формате, а не "завтра после обеда".
На практике обычно помогают простые ограничения:
- для идентификаторов задавайте
pattern,minLengthиmaxLength - для дат и статусов оставляйте один формат и один список значений
- для чисел задавайте границы, если они известны
- для строк запрещайте лишний текст, если нужен код
Версионируйте схему с первого дня. Добавьте schema_version в каждый вызов функции и меняйте версию при любом несовместимом изменении. Тогда при смене модели сразу видно, какая связка из модели и схемы дала сбой.
Сухой контракт выглядит не очень красиво, и это нормально. Чем меньше в нем свободы, тем проще держать tool-режим стабильным.
Как настроить фолбэк по шагам
Фолбэк лучше настраивать как цепочку проверок, а не как простое переключение на любую доступную модель. Если запасная модель отвечает быстро, но меняет структуру полей или формат аргументов, tool-режим ломается так же, как при полном сбое.
Сначала соберите небольшой эталонный набор запросов. В него обычно входят короткие, длинные, двусмысленные и редкие случаи. На этом наборе прогоняют базовую модель и смотрят не только на смысл ответа, но и на форму: обязательные поля, типы, enum, вложенные объекты, пустые значения.
Потом подключают первый резерв и гонят тот же набор без изменений. Сравнивать нужно по одному контракту. Если основная модель возвращает customer_id как строку, а резерв иногда отдает число или null, это уже несовместимый ответ, даже если текст выглядит правдоподобно.
Рабочий порядок обычно такой:
- Проверьте базовую модель на эталонных кейсах и зафиксируйте процент валидных ответов.
- Добавьте одну резервную модель и сравните не стиль текста, а прохождение схемы и вызов инструментов.
- Включайте retry только после тайм-аута, сетевой ошибки или явного провала валидации.
- Подключайте следующий резерв по одному, чтобы видеть, какая модель внесла поломку.
- Логируйте причину каждого перехода: тайм-аут, 5xx, невалидный JSON, нарушение схемы, пустые аргументы инструмента.
Retry до валидации часто только мешает. Модель могла вернуть ответ, который похож на JSON, но не проходит проверку. Если сразу отправить тот же запрос в следующую модель и не записать причину, команда потом не поймет, где именно сломался вызов инструментов.
Есть полезное разделение ролей. Маршрутизатор решает, когда переключать модель. Валидатор решает, можно ли пускать результат дальше в код. Эти роли лучше не смешивать.
Например, в сценарии с заявкой клиента базовая модель извлекает intent, priority и department. Если она не уложилась в тайм-аут, система идет к резерву. Если резерв вернул JSON, но забыл department, запрос не должен уходить в CRM. Сначала запись в лог, потом еще одна попытка по правилу, а не по догадке.
Какие валидаторы поставить
При смене модели tool-режим чаще всего ломают не большие ошибки, а мелкие. Одна модель возвращает чистый JSON, другая добавляет фразу перед объектом, третья пишет число строкой. Если сразу передавать такой ответ в бизнес-логику, сбой уходит далеко по цепочке и разбирать его потом неприятно.
Надежнее поставить несколько слоев проверки. Тогда фолбэк не превращается в лотерею, а резервные модели можно менять без ручной чистки каждого ответа.
Минимальный набор проверок
Сначала парсер проверяет чистый синтаксис JSON. Если ответ не парсится, дальше идти некуда. Затем валидатор сверяет схему: типы, обязательные поля, допустимые значения enum. После этого нормализатор приводит спорные поля к одному виду. Даты хранятся в одном формате, числа становятся числами, а пустые строки вроде "" или "N/A" превращаются в null, если контракт это допускает.
Отдельный фильтр должен отбрасывать ответы, где модель написала текст до или после JSON. Для вызова инструментов это не мелочь, а брак. И наконец, логгер сохраняет сырой ответ модели рядом с текстом ошибки и именем провайдера. Без этого вы не поймете, кто именно сломал контракт.
