Что логировать в LLM-приложении без лишнего риска
Разберём, что логировать в LLM-приложении, чтобы видеть сбои, ловить инциденты и проходить аудит без хранения промптов, PII и лишних данных.
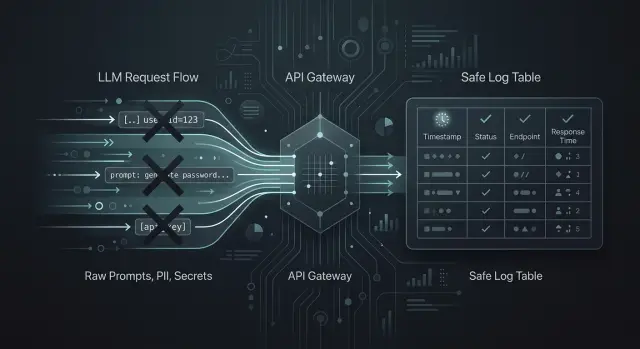
Где логи помогают, а где вредят
Без логов команда видит только жалобу пользователя и общий факт ошибки. Этого мало, если нужно понять, почему модель дала странный ответ, почему выросли расходы или почему запросы начали падать ночью.
В LLM-приложениях логи нужны не "на всякий случай", а для конкретных задач. По ним ищут сбои в шаблонах промптов, всплески задержки, ошибки маршрутизации между моделями, превышение лимитов и отказы на стороне провайдера. Если между приложением и моделями стоит единый OpenAI-совместимый шлюз, без логов быстро теряется понимание, где именно проблема: в приложении, в выбранной модели или в политике доступа по ключу.
Но самый удобный лог для разработчика часто самый опасный для бизнеса. Сырые промпты и полные ответы быстро превращаются в склад лишних данных: имена клиентов, номера договоров, фрагменты переписки, медицинские детали, внутренние инструкции, API-ключи, куски документов. Сегодня такой лог помогает разобрать инцидент, а через месяц сам становится источником риска.
Поэтому лучше сразу разделить цели. Для отладки обычно хватает технического следа: когда пришел запрос, какая модель сработала, сколько занял ответ и где возникла ошибка. Для безопасности важны признаки риска: попытка отправить секрет, всплеск трафика, необычный IP, частые отказы по одному ключу. Для аудита нужен факт действия: кто вызвал систему, какой маршрут прошел запрос, какое правило сработало и сохранился ли обязательный след.
Когда эти задачи смешивают, логирование разрастается без пользы. Команда начинает хранить все подряд, потому что "вдруг пригодится". На практике нужна малая часть, а отвечать потом приходится за весь объем.
Принцип простой: храните только то, что помогает принять решение. Если запись не помогает исправить сбой, расследовать инцидент, подтвердить действие для аудита или выполнить требование закона, ее лучше не писать вообще. Для любых чувствительных данных сначала задайте два вопроса: кто это будет читать и сколько дней это действительно нужно хранить.
Минимальный состав логов
Если вы решаете, что логировать в LLM-приложении, начните не с текста запроса, а с метаданных. Для отладки, безопасности и аудита почти всегда хватает короткого набора полей, по которым видно, что произошло, когда это случилось и через какой маршрут прошел запрос.
Сначала нужны идентификаторы: request_id, trace_id, tenant_id и точное время запроса. request_id помогает найти конкретный вызов, trace_id связывает цепочку из нескольких сервисов, а tenant_id отделяет одного клиента или подразделение от другого. Когда в 14:03 резко растет число ошибок, без этих полей журнал быстро превращается в шум.
Дальше идет описание вызова модели: имя модели, провайдер, выбранный маршрут и версия промпта. Это особенно важно, если приложение умеет переключаться между несколькими моделями или ходит через единый шлюз. Без маршрута и версии промпта трудно понять, почему вчера ответ был нормальным, а сегодня стал хуже или дороже.
Еще одна группа полей нужна для эксплуатации и расходов: latency, status_code, число входных и выходных токенов, стоимость вызова. Эти данные быстро показывают, где приложение тормозит, где модель отвечает слишком длинно и какой сценарий съедает бюджет.
Полезно сразу отмечать и тип операции: chat, embeddings, tool_call, moderation. Иначе потом трудно отделить сбой в диалоге от сбоя в поиске по базе знаний или вызове инструмента.
Отдельно фиксируйте признаки нестабильности: был ли retry, случился ли timeout, уперся ли запрос в rate_limit. Один такой флаг часто полезнее длинного текста ошибки. По нему сразу видно, это разовый сетевой сбой или системная проблема с лимитами.
