AI-задачи через очередь: когда уводить в async-пайплайн
Разберем, когда AI-задачи через очередь работают лучше веб-запроса, как собрать async-пайплайн и где он снижает таймауты, цену и риск сбоев.
Где ломается прямой веб-запрос
Проблема обычно начинается не с модели, а с ожидания. Пользователь нажимает кнопку, а страница висит 8, 15 или 30 секунд, пока LLM дочитывает текст, думает и собирает ответ. Для чата это иногда терпимо. Для классификации документа, суммаризации звонка или извлечения полей из файла - уже нет.
Обычный веб-запрос хорош, когда ответ нужен почти сразу. У AI-вызова время ответа скачет. Один запрос проходит за 2 секунды, следующий - за 18. Если в цепочке есть загрузка файла, OCR, несколько промптов и повторная проверка результата, задержка растет еще сильнее. Пользователь видит крутилку, а потом нередко получает ошибку, хотя сама задача была нормальной.
Дальше приходят таймауты. Браузер, балансировщик, nginx, backend и SDK модели живут со своими лимитами. Даже если ваша функция готова ждать минуту, кто-то в цепочке оборвет запрос раньше. Самый неприятный случай простой: модель почти закончила работу, но клиент уже отключился, и весь сценарий рвется в самом конце.
Есть и другая проблема - всплески трафика. Когда десять пользователей одновременно отправляют большие документы на суммаризацию, тормозит не только AI-часть. Под удар попадают обычные страницы, логин, карточки заказов и поиск. Один тяжелый синхронный путь легко забивает воркеры приложения и съедает пул соединений.
Обычно это видно по нескольким сигналам:
- p95 и p99 растут намного быстрее среднего времени ответа
- часть запросов падает ровно около лимита таймаута
- повторные клики и ретраи создают новую волну нагрузки
- сбой у AI-провайдера ломает весь пользовательский путь
Последний пункт часто недооценивают. Если модель недоступна, пользователь не должен терять форму, платеж или уже загруженный файл. Но при прямом вызове AI внутри HTTP-запроса сбой модели часто превращается в поломку всей операции. Человек нажимает "Отправить", а система отвечает 500, хотя могла принять задачу, поставить ее в очередь и вернуть статус "принято в обработку".
Даже если команда использует единый шлюз и может быстро сменить модель или провайдера, сам синхронный сценарий остается хрупким. Очередь не делает модель быстрее. Зато она отделяет долгую AI-работу от пользовательского клика. В большинстве случаев это важнее.
Какие задачи стоит уводить в фон
В фон лучше отправлять работу, где ответ не нужен в ту же секунду, а сама операция может занять заметное время, упасть по таймауту или потребовать повторной попытки. Обычно это задачи с длинным входом, большим числом документов или мягким сроком ответа. Если результат нужен через минуту, час или в следующем отчете, очередь почти всегда удобнее прямого веб-запроса.
Чаще всего в такой режим попадает не чат, а обработка потока данных после события. Пришло письмо, загрузилась запись звонка, сохранилась анкета, за день накопилась пачка чеков - и система спокойно разбирает их без давления со стороны пользователя.
Хорошо подходят классификация входящих обращений, суммаризация длинных писем, звонков и документов, извлечение полей из анкет, договоров и чеков, а также пакетная обработка по расписанию. Ночью можно прогнать накопившиеся документы, пересчитать теги, обновить карточки клиентов или собрать сводки по отделам.
У таких задач есть общий признак: результат важен, но мгновенный ответ не нужен. Часто есть и второй признак - работа идет сразу над множеством объектов. Если у вас 5 тысяч анкет за день, лучше поставить их в очередь, чем пытаться обработать все внутри пользовательских запросов.
Очередь особенно полезна там, где качество зависит от повторов и проверки. С первого раза модель может не извлечь поле, вернуть пустой ответ или отдать формат не по схеме. В фоне это чинится проще: можно добавить retry, отправить задачу на другую модель, записать статус и сохранить аудит-лог.
Простой пример: контакт-центр загружает записи звонков каждые 15 минут. Система отдельно делает транскрипт, потом краткое резюме, потом ставит категорию обращения. Оператору не нужно ждать это на экране. Руководитель видит итог позже, зато без таймаутов и ручного перезапуска.
Когда ответ нужен сразу
Если человек смотрит на экран и ждет следующий шаг, ответ лучше отдавать в том же запросе. Очередь тут только мешает: она добавляет лишние секунды и усложняет интерфейс. Для короткого чата, подсказки в форме или быстрой проверки ответа синхронный вызов обычно честнее и проще.
