Фичефлаги для AI-функций по арендаторам: схема запуска
Фичефлаги для AI-функций помогают включать новые модели по арендаторам без общего релиза: схема запуска, проверки, ошибки и пример.
Почему общий релиз мешает разным клиентам
В B2B AI клиенты почти никогда не готовы одновременно. Один уже прогнал тесты на новой модели, сверил качество ответов и хочет включить ее сегодня. Если держать его до общего релиза, команда теряет время, а бизнес - эффект от запуска.
Другой клиент живет в другом темпе. У него ИБ проверяет хранение данных, юристы смотрят договор, закупка согласует бюджет, а владелец процесса просит пилот только на части пользователей. Для банков, госсектора и healthcare это обычная ситуация. Им нельзя просто сказать: "модель уже доступна всем".
Общий релиз ставит всех в одну очередь. Самый быстрый клиент начинает ждать самого медленного. В итоге график определяет не тот, кто готов, а тот, у кого длиннее внутреннее согласование.
Проблемы от этого вполне приземленные. Готовый клиент ждет без причины. На клиента без согласования давит его же бизнес. Поддержка путается, кому уже можно новую модель, а кому еще нельзя. А если в новой модели всплывает сбой, он сразу бьет по всем арендаторам.
Последний риск часто недооценивают. Допустим, новая модель нормально ведет себя на коротких запросах, но у одного арендатора длинные диалоги, сложные промпты и высокий трафик. Он первым ловит рост задержки, странные ответы или скачок расходов. При общем релизе проблема не остается локальной. Она уходит в общий контур и затрагивает остальных, хотя никто не планировал такой тест.
Даже если у вас один OpenAI-совместимый эндпоинт, момент включения не должен быть одинаковым для всех. Единый API удобен для интеграции, но правила доступа должны отличаться по арендатору.
Фичефлаги решают эту задачу просто: кто готов, тот идет вперед. Кто еще согласует запуск, остается на текущем варианте без спешки и без чужого риска.
Что ставить на флаг
Фичефлаги работают нормально только тогда, когда команда с самого начала выбирает правильный уровень управления. Частая ошибка проста: заводят один флаг вроде new_model_enabled, а потом пытаются через него включать модель, менять промпт, ограничивать трафик и отделять тест от боевого режима.
Такой флаг быстро перестает что-либо объяснять. Один клиент уже согласовал новую модель, но не новый промпт. Другой готов к новому сценарию, но только со старыми лимитами. Один переключатель этого не выдерживает.
Обычно хватает трех уровней.
Первый - модель. Такой флаг нужен, когда вы даете арендатору доступ к конкретной модели или ее версии. Например, банк еще ждет внутреннее одобрение, а SaaS-клиент уже может идти на новый маршрут.
Второй - промпт. Он полезен, когда модель остается той же, но вы меняете системную инструкцию, формат ответа или правила вызова инструментов. Так можно выпускать правки точечно, без лишнего шума для всей цепочки.
Третий - сценарий целиком. Это уже не только model_id, а весь рабочий путь: маршрутизация, промпт, лимиты, инструменты и постобработка. Такой уровень удобен, когда вы запускаете новую функцию, а не просто меняете модель под капотом. Например, включаете для части арендаторов новый сценарий суммаризации звонков или черновик ответа оператору с другой логикой вызова tool.
На практике команды часто комбинируют эти уровни. Снаружи есть флаг сценария, а внутри него зафиксированы версия модели и версия промпта. Так проще понять, что именно вы включили и что нужно откатить.
Как собрать схему запуска по арендаторам
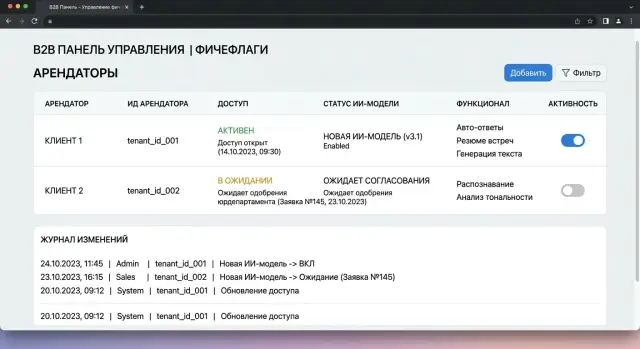
Схема по арендаторам начинается не с кода, а с короткого реестра. У каждого клиента в нем должны быть tenant ID, текущая модель, статус согласования, владелец решения и дата, когда можно включить новый сценарий. Самая частая ошибка - держать все это в переписке или в голове одного человека.
Лучше считать арендатором не "компанию по договору", а конкретный tenant_id, который система видит в запросе. Тогда правило проверяется автоматически, без ручных исключений. Иначе один и тот же клиент быстро расползается на тестовые кабинеты, дочерние команды и временные окружения.