Такой порядок лучше одной общей проверки "все ли нормально". Он сразу показывает место сбоя. Если модель вернула "amount": "15000", парсер пройдет, схема может упасть, а нормализатор в некоторых сценариях аккуратно исправит ответ. Если же перед JSON стоит "Готово, вот результат:", ответ лучше отклонить сразу, а не пытаться угадывать, что имела в виду модель.
Есть простое правило: не смешивайте исправление формата и бизнес-правила. Сначала приведите ответ к контракту, и только потом решайте, можно ли создавать заявку, отправлять событие в CRM или вызывать следующий инструмент. Иначе одна и та же ошибка будет всплывать в разных местах.
Даже если вы маршрутизируете запросы через единый API-шлюз, валидаторы все равно нужны. Шлюз упрощает замену провайдера, но не отменяет различия в том, как модели соблюдают схему.
Пример с заявкой клиента
Бот банка принимает заявку на перевыпуск карты. После короткого диалога он должен отдать в backend только четыре поля: reason, city, contact_time, consent. Для такого сценария tool-режим живет только пока ответ строго совпадает со схемой.
Схема простая: reason, city, contact_time - строки, consent - boolean. В обычном режиме основная модель отвечает так:
{
"reason": "карта повреждена",
"city": "Алматы",
"contact_time": "после 18:00",
"consent": true
}
Backend сразу создает заявку. Никаких догадок не нужно.
Проблема начинается в день, когда у основного провайдера тайм-аут. Маршрутизатор получает явную ошибку и только после нее включает резервную модель. Так и должен работать фолбэк: система не перескакивает между моделями без причины, иначе вы ловите случайные отличия формата даже на здоровом трафике.
Резервная модель может понять смысл верно, но все равно сломать контракт:
{
"reason": "карта повреждена",
"city": "Алматы",
"contact_time": "после 18:00",
"consent": "Да"
}
Для человека ответ выглядит нормально. Для схемы - нет. Поле consent должно быть boolean, а строка "Да" нарушает тип.
Валидатору тут нужна простая дисциплина:
- Он принимает мелкий ремонт, если смысл не меняется. Например, убирает лишний текст вокруг JSON или приводит
"true"кtrue. - Он не гадает, если значение двусмысленное или бизнес-логика строгая.
- Если он видит ошибку типа, он просит ту же модель повторить ответ по той же схеме один раз.
- Если повтор снова не проходит, он помечает вызов как
schema_errorи передает управление маршрутизатору.
"Да" можно исправить только в одном случае: продукт уже знает из trusted source, что пользователь дал согласие, а модель лишь пересказала этот факт словами. Если такого источника нет, лучше запросить повтор. Иначе бот сам дорисует согласие там, где его никто не давал.
Именно на таких мелочах и падает вся цепочка. Один неверный тип выглядит безобидно, но после смены модели ломает весь вызов инструмента.
Где команды ошибаются
Чаще всего проблема не в самом фолбэке, а в том, как его включают. Команда видит более дешевую модель, ставит ее в резерв и считает, что задача решена. Потом tool-режим начинает отдавать ответы, которые выглядят нормально глазами, но не проходят схему.
Первая ошибка простая: смотрят на цену за токены и почти не смотрят на долю валидных ответов. Для JSON это плохой ориентир. Если резервная модель дешевле на 20%, но в 8% случаев ломает структуру, итоговая цена системы часто становится выше из-за повторов, попыток починки и ручных разборов.
Вторая ошибка появляется при смене провайдера. Команды думают, что если API похож на OpenAI, то и вызов инструментов поведет себя так же. На деле различия бывают в мелочах: где модель кладет аргументы, как сериализует числа, что делает с пустыми полями, возвращает ли текст вместе с tool call. Именно эти мелочи и ломают парсер.
Третья ошибка сидит в самой схеме. Описания полей делают слишком общими: comment, result, status. Модель видит расплывчатое поле и начинает додумывать формат. Один провайдер вернет короткую строку, другой - объект, третий - массив из одного элемента.