Ориентир простой: пользователь еще не отвел взгляд от экрана, а результат уже нужен, чтобы продолжить действие. Если модель читает 2-3 абзаца, отвечает за секунду и ошибку нужно показать сразу, async-пайплайн пользы не даст. Он нужен там, где работу можно отложить без потери смысла.
В чате это видно лучше всего. Пользователь отправил короткий вопрос, ждет уточнение, а потом пишет следующее сообщение. Если вынести такой обмен в фон, диалог начинает рваться: статус крутится, ответ приходит позже, человек уже успел нажать еще раз или ушел. Для коротких реплик прямой вызов почти всегда лучше.
То же самое с проверкой формы по одному простому признаку. Например, вы просите модель быстро определить, есть ли в тексте номер договора, есть ли запрещенное слово, совпадает ли язык с выбранным полем. Если от этой проверки зависит, можно ли нажать "Отправить", ответ нужен сразу.
Иногда синхронный вызов нужен не ради финального ответа, а ради выбора следующего шага. Частый пример - короткая маршрутизация перед основным запросом. Сначала вы даете модели 1-2 предложения: "это классификация, поиск по базе или суммаризация?" После этого код выбирает другой промпт, лимит токенов или саму модель. Такой первый вызов должен быть быстрым, иначе вы тормозите всю цепочку.
Синхронный путь обычно подходит, когда пользователь ждет ответ прямо сейчас, текст короткий и предсказуемый по объему, ошибку нужно показать на текущем экране, а результат влияет на следующий вызов в ту же секунду.
Во многих командах схема выглядит просто: один быстрый вызов определяет маршрут, второй делает основную работу. Но если оба укладываются в нормальное время ответа, очередь не нужна. Для маленьких задач лишняя асинхронность чаще усложняет код, чем помогает.
Как собрать простой async-пайплайн
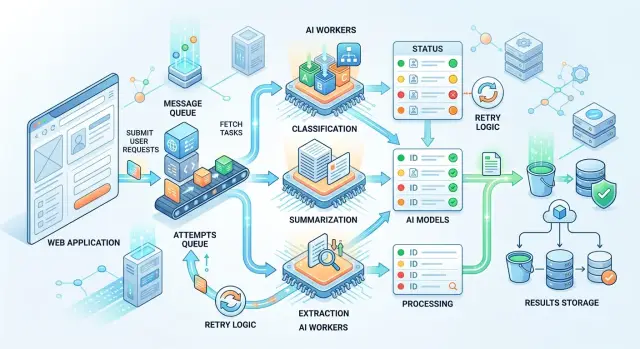
Простейшая схема состоит из пяти частей: API, очередь, воркер, хранилище результатов и способ узнать статус. Пользователь отправляет текст, а сервер не держит соединение до конца обработки. Он создает задачу, записывает ее в базу, кладет сообщение в очередь и сразу возвращает job_id.
Такой подход полезен, когда AI-задачи идут десятками или сотнями подряд. Веб-запрос живет секунды, а обработка документа, пачки отзывов или длинного чата часто живет заметно дольше. Если не отделить одно от другого, приложение начинает зависать под нагрузкой.
Минимальная схема
В сообщение очереди лучше класть не все подряд, а только то, что нужно воркеру для старта. Обычно хватает job_id, типа работы, ссылки на текст или самого текста, дедлайна и пары служебных полей вроде клиента или приоритета. Если документ большой, сам файл лучше хранить отдельно, а в очередь передавать ссылку на него.
Дальше воркер забирает задачу и решает, какую модель вызвать. Для простой классификации часто хватает быстрой и дешевой модели. Для извлечения полей из сложного договора может понадобиться модель сильнее. Если у команды один OpenAI-совместимый слой, менять провайдера или модель проще, потому что бизнес-логика не зависит от конкретного API.
Результат и статус лучше хранить раздельно. Статус отвечает на вопрос "что происходит сейчас": queued, running, done, failed. Отдельная запись с результатом хранит сам ответ модели, время обработки, ошибку при сбое и, если нужно, метаданные для аудита. Так легче делать повторный запуск и не смешивать служебную информацию с полезными данными.
Пользователь может получить готовый ответ двумя обычными способами. Первый - приложение раз в несколько секунд спрашивает статус по job_id. Второй - система сама отправляет событие, когда задача завершилась. Для внутреннего кабинета часто хватает опроса. Для цепочки из нескольких сервисов удобнее событие.
