Человек в контуре: пороги уверенности без ручного ада
Человек в контуре нужен не для каждой проверки: разберите пороги уверенности, типы запросов и простой порядок эскалации к оператору.
Где постоянная ручная проверка ломает процесс
Идея проверять каждый ответ кажется безопасной только на старте. На практике она быстро ломает скорость, расходы и сам смысл автоматизации. Если модель отвечает за 3 секунды, а человек тратит на ту же проверку 60-90 секунд, для клиента разница очевидна.
Очередь растет даже при обычной нагрузке. Представьте поддержку с 600 запросами в день. Если один сотрудник успевает внимательно проверить 25 ответов в час, за 8 часов это около 200 проверок. Два человека закроют примерно 400. Еще 200 останутся на потом уже в первый день.
Дальше становится хуже. На следующий день старый хвост складывается с новыми запросами. Через неделю задержка измеряется уже не минутами, а часами. В этот момент человек в контуре не снижает риск, а добавляет новый: клиент дольше ждет, оператор спешит, команда занята очередью вместо спорных случаев.
Проблема не только во времени. Расходы почти линейно растут вместе с трафиком: больше обращений - больше смен, больше проверяющих, больше накладных затрат. При этом ошибки никуда не исчезают. Уставший сотрудник тоже пропускает странный ответ или одобряет его по инерции. В итоге LLM перестает быть автоматизацией и превращается в дорогой черновик.
Однотипные запросы утомляют особенно быстро. Когда сотрудник сотый раз видит "где мой заказ" или "как сбросить пароль", внимание падает. Он смотрит на первые строки, а мелкая ошибка, лишнее обещание или неверная сумма остаются незамеченными.
Есть и менее заметный эффект. Команда, привыкшая проверять все подряд, обычно не строит нормальные правила эскалации. Простой и спорный случай идут одним маршрутом. Система не учится отличать безопасные запросы от тех, где без человека нельзя.
Поэтому сплошная ручная проверка почти всегда упирается в тупик. Людей лучше оставлять там, где цена ошибки действительно высокая: деньги, персональные данные, спорные решения, нестандартные жалобы. Тогда очередь короче, ответы быстрее, а внимание команды уходит туда, где оно правда нужно.
Какие запросы стоит сразу отдавать человеку
Лучший старт для схемы "человек в контуре" - отделить рутину от случаев, где ошибка дорого обходится клиенту или компании. Здесь не нужна сложная математика. Во многих случаях тип запроса сам подсказывает, нужен ли оператор.
Сразу переводите человеку обращения, где промах заметно влияет на деньги, права клиента или обязательства компании. Обычно в эту группу попадают:
- возвраты, списания, смена тарифа, закрытие договора, пересчет штрафов;
- смена телефона, адреса, паспортных данных, доступ к истории операций;
- претензии, согласия, отказ от услуги, спор по условиям договора;
- редкие или странно сформулированные запросы, где модель скорее начнет гадать;
- обращения без обязательных данных, например без номера, даты или суммы платежа.
Рутинные запросы выглядят иначе. Если клиент спрашивает статус доставки, часы работы, стандартные условия тарифа или просит короткую справку по утвержденной базе знаний, человека обычно можно не подключать. Ошибка там неприятна, но редко ведет к спору или прямому убытку.
Есть простой ориентир: если после ответа модели оператор все равно должен проверить факт, документ или право на действие, не тратьте время на лишний круг. Сразу передавайте диалог человеку.
Отдельно стоит помечать случаи, где модель хочет вызвать инструмент, но не получает результат. Клиент просит остаток по счету, а CRM не отвечает. В такой ситуации модель часто пытается "быть полезной" и строит ответ на догадках. Так делать не стоит. Если инструмент не вернул данные, диалог должен уйти оператору с короткой причиной.
Полезно смотреть и на частоту формулировки. Если запрос приходит раз в месяц, устойчивого паттерна ответа обычно нет. В банке, клинике или SaaS это часто всплывает в спорах по списанию, нестандартных скидках и старых договорах. Такие обращения лучше не держать на автопилоте.
Рабочее правило простое: автоматизируйте частое, понятное и обратимое. Все, что меняет деньги, права, личные данные или требует догадок, лучше сразу отдавать человеку.
Как задать пороги уверенности без сложной математики
Чтобы настроить пороги уверенности LLM, не нужен отдельный data science проект. Достаточно взять 100-200 недавних запросов из живого потока и разметить ответы по простой схеме: "можно отправлять", "нужна правка", "нельзя отправлять". Уже на такой выборке видно, где модель ошибается часто, а где ручная проверка почти ничего не дает.
