Жаңа эмбеддинг моделіне көшу: нені тексеру керек
Эмбеддингтің жаңа моделіне көшу өлшемділікті, іздеу сапасын, жылдамдықты, жадты және ескі векторлармен үйлесімділікті тексеруді талап етеді.
Неге көзсіз реиндекс нәтижені бұзады
Сұраулар, база және код өзгермесе де, жаңа эмбеддинг моделі векторлық кеңістіктің геометриясын дерлік әрдайым өзгертеді. Іздеу үшін бұл ұсақ нәрсе емес. Бұрын жоғары тұрған құжаттар төмен түсіп кетуі мүмкін, ал дәлірек емес жауаптар керісінше алға шығады.
Пайдаланушы "тауарды қайтару шарттары" деп іздейді. Бұрын алғашқы жолдарда қайтару ережелері мен мерзімдері тұрса, реиндекстен кейін бірінші болып жалпы FAQ шығуы мүмкін, өйткені жаңа модель фразалардың жақындығын басқаша бағалайды. Формалды түрде іздеу жұмыс істеп тұр. Пайдаланушы үшін ол нашарлады.
Ұқсастық порогтарында да сол жағдай. Егер бұрын score 0.82-ден жоғары болса, жақсы сәйкестік жиі табылатын, модель ауысқаннан кейін бұл порог енді ештеңеге кепіл болмайды. Жаңа модель қашықтықтарды тығызырақ не, керісінше, сирегірек таратуы мүмкін. Соның салдарынан жүйе артық құжаттарды өткізіп жібереді немесе пайдалысын кесіп тастайды.
Тағы бір қарапайым мәселе бар: эмбеддинг өлшемділігі. Жаңа модельдің векторы ұзындау болса, индекс жадта да, дискіде де тез үлкейеді. Үлкен коллекцияларда бұл бірден байқалады. 768 өлшемдегі және 3072 өлшемдегі миллион құжат — сақтауға да, кідіріс профиліне де мүлде басқа есеп.
Ең жағымсыз жағдай — ескі және жаңа векторлардың аралас жиыны. Көп команда сервисті тоқтатпау үшін индексті бөліп-бөліп жаңартады. Бірақ әртүрлі модельдің векторлары әртүрлі кеңістікте өмір сүреді, сондықтан оларды тікелей салыстыруға болмайды. Нәтижесінде бір сұрау бүгін бір нәрсені табады, ертең басқа нәрсені, ал дерек қосылғаннан кейін қайтадан өзгеріп кетеді.
Көбіне көзсіз реиндекс нәтижені төрт себеппен бұзады:
- нәтижедегі құжаттардың реті өзгереді;
- ескі ұқсастық порогтары шу шығара бастайды;
- индекс көбірек жад пен орын сұрайды;
- ескі және жаңа векторлардың араласуы жауапты құбылмалы етеді.
Сондықтан эмбеддингтің жаңа моделіне көшу — жай ғана "векторларды қайта есептеп, әрі қарай жүре беру" емес. Алдымен жаңа модель ранжирлеуді, порогтарды және индекс өлшемін өз деректеріңізде қалай өзгертетінін тексеріңіз. Әйтпесе мәселе пайдаланушылар біртүрлі жауап көре бастағанда, production-да шығады.
Модельмен бірге не өзгереді
Жаңа модель тек векторлардың өзін ғана өзгертпейді. Көбіне іздеудің бүкіл логикасы өзгереді: индекс қанша жад алады, салыстыру үшін қай метрика жақсы, модель ұзын мәтіндерде қалай жұмыс істейді және ескі мен жаңа векторларды бір коллекцияда ұстауға бола ма — соның бәрі.
Алдымен өлшемділікті тексеріңіз. Егер ескі модель 768 сан берсе, ал жаңасы 1024 немесе 3072 берсе, индекс, кэш және желі трафигі өседі. Құжат саны өзгермесе де, жад айырмасы айтарлықтай болуы мүмкін. Формат та маңызды: float32, float16, кейде квантизацияланған нұсқа. Бұл сақтау құнына да, жылдамдыққа да әсер етеді.
Метрика және нормализация
Содан кейін нормализацияға қараңыз. Кейбір модельдер ұзындығы бойынша алдын ала нормаланған вектор береді, кейбірі бермейді. Сондықтан cosine және dot product бірдей құжат жиынында нәтижелердің ретін басқаша беруі мүмкін. Егер база cosine-ке есептелсе, ал жаңа модель dot product-пен жақсы жұмыс істесе, кодта бірде-бір қате болмаса да іздеу сапасы төмендеуі мүмкін.