На практике это выглядит просто. Менеджер загружает 500 обращений клиентов на суммаризацию. Интерфейс сразу показывает, что пакет принят, и дает номер задачи. Через пару минут экран обновляется, и менеджер видит итоговый файл, а не зависший запрос, который давно бы упал по таймауту.
Что класть в сообщение очереди
Сообщение в очереди должно отвечать на три вопроса: что обработать, как обработать и когда уже поздно. Если этих данных нет, воркер начинает гадать, а такие догадки потом дорого искать в логах.
Сначала передайте ID объекта и источник текста. ID нужен, чтобы потом сохранить результат в нужную запись, а источник помогает не таскать в очередь большие куски данных без причины. Для письма, обращения или карточки товара обычно хватает пары вроде document_id=84521 и source=crm.ticket_body. Если текст короткий и безопасный, его можно положить прямо в сообщение. Если текст большой или содержит личные данные, лучше передать ссылку на внутреннее хранилище или путь до записи.
Дальше добавьте версию промпта и ожидаемый формат ответа. Это спасает от путаницы, когда вчера вы просили "короткую сводку", а сегодня ждете JSON с полями category, confidence и reason. В сообщении лучше явно писать что-то вроде prompt_version=summary_v3 и response_schema=incident_extract_v2. Тогда повторная обработка идет по тем же правилам, и результат можно сравнивать с прошлым запуском.
Срок выполнения тоже нужен. У фоновой задачи почти всегда есть дедлайн, даже если он не выглядит жестким. Суммаризация отчета для внутренней панели может подождать 10 минут, а разбор заявки для оператора должен уложиться, например, в 30 секунд. Рядом храните число повторных попыток и текущий номер попытки. Если модель или провайдер недоступны, воркер не должен гонять задачу бесконечно.
Отдельно стоит передавать приоритет и лимит стоимости. Это особенно полезно там, где запросы идут через маршрутизатор моделей. Одну и ту же задачу можно отправить на более быструю или более дешевую модель, если приоритет низкий и бюджет ограничен. Для срочной задачи правило другое: лучше ответить быстрее и чуть дороже, чем держать пользователя в ожидании.
И еще одно поле часто экономит много времени - уникальный ключ для отсечения дублей. Если один и тот же документ случайно попал в очередь дважды, система должна это понять. Обычно такой ключ собирают из типа задачи, ID объекта и версии промпта, например ticket-84521-classify-v2. Тогда воркер либо пропустит дубль, либо обновит уже существующую задачу, а не создаст две разные записи с разными ответами.
Хорошее сообщение в очереди не просто запускает LLM. Оно делает задачу воспроизводимой, управляемой по срокам и предсказуемой по деньгам.
Пример из обычного потока работы
Представьте банк, который за день получает тысячи обращений из мобильного приложения, сайта и чата. Люди пишут как получится: "деньги списались два раза", "не вижу перевод", "хочу закрыть кредит раньше". Если отправлять каждое такое сообщение в LLM прямо во время веб-запроса, форма начнет тормозить, а в часы пик часть запросов просто не дождется ответа.
Поэтому вход лучше разделить на два шага. Сначала форма принимает текст, сохраняет его и сразу подтверждает прием. Клиент почти мгновенно видит номер обращения и не думает о том, что внутри системы сейчас идет классификация или суммаризация.
Дальше работает async-пайплайн. После сохранения обращения система кладет задачу в очередь. Воркер забирает ее, определяет тип проблемы и пишет короткое резюме. При необходимости он добавляет служебные пометки: есть ли жалоба на платеж, нужен ли срочный разбор, есть ли в тексте признаки мошенничества или спорной операции.
Через минуту, а часто и быстрее, сотрудник открывает не пустую карточку с длинным сообщением клиента, а уже подготовленную запись. В ней есть категория, краткое описание и поля для маршрута обработки. Это экономит не абстрактную эффективность, а вполне реальные 20-40 секунд на каждом обращении.
Поток обычно выглядит так: клиент отправляет текст и сразу получает подтверждение, система ставит задачу в очередь, воркер делает классификацию и короткое резюме, результат попадает в карточку обращения, а сотрудник видит уже размеченный запрос.
Ошибки все равно будут, и это нормально. Модель может спутать возврат платежа с обычной претензией по карте или принять запрос на смену номера за проблему со входом. Поэтому спорные задачи не стоит проталкивать дальше автоматически. Если ответ выглядит сомнительно, система отправляет задачу на повторный прогон другой моделью или помечает ее для ручной проверки.
