Что хранить для отладки промптов без риска для приватности
Что хранить для отладки промптов: разберем, как разделить сырые запросы, маскированные копии и метрики, чтобы не раскрывать личные данные.
Где риск
Команде нужны логи промптов по простой причине: без них трудно понять, почему модель дала странный ответ, сломала формат или начала путать роли в диалоге. Один неудачный кейс почти никогда ничего не объясняет. Нужен контекст: какой был запрос, какие системные инструкции сработали, какой ответ вернулся и на каком шаге все пошло не так.
Проблема начинается в тот момент, когда в лог уходит полный текст всего подряд. Для первых дней отладки это кажется удобным. Потом такие журналы быстро превращаются в склад лишних данных. В запрос к LLM часто попадает не только вопрос пользователя, но и куски CRM, история переписки, служебные поля, внутренние заметки и данные из вложенных документов.
Самая частая ошибка - считать, что риск есть только в тексте сообщения. На деле личные данные часто прячутся в обычных полях, которые никто не замечает с первого взгляда: имя и фамилия в профиле, телефон и email в метаданных заявки, адрес доставки, ИИН, номер договора, счета или паспорта. Особенно опасны свободные комментарии оператора. В них обычно оказывается почти все.
Есть и вторая проблема: сырые запросы живут намного дольше, чем команда собиралась. Их включают "на неделю для диагностики", а через полгода они уже лежат в аналитике, бэкапах и тестовых выгрузках. Чем больше копий, тем сложнее понять, кто имеет к ним доступ и зачем.
Отладка и долгий архив - это разные задачи. Для отладки обычно нужны последние инциденты, несколько типовых примеров и технический контекст ошибки. Хранить полный текст месяцами чаще всего бессмысленно, если цель только поправить промпт, а не выполнить отдельное требование закона или внутренней политики.
В банке, телекоме или healthcare это видно особенно хорошо: один плохо настроенный лог может собрать больше персональных данных, чем сама бизнес-функция. Поэтому правила лучше определить до запуска. Даже если запросы идут через единый API-шлюз вроде AI Router, политика логирования, сроки хранения и доступы все равно остаются зоной ответственности команды.
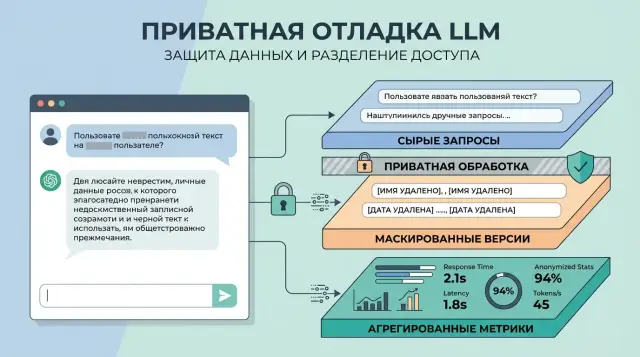
Три слоя логов
Если вы решаете, что хранить для отладки промптов, не складывайте все в один журнал. Для поиска сбоев, контроля качества и отчетности нужны разные данные, а значит, и разные сроки жизни.
Обычно хватает трех слоев:
- сырой запрос для редких разборов серьезных инцидентов
- маскированная копия для обычной отладки и анализа качества
- агрегированные метрики для общей картины без текста
Сырой слой нужен не каждый день. К нему обращаются, когда команда видит спорный ответ, сбой в цепочке инструментов или жалобу, которую нельзя понять по обезличенной версии. Поэтому такой слой лучше хранить очень недолго - от нескольких часов до нескольких дней. Доступ к нему стоит давать только дежурным инженерам и тем, у кого есть формальное право разбирать инциденты. Если компания работает с чувствительными данными, сырой слой лучше держать отдельно от обычных логов и записывать, кто и зачем его открывал.
Маскированная копия живет дольше. Именно по ней разработчики обычно ищут слабые места в промпте: где модель теряет контекст, путает роли или не соблюдает формат ответа. В этой версии имена, телефоны, email, ИИН, номера договоров и другие идентификаторы заменяются на понятные маркеры вроде [NAME] или [ACCOUNT_ID]. Текст остается полезным, но уже не раскрывает человека напрямую.
Агрегированные метрики вообще не должны содержать текст. Здесь достаточно чисел и меток: доля ошибок, средняя задержка, число токенов, отказы модели, срабатывания фильтров, доля попаданий в кэш, частота ручных эскалаций. По ним можно быстро увидеть, что новый промпт поднял стоимость на 18% или удвоил число пустых ответов, даже если никто не читает ни один запрос.