Еще один частый промах - лишняя свобода в схеме. Если оставить дополнительные поля разрешенными, сначала это кажется удобным. На практике парсер теряет жесткие границы: сегодня модель добавит harmless_note, завтра provider_meta, а послезавтра вложенный объект, которого ваш код не ждет. Для tool-режима строгий контракт почти всегда лучше.
Часто путают и три разных механики:
- Retry нужен, когда та же модель с тем же контрактом может ответить нормально со второй попытки.
- Repair нужен, когда ответ почти подходит и его можно безопасно довести до схемы.
- Фолбэк нужен, когда текущая модель или провайдер в целом плохо держат этот сценарий.
Если смешать все в одну ветку, система становится шумной и непредсказуемой. Вы уже не понимаете, что именно помогло: повтор, правка JSON или переход на другую модель.
Нормальная проверка выглядит скучно, но работает. Для основной и резервной модели отдельно меряют долю валидного JSON, долю корректных tool call, число лишних полей, среднюю задержку и цену успешного ответа. Если резерв проходит тесты по тексту, но срывается на схеме, это не резерв. Это просто другая модель с другим поведением.
Быстрый чек перед запуском
Перед релизом проверьте не только то, что модель умеет звать tool, но и то, что она делает это одинаково в каждом запасном маршруте. Один удачный ответ в песочнице ничего не доказывает. Нужна повторяемость.
Для каждого инструмента держите эталонный JSON-ответ. Это не просто пример из документации, а образец, который проходит вашу схему, содержит все обязательные поля и задает формат для спорных мест: даты, null, enum, массивы, вложенные объекты. Если у инструмента есть три типовых сценария, лучше хранить три эталона.
Потом прогоните через те же тесты каждую резервную модель. Не меняйте промпт под каждую из них, иначе вы тестируете не совместимость, а набор ручных костылей. Если основная модель вернула корректный вызов 20 раз подряд, резервная должна пройти тот же прогон с теми же сообщениями, той же схемой и теми же настройками температуры.
Отдельно проверьте валидатор. Он должен писать причину отказа так, чтобы инженер понял ее по логу за 10 секунд. Не invalid output, а что именно сломалось: поле customer_id отсутствует, status не входит в enum, items[2].price ожидается number, получена string.
Полезно заранее разделить два действия: когда система просит модель повторить ответ и когда сразу уходит на фолбэк. Повтор нужен, если ошибка мелкая и модель, скорее всего, исправится со второй попытки. Переключение на резерв лучше делать, если ответ развалил структуру целиком, смешал текст с JSON или два раза подряд нарушил одну и ту же схему.
Перед запуском обычно хватает такого списка:
- у каждого инструмента есть эталонный JSON и версия схемы
- основная и резервные модели прошли одинаковый набор тестов
- валидатор возвращает точную причину отказа
- правила retry и switch описаны явно, а не по ощущению
- логи сохраняют модель, провайдера, имя инструмента и версию схемы
Последний пункт часто забывают. Если в логах нет версии схемы и имени модели, вы не поймете, что именно сломалось после смены провайдера.
Что делать дальше
После первого рабочего набора не оставляйте фолбэк без присмотра. Резервная цепочка стареет быстро: вы меняете промпт, добавляете поле в схему, провайдер обновляет модель, и вчерашний резерв уже пишет другой JSON. Такой сбой обычно всплывает в самый неудобный момент.
Полезно держать короткую матрицу и обновлять ее вместе с кодом. В ней фиксируют весь контракт, а не только названия моделей: какой инструмент вызывается в каждом сценарии, какая JSON-схема считается допустимой, какая модель основная и какие резервы разрешены, какой валидатор проверяет ответ и что считается ошибкой.
Эта таблица быстро показывает слабые места. Если у одного инструмента три резерва, но только один стабильно проходит проверку enum, проблема не в фолбэке вообще, а в конкретной паре "модель плюс схема".