Именно в таком потоке фоновые AI-задачи дают понятный эффект. Клиент не ждет AI-ответ, интерфейс не висит, а команда поддержки получает уже разобранные обращения почти сразу после отправки.
Почему очередь иногда не спасает
AI-задачи через очередь работают только тогда, когда сама очередь остается простой и предсказуемой. Если правила не задать заранее, вы просто переносите проблемы из веб-запроса в фон: задержки растут, ответы дублируются, а старые задачи висят без конца.
Где все ломается на практике
Частая ошибка - класть в сообщение не ссылку на файл, а весь PDF, аудио или большой JSON. Очередь от этого быстро разрастается, повторные попытки занимают больше времени, а воркеры тратят ресурсы на передачу данных. Почти всегда лучше передавать путь к объекту, хеш файла, размер и несколько служебных полей.
Другая ошибка - пускать срочные задачи и ночную пакетную обработку в один поток. Днем это особенно больно: короткая суммаризация звонка ждет, пока система дожует архив из тысяч документов. Разделяйте очереди хотя бы по приоритету и типу работы.
Еще одна проблема появляется, когда команда не сохраняет промпт, имя модели и версию настроек. Через несколько дней результаты начинают расходиться, а понять причину уже нельзя. Для классификации и извлечения данных это ломает проверку качества и разбор ошибок.
После сбоя задачу иногда запускают повторно без постоянного идентификатора. В итоге один документ получает две суммаризации, CRM создает две заметки, а отчет считает один кейс дважды. Повторный запуск должен быть безопасным, иначе очередь сама производит мусор.
Наконец, многие забывают про срок жизни задачи. Если обработка пришла через сутки, ответ может уже не иметь смысла: клиенту ответили, заявка закрыта, данные изменились. Старую задачу лучше отменить, чем тихо обработать слишком поздно.
Если у вас один OpenAI-совместимый эндпоинт, а модель под капотом может меняться, фиксируйте в задаче точное имя модели, версию промпта и важные параметры. Иначе любой спор о качестве превращается в догадки.
Нормальный минимум такой: маленькое сообщение в очереди, отдельные очереди для срочного и пакетного потока, ID задачи для защиты от дублей и дедлайн, после которого работа теряет смысл. Без этого даже хорошая очередь для суммаризации не спасает. Она просто аккуратно складывает старые проблемы в новый ящик.
Проверка перед запуском
Очередь помогает не всегда. Иногда она просто прячет медленный и хрупкий процесс за словом "async". Перед запуском полезно честно ответить на несколько вопросов.
Пользователь может закрыть страницу и вернуться позже без потери смысла? Это частый случай для классификации документов, пакетной суммаризации звонков и извлечения полей из файлов. Задача спокойно терпит минуты, а не секунды? Если результат нужен через 5-10 минут, очередь подходит. Если человек нажимает кнопку и ждет ответ прямо сейчас, лучше оставить прямой вызов.
Интерфейс показывает статус? Человек должен видеть не пустой экран, а понятные состояния: "в очереди", "обрабатывается", "готово", "ошибка". Команда знает, что делать, если модель ошиблась или не ответила? Нужны простые правила: сколько раз повторять запрос, когда отправлять задачу в ручную проверку, когда помечать ее как неуспешную.
Вы считаете цену одной задачи и цену повтора? Без этого очередь быстро превращается в черный ящик, который молча тратит бюджет.
Самый частый провал не в коде, а в ожиданиях. Команда уводит задачу в фон, но пользователь все равно сидит и ждет тот же результат на том же экране. Тогда выигрыша почти нет. Очередь имеет смысл только там, где процесс можно отпустить и забрать итог позже.
Хороший признак - когда результат естественно приходит после события. Например, менеджер загрузил 300 отзывов, ушел на встречу и через несколько минут получил готовые теги и краткую сводку. Плохой признак - когда оператор колл-центра не может продолжить работу, пока LLM не вернет ответ.
Отдельно проверьте стоимость повторов. Одна неудачная попытка редко страшна. Десять автоповторов на большом документе уже заметны.
Если почти на все вопросы ответ "да", фоновые AI-задачи через очередь обычно оправданы. Если сомневаетесь хотя бы в двух местах, начните с малого: уведите в async только самые долгие операции и оставьте быстрый путь для всего остального.