Для каждого слоя задайте свой срок хранения и свой круг доступа. У сырых данных срок самый короткий и доступ самый узкий. У маскированных логов срок средний. У метрик срок самый длинный и доступ самый широкий.
Если вы работаете через AI Router на airouter.kz, это стоит согласовать сразу: где включается маскирование PII, кто видит аудит-логи и как долго вообще живут сырые запросы. Сам шлюз снижает часть операционных рисков, но не заменяет внутреннюю политику хранения.
Что оставить в сыром слое
Сырой запрос нужен не для аналитики, а для редких разборов, когда ответ сломался и команда хочет понять причину. Поэтому храните только то, без чего нельзя воспроизвести сбой. Все остальное лучше вынести в маскированный слой или в метрики.
Практичный минимум выглядит так:
- текст system prompt в отдельном поле
- текст user prompt в отдельном поле
- tool calls и ответы инструментов отдельно от текста диалога
- имя модели, версия, провайдер и фактический маршрут запроса
- параметры вызова: temperature, max tokens, top_p и другие, если они реально влияют на поведение
- число входных и выходных токенов, код ответа, время ответа и request id
Такой разрез упрощает разбор. Если модель начала вести себя странно после смены system prompt, это видно сразу. Если сбой вызвал tool call, его не придется искать внутри большого JSON, где смешаны роли, текст и служебные поля.
Не складывайте в сырой слой все подряд. Вложения, файлы, изображения, сканы документов, длинные профили клиента и историю из CRM лучше не копировать туда целиком. Для поиска ошибок обычно хватает ссылки на объект, его типа, размера, MIME type и статуса обработки. Если файл повредился, вы это поймете и без копии паспорта или выписки.
То же правило работает для данных клиента. Не нужно писать в лог весь профиль, адреса, номера карт и полную историю обращений. Если для разбора важен контекст, оставьте короткие технические поля: internal user id, сегмент, язык, канал, версию сценария. Этого обычно достаточно.
Если команда использует единый LLM-шлюз, полезно сохранять не только внешний endpoint, но и фактическую модель и провайдера, куда ушел запрос. Иначе любой разбор упрется в фразу "у нас все шло через один API", а это почти ничего не объясняет.
Сырый текст лучше удалять по таймеру. Не вручную и не по принципу "потом почистим", а через TTL и автоматическую очистку. Для многих команд хватает 7-30 дней, если инциденты разбирают быстро. Дольше обычно держат только отдельные случаи с понятным основанием. Такой режим проще проверить, проще объяснить службе безопасности и намного труднее нарушить случайно.
Как собрать маскированную копию
Маскированная версия нужна для обычной отладки. Она показывает, где промпт ломается, но не тащит за собой лишний риск. Для большинства команд это самый полезный слой: видно форму запроса, порядок полей и место сбоя, но не видно чужих персональных данных.
Чувствительные фрагменты лучше заменять на простые метки. Имя можно заменить на [NAME], телефон на [PHONE], почту на [EMAIL], ИИН на [IIN]. Если в тексте встречаются номер карты, адрес или номер договора, для них тоже стоит завести свои теги.
Смысл не в том, чтобы превратить фразу в пустой шаблон. Сохраните структуру. Если пользователь написал: "Меня зовут Айжан, мой ИИН 990101300123, проверьте статус заявки", в логе лучше оставить: "Меня зовут [NAME], мой [IIN], проверьте статус заявки". Тогда видно, на каком месте модель ошиблась: при извлечении сущности, маршрутизации запроса или уже в ответе.
Маскировать нужно и входной текст, и ответ модели. Иначе команда уберет данные из запроса, а модель снова выведет их в своем сообщении. В чат-ботах банка, клиники или службы поддержки это происходит постоянно: ответ повторяет имя клиента, номер телефона или часть документа.
Словарь замен лучше хранить отдельно от логов. В обычный журнал должен попадать только маскированный текст. Таблица соответствий, где [NAME_17] связан с реальным значением, если она вообще нужна, должна жить в другом хранилище, с коротким сроком жизни и очень узким доступом. Большинству разработчиков она не нужна вовсе.
Есть и более неприятная ловушка: маскирование часто пропускает кривой ввод. Люди пишут email с пробелами, телефон без кода страны, ИИН с лишним символом. OCR из скана добавляет шум: "8" превращается в "B", "@" исчезает, имя режется на части. Поэтому маскировку стоит проверять на живых примерах с опечатками, смешанным языком и текстом после распознавания документов.
Правило здесь простое. Если маска мешает понять ход диалога, она слишком грубая. Если по логу можно восстановить человека, она слишком слабая.