L2-ні де тек формальді түрде тексермеңіз. Кейбір модельдер үшін бұл метрика top нәтижелерінде шу көп береді, әсіресе векторлар нормаланбаған болса. Практикада бұл былай көрінеді: керекті құжат екінші орында еді, енді тоғызыншы орынға түсіп кетті.
Тағы бір ығысу кіріс мәтіннің лимитіне байланысты. Жаңа модель көбірек токен қабылдауы мүмкін, бірақ бұл әрдайым плюс емес. Кейде ол ұзын абзацты ескіден нашар қысқартады, ал қысқа дәл сұраулар тым жалпы құжаттарды тарта бастайды. Кейде керісінше: лимит кішірек болып, чанк-теріңіз күштірек кесіледі.
Орысша, қазақша және аралас деректер
Егер базаңыз орысша болса, оны жалпы орташа баллмен ғана емес, жеке тексеріңіз. Дәл солай "доставкa заказа", "refund", "SKU" және өнім атаулары латын қарпімен берілген аралас фрагменттерге де қатысты. Кей модельдер ағылшын тілін жақсы ұстайды, бірақ тұрмыстық код-свитч-ті нашар түсінеді.
Ескі векторларды әдетте автоматты түрде үйлесімді деп санауға болмайды. Өлшемдері сәйкес келген күннің өзінде кеңістік басқа болуы мүмкін. Онда жаңа модельмен кодталған сұрау ескі модельмен кодталған құжаттарды нашар таба бастайды.
Бір параметрге емес, мына байланысқа қараңыз: өлшемділік, нормализация, метрика, мәтін лимиті және сіздің тілдеріңіздегі мінез-құлық. Әдетте сюрприздердің көбі дәл осы жерден шығады.
Тексеру үшін қандай дерек керек
Тесттік жиын бәрін дерлік шешеді. Егер тек таза оқу мысалдарын алсаңыз, жаңа модель әдемі орташа баға көрсетіп, бірінші күні-ақ тірі трафикте құлайтын болады.
Тексеру үшін нақты іздеу сұрауларын, қолдау чатын, RAG-логтарды және ішкі ассистенттерді жинаған дұрыс. Егер бұл шынайы жағдайлар болса, 100–300 сұрау көбіне жетеді. Жұмысқа кіріспес бұрын жеке деректерді алып тастаңыз немесе бүркемелеңіз.
Жақсы жиын әрдайым сәл ыңғайсыз болады. Онда тек "тауарды қайтару шарттары" сияқты ұқыпты сұраулар ғана емес, қысқа, шуылы көп және сирек тұжырымдар да болуы керек: "қайтару", "акті таппадым", "тариф b2b архив", қате терілген сұраулар, аббревиатуралар және тіл араласқан нұсқалар.
Егер білім базасы бірнеше командаға немесе нарыққа жұмыс істесе, мысалдарды срездерге бөліңіз. Орташа метрика көбіне бір сегменттегі құлдырауды жасырады. Кемінде тіл, өнім, сценарий және сұрау ұзындығы бойынша қарау ыңғайлы. Мысалы, орысша, қазақша және аралас сұрауларды бөлек, ал FAQ, регламенттер, техқолдау және заң мәтіндерін бөлек шығару.
Мұндай бөлініс бір ағында күнделікті сұрақтар мен саясат не келісімшарттағы қатаң тұжырымдар қатар жүретін жерде өте пайдалы. Банк, телеком және мемлекеттік секторда бұл — қалыпты жағдай.
Алғашқы тестке дейін эталонды бекітіп алыңыз. Әр сұрау үшін қандай құжаттар, чанк-тер немесе жауаптар дұрыс деп саналатынын белгілеңіз. Міндетті түрде бір ғана идеалды мәтін бөлігін таңдау шарт емес. Егер 2-3 нәтиже міндетті бірдей шешсе, оларды дұрыс деп көрсету әлдеқайда адал.
Егер қазіргі индекс production-да жұмыс істеп тұрса, сол сұраулар жиынындағы оның жауаптарын да сақтап қойыңыз. Кейін сезіммен емес, нақты айырмашылықпен салыстырасыз: жаңа модель қай жерде жақсы, қай жерде нашар және қай жерде ескі векторлармен үйлесім бұзылады.
Тағы бір ереже: тесттік жиынды жұмыс барысында өзгертпеңіз. Әйтпесе модельдерді емес, әртүрлі таңдама жиындарын салыстырасыз.