Минимальный состав логов обычно укладывается в пять групп:
- кто и когда отправил запрос:
tenant_id,request_id,trace_id,timestamp - куда он ушел: модель, провайдер, маршрут, версия промпта
- что произошло: тип операции и
status_code - сколько это заняло:
latency, токены, стоимость - были ли сбои:
retry,timeout,rate_limit
Если эти поля пишутся стабильно, команда уже может расследовать инциденты, считать расходы и проходить аудит без лишнего риска хранения чувствительных данных.
Что лучше не хранить
Главная ошибка проста: в логи попадает все подряд. Для отладки это удобно первые пару дней. Потом такие логи сами становятся проблемой.
Сырые промпты лучше не записывать, если пользователь может вставить туда ФИО, ИИН, номер карты, адрес, диагноз, договор или внутренние данные компании. Для разбора инцидента обычно хватает шаблона промпта, версии приложения, времени запроса и нескольких технических меток. Если нужен пример текста, сохраните короткий фрагмент после маскирования, а не весь ввод целиком.
С полными ответами модели то же самое. Модель часто повторяет секреты из входных данных, пересказывает фрагменты документов или почти без изменений выводит результат tool_call. Разработчику такой ответ читать удобно, но хранить его месяцами плохая идея. Чаще хватает статуса ответа, длины, типа задачи, оценки модерации и признака того, что ответ ушел пользователю.
Из логов стоит убрать все, что дает прямой доступ:
- API-ключи
- access token
- cookie
- session id
- временные ссылки на файлы
Даже один такой фрагмент в общем журнале может открыть лишний доступ тестировщику, подрядчику или любому сотруднику с правом чтения.
Вложения и документы тоже не стоит сохранять "на всякий случай". PDF, сканы паспорта, выписки, медкарты и внутренние отчеты быстро копятся, а пользы от них в логах почти нет. Если файл важен для расследования, лучше сохранить его как отдельный защищенный объект с коротким сроком жизни и ссылкой на инцидент, а в лог записать только тип файла, размер и хеш.
Часто недооценивают еще одну зону риска: результаты tool_call. Приложение может сходить в CRM, банковую систему, ERP или медреестр и вернуть ИИН, номер счета, остаток, диагноз или историю операций. Эти данные не нужно тянуть в обычные логи. Достаточно сохранить имя инструмента, время вызова, код результата и список полей без значений.
Для банковского бота правило выглядит очень приземленно. Он может записать request_id, модель, задержку, число токенов и факт ошибки. Но ему не нужно хранить фото документа, полный текст жалобы с персональными данными и ответ бэкенда с номером карты.
Разделите логи по цели
Одна из самых частых ошибок - складывать все в один поток. Там оказываются тексты диалогов, ошибки, действия пользователя, срабатывания правил и продуктовые метрики. Через месяц такой журнал уже трудно читать, а риск утечки растет без причины.
Лучше делить логи по вопросу, на который вы хотите ответить. Если вопрос разный, поток тоже должен быть разным.
Отладка
Отладочные логи нужны, чтобы повторить сбой и понять, что пошло не так. Обычно им достаточно request_id, времени, модели, версии промпта, кода ошибки, задержки, числа токенов и статуса маскирования. Хранить такие записи лучше недолго.
После разбора инцидента длинная история сырого запроса обычно уже не нужна. На практике часто хватает хеша промпта, идентификатора шаблона, параметров модели и пары безопасных фрагментов, которые прошли маскирование.
Аудит
Аудитный поток должен быть строгим и предсказуемым. В нем важны последовательность событий, время, actor_id, policy_id, outcome и trace_id. Если вы работаете в среде с требованиями к хранению данных внутри страны и к аудит-логам, такой поток лучше держать отдельно и хранить дольше, чем технические журналы.
Безопасность
Логи безопасности отвечают на другой вопрос: не пытается ли кто-то злоупотребить системой. Здесь важны неудачные попытки входа, всплески запросов, обход rate_limit, срабатывания фильтров, попытки отправить PII и необычные паттерны по ключам или IP. Смешивать это с продуктовой аналитикой не стоит.
Аналитика
Для аналитики чаще всего достаточно агрегатов. Средняя задержка, доля отказов, цена на 1000 запросов и частота эскалации в человека дают больше пользы, чем архив чужих диалогов. Сырые тексты здесь обычно лишние.
Для поддержки тоже лучше оставлять только то, что помогает воспроизвести сбой. Оператору банковского бота редко нужен полный текст разговора клиента. Ему важнее request_id, тип сценария, код ошибки и факт того, что система скрыла номер карты.
Как внедрить схему логирования
Команды часто идут по плохому пути: включают подробное логирование всего подряд и надеются потом разобраться. Рабочий подход проще. Сначала соберите небольшую схему логов, потом проверьте ее на реальном инциденте.
-
Выпишите 5-10 событий, без которых команда не найдет причину сбоя. Обычно этого хватает: входящий запрос, вызов модели, ответ модели, ошибка провайдера, отказ по
rate_limit, действие администратора, изменение маршрутизации. -
Для каждого поля задайте два вопроса: зачем оно нужно и кто его смотрит.
request_idнужен инженеру для трассировки,timestampнужен почти всем,modelиproviderнужны команде, которая разбирает стоимость и сбои.user_idлучше хранить в виде хеша, если этого достаточно для поиска. -
Включите маскирование PII до записи в лог. Телефоны, почту, ИИН, номера карт, адреса и свободный текст с персональными данными лучше резать или заменять токеном еще в приложении. Поздняя очистка почти всегда дает утечки, потому что сырая строка уже успевает попасть в несколько систем.
-
Задайте срок хранения для каждого типа логов. Технические журналы для отладки часто живут 7-14 дней, журналы безопасности дольше, а аудит хранится по внутренней политике и требованиям регулятора. Один срок на все типы логов обычно неудобен.
-
Проведите короткий тест. Возьмите инцидент, например резкий рост ошибок у одного клиента, и попробуйте найти причину без сырого текста диалога. Если вам хватает
request_id, статуса ответа, времени, маршрута к модели, счетчиков токенов, хеша пользователя и признака срабатывания фильтра, схема работает.
Если между приложением и моделью стоит единый API-шлюз, держите один и тот же request_id на всех этапах. Тогда команда быстро свяжет логи приложения, безопасности и провайдера в одну цепочку и не будет открывать лишние данные ради обычной отладки.
Пример: бот поддержки банка
Бот поддержки банка обычно отвечает на простые вопросы: где посмотреть статус заявки, как перевыпустить карту, почему не прошел платеж. Для ответа он обращается в CRM за данными клиента и в базу знаний за правилами и инструкциями. В такой схеме логи нужны, но хранить весь диалог целиком не стоит.
Практичнее собирать минимальный состав логов. Он помогает понять, что случилось, если бот ошибся, завис или дал спорный ответ, и при этом не тянет в журнал лишние персональные данные.
Одна запись на запрос может содержать:
request_idдля сборки цепочки событий- маршрут модели: какая модель ответила и был ли фолбэк
latency: общее время ответа и, если нужно, время вызова CRM или поиска по базе знаний- статус
tool_call:success,error,timeout,blocked - короткую метку интента или хеш нормализованного вопроса вместо исходного текста
Если клиент пишет: "Не могу войти, мой номер 8 777 123 45 67, ИИН 990101300123", приложение сначала маскирует эти данные. В лог уходит не исходная строка, а что-то вроде intent=login_problem, phone=8 777 *** ** 67, iin=990101******. Еще лучше вообще не писать номер и ИИН, если они не нужны для разбора инцидента.
То же правило работает и для ответов бота. Нет смысла хранить полную переписку только потому, что она когда-нибудь может пригодиться. Для аудита обычно хватает цепочки событий: бот получил запрос, выбрал модель, обратился к CRM, получил timeout, сходил в базу знаний и выдал безопасный запасной ответ.
При споре по ответу команда поднимает request_id и смотрит не на весь чат, а на маршрут решения. Часто этого достаточно, чтобы быстро найти причину. Например, бот дал общий ответ про лимиты не потому, что модель что-то выдумала, а потому что CRM не вернула профиль клиента за 2,4 секунды и система ушла в запасной сценарий.
Если хотите еще сильнее сократить риск, логируйте не текст найденной статьи, а ее ID и версию. Тогда инженер увидит, на какой материал опирался бот, без копии содержимого в журнале.
Частые ошибки
Самая распространенная ошибка - писать в лог весь промпт и весь ответ модели. Сначала это кажется удобным. Потом в логах копятся номера договоров, фрагменты переписки, адреса, диагнозы, внутренние инструкции и куски документов. Для отладки почти никогда не нужен полный текст каждого запроса. Обычно хватает версии промпта, имени модели, размера входа, статуса, времени ответа и нескольких безопасных флагов.