С чего начать без лишней переделки
Не переводите сразу весь поток на очередь. Проще взять один медленный случай, где длинный текст уже создает паузы: расшифровку звонка, большой PDF, пачку отзывов или письмо с вложениями. Такой старт быстро показывает, нужны ли вам AI-задачи через очередь именно в вашем продукте.
Хороший первый кандидат - суммаризация или извлечение полей из документа на 10-20 страниц. Пользователь загружает файл, система сразу отвечает, что приняла задачу, а потом спокойно делает разбор в фоне. Интерфейс при этом не висит 30-60 секунд, и сервер не держит открытый веб-запрос без причины.
Короткие запросы лучше пока оставить на прямом пути. Если человек ждет ответ в чате, подсказку в форме или классификацию одного абзаца, лишняя очередь часто только добавляет задержку. Простое правило такое: длинный вход и не срочный ответ уводите в фон, короткий вход и мгновенный отклик оставляйте как есть.
Чтобы не переделывать интеграцию второй раз, спрячьте вызов модели за одним OpenAI-совместимым слоем. Тогда приложение обращается не к конкретному провайдеру напрямую, а к одному внутреннему клиенту. Позже вы сможете сменить base_url, добавить резервный маршрут или выбрать другой класс модели без переписывания бизнес-логики.
Для команд в Казахстане это особенно удобно, если сразу нужен один предсказуемый путь к разным моделям и понятные операционные правила. Например, AI Router на api.airouter.kz дает OpenAI-совместимый эндпоинт, помесячный B2B-инвойсинг в тенге и инструменты вроде аудит-логов, маскирования PII и хранения данных внутри страны, когда это требуется.
На старте хватит пяти шагов:
- выбрать один длинный и не срочный процесс
- оставить синхронный путь для коротких запросов
- вынести вызов модели в единый клиент
- записывать
task_id, статус, время обработки и цену - возвращать результат в интерфейс или webhook после завершения
Через неделю уже видно, работает схема или нет. Сравните среднюю задержку, долю ошибок и цену одной задачи до очереди и после нее. Если разница заметна, расширяйте подход на соседние процессы, а не на всю систему сразу.
Часто задаваемые вопросы
Когда очередь лучше прямого веб-запроса?
Уводите задачу в очередь, когда ответ не нужен в ту же секунду и сам вызов может жить дольше обычного HTTP-запроса. Это особенно хорошо работает для длинных документов, OCR, цепочек из нескольких промптов и пакетной обработки.
Какие AI-задачи обычно уводят в фон?
Чаще всего в фон отправляют классификацию обращений, суммаризацию писем и звонков, извлечение полей из анкет, договоров и чеков, а также ночные пакетные прогоны. Общий признак простой: результат нужен, но пользователь не ждёт его прямо на экране.
Когда лучше оставить синхронный вызов?
Оставляйте синхронный вызов там, где человек ждёт следующий шаг сразу. Это подходит для короткого чата, быстрой проверки формы и короткой маршрутизации перед основным запросом.
Что должно происходить после нажатия кнопки пользователем?
Сразу принимайте задачу, сохраняйте её и возвращайте job_id или номер обработки. Пользователь должен увидеть понятный статус, а не крутилку до конца работы модели.
Что класть в сообщение очереди?
Обычно хватает job_id, типа задачи, ссылки на текст или файла, версии промпта, схемы ответа, дедлайна, приоритета и номера попытки. Большие файлы в очередь не кладите — храните их отдельно и передавайте ссылку.
Как защититься от дублей?
Соберите постоянный идентификатор из типа задачи, ID объекта и версии промпта. Тогда система поймёт, что один и тот же документ уже обрабатывается, и не создаст второй результат поверх первого.
Как настроить ретраи и ошибки?
Не гоняйте задачу бесконечно. Задайте лимит повторов, фиксируйте ошибку, а для спорных случаев отправляйте задачу на другую модель или на ручную проверку.
Почему очередь всё равно может не решить проблему?
Очередь не спасает, если вы смешали срочные задачи с ночными пакетами, не ставите дедлайн или не сохраняете версию промпта и имя модели. В таком случае проблемы просто переезжают из веб-запроса в фон.
Как показывать статус задачи пользователю?
Покажите простые состояния: queued, running, done, failed. Для кабинета обычно хватает опроса по job_id, а для цепочки сервисов удобнее отправить событие после завершения.
С чего начать, если не хочется переделывать весь продукт?
Начните с одного долгого сценария: большого PDF, расшифровки звонка или пачки отзывов. Вынесите вызов модели в единый клиент, записывайте статус, время и цену, а короткие запросы пока оставьте на прямом пути.