Реиндекстен бұрын сапаны қалай тексеру керек
Реиндекстен бұрын ескі және жаңа модельді бірдей, мұздатылған сұраулар мен құжаттар жиынында салыстырыңыз. Егер корпус, чанк-тер немесе фильтрлерді қатар өзгертсеңіз, тесттің мәні жоғалады.
Алдымен top-k және MRR-ге қараңыз. Релевант құжат top-3 немесе top-10 ішіне жиірек кірсе, бұл жақсы белгі. MRR жауаптың жай ғана кіргенін емес, қаншалықты жоғары көтерілгенін көрсетеді.
Бірақ орташа көрсеткіш оңай алдайды. Жаңа модель жалпы цифр бойынша жақсы болып көрініп, қысқа сұрауларды, тауар кодтарын, аралас орысша-қазақша мәтінді, қате терілген сұрауларды немесе тар терминдерді бұзуы мүмкін. Сондықтан бөлек ең нашар сұраулар тізімін жинап, жаңа модель қай жерде ең көп құлағанын қараңыз.
20-30 сәтсіздікті қолмен талдау пайдалы. Көбіне себеп тез түсініледі: модель синонимдер мен аббревиатураларды нашар байланыстырады, жаңа вектор тым жалпы мәтінді тартады, өріс бойынша фильтр дұрыс нәтижені кесіп тастайды, мәселе модельде емес, чанкингте немесе метадеректе жатыр, не ұқсастық порогының ескі логикасы енді сай келмейді.
Мұндай талдау көбіне тағы бір орташа метрикадан пайдалырақ. Егер 20 сәтсіздіктің 8-і бір типтегі құжаттарға байланысты болса, қай пайплайнды түзету керегі бірден көрінеді.
Фильтрлері бар іздеуді және гибридті ранжирлеуді бөлек тексеріңіз. Таза векторлық іздеуде жаңа модель ұтуы мүмкін, ал өнім, аймақ немесе күн бойынша фильтрден кейін керекті құжаттарды жоғалтуы ықтимал. Бұл BM25, векторлар және rerank араласқан схемаға да қатысты. Лабораториялық шартта ғана емес, production-ға жақын режимде салыстырыңыз.
Ұқсастық порогы бар міндеттер үшін өз тесттері керек. Дедупликация, карточкаларды сәйкестендіру және ұқсас инциденттерге арналған алерттер top-k ішіндегі орынға емес, нақты порогқа тәуелді. Егер бұрын көшірмелер 0.82-де сенімді ажыратылса, жаңа модель жұмыс аймағын 0.74 немесе 0.89-ға жылжытуы мүмкін. Сонда іздеу қалыпты көрінеді, ал бизнес-ережелер қателесе бастайды.
Реиндекстен бұрынғы жақсы тест қарапайым көрінеді: бірдей деректер, екі модель, бірдей фильтрлер, бірдей ранжирлеу қабаты және сәтсіздіктерді қолмен тексеру. Мұндай салыстырудан кейін шешім әдетте ойланбай-ақ көрінеді.
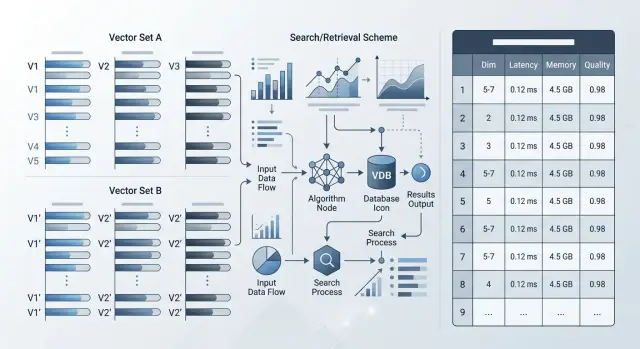
Индекс өлшемі мен жадты қалай есептеу керек
Ең қарапайым бағалаудан бастаңыз: вектор саны × эмбеддинг өлшемділігі × бір санның көлемі. float32 үшін бұл 4 байт, float16 үшін 2 байт, int8 үшін 1 байт, егер сіздің engine векторларды сол форматта сақтай алса.
Мысал: 10 млн вектор, әрқайсысы 1024 өлшемнен тұрады және float32 форматында болса, 10 000 000 × 1024 × 4 = 40,96 ГБ таза векторлық қабат береді. Егер жаңа модель өлшемділікті 768-ден 1536-ға өсірсе, бұл қабат үстеме шығындарды есептеместен-ақ екі есеге жуық ұлғаяды.