Какие метрики считать без текста
Чтобы понять, где промпт ломается, не всегда нужен сам текст. Часто цифры дают даже более честную картину: они не тянут за собой персональные данные и быстро показывают, где команда теряет деньги, время и качество.
Вместо хранения каждого сообщения начните с событий вокруг него. Для каждой попытки вызова обычно достаточно сохранить тип задачи, модель, маршрут, время ответа, число токенов, итоговый статус и несколько служебных флагов.
Чаще всего хватает пяти групп метрик:
- доля отказов по типам задач
- токены и стоимость по модели и маршруту
- задержка, тайм-ауты и сетевые обрывы
- частота и глубина правок ответа человеком
- число повторов в одном сценарии
Доля отказов быстро показывает, где промпт не держит задачу. Один и тот же набор инструкций может нормально работать для суммаризации, но регулярно срываться на извлечении полей или ответах клиентам. Для такого сигнала не нужен текст запроса. Нужен ярлык сценария и понятная причина: пустой ответ, отказ по политике, неверный формат, слишком длинный вывод.
Токены и стоимость полезно смотреть по модели и маршруту. Это особенно заметно там, где запросы идут через единый LLM-шлюз и команду ничто не ограничивает одной моделью. Иногда тот же результат получается на более дешевой модели. Иногда дорогая модель просто тратит вдвое больше токенов из-за лишнего контекста. По одним числам это видно уже через день.
Задержку тоже стоит смотреть не только по среднему значению. Пользователю все равно, что среднее было хорошим, если каждый двадцатый запрос зависает на 18 секунд. Поэтому полезны p95, p99, тайм-ауты, повторные попытки и сетевые обрывы.
Частота ручных правок показывает реальное качество лучше, чем сухой статус "ошибка или не ошибка". Если оператор банка меняет ответ модели в 40% случаев, промпт пока сырой, даже если формальных сбоев мало. Имеет смысл считать и глубину правки: одна исправленная дата и полная перепись ответа - это разные проблемы.
Повторы в одном сценарии тоже говорят много. Если пользователь или оператор дважды отправляет один и тот же запрос, значит первый ответ не помог. Это хороший сигнал для доработки, даже когда сам текст не хранится.
Такие метрики удобно смотреть по дням, версиям промпта и типам задач. Тогда после каждого изменения команда видит, что именно стало лучше, а что не изменилось.
Как внедрить по шагам
Начинать лучше не с длинной таблицы полей, а с ролей. Сначала определите, кто вообще смотрит логи. Разработчику нужен текст, чтобы понять, почему промпт дал слабый ответ. Аналитику чаще хватает маскированной версии и счетчиков. Сотруднику поддержки обычно достаточно номера сессии, времени и итогового статуса.
Дальше соберите схему хранения и раздайте права по слоям.
- Сырой слой оставьте самым узким. Храните только то, без чего нельзя разобрать сбой: ID запроса, время, модель, system prompt, пользовательский ввод, ответ, код ошибки и параметры вызова. Срок хранения делайте коротким.
- Маскированный слой пишите до записи в журнал, а не после. Если запрос содержит имя, телефон, ИИН, номер карты или адрес, сервис должен заменить эти части на метки еще до того, как запись попадет в лог.
- Метрики держите отдельно. Туда не нужен текст. Достаточно длины запроса, числа токенов, задержки, доли ошибок, стоимости и оценки качества, если она у вас есть.
- Проверьте схему на одном понятном сценарии. Например, возьмите поток с одним типом пользовательского запроса и прогоните его через всю цепочку: прием, маскирование, запись лога, сбор метрик, разбор инцидента.
- Расширяйте покрытие только после короткой проверки с командой. Пусть разработчик, безопасник и владелец продукта ответят на простой вопрос: можно ли найти причину ошибки без лишних персональных данных.
Такой порядок снимает половину споров еще до запуска. Команда быстрее понимает, где действительно нужен исходный текст, а где хватает маскированной копии и сухих метрик. Для компаний с требованиями к хранению данных внутри страны и аудит-логам это еще и упрощает проверку доступа и сроков жизни данных.
Пример с чат-ботом банка
Клиент пишет в чат банка: "Здравствуйте, я не вижу статус перевыпуска карты. Меня зовут Алия, мой телефон 8 701 123 45 67". Для команды это обычный запрос на поддержку. Для логирования это уже смесь полезного сигнала и персональных данных.
В такой ситуации не нужен один общий лог со всем подряд. Лучше разделить запись на три слоя и дать каждому свой срок жизни.