Если запросы проходят через единый шлюз, удобно брать первую выборку из аудит-логов. Для старта нужны всего несколько полей: сам запрос, ответ модели, итог для клиента и факт эскалации запросов человеку.
Дальше оставьте 2-3 сигнала, которые команда реально будет смотреть каждый день.
- Уверенность модели. Это может быть собственная оценка модели, score из вашего пайплайна или простой proxy-сигнал.
- Риск темы. Платежи, возвраты, персональные данные, медицина и юридические вопросы требуют более строгого порога.
- Цена ошибки. Неверный ответ про график работы неприятен. Неверный ответ про комиссию или договор уже дорог.
Не стоит собирать десять метрик сразу. Чем сложнее схема, тем быстрее люди начинают обходить ее вручную.
Лучше сразу задать три зоны вместо одного общего порога:
- автоответ;
- выборочная проверка;
- обязательная передача человеку.
Для безопасных FAQ можно начать осторожно: все, что выше 0.85, отправлять автоматически, диапазон 0.65-0.85 пускать на выборочную проверку, а все ниже передавать оператору. Для финансовых или медицинских тем порог разумно поднять еще выше, даже если модель выглядит уверенно.
Раз в неделю пересматривайте границы на свежей выборке. Если в зоне автоответа почти нет плохих ответов, ее можно немного расширить. Если люди часто исправляют ответы из средней зоны, порог стоит поднять или сам тип запроса перевести в ручную обработку. Так система учится на реальном потоке, а команда не вязнет в сплошной проверке.
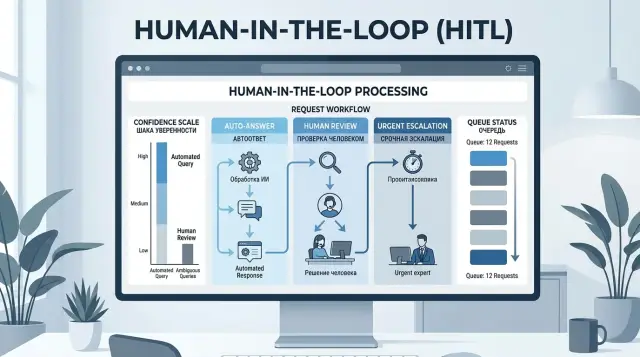
Простой порядок маршрутизации шаг за шагом
Нормальная маршрутизация LLM-запросов устроена проще, чем кажется. Сначала вы смотрите на риск запроса, потом на уверенность модели, затем на сбои в данных и инструментах. После этого запрос уходит либо в автоответ, либо в нужную очередь человеку.
Такой порядок помогает не смешивать разные причины эскалации. Одно дело, когда модель сама сомневается. Совсем другое - когда она уверена, но тема рискованная или система не получила нужные данные из CRM, базы заказов или внутреннего сервиса.
Базовая схема выглядит так:
- определить класс риска: низкий, средний или высокий;
- проверить уверенность модели внутри этого класса;
- посмотреть служебные сигналы: ошибка инструмента, таймаут, пустые поля, конфликт данных;
- отправить запрос в нужную очередь и сохранить причину.
На первом шаге важна не формула, а здравый смысл. Смена тарифа, возврат денег, медицинская рекомендация, жалоба, спор по договору, работа с персональными данными - все это лучше сразу отдавать человеку. Простой вопрос вроде "где мой заказ" или "какой у вас график" часто можно закрыть без ручной проверки ответов.
Дальше уверенность модели нужно смотреть только внутри своего класса риска. Для низкого риска порог может быть мягче. Для среднего риска его стоит поднять. Для высокого риска одна уверенность не должна решать все сама.
Потом проверьте, на чем строился ответ. Если внешний инструмент не ответил, не подтянулся номер заказа или в карточке нет суммы и даты, не стоит надеяться на хороший текст. Такой запрос сразу уходит человеку, потому что проблема не в формулировке, а в дыре в данных.
Очереди тоже лучше разделять. Финансовые вопросы идут одной группе, жалобы другой, обычная поддержка третьей. Тогда оператор получает не абстрактный "сложный кейс", а понятную задачу.
Причину эскалации лучше писать коротко и одинаково: "высокий риск", "уверенность ниже порога", "ошибка CRM", "нет обязательного поля". На это уходят секунды, зато потом легко понять, где именно ломается процесс: в модели, в правилах маршрута или в источниках данных.
Если команда работает через AI Router, такие причины удобно хранить рядом с аудит-логами. Это помогает быстро увидеть не только ответ модели, но и почему система не пустила его дальше автоматически.
Какие сигналы риска смотреть кроме уверенности
Одна только уверенность модели часто дает ложное чувство контроля. Ответ может звучать спокойно и убедительно, но все равно быть рискованным. Поэтому человек в контуре нужен не для всех ответов подряд, а для случаев с понятными признаками риска.
Самый частый сигнал - PII и другие чувствительные данные в запросе или ответе. Если пользователь пишет ИИН, номер карты, адрес, диагноз или детали трудового спора, маршрут стоит ужесточить сразу. Даже корректный ответ может создать проблему, если такие данные нельзя хранить или пересказывать без проверки.
Второй важный сигнал - конфликт между ответом модели и данными из ваших систем. Модель пишет, что заказ доставлен, а CRM показывает "в пути". Или обещает возврат, хотя по правилам он уже невозможен. Здесь важен не красивый текст, а совпадение с источником истины. Если есть расхождение, ответ должен увидеть человек.
Стоит следить и за формой ответа. Подозрительно выглядят слишком короткие ответы на сложный вопрос, слишком длинные ответы с лишними деталями, резкая смена тона по сравнению с обычными сообщениями, попытка обойти правила через странную формулировку и повторный запрос после неудачного ответа.
Необычные формулировки часто ломают простые фильтры. Пользователь может не просить запрещенное напрямую, а обходить правило намеками, ролевой игрой или цепочкой уточнений. Такие случаи лучше ловить не по стоп-словам, а по поведению: запутанный контекст, давление на систему, просьба "ответить как будто" или "игнорировать прошлые инструкции".
Повторный запрос тоже важен. Если человек уже дважды перефразировал вопрос после плохого ответа, это сигнал. Чаще всего модель не поняла задачу, а не просто ошиблась в детали. В потоке поддержки такой диалог лучше быстро передать оператору, чем тратить еще несколько ходов и раздражать клиента.
Если у команды есть шлюз с маскированием PII и аудит-логами, эти сигналы легче собирать и проверять без ручного поиска по журналам. В AI Router такие функции можно использовать как часть общего потока. Но само правило остается простым: уверенность модели нужно смотреть вместе с контекстом, а не вместо него.
Пример сценария на потоке поддержки
Представим поддержку банка, где LLM разбирает входящие сообщения и выбирает одно из трех действий: ответить автоматически, запросить уточнение или сразу передать диалог сотруднику. В такой схеме человек в контуре остается в процессе, но не тратит день на однотипные обращения.
Клиент пишет: "Какая комиссия у тарифа для переводов между своими счетами?" Это обычно безопасный вопрос. Если модель правильно распознала тему и нашла точный ответ в базе, она может ответить сама. Держать такие обращения на постоянной ручной проверке бессмысленно.
Другой пример сложнее: "Поменяйте лимит по карте на снятие наличных". Тут мало просто хорошо сформулировать ответ. Система должна проверить, кто пишет, какой продукт у клиента, прошел ли он нужную верификацию, нет ли ограничений по профилю. Если все поля на месте и сценарий четко описан, запрос можно вести дальше автоматически. Если хотя бы одного поля не хватает, лучше не гадать. Такой диалог уходит в очередь на уточнение, где бот просит недостающие данные по шаблону.
Есть и обращения, которые стоит отдавать человеку сразу, даже при высоких порогах уверенности LLM: "Я не узнаю эту операцию", "С карты списали деньги дважды", "Мне кажется, доступ получил кто-то еще". Спорная операция, риск мошенничества, жалоба на списание, возможный юридический спор - все это не место для автоответа.
На практике маршрут можно свести к четырем правилам:
- простой вопрос о тарифе или статусе услуги идет в автоответ;
- запрос на смену лимита проходит только при полной информации и ясном намерении;
- спорные операции и жалобы сразу попадают сотруднику;
- неполные обращения идут на уточнение, а не в бесконечную очередь.
Через одну-две недели команда должна смотреть не только на качество ответов, но и на долю ручных передач. Если почти все запросы уходят вверх, пороги выставлены слишком строго. Если передач мало, а исправлений много, пороги слишком мягкие. Рабочий режим находят по живому потоку, а не по красивой схеме в презентации.
Ошибки, которые снова приводят к ручному аду
Чаще всего процесс ломается не из-за модели, а из-за слишком грубых правил. Самая типичная ошибка - один и тот же порог для всех тем, каналов и сценариев. После этого очередь на проверку растет каждый день, и команда не понимает почему.
Причина простая: смена адреса доставки в чате, жалоба на списание денег и внутренний FAQ для сотрудников несут разный риск. Если держать единый порог, вы либо пропустите опасные случаи, либо завалите людей рутиной.
Еще одна частая ошибка - отправлять человеку почти все новые типы запросов только потому, что они новые. На старте это кажется осторожным решением, но через неделю ручная проверка съедает весь выигрыш от автоматизации. Для новых категорий лучше задать короткий период наблюдения, а не вечный статус "только через оператора".
Очередь на проверку тоже нельзя оставлять без лимита. Если верхней границы нет, система начинает складировать задачи, которые никто не успевает разбирать. В итоге клиент ждет дольше, оператор спешит, а качество падает именно там, где вы хотели его поднять.
Полезно ввести простое правило: если очередь вышла за предел, часть пограничных случаев идет по запасному сценарию. Например, модель просит уточнение у пользователя, а не ставит запрос в хвост на сорок минут.
Многие команды еще и не собирают причины эскалации. Человек исправил ответ, закрыл тикет, и на этом все. Так невозможно понять, где именно сбоит система: в классификации темы, в пороге уверенности, в промпте или в нехватке данных.
Без такой обратной связи человек в контуре становится дорогим фильтром, а не способом улучшать маршрут. Даже простая пометка причины уже помогает: "нехватка контекста", "рискованная тема", "модель перепутала намерение", "нужно решение по политике компании".
Есть и обратная крайность: ручную проверку не снимают даже там, где модель уже месяц отвечает стабильно. Это хорошо видно на повторяющихся запросах вроде статуса заказа, стандартных условий возврата или базовых инструкций. Если метрики ровные, часть потока стоит отпускать в автоответ.
Здоровая схема выглядит просто: люди разбирают редкие, спорные и дорогие ошибки, а не читают подряд тысячи безопасных ответов. Иначе это не контроль качества, а пробка.
Быстрый чек-лист перед запуском
Перед стартом полезно проверить не саму модель, а маршрут принятия решения. Если у вас есть человек в контуре, он должен вмешиваться редко, по понятной причине и в нужный момент.
Проверьте несколько вещей.
- Разделите поток на три зоны: низкий риск и высокая уверенность, серая зона и высокий риск без автоответа.
- Показывайте оператору причину эскалации, а не просто фразу "проверьте этот ответ".
- С первого дня смотрите на две цифры: долю эскалаций и время ответа клиенту.
- Меняйте пороги по журналу запросов, а не по общему впечатлению от пары громких случаев.
- Не задерживайте простые запросы без причины.
Хороший признак перед запуском такой: оператор понимает, зачем запрос пришел к нему, а команда может объяснить, почему именно этот порог стоит сейчас. Если вы сравниваете несколько моделей через один шлюз, это особенно удобно: проще увидеть, где различия идут от модели, а где от правил маршрута.
Если хотя бы один из этих пунктов не закрыт, лучше потратить еще день на настройку. Это почти всегда дешевле, чем потом разбирать ручной завал.
Что делать дальше
Начните с одного типа запросов, где ошибку легко заметить и посчитать. Для старта подходят обращения поддержки со стандартным ответом: возвраты, смена тарифа, статус заказа, типовые справки. Не стоит сразу брать весь поток. Так человек в контуре останется точечным механизмом, а не новой формой ручной проверки всего подряд.
Сначала зафиксируйте базовую неделю без изменений. Посмотрите, сколько ошибок доходит до клиента, сколько ответов сотрудник правит вручную и сколько времени уходит на один запрос. После этого включите выборочную проверку на две недели и сравните цифры на том же типе обращений.
Во время пилота хватит четырех метрик:
- доля запросов, которые ушли человеку;
- доля ошибок после автоответа;
- доля ответов, которые оператор исправил;
- среднее время ответа клиенту.
Если ручных касаний стало меньше, а доля ошибок не выросла, схема работает. Если ошибок стало больше, спорить с результатом не стоит. Лучше поднять порог, сузить класс запросов или добавить еще одно правило эскалации.
Потом соберите защитный контур вокруг этой схемы. Сначала включите аудит-логи, чтобы видеть, какой запрос прошел автоматически, какой ушел человеку и по какой причине. Затем добавьте маскирование PII, чтобы ИИН, телефоны, номера карт и адреса не попадали в промпты и журналы в открытом виде. После этого поставьте лимиты на уровне ключа, чтобы один сервис не съедал весь бюджет и не забивал общий поток.
Для бизнеса в Казахстане такие требования часто возникают уже на раннем этапе. Если команда строит LLM-поток через AI Router, можно использовать один OpenAI-совместимый эндпоинт, хранить данные внутри страны и вести аудит-логи без отдельной сборки этого контура с нуля.
Через две недели у вас будет не спор о подходе, а нормальная картина по цифрам. По ней уже видно, где автоматика справляется сама, а где человеку лучше оставаться в цепочке.