Есеп мұнымен бітпейді. Индекс жадта тек векторлардың өзін ғана ұстамайды. Іздеу графы, қызметтік өрістер, құжат ID-лері, фильтрлер және ішкі құрылымдар көбіне үстіне тағы 20–60% қосады. HNSW-дің агрессивті баптауларында одан да көп болуы мүмкін.
Төрт қабатты бөлек есептеген пайдалы:
- таза векторлар;
- индекс құрылымына кететін жад;
- метадерек және қызметтік өрістер;
- репликалар және жинау кезіндегі қор.
Репликалар картинаны ойлағаннан да қатты өзгертеді. Егер бір индекс 55 ГБ алса, бір репликамен ол шамамен 110 ГБ болады, фондық процестерді, кэштерді және сервис жадын қоспағанда. Қайта жинау кезінде көбіне тағы бір уақытша индекс керек, сондықтан ең жоғары тұтыну екі есеге жуық өсуі мүмкін.
Сосын RAM-мен ғана емес, SSD-мен де салыстырыңыз. Кей engine индексін дискіден белсенді оқиды, кейбірі бәрін дерлік жадта ұстайды, бірақ екі жағдайда да өлшемділіктің өсуі әдетте ұзақ жиналуға және түйіндер арасындағы көбірек трафикке әкеледі. Егер индекс бұрын 3 сағатта жиналса, модель ауысқаннан кейін тек дерек көлемінің өсуінен 6–8 сағатқа созылуы мүмкін.
Соңғы тексеру өте қарапайым: жаңа индекс қазіргі түйіндерге swap-сыз сыя ма. Егер жад тек қағаз жүзінде жетсе, жүйе ең ыңғайсыз сәтте баяулай бастайды. Миграция кезінде ең кемі 20–30% қор қалдырған дұрыс: жүктеме шарықтауы, фондық міндеттер және ескі векторларға кері қайту үшін.
Өз жүктемеңізде жылдамдықты қалай өлшеу керек
Жаңа модельдің жылдамдығы көбіне қысқа тестте нақты жұмыстан жақсырақ көрінеді. Оны production-та бар дәл сол құжаттарда, batch өлшемінде және параллелизм деңгейінде тексеріңіз.
Алдымен екі жағдай үшін p50 және p95 өлшеңіз: бір сұрауға бір мәтін және батчпен жіберу. Бір сұрау базалық кідірісті көрсетеді. Батчтар түнгі каталог жүктеуде, білім базасында немесе тикет архивінде не болатынын көрсетеді. Кейде модель бір құжатқа тез жауап береді, бірақ 64 немесе 128 жазбалық батчтарда қатты баяулайды.
Әдетте төрт санды бекіту жеткілікті:
- жеке эмбеддинг үшін p50 және p95;
- пакетпен эмбеддинг үшін p50 және p95;
- толық реиндекстің уақыты;
- суық және жылы кэш кезіндегі іздеу кідірісі.
Толық реиндексті 10 мың жолдық таңдамада емес, толық массивте немесе кемінде кезек, диск жүктемесі және провайдер шектеулері байқалатын үлкен бөлікте өлшеген дұрыс. Кіші тест жиі алдайды. 1 миллион құжатта бір сағатқа сыйсаңыз, 40 миллионда кенеттен storage өткізу қабілетіне тіреліп қалуыңыз мүмкін, модельдің өзіне емес.
Іздеуді де екі режимде тексеріңіз. Суық кэш таңертеңгі бірінші пайдаланушының немесе қайта іске қосудан кейінгінің көретінін көрсетеді. Жылы кэш кәдімгі жұмыс картинасына жақын. Екеуінің айырмасы кейде екі модельдің айырмасынан да үлкен.
Егер бірнеше модельді бір OpenAI-үйлесімді контур арқылы салыстырсаңыз, бір клиенттік кодты қалдырып, тек модель мен провайдерді ауыстырған ыңғайлы. Мұндай тесттер үшін AI Router сияқты бір шлюз пайдалы: SDK-ны қайта жазбайсыз және модельді бағалауды бүкіл обвязканың өзгерісімен араластырмайсыз.
Жылдамдықты іздеу сапасымен бірге қараңыз. Жаңа модель 80 мс жылдамырақ жауап беріп, бірақ top-тағы 20 релевант құжаттың 6-сын жоғалтса, мұндай көшу өзін ақтай қоюы екіталай.