Сырой слой нужен только для редких сбоев. Туда банк кладет prompt ID, выбранную модель, время запроса, технический статус и сам текст в короткое окно хранения - например, на 24 часа или несколько дней по внутренним правилам. Этого достаточно, чтобы разобрать конкретный сбой: модель не поняла намерение клиента, задала лишний вопрос или зависла на ответе.
Параллельно система создает маскированную копию. В ней фраза клиента уже выглядит так: "Здравствуйте, я не вижу статус перевыпуска карты. Меня зовут [NAME], мой телефон [PHONE]". Если в диалоге есть номер договора, ИИН или адрес, они тоже заменяются на метки. Смысл запроса сохраняется, а личные данные уходят.
Этот слой полезнее, чем кажется. Продуктовая команда все еще видит, что люди часто спрашивают статус карты, путают перевыпуск с блокировкой или не понимают, какие данные бот вообще вправе запрашивать. Но для обычной аналитики никому не нужно читать реальные имена и телефоны.
Отдельно живут агрегированные метрики без текста. Банк считает долю уточняющих вопросов, среднюю задержку ответа, число переводов на оператора и частоту ошибок по шаблону промпта или модели. Если доля уточняющих вопросов выросла с 12% до 27%, проблема заметна сразу. Ни один реальный номер телефона для этого не нужен.
Через неделю сырой текст удаляют. Маскированные примеры можно оставить дольше для разбора сценариев и проверки новых версий промпта. Метрики обычно живут еще дольше, потому что помогают сравнивать модели по месяцам и не несут в себе личные данные.
Для банка это нормальный компромисс. Инженеры не теряют материал для отладки, а служба безопасности не получает бесконечный архив клиентских сообщений.
Где команды ошибаются
Первая ошибка проста: команда хранит полный текст запросов дольше, чем он нужен для разбора сбоев. Сначала это кажется удобным. Через месяц в логах уже лежат имена клиентов, номера договоров, фрагменты писем, вложенные документы и весь диалог целиком. Потом никто не может честно ответить, зачем все это еще хранится.
Вторая ошибка выглядит аккуратнее, но по сути не лучше. Команда маскирует входной запрос, а ответ модели оставляет как есть. Этого достаточно, чтобы чувствительные данные вернулись в лог. Пользователь пишет номер счета во входе, маскирование его скрывает, а модель повторяет номер в ответе.
Третья ошибка - одинаковый доступ для всех. Разработка, аналитика и безопасность получают один и тот же уровень прав просто потому, что так быстрее. На старте это удобно. Потом становится ясно, что разработчику редко нужен полный сырой текст, аналитику почти никогда не нужны исходные сообщения, а команде безопасности не нужен постоянный доступ к каждой сессии.
Четвертая ошибка появляется там, где лог забирает весь контекст без разбора. В него попадают system prompt, история переписки, результаты RAG-поиска и приложенные файлы. Один неудачный debug dump в таком случае превращается в архив приватных данных.
Есть и более тихая проблема: команда смотрит только на токены, стоимость и задержку. Эти цифры полезны, но они не показывают, где модель начала путать роли, терять инструкции или отвечать не по теме. Если считать только агрегированные метрики, можно долго не замечать сбой, который пользователи уже видят каждый день.
Обычно помогает простая схема: сырые запросы живут недолго и доступны узкому кругу, маскированные версии хранятся дольше и подходят для разбора качества, а агрегированные метрики остаются дольше всех и не содержат текста.
Проверка перед запуском
Такая схема ломается не в теории, а в первый день после релиза, когда кто-то ищет причину сбоя в ответах модели. Если в логах смешаны сырой текст, маскированные копии и метрики, команда тратит часы и заодно создает лишний риск для приватности.
Нормальный признак готовности простой: инженер за несколько минут понимает, где искать причину, и для этого ему не нужен доступ ко всему сразу.
Перед запуском стоит проверить несколько вещей:
- у сырого слоя есть точный срок удаления и автоматическая очистка
- маскированная копия не позволяет восстановить человека по набору полей
- метрики не содержат текст, user_id, email, номер заявки и другие прямые идентификаторы
- доступы разделены по ролям, а не выданы всем одинаково
- маршрут разбора инцидента понятен: сначала метрики, потом маскированные примеры и только потом сырой слой
На практике чаще всего проваливают второй и четвертый пункты. Команда маскирует email, но оставляет номер договора, редкий адрес или свободный комментарий с фамилией врача. Формально данные уже "обезличены", но человека все еще можно узнать. С доступами похожая история: если один общий лог видят аналитик, разработчик и подрядчик поддержки, разделения по сути нет.