Вторая проблема появляется тише. Разработчик однажды включает подробный debug в продакшене, чтобы поймать редкий сбой, а потом этот режим никто не выключает. Ручная отладка смешивается с обычными рабочими логами, шума становится больше, а доступ к чувствительным данным получают люди, которым он не нужен. Намного лучше держать два режима отдельно: короткие продакшен-логи по умолчанию и временный расширенный сбор с понятной датой удаления.
Еще одна ловушка - отсутствие общей цепочки событий. Запрос пришел, tool_call сходил в CRM, потом модель вернула ответ, но общего trace_id нет. Через день уже непонятно, где именно случился сбой: в оркестрации, модели, внешнем сервисе или клиентском коде. Один trace_id часто экономит часы разбора.
Проблемы создает и бессрочное хранение логов. Команда думает, что лишние записи никому не мешают, пока не приходит внутренний аудит или запрос на удаление данных. Если debug нужен семь дней, не держите его полгода. Если аудит требует один набор полей, не складывайте рядом все остальное.
И еще один частый промах: в лог попадает не только текст чата, но и параметры tool_call, JSON с ответом из ERP, имя файла, OCR-текст из вложения или кусок PDF. Даже если шлюз маскирует PII и ведет аудит-логи, само приложение все равно может сливать лишнее через собственные журналы.
Быстрая самопроверка выглядит так:
- любой разработчик видит полный промпт пользователя
- PDF или изображение пишется в лог целиком
- у
debug-логов нет срока удаления - один пользовательский запрос нельзя проследить по всем сервисам
tool_callпишет сырые поля из CRM или биллинга
Если совпадают хотя бы два пункта, система логирования уже создает риск, а не только помогает искать ошибки.
Проверка перед запуском
За час до релиза смотрите не на объем логов, а на то, помогут ли они быстро ответить на простой вопрос: что случилось с конкретным запросом. Хороший набор логов дает ясную картину по одному request_id, плохой только копит риск.
Сделайте короткий прогон. Возьмите один тестовый запрос и проверьте, виден ли его путь от входа в API до ответа пользователю. Если запрос проходил через несколько шагов, например маскирование данных, выбор модели и повторную попытку после ошибки, это должно читаться как одна история, а не как россыпь несвязанных записей.
Перед запуском полезно пройтись по короткому списку:
- по одному
request_idкоманда видит весь маршрут запроса: вход, обработку, вызов модели, ответ и сбой, если он был - в логах есть модель, задержка, расход токенов, примерная стоимость и понятная причина ошибки, а не только код
500 - логи не содержат PII, секреты, токены доступа, номера карт, пароли и полный текст документов или переписки
- у каждого типа лога назначен владелец: кто смотрит, кто одобряет доступ и когда запись нужно удалить
- команда может включить подробные логи на время инцидента и потом быстро вернуть обычный режим
Если один из пунктов не выполняется, запуск лучше притормозить. Обычно проблема сидит в деталях: request_id есть на входе, но теряется после ретрая; стоимость считают в отдельной системе; ошибка записывается без текста провайдера; маскирование PII работает в приложении, но не срабатывает в инфраструктурных логах.
Полезно сделать еще одну проверку вручную. Пусть инженер, который не участвовал в настройке, попробует по логам разобрать один неудачный запрос за последние сутки. Если он за 5-10 минут понимает, какая модель ответила, сколько занял вызов, почему случился сбой и какие данные система сохранила, набор логов собран нормально.
И последнее: расширенное логирование нельзя оставлять включенным "на всякий случай". После инцидента команда должна выключать его по понятной процедуре. Иначе временная мера быстро становится постоянным риском.
Что сделать дальше
Начните не с настройки системы, а с простой таблицы. Она быстро показывает, что логировать в LLM-приложении, где нужна маскировка, а что лучше вообще не писать в журналы. Без такой таблицы команды почти всегда собирают лишнее, а потом долго чистят хранилища и спорят с безопасностью.
В таблице обычно хватает четырех колонок:
- поле или событие
- зачем это хранить
- срок хранения
- статус: хранить, маскировать, не хранить
Добавьте туда не только тексты запросов и ответов. Нужны и служебные данные: ID запроса, модель, версия промпта, время ответа, код ошибки, имя инструмента, факт срабатывания фильтра, хеш пользователя или сессии. А вот полные номера документов, телефоны, карты, медицинские данные и сырой ввод с персональными данными чаще всего стоит либо маскировать, либо не сохранять совсем.