Ескі векторлармен не істеу керек
Ескі векторларды жаңаларымен араластырмаған дұрыс. Егер модельдердің өлшемі әртүрлі болса, ортақ индекс схема бойынша жай ғана сәйкес келмейді. Өлшемдері кездейсоқ бірдей болса да, модельдердің кеңістігі әртүрлі, сондықтан іздеудегі көршілестікті адал деп санау мүмкін емес.
Дұрыс жол — тексеру уақытына ескі және жаңа индексті қатар ұстау. Сонда қосымша трафиктің бір бөлігі жаңа индекстен оқылады, ал ескі индекс сақтандыру ретінде қалады. Мұндай режимді бір үлкен индексті түнде қайта жинап, таңертең бәрі жұмыс істейді деп үміттенгеннен гөрі оңайырақ жөндеу керек.
Егер команда жаңа модельді AI Router арқылы сынаса, провайдерді немесе модельді API деңгейінде ауыстырған ыңғайлы. Бірақ векторлық база үшін бұл ештеңені өзгертпейді: тұрақты нәтижені нақты сұрауларда көрмейінше, ескі және жаңа векторларды бәрібір бөлек сақтау керек.
Архив пен сирек қолданылатын деректерге асықпау керек. Көбіне мына тәртіп жеткілікті:
- алдымен белсенді каталогты, білім базасын немесе жаңа құжаттарды қайта есептеу;
- архивті ескі индексте қалдыру;
- суық деректерді кесте бойынша немесе бірінші сұрауда қайта есептеу;
- ескі индексті бақылау кезеңінен кейін ғана жою.
Осылайша сіз іс жүзінде ешкім сирек іздемейтін деректерге күндер жоғалтпайсыз және тірі трафиктен сапа туралы тезірек сигнал аласыз.
Кері қайту терезесін алдын ала қалдыру керек, оны іске қосу күні ойлап табуға болмайды. Ескі индексті, ранжирлеудің ескі конфигурациясын және ауыстыруға арналған түсінікті флагты сақтаңыз. Егер жаңа шығару дәлдікті жоғалта бастаса, команда жүйені бөліп-бөліп қайта жинамай-ақ, бірнеше минутта ескі маршрутқа қайта орала алады.
Мен кері қайтуды екі шарт орындалмайынша жаппас едім: іздеу метрикалары тұрақты тұруы және support-та пайдаланушылардың жаңа шағымдары көрінбеуі. Көп команда үшін бұл 2 сағат емес, 1–2 апта.
Практикалық компромисс те бар. Егер толық қайта есептеу тым қымбат болса, ескі векторларды тек ұзын құйрықтағы құжаттарға қалдырып, күнделікті іздеуге әсер ететіннің бәріне жаңаларын қолданыңыз. Бұл мінсіз схема емес, бірақ аралас индекске және көзсіз миграцияға қарағанда әлдеқайда қауіпсіз.
Миграцияны кезең-кезеңімен қалай өткізу керек
Толық көшу сирек толық реиндекстен басталады. Кішкентай, бірақ тірі дерек срезін алған қауіпсіз: жаңа құжаттар, жиі сұраулар, күрделі тұжырымдар, көшірмелер және қысқа мәтіндер. Мұндай жиынды қайта есептеу жылдамырақ және қолмен тексеру жеңілірек.
Жұмыс тәртібі әдетте мынадай:
- оқу таңдамасында емес, нақты деректерде бөлек тесттік индекс құру;
- бірдей сұраулар ағынын ескі және жаңа индекске беру;
- тек іздеу метрикаларын ғана емес, кідірісті, индекс өлшемін және өңдеу құнын да салыстыру;
- трафикті бөліп көшіру және кері қайту шегін алдын ала қою;
- іске қосу күнін, модель версиясын және чанкинг параметрлерін жазып қою, сонда нәтижені кейін қайта қайталауға болады.
Ең жақсысы параллель прогон жұмыс істейді. Бірдей сұрау екі индекстен де өтеді, ал команда қай құжат жоғары шыққанын, іздеу қанша уақыт алғанын және шығын өспегенін қарайды. Егер жаңа модель керекті фрагментті жиірек тапса, бірақ индекс екі есе үлкейсе, бұл автоматты жеңіс болып көрінбейді.
Тәжірибеде 5% трафиктен бастап, кейін 20%-ға, одан соң 50%-ға көтеру ыңғайлы. Кері қайту шегін алдын ала анықтап қойған дұрыс. Мысалы, егер кідіріс 120 мс-тан артық өссе немесе сәтті табулар үлесі кемінде 2% төмендесе, сіз ескі маршрутқа талассыз және шұғыл қоңыраусыз қайта ораласыз.