Небольшой тест быстро находит слабые места. Возьмите 20 реальных записей, покажите их маскированную версию человеку не из проекта и спросите: можно ли угадать клиента, продукт или конкретный кейс? Если ответ "да" хотя бы пару раз, маскирование еще не готово.
Если вы разворачиваете LLM-интеграции через AI Router на airouter.kz, до первого продового трафика отдельно проверьте четыре вещи: где живут сырые запросы, как включено маскирование PII, кто видит аудит-логи и какие данные должны храниться внутри страны. Это лучше решить заранее, чем переделывать схему на живом трафике.
Что сделать дальше
Не пытайтесь перестроить все логи за один раз. Выберите один сценарий, где запросов много и ошибка быстро бьет по сервису: чат поддержки, поиск по базе знаний или помощник для операторов. На одном потоке легче увидеть, какие данные реально нужны для разбора сбоев, а какие поля вы храните просто по привычке.
Сроки хранения согласуйте до запуска. Продукт, разработка, безопасность и юристы должны заранее решить, сколько живет сырой текст, сколько хранятся маскированные копии и кто может их смотреть. После инцидента такие решения почти всегда выходят хуже: команда нервничает и оставляет лишнее.
Рабочий порядок обычно такой: сырой запрос хранит только узкая группа и только короткое время, маскированная версия живет дольше, потому что по ней удобно искать шаблоны ошибок, а в отчеты и дашборды попадают только агрегированные метрики без текста. Полезно раз в месяц пересматривать схему логов и убирать поля, которые никто не использовал.
Это простая дисциплина, но она хорошо режет риск. Очень часто в журналах месяцами лежат куски переписки, идентификаторы клиентов и внутренние заметки, хотя для отладки хватает длины запроса, типа ошибки, модели, задержки и стоимости.
Хороший первый шаг на этой неделе простой: возьмите один частый сценарий, нарисуйте для него три слоя хранения и удалите хотя бы одно поле, которое никому не помогает разбирать ошибки.
Часто задаваемые вопросы
Зачем вообще хранить сырые запросы, если есть маскирование?
Сырые логи нужны для редких разборов, когда маскированной версии уже не хватает. Они помогают увидеть точный system prompt, ввод пользователя, ответ модели и параметры вызова, чтобы быстро найти причину сбоя.
Сколько времени хранить сырой слой логов?
Обычно хватает окна от нескольких часов до нескольких дней. Если команда разбирает инциденты быстро, не держите полный текст месяцами и удаляйте его по TTL, а не вручную.
Что реально стоит записывать в сырой лог?
Оставьте только то, без чего нельзя понять сбой: system prompt, user prompt, ответ модели, tool calls, имя модели, провайдера, маршрут, параметры вызова, токены, код ответа, время и request id. Этого хватает для разбора большинства проблем.
Что лучше не класть в сырой слой?
Не тяните туда профили клиента, вложения, сканы, полную историю CRM и лишние служебные поля. Для файлов обычно хватает ссылки на объект, типа, размера и статуса обработки.
Как понять, что маскирование PII работает нормально?
Проверьте маскировку на живых примерах с опечатками, OCR-шумом и смешанным языком. Если лог все еще позволяет узнать человека, маска слабая; если из текста уже не понять ход диалога, маска слишком грубая.
Нужно ли маскировать не только запрос, но и ответ модели?
Да, обязательно. Если скрыть только вход, модель часто повторит имя, телефон, ИИН или номер договора в ответе, и данные снова попадут в журнал.
Какие метрики можно собирать без текста запросов?
Начните с доли ошибок, задержки, тайм-аутов, токенов, стоимости, ручных правок и повторов в одном сценарии. Эти цифры быстро показывают, где промпт ломается, даже без чтения текста.
Кому нужен доступ к сырым логам, а кому хватит маскированных?
Разделите доступ по ролям. Инженерам дайте узкий доступ к сырому слою на короткое время, разработчикам и аналитикам оставьте маскированные логи, а метрики откройте шире, потому что там нет текста.
Как проверить схему логирования перед запуском?
Сделайте короткий прогон на одном сценарии: прием запроса, маскирование, запись лога, сбор метрик и разбор инцидента. Потом покажите маскированные записи человеку не из проекта и спросите, может ли он узнать клиента или кейс.
С чего начать внедрение такой схемы?
Возьмите один частый сценарий, например чат поддержки, и сразу разделите его на три слоя: сырой, маскированный и метрики. Так команда быстрее увидит, какие поля правда нужны для отладки, а какие лежат в логах просто по привычке.