Состояния лучше сделать простыми и понятными не только разработчикам:
- Выкл - новая модель или функция недоступна, запрос идет по старому сценарию.
- Пилот - доступ есть, но с ограничением по объему, времени или группе пользователей.
- Боевой доступ - новый сценарий включен для всего арендатора по обычным правилам.
Этих трех состояний обычно хватает. Если добавить пять или шесть, команда начнет спорить о названиях вместо запуска.
Правило стоит привязывать именно к tenant_id, а не к названию клиента в CRM. Удобный формат простой: tenant_id -> state -> model -> start_date -> owner. Например, tenant bank-17 остается на текущей модели, а tenant retail-04 получает пилот на новую. Если вы используете единый LLM-шлюз, проверку удобно делать до отправки запроса дальше по маршруту. В случае с AI Router приложение может по-прежнему работать через один OpenAI-совместимый эндпоинт, а решение о том, кого пускать на новую модель, принимать на своей стороне по tenant_id и флагу.
У каждого правила должен быть один владелец. Не комитет и не общий чат. Один человек отвечает за включение, паузу и откат. Рядом с владельцем ставят дату старта и дату пересмотра. Без этого пилот легко зависает на месяцы и превращается в странную полупродакшен схему.
Путь назад готовят в тот же день, когда создают правило. Для каждого арендатора заранее сохраните предыдущую модель, лимиты и условие, при котором система вернется к старому маршруту. Откат не должен требовать релиза. В идеале оператор меняет состояние с "пилот" на "выкл", и арендатор за минуту возвращается на прежний сценарий.
Рабочая схема держится на пяти вещах: точный список арендаторов, три ясных состояния, правило по tenant_id, назначенный владелец и заранее описанный откат. Остальное можно дорастить позже.
Где хранить правила и кто их меняет
Когда правила лежат в чатах, таблицах и личных заметках, команда быстро путается. Один менеджер помнит, что клиент уже согласовал новую модель, другой видит старый комментарий и блокирует запуск. Для фичефлагов нужен один реестр, где текущее состояние видно без догадок.
Такой реестр лучше держать рядом с рабочей конфигурацией, а не в переписке. Если у арендатора меняется доступ к AI-сценарию, запись должна обновиться в одном месте. Тогда разработка, поддержка и аккаунт-команда видят одно и то же.
Что хранить рядом с флагом
Один флаг без контекста мало помогает. Рядом с ним храните арендатора, сценарий, модель или версию модели, текущий статус, дату изменения, автора изменения и короткую причину. Полезно добавить и срок жизни флага. Временные решения любят жить месяцами, а потом никто не помнит, зачем они вообще остались.
Журнал изменений тоже нужен. Если банк получил доступ к новой модели после проверки безопасности, а другой клиент еще ждет внутреннее согласование, система должна прямо показывать, кто перевел статус и почему. Это снимает споры и сильно экономит время во время инцидента.
Право менять флаг и право выкатывать код лучше разделить. Статус арендатора часто меняют продакт, владелец клиента, compliance или security. Код выкатывает другая команда. Если один и тот же человек делает все сразу, ошибка в релизе может открыть модель не тем клиентам.
Сложная админка здесь редко нужна. Обычно хватает простой панели, где видно арендатора, сценарий, текущую и запасную модель, статус флага, дату окончания, согласующего и того, кто менял запись последним. Этого достаточно, чтобы быстро ответить на обычный вопрос: почему у клиента А уже новая модель, а у клиента Б еще старая.
Если трафик идет через единый шлюз, полезно держать этот статус рядом с маршрутами и журналом изменений. Тогда решение видно сразу, без поиска по чатам и тикетам. Если у флага нет владельца и срока, он почти наверняка останется в системе дольше, чем нужно.
Сценарий с двумя клиентами
У банка А и ритейлера Б один сервис для чат-оператора. Оба клиента отправляют запросы в один API и ждут похожий результат. Но готовность к новой модели у них разная: банк уже прошел согласование, а ритейлер еще ждет внутреннее решение.
Если команда включит новую модель сразу для всех, она создаст лишний риск. Банк получит то, что уже утвердил, а ритейлер - то, что ему пока нельзя запускать. Поэтому сервису мало знать только маршрут запроса. Ему нужен tenant_id и правило, которое проверяет флаг перед выбором модели.
Логика простая:
- запрос приходит с
tenant_id; - сервис читает флаг
model_v2_enabledдля этого арендатора; - для банка А выбирает новую модель;
- для ритейлера Б оставляет прошлую версию;
- в логах команда видит, какой арендатор куда был отправлен.
Плюс такой схемы в том, что приложение не приходится дробить на отдельные ветки под каждого клиента. Чат-оператор работает через один сервис, а развилка живет в слое правил. Если под капотом стоит OpenAI-совместимый шлюз вроде AI Router, приложение и дальше может отправлять запросы в один совместимый эндпоинт, не меняя SDK, код и промпты, а выбор модели оставлять за вашей логикой доступа.
На практике банк А можно перевести на новую модель сначала для части операторов или для одного типа диалогов. Это дает живую проверку без общего переключения. У ритейлера Б флаг остается выключенным, пока юристы, ИБ или владелец продукта не дадут добро.
Команде важно видеть не только сам ответ модели, но и следы запуска. Когда в журнале есть tenant_id, активный флаг, версия модели и время смены правила, спорных ситуаций становится меньше. Если банк скажет, что после вторника ответы стали короче, команда быстро поймет, сработал ли новый маршрут или причина в другом.
Быстрая проверка перед включением
Перед запуском не нужен длинный аудит. Нужны несколько ясных ответов, которые команда может проверить за 10-15 минут. Если хотя бы один пункт висит в воздухе, включение лучше отложить.
Новая модель может вести себя нормально в одном сценарии и ломать другой: менять формат ответа, тратить больше токенов или упираться в лимит раньше, чем старая. Поэтому перед запуском стоит быстро пройтись по короткому списку.
Что проверить за несколько минут
- Составьте список затронутых сценариев. Не общий "чат" или "поиск", а конкретные потоки: суммаризация звонков, черновик ответа оператору, проверка анкеты, классификация обращения.
- Зафиксируйте лимит запросов для арендатора. Команда должна знать не только дневной потолок, но и что считать тревогой в первый час после включения.
- Разведите логи нового и старого потока. Потом это сэкономит часы: вы сразу увидите, где ответ дала новая модель, а где еще работал старый маршрут.
- Назначьте понятный сигнал для отката. Это может быть рост ошибок, скачок стоимости, задержка выше порога или жалоба из бизнес-команды на конкретный сценарий.
- Дайте поддержке короткую памятку: дата включения, список арендаторов, что изменилось для пользователя и кому писать при сбое.
Обычно ломается не модель, а договоренность между командами. Разработчики думают про качество ответа, поддержка ждет формулировку для клиентов, а владелец продукта уверен, что лимиты уже согласованы. В итоге флаг включили, а потом полдня выясняют, кто должен был заметить рост нагрузки.
Хороший признак готовности простой: любой дежурный может за минуту ответить на два вопроса - у кого флаг включен и по какому сигналу его нужно выключить. Если ответ ищут в чате за прошлую неделю, запуск еще сырой.
Если вы ведете трафик через AI Router, проверьте до релиза, что в аудит-логах видно трафик по арендаторам, а rate limits на уровне ключа уже настроены так, как вы договорились с клиентом. Тогда при первых отклонениях вы увидите не просто "ошибки выросли", а у какого клиента, на каком потоке и после какого включения это случилось.
Ошибки, которые срывают запуск
Чаще всего запуск ломает не сама модель, а грубое управление доступом. Когда один флаг включает новую логику сразу для всех арендаторов, любая проблема у одного клиента стопорит релиз целиком. Смысл появляется только тогда, когда правила разделены по арендатору, сценарию и версии модели.
Вторая частая ошибка еще проще: флаг создают для пилота, а потом забывают убрать. Через пару месяцев никто не помнит, почему один клиент сидит на старой ветке, кто это одобрил и можно ли удалить обходной код. У каждого флага должны быть владелец и дата конца. Иначе временная мера превращается в постоянную путаницу.
Старые промпты тоже часто ломают запуск. Команда меняет только model_id и думает, что этого хватит. Но новая модель по-другому понимает инструкцию, иначе держит формат и может отвечать длиннее, осторожнее или, наоборот, слишком кратко. Если вы не проверили системные промпты, примеры в промпте и правила постобработки, проблемы пойдут не в логике флага, а в самом ответе.
Отдельная ловушка - формат ответа. API может остаться тем же, но модель вернет лишний текст перед JSON, поменяет порядок полей, иначе вызовет tool или добавит пояснение там, где раньше был чистый объект. Для бизнеса это не мелочь. Один клиент увидит приемлемый ответ, а другой получит сбой в парсере и пустой экран.
Еще одна ошибка кажется скучной, пока не приходит счет. Команды часто не сверяют стоимость по арендаторам до запуска. Два клиента могут делать одинаковое число запросов, но один отправляет короткие заявки, а второй гоняет длинный контекст и просит большой ответ. После включения новой модели расходы растут неравномерно, и разговор быстро уходит от качества к бюджету.
Если вы используете шлюз вроде AI Router, смотрите метрики не в среднем по системе, а отдельно по арендатору, модели, размеру промпта и длине ответа. Иначе общая картина будет выглядеть нормально, а один дорогой клиент незаметно съест половину лимита.
Перед включением полезно задать четыре вопроса:
- Флаг включает функцию только для нужного арендатора, а не для всех сразу?
- У флага есть срок жизни и человек, который потом уберет его из кода?
- Команда проверила старые промпты, парсеры и шаблоны ответа на новой модели?
- Вы видите цену, ошибки и задержку отдельно по каждому арендатору?
Если на любой вопрос ответ расплывчатый, запуск лучше притормозить на день. Это дешевле, чем потом разбирать инцидент у клиента в рабочее время.
Как откатить без суеты
Фичефлаги имеют смысл только тогда, когда откат занимает минуты, а не полдня. Если новая модель дала слабые ответы или выросла задержка, команда должна вернуть конкретного арендатора на прошлый маршрут одним действием. Без правок в коде, без срочного релиза и без ручной замены промптов.
Для этого правило включения лучше хранить отдельно от приложения. У арендатора должен быть простой выбор: новая модель или прежняя. Тогда откат сводится к одному переключателю в конфиге, базе правил или внутренней панели.
Часто команды спотыкаются на банальной вещи: старую модель убирают сразу после запуска новой. Это плохая идея. Прошлую модель стоит держать рядом хотя бы на время наблюдения, с той же схемой вызова и понятной версией. Если запросы идут через один OpenAI-совместимый шлюз, вы можете поменять маршрут для одного клиента и не трогать само приложение.
В первые 10-15 минут после включения смотрите сразу на три метрики:
- качество ответов на живых запросах;
- цену одного сценария или диалога;
- задержку до первого токена и до полного ответа.
Не ждите, пока накопятся жалобы от пользователей. Если ответы стали хуже, стоимость вышла за план или сервис начал отвечать медленнее, лучше откатить сразу. Ранний откат почти всегда дешевле длинного разбора уже после инцидента.
Полезно заранее задать пороги. Например, если средняя задержка выросла на 40% или доля невалидных ответов превысила норму, дежурный инженер возвращает арендатора на прошлую модель по готовому правилу. Так команда не спорит в моменте и не тратит время на лишние согласования.
После отката оставьте запись в журнале. Хватит короткой строки: кто переключил, какого арендатора затронули, когда это случилось и что именно пошло не так. Причина должна быть конкретной: "стоимость выросла в 1,8 раза", "модель чаще нарушала формат ответа", "задержка стала выше SLA".
Еще лучше сохранить снимок настроек на момент отката: модель, версию промпта, лимиты и включенные инструменты. Через неделю это сэкономит много времени и избавит команду от споров по памяти.
Что сделать после первого запуска
Первый запуск редко заканчивается в тот момент, когда вы включили новую модель одному арендатору. После него почти всегда остаются временные флаги, обходные маршруты и лимиты, которые ставили "на всякий случай". Если не разобрать это сразу, через пару недель команда уже спорит, что считать нормой, а что было временной мерой.
Сначала уберите все, что уже отработало. Удалите флаги, которые были нужны только для теста или пилота, сохраните историю изменений и запишите, почему вы их выключили. Лишние флаги потом сами становятся источником риска.
После этого зафиксируйте обычный порядок согласования для новых моделей. Не нужен регламент на двадцать страниц. Хватает короткой схемы: инициатор запрашивает модель, владелец продукта подтверждает сценарий, безопасность и юристы смотрят ограничения, владелец бюджета проверяет стоимость, потом инженер включает доступ по арендатору. Когда этот порядок записан, следующая заявка проходит без суеты.
Полезно держать в одном месте несколько вещей: маршруты моделей по каждому арендатору, аудит-логи по включениям и смене правил, лимиты по API-ключам и сценариям, а также правила маскирования PII и хранения данных, если для клиента это обязательно.
Если у части клиентов есть требования по хранению данных внутри Казахстана, единый шлюз вроде AI Router упрощает базовую часть схемы: один OpenAI-совместимый эндпоинт, аудит-логи, маскирование PII и инфраструктура внутри страны. Но сам порядок доступа все равно лучше держать у себя явно, через tenant_id, статусы и понятные правила отката.
И в конце разберите первый запуск по фактам. Сколько запросов прошло через новый маршрут? Были ли ручные вмешательства? Где сработали лимиты? Не было ли лишних отказов из-за правил доступа? Эти заметки сильно экономят время перед следующим релизом.
Хороший признак зрелого процесса очень простой: следующий запуск занимает часы, а не неделю ручных согласований. Команда открывает одно место с правилами, выбирает арендатора, ставит лимит и включает модель по понятной схеме.