Потом прогоните через эту таблицу все реальные сценарии. Не только чат. Отдельно проверьте поиск по документам, агентные цепочки и tool_call. Именно там состав логов часто расходится сильнее, чем кажется.
Например, в поиске полезно хранить ID найденных документов и оценку релевантности, но не весь текст фрагментов. В агенте полезно видеть порядок вызовов инструментов, таймауты и причину отказа, но не секреты из CRM и не содержимое внутренних токенов. Такой проход быстро находит лишние поля.
Раз в квартал пересматривайте таблицу. Лучший момент - после инцидента, внутренней проверки или аудита. Если для разбора ошибки не хватило одного поля, добавьте его осознанно. Если какое-то поле ни разу не помогло, уберите его. Логи не должны расти по привычке.
Если у вас несколько моделей и провайдеров, полезно иметь один слой, где правила логирования и аудита применяются одинаково. Для команд в Казахстане и Центральной Азии эту роль может выполнять AI Router: единый OpenAI-совместимый эндпоинт, аудит-логи, маскирование PII и хранение данных внутри страны. Это удобно, когда нужно менять провайдера без переписывания SDK, кода и промптов и при этом не терять контроль над журналами.
Назначьте владельца этой таблицы и сразу поставьте дату первого пересмотра. Иначе даже хороший список полей через пару месяцев устареет.
Часто задаваемые вопросы
Нужно ли писать в логи полный промпт пользователя?
Обычно нет. Для разбора большинства сбоев хватает request_id, версии шаблона, модели, маршрута, времени ответа и кода ошибки. Если без текста совсем не обойтись, сохраните короткий фрагмент после маскирования и удалите его через короткий срок.
Какие поля стоит логировать в первую очередь?
Начните с метаданных. Чаще всего хватает request_id, trace_id, tenant_id, timestamp, модели, провайдера, маршрута, версии промпта, status_code, latency, числа токенов, стоимости и флагов вроде retry, timeout и rate_limit. Такой набор помогает искать сбои и считать расходы без лишних данных.
Зачем нужны и request_id, и trace_id?
request_id находит один конкретный вызов, а trace_id связывает всю цепочку между сервисами. Когда запрос проходит через приложение, шлюз, tool_call и модель, без trace_id команда быстро теряет картину. Лучше передавать оба идентификатора на каждом шаге.
Сколько хранить debug-логи?
Не держите их долго по умолчанию. Для отладки часто хватает 7–14 дней, если команда быстро разбирает инциденты. Логи безопасности и аудит обычно живут дольше, но их стоит хранить отдельно и по своим правилам.
Можно ли хранить полные ответы модели?
Полный ответ модели лучше не сохранять. Он часто повторяет персональные данные, куски документов или результат tool_call. В журнал обычно достаточно записать статус, длину ответа, тип операции, оценку модерации и факт отправки пользователю.
Что делать с логами tool_call и ответами из CRM?
Не тяните в обычные логи сырые данные из CRM, ERP или медсистем. Практичнее записывать имя инструмента, время вызова, код результата и список полей без значений. Этого хватает, чтобы понять, где сломалась цепочка.
Как проверить, что маскирование PII реально работает?
Маскируйте данные до записи в лог, а не после. Потом прогоните тестовые строки с телефоном, ИИН, картой и почтой через весь путь запроса и проверьте не только приложение, но и инфраструктурные журналы. Если сырая строка всплывает хотя бы в одном месте, схему нужно править.
Как понять, что логов стало слишком много?
Это видно по простым признакам. В логах лежат полные чаты, вложения или токены доступа, у записей нет срока удаления, а часть полей никто не использует даже при разборах инцидентов. Если журнал копится по привычке, он уже мешает больше, чем помогает.
Что должно быть в аудит-логах?
Аудитный поток держите строгим и отдельным. Обычно туда входят actor_id, policy_id, outcome, trace_id, время события и маршрут запроса. Такой журнал показывает, кто что сделал и какое правило сработало, без копии всей переписки.
Как расследовать сбой, если вы не храните текст диалога?
Смотрите не на текст чата, а на маршрут запроса. По request_id и trace_id можно поднять модель, провайдера, версию промпта, задержку, токены, стоимость, флаги retry и timeout, а также статус tool_call. Во многих случаях этого достаточно, чтобы понять причину без чтения чужого диалога.