Дальше нужен регулярный прогон на свежих примерах. Берите недавние запросы, убирайте персональные данные и запускайте один и тот же набор через основную модель и все резервы. Смотрите не только на долю успешных ответов. Проверяйте, какой процент ответов проходит валидатор с первого раза, где модель пропускает обязательные поля, где меняет тип значения, а где выбирает не тот инструмент.
После любой заметной правки резервы стоит пересматривать заново. Причина может быть любой: новая модель, другой системный промпт, смена провайдера, даже небольшой сдвиг в правилах постобработки. Смена base_url сама по себе не делает модели взаимозаменяемыми.
Если часть трафика должна оставаться внутри Казахстана, удобнее проверять резервы через один совместимый слой, а не собирать разную логику по коду. В этом месте AI Router бывает полезен как единый шлюз: можно сохранить прежние SDK и промпты, держать аудит-логи и ограничения на уровне ключа в одном месте и при этом тестировать разные модели по одному контракту.
Рабочий ритм тут довольно простой: обновили схему, в ту же неделю прогнали свежий набор, посмотрели несколько худших кейсов и убрали слабые резервы. Это занимает меньше времени, чем разбирать один сломанный вызов инструмента утром понедельника.
Часто задаваемые вопросы
Что обычно ломается при фолбэке в tool-режиме?
Чаще всего ломается не смысл ответа, а форма. Резервная модель может убрать обязательное поле, поменять тип, добавить лишний атрибут или обернуть JSON обычным текстом, и на этом парсер или tool call падает.
Как понять, что резервная модель реально совместима?
Смотрите на то, проходит ли ответ один и тот же путь без костылей. Если JSON парсится, схема совпадает, а код вызывает инструмент без ручной правки, модель совместима.
Стоит ли разрешать лишние поля в схеме?
Лучше запретить их по умолчанию. Разрешайте дополнительные поля только там, где код точно умеет их игнорировать и они не меняют логику дальше по цепочке.
Что должно быть в минимальном JSON-контракте?
Зафиксируйте обязательные поля, тип каждого поля, допустимые пустые значения и формат спорных значений вроде дат, денег и ID. С первого дня добавьте schema_version, чтобы быстро видеть, какая связка модели и схемы дала сбой.
По каким критериям выбирать основную и резервную модель?
Берите не ту модель, которая красиво пишет, а ту, что чаще отдает валидный JSON на ваших кейсах. Потом сравните задержку, поведение на тайм-аутах и цену именно успешного ответа, а не просто цену токенов.
Когда делать retry, а когда сразу уходить на резерв?
Сначала дайте той же модели один шанс исправиться, если вы словили тайм-аут, сетевую ошибку или мелкий сбой схемы. Если ошибка повторяется или провайдер сам отвечает нестабильно, переключайте запрос на резерв и обязательно пишите причину в лог.
Какие валидаторы поставить перед вызовом инструмента?
Обычно хватает четырех слоев: парсер JSON, проверка схемы, аккуратная нормализация формата и фильтр, который отсекает текст до или после объекта. В логах храните сырой ответ, модель, провайдера и текст ошибки, иначе вы долго будете искать причину вслепую.
Можно ли автоматически поправлять ответ модели?
Чините только то, что не меняет смысл. Например, можно убрать мусор вокруг JSON или привести "true" к true, но нельзя наугад превращать "Да" в согласие пользователя, если у вас нет другого надежного источника.
Сколько резервных моделей держать в цепочке?
Обычно хватает двух или трех резервов. Ставьте модели с разным поведением, а не три почти одинаковых варианта, и прогоняйте их заново после каждой правки схемы, промпта или провайдера.
Как быстро проверить фолбэк перед запуском?
Перед релизом прогоните каждую модель на одном и том же наборе эталонных кейсов и сравните не текст, а прохождение схемы. Проверьте, что валидатор пишет точную причину отказа, а логи сохраняют имя инструмента, модель, провайдера и версию схемы.