Білім базасы үшін бұл оңай көрінеді: сізде 10 000 мақала, support-тың 300 жиі сұрауы және 500 токендік чанкингі бар ескі схема бар. Екінші индексті құрып, сол сұрауларды дәл соларға жіберіп, top-5 нәтижені салыстырасыз. Көбіне проблема модельдің өзінде емес, жаңа эмбеддинг тек басқа чанктің өлшемінде немесе мәтінді тазалауда жақсы жұмыс істейтінінде болады.
Соңында нәтижеге әсер ететіннің бәрін бекітіңіз: күнін, модель атын, версиясын, өлшемділікті, нормализацияны, чанкингті және алдын ала өңдеу ережелерін. Әйтпесе бір айдан кейін бірдей миграция неге әртүрлі сан бергенін ешкім түсінбейді.
Білім базасына арналған қарапайым сценарий
Қолдау қызметінде орысша және қазақша 50 мың мақаладан тұратын база бар. Ескі іздеу сөз сәйкестіктеріне адал ұсталады, бірақ мағынадан жиі мүлт кетеді. "Нөмір ауысқаннан кейін код келмеді" сияқты сұрау "код" пен "нөмір" туралы мақалаларды көтеріп, қолжетімділікті қалпына келтіру нұсқауын емес, мүлде басқа нәрсені көрсетуі мүмкін.
Жаңа модель әдетте мағынаны жақсырақ ұстайды, әсіресе ұзын сұрақтарда, аралас тілде және ауызекі формулировкаларда. Бірақ мұндай қадамның бағасы бар: өлшемділік өседі, индекс көбірек RAM алады, ал толық реиндекс енді ұсақ нәрсе болып көрінбейді.
Команда мұны қалай тәуекелсіз тексереді
Алдымен команда логтардан 500 тірі сұрау алады. Олардың ішінде жиі қойылатын сұрақтар, сирек тұжырымдар, орысша және қазақша сұраулар, сондай-ақ пайдаланушылар бірінші ретте жауап таппайтын бірнеше тақырып бар.
Сосын әр сұрау үшін ескі және жаңа нұсқадағы top-5 нәтижені қарайды. Бағалау қарапайым: жауап бірден табылды, пайдалы мақала бар, бірақ бірінші орында емес, шығару тақырыптан ауытқыды, немесе алғашқы бесте мүлде қажетті жауап жоқ.
Мұндай қолмен қарап шығу уақыт алады, бірақ іздеу сапасын тез көрсетеді. Осы кезеңде жаңа модель тірі базаға шынымен көмектесіп тұрғанын, әлде тек ұқыпты демо-жиында жақсы көрінетінін бірден байқайсыз.
Тексеруден кейін команда үш нәрсені жинақтайды: сапа қаншалықты өсті, жаңа индекс қанша RAM жейді және қайта есептеу қанша уақыт алады. Егер жаңа модель күрделі сұрауларды айтарлықтай жоғары көтерсе, ал жад өсімі көтерімді болса, толық реиндекс ақталады. Егер ұтыс сұраулардың аз ғана бөлігінде көрініп, индекс қатты ауырласа, асықпаған дұрыс.
Ескі векторлардың үйлесімділігіне де бөлек қарайды. Егер жаңа модель басқа өлшем берсе, ескі және жаңа векторларды бір индексте жай ғана араластыруға болмайды. Онда әдетте тест кезінде екі индексті қатар ұстайды немесе аралық ымырасыз бірден толық қайта есептеуді жоспарлайды.
Іске қосар алдындағы жиі қателер
Ең жиі қате — көшуді тым таза жиында тестілеу. Ондай жиында сұраулар қысқа, құжаттар ұқыпты, көшірме аз, ал шу нөлге жақын. Production-да адамдар қате тереді, орысша мен ағылшынды араластырады, өнім атауларын, артикулдарды және чат үзінділерін қосады. Мұны алдын ала тексермесеңіз, жаңа модель шын мәнінен жақсырақ көрінеді.
Тағы бір типтік проблема — модельді ғана емес, айналасындағы ортаны да өзгерту. Жаңа модельдің өлшемділігі басқа болуы мүмкін, онымен бірге көбіне іздеу метрикасы мен индекс баптаулары да өзгереді. Егер бұрын cosine жұмыс істесе, дәл сол параметрлер көшу кезінