Политики доступа к моделям на один запрос без лишних рисков
Политики доступа к моделям помогают задать правила по ролям, данным и средам, чтобы сдержать расходы и не выпускать чувствительные данные наружу.
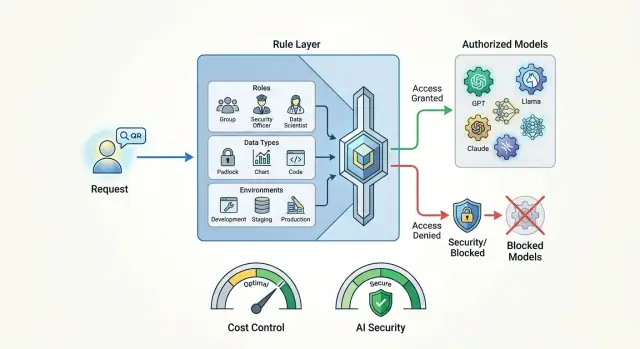
Почему один и тот же запрос нельзя отправлять во все модели
Один и тот же запрос может стоить команде совсем разных денег в зависимости от модели. Короткий вопрос пользователя нередко превращается в длинный пакет данных: история диалога, системный промпт, вложения, служебные поля. На дешевой модели это почти незаметно, на дорогой счет растет быстро. Обычно проблему замечают не сразу, а после первого крупного инвойса.
Расходы растут не только из-за цены за токен. Сильные внешние модели часто выбирают по привычке даже для простых задач: классифицировать письмо, вынуть дату из текста, сделать короткую сводку, предложить черновик ответа. Для этого нередко хватает более простой модели. Если отправлять весь трафик в самый дорогой вариант, переплата копится каждый день и долго не бросается в глаза.
Есть и второй риск. В запросе могут оказаться номер договора, телефон, диагноз, жалоба клиента или внутренний документ. Даже если сотрудник не собирался передавать чувствительные данные, модель получает их целиком. Для банка, телекома, клиники или госкоманды это уже вопрос не удобства, а правил работы с данными. В Казахстане к этому добавляются требования по хранению данных внутри страны и по обработке PII.
Еще один фактор - роль сотрудника. Аналитику или ML-инженеру иногда нужен доступ к сильной внешней модели для эксперимента. Оператору поддержки такой доступ часто не нужен совсем. У них разный риск, разный бюджет и разные последствия ошибки. Одно правило для всех почти всегда бьет либо по расходам, либо по безопасности.
Среда тоже меняет решение. В разработке команда гоняет тестовые сценарии и проще относится к ошибкам. В продакшене идут живые обращения клиентов, и цена промаха заметно выше. То, что допустимо в песочнице, не стоит автоматически пускать в рабочий поток.
Перед отправкой запроса обычно достаточно проверить четыре вещи:
- кто отправляет запрос
- какие данные есть в тексте и вложениях
- из какой среды пришел трафик
- сколько команда готова платить за этот класс задач
Когда эти проверки собираются в одно правило, выбор модели перестает быть случайным. Для части задач подойдет внешняя сильная модель, для части - локальная, а некоторые запросы лучше вообще не выпускать наружу.
Что проверять перед каждым вызовом
Маршрут запроса лучше выбирать не по одному полю model, а по контексту. Один и тот же промпт может быть безопасным в демо и слишком рискованным в продакшене.
Сначала проверьте, кто запускает вызов. У внутренней команды может быть один набор моделей, у сервисного аккаунта - другой, у подрядчика - самый узкий. Это не формальность. У разных отправителей разный уровень доверия и разная зона ответственности.
Потом посмотрите на сами данные. Открытый текст, внутренний документ и персональные данные нельзя обрабатывать одинаково. Если в промпт попали ФИО, телефон, номер договора или медицинская информация, правило должно сработать до отправки. Вариантов обычно три: замаскировать поля, запретить внешнюю модель или перевести запрос на локальный маршрут.
Дальше проверьте среду. В разработке можно оставлять больше свободы, но уже в тестовой среде полезно включать лимиты и вести журнал запросов. В продакшене любой обход политики лучше считать ошибкой, а не обычным исключением.
Отдельно считайте цену модели именно для этой задачи. Короткая классификация, извлечение полей из формы или простой пересказ редко требуют самой дорогой модели. Если таких вызовов тысячи в час, лишние 2-3 цента быстро превращаются в заметную строку в бюджете.
И последний вопрос: внешняя модель вообще нужна? Для суммаризации, тегирования, короткого черновика ответа и других типовых задач часто хватает локальной модели. Для команд в Казахстане это еще и снижает риск, если обработку нужно держать внутри страны.
Хорошее правило звучит просто: сначала понять, кто отправил запрос и что в нем лежит, потом проверить среду и лимит цены, и только после этого выбирать модель.
Как разделить доступ по ролям
Ролевой доступ работает лучше, когда вы управляете понятными ролями, а не списком людей. Сегодня сотрудник помогает поддержке, завтра тестирует новый сценарий, и набор личных разрешений быстро разваливается. Роль живет дольше, чем конкретная фамилия, поэтому правила проще читать, менять и проверять.
Обычно имеет смысл дать всем командам базовый набор моделей. Это быстрые и недорогие варианты для черновиков, кратких ответов, классификации и поиска по внутренним материалам. Такой набор закрывает большую часть повседневных задач и не толкает людей к дорогим моделям без причины.
Дальше доступ лучше расширять по реальной сложности работы, а не по должности в HR-системе. Оператору поддержки, редактору каталога или сотруднику бэк-офиса редко нужен ручной выбор из десятков моделей. Если оставить его открытым, люди начнут брать самую сильную модель "на всякий случай", а расходы вырастут раньше, чем это кто-то заметит.
Базовая схема может быть такой:
- обычные роли получают только стандартный набор моделей
- роли с аналитикой и сложными текстами получают 1-2 более сильные модели с лимитами
- узкие команды с редкими и дорогими задачами получают доступ по согласованию и на срок
- сервисные аккаунты работают только по заранее заданному маршруту
Исключения тоже нужны, но у каждого исключения должен быть владелец и дата окончания. Если команда по антифроду просит доступ к дорогой внешней модели на две недели для проверки гипотезы, это стоит записать сразу. Иначе временное разрешение останется навсегда.
На практике полезно хранить имя роли прямо в запросе или в профиле приложения, например support-agent, risk-analyst, ml-team. Тогда правило читается за секунду. Когда вместо ролей используется список отдельных людей, система быстро превращается в таблицу исключений, которую никто не хочет трогать.
Как учитывать тип данных и место хранения
Одинаковое правило для всех запросов ломается почти сразу. Один запрос содержит публичный текст, другой - внутренний отчет, третий - имя клиента, телефон и номер договора. Если система не различает эти случаи до вызова модели, политика теряет смысл.
Обычно больше всего пользы дает простая маркировка данных на входе. Часто хватает трех меток: открытые, внутренние и персональные. Этого уже достаточно, чтобы принять первое решение без долгих споров.
Подход может быть таким:
- открытые данные отправляются в разрешенные модели без дополнительных ограничений
- внутренние документы идут по отдельному маршруту, где список моделей уже и логирование строже
- персональные данные не уходят во внешние модели без явной причины и отдельного разрешения
Самая частая ошибка простая: поля маскируют после ответа модели. Это поздно. Если в промпт уже ушли ФИО, ИИН, адрес или номер счета, проблема случилась на этапе отправки. Маскировать такие поля нужно до вызова модели, даже если запрос кажется безобидным.
Для внутренних документов лучше сделать отдельный маршрут, а не надеяться на общее правило. Инструкции для сотрудников, договоры и отчеты могут не содержать персональных данных, но компания все равно не хочет отправлять их во внешние сервисы. Тогда запрос сразу направляется только в заранее разрешенный набор моделей.
Место хранения тоже должно влиять на маршрут. Если данные обязаны оставаться в Казахстане, запрос нельзя отправлять во внешнюю модель только потому, что она дешевле или пишет чуть лучше. Сначала правило хранения, потом удобство.
Чем должны отличаться dev, stage и prod
Одинаковые правила для всех сред обычно дают либо лишние траты, либо лишний риск. В разработке людям нужна скорость и право ошибаться. В продакшене нужен предсказуемый маршрут, понятные лимиты и запрет на случайные изменения.
Что оставить в разработке
Для dev-среды обычно хватает дешевых моделей, короткого таймаута и небольшого лимита токенов. Если разработчик случайно отправит слишком длинный промпт или начнет гонять десятки запросов подряд, потери будут небольшими.
Практика простая: по умолчанию оставить 1-2 недорогие модели для черновых проверок, а дорогие и внешние варианты закрыть. Если команде нужен доступ к сильной модели, лучше выдавать его отдельно и на короткий срок.
Ключи доступа тоже стоит разводить по средам. Тестовый сервис не должен иметь тот же ключ API и те же права, что и продакшен. Иначе один старый секрет в CI или один неверный base_url могут отправить тестовый трафик не туда.
Что проверить в stage
В stage полезно проверять не только сам ответ модели, но и все служебные следы: журнал запросов, маскирование PII, метки контента, срабатывание лимитов и запасной маршрут. Если это не проходит в тестовой среде, в прод выпускать рано, даже когда сам текст ответа выглядит нормально.
Stage хорош тем, что позволяет прогнать реальные правила на безопасных данных. Именно здесь чаще всего видно, что политика на бумаге понятная, а в работе то слишком жесткая, то слишком дырявая.
Что ужесточить в продакшене
В продакшене маршрут к модели лучше фиксировать политикой, а не оставлять на выбор разработчику. Приложение не должно после каждого деплоя внезапно перескакивать с одной модели на другую. Иначе команда быстро теряет контроль над ценой, задержкой и местом обработки данных.
Обычно рабочая схема выглядит так:
- dev: дешевые модели, короткие лимиты, урезанный контекст
- stage: те же маршруты, что и в проде, но на тестовых данных и с полной проверкой логов
- prod: фиксированный список моделей, отдельные ключи, строгие лимиты по ролям
- аварийный режим: заранее одобренная замена на случай сбоя или резкого роста задержки
Запасной маршрут лучше готовить заранее. Если основная модель недоступна, система должна перейти на заранее разрешенную замену, а не на любую доступную модель.
Как собрать политику на один запрос
Политика работает лучше, когда вы описываете не абстрактные модели, а реальные рабочие задачи. Начните с 5-7 частых сценариев: ответ клиенту, сводка звонка, поиск по базе знаний, разбор договора, генерация SQL, проверка текста на рискованные фразы. Этого обычно хватает, чтобы увидеть и лишние расходы, и слабые места в работе с данными.
- Для каждого типа запроса задайте цель. Что важнее именно здесь: низкая цена, быстрый ответ, большой контекст, точность или хранение данных внутри страны?
- Выберите допустимые модели для каждого сценария. Обычно хватает основной модели, запасной и локального варианта для чувствительных данных.
- Задайте жесткие рамки: потолок цены на вызов, максимальный таймаут и размер контекста. Без этого даже хорошая политика быстро ломается под реальной нагрузкой.
- Добавьте правила по роли, данным и среде. Аналитик в dev может тестировать внешнюю модель на обезличенных данных, но тот же запрос в prod с персональными полями должен идти только по разрешенному маршруту или получать отказ.
- Не оставляйте отказ без объяснения. Система должна вернуть понятную причину: "эта модель недоступна в production", "запрос превышает лимит цены", "для данных с PII разрешены только локальные модели".
Хорошая политика не выглядит сложной. Она просто отвечает на пять вопросов: что это за запрос, кто его отправил, какие в нем данные, из какой он среды и сколько вы готовы за него платить.
Пример для службы поддержки банка
Оператор банка открывает обращение клиента и хочет быстро собрать черновик ответа. В запросе уже есть номер договора, детали продукта и история переписки. Для работы это удобно, для модели - чувствительные данные.
Поэтому правило должно смотреть не только на текст, но и на контекст. Система видит роль сотрудника, тип данных и среду, в которой идет обработка. Если запрос пришел из продакшена и содержит персональные поля, включается более строгий маршрут.
В таком сценарии логика обычно простая:
- номер договора, ФИО, телефон и другие поля маскируются до отправки
- запрос помечается как содержащий PII и внутренние инструкции
- внешние модели для такого класса запросов запрещены
- черновик ответа строит локальная модель внутри разрешенного контура
Оператор получает проект ответа, ссылки на нужный регламент и подсказку, что проверить вручную. На простых обращениях это экономит время и не создает лишний риск.
Если спор сложный, например клиент оспаривает комиссию и ссылается на прошлое обещание банка, политика может дать старшему сотруднику другой уровень доступа. Он может запустить повторную проверку на более сильной модели, но только в пределах разрешенного контура и с записью в аудит-лог.
Именно в таких ситуациях правило на один запрос работает лучше всего. Обычный оператор не думает, какую модель выбрать и можно ли отправлять туда текст. Система решает это заранее и по понятным условиям.
Где команды ошибаются чаще всего
Самая частая ошибка - одно правило для всех. Маркетингу, аналитикам, поддержке и разработке дают одинаковый доступ к моделям, хотя задачи, данные и лимиты у них разные. В итоге кто-то получает лишние права, а кто-то упирается в запрет там, где он не нужен.
Вторая ошибка - ручной выбор любой модели в продакшене. На тестовом стенде это еще терпимо. В рабочей среде такой подход быстро ведет к лишним расходам и промахам с данными. Один сотрудник выбирает дорогую модель для простой задачи, другой отправляет чувствительный текст туда, где хранение не подходит под правила компании.
Третья ошибка - смотреть только на цену токенов. Команды часто забывают спросить, куда уходит запрос, где хранятся данные, остаются ли журналы у внешнего провайдера и можно ли вообще отправлять туда этот тип текста. Дешевая модель легко оказывается плохим выбором, если она нарушает требования по хранению или внутренним правилам.
Еще одна частая проблема - вечные временные исключения. Кто-то просит доступ к внешней модели "на пару дней" для пилота, правило добавляют вручную, а потом забывают убрать. Через месяц этим исключением уже пользуются в обычной работе.
И наконец, запасной маршрут часто проверяют хуже основного. На главную модель ставят строгие ограничения, а резервный вариант оставляют почти без фильтров. В момент сбоя запрос уходит в другую модель, и все аккуратные ограничения пропадают в самый неудобный момент.
Если политика кажется готовой, задайте себе три простых вопроса:
- кто отправляет запрос и в какой среде он работает
- какие данные лежат в запросе
- действуют ли те же ограничения для запасного маршрута
Если на любой вопрос нет точного ответа, правило еще сырое.
Что проверить перед запуском
Перед запуском полезно пройтись по нескольким вещам вручную. На схеме политика часто выглядит логично, а в реальной работе дает лишние траты или слишком широкий доступ.
Проверьте хотя бы следующее:
- роли совпадают с реальным доступом, и у оператора поддержки, аналитика и разработчика не один и тот же набор моделей
- для персональных данных есть отдельное правило и отдельный маршрут
- тестовая и рабочая среды разведены по ключам, лимитам и спискам разрешенных моделей
- аудит показывает не только отказ, но и замену модели, если система выбрала более безопасный или дешевый маршрут
- у политики есть владелец, который видит, кто менял правило, когда и зачем
Простой пример: сотрудник контакт-центра открывает карточку клиента и задает вопрос помощнику. Если в тексте есть персональные данные, система должна сразу применять отдельное правило, а не решать это "по умолчанию". Если сотрудник работает в тестовой среде, тот же запрос может идти в более дешевую модель с более низким лимитом.
Что делать после запуска
После запуска почти всегда всплывают две вещи: лишние отказы и тихие обходы правил. Если команда не смотрит на это регулярно, политика быстро превращается в формальность. Люди начинают просить разовые исключения, а расходы снова растут.
Собирайте не только число блокировок, но и причину каждой. Отдельно ведите журнал ручных исключений: кто запросил доступ, для какой задачи, какая модель понадобилась и чем все закончилось. Через несколько недель уже видно, где правило защищает бюджет и данные, а где просто мешает работе.
Каждый месяц полезно смотреть на несколько срезов:
- сколько отказов было по ролям, средам и типам задач
- как часто команды просили ручные исключения
- какие правила ни разу не сработали
- где расходы выросли сильнее обычного
- были ли попытки отправить чувствительные данные во внешние модели
Мертвые правила лучше убирать. Если ограничение месяцами не используется и не закрывает понятный риск, оно только путает людей. Хорошая политика обычно короче, чем кажется.
Полезно смотреть на расходы не только в целом по компании, но и по ролям, средам и видам задач. Один отдел может почти ничего не тратить, а другой незаметно уводить бюджет на дорогие модели в тестовой среде. Такой разрез быстро показывает, где правило стоит ужесточить, а где, наоборот, смягчить.
Если у команды несколько провайдеров и много маршрутов, контроль удобнее держать в одном месте. Например, AI Router на airouter.kz дает единый OpenAI-совместимый адрес API, аудит-логи, маскирование PII и локальный хостинг моделей в Казахстане. Это помогает держать правила, маршруты и ограничения под одним слоем, особенно когда часть запросов нельзя выпускать за пределы страны.
Если через месяц стало меньше ручных обходов, расходы стали понятнее, а правила перестали разрастаться без причины, значит политика работает как надо.
Часто задаваемые вопросы
Почему нельзя просто дать всем одну и ту же модель?
Потому что задачи, риск и цена у всех разные. Оператору поддержки часто хватает недорогой или локальной модели, а аналитик может временно получить доступ к более сильной внешней модели для сложной проверки. Если открыть один и тот же набор всем, команда или переплатит, или пропустит чувствительные данные наружу.
Когда дорогая внешняя модель правда нужна?
Берите ее для задач, где простая или локальная модель уже дает слабый результат. Обычно это сложный разбор длинных документов, спорные клиентские кейсы, генерация SQL с высоким риском ошибки или работа, где нужен большой контекст. Для короткой классификации, сводки и черновика ответа такой выбор часто не окупается.
Что проверять перед каждым вызовом модели?
Смотрите на роль отправителя, тип данных, среду и лимит цены на этот класс задач. Этого уже хватает, чтобы отсеять случайные и дорогие маршруты. Потом выбирайте модель, а не наоборот.
Что делать, если в запросе есть ФИО, ИИН или номер договора?
Сначала маскируйте эти поля, а не после ответа. Если данные нельзя выпускать наружу, сразу отправляйте запрос только в локальную модель или блокируйте внешний маршрут. Для prod это правило должно срабатывать автоматически, без ручного выбора сотрудника.
Чем должны отличаться dev, stage и prod?
В dev оставляйте дешевые модели, короткие лимиты и отдельные ключи. В stage гоняйте те же правила, что и в prod, но на безопасных данных и с полной проверкой логов. В prod фиксируйте маршрут политикой и не давайте приложению свободно менять модель после деплоя.
Как разделить доступ по ролям без ручной путаницы?
Удобнее управлять ролями, а не списком людей. Задайте базовый набор моделей для обычных задач, а более сильные варианты открывайте только тем ролям, которым они реально нужны, и лучше на срок. Так правила проще читать, менять и проверять.
Зачем нужен запасной маршрут к модели?
Да, иначе в момент сбоя система может уйти в любой доступный вариант и обойти ваши ограничения. Подготовьте запасную модель заранее и дайте ей те же правила по роли, данным, среде и цене. Тогда аварийный переход не сломает политику в самый плохой момент.
Что показать пользователю, если политика блокирует запрос?
Давайте короткую и понятную причину. Человек должен сразу видеть, что именно не прошло: среда, лимит цены, внешний маршрут для PII или запрет по роли. Это уменьшает ручные обходы и помогает быстро исправить запрос или выбрать разрешенный сценарий.
Как понять, что политика тратит лишние деньги или мешает работе?
Смотрите не только на общий счет. Полезнее разложить расходы по ролям, средам и типам задач, а рядом держать журнал отказов и ручных исключений. Если простые сценарии часто идут в дорогие модели или люди постоянно просят обход, правило пора править.
Можно ли держать правила, аудит и маршрутизацию в одном API слое?
Да, это самый удобный вариант для команд с несколькими провайдерами и разными маршрутами. Один слой API помогает держать в одном месте аудит, маскирование PII, лимиты и выбор локальной или внешней модели. Для команд в Казахстане это еще упрощает правила, где данные должны оставаться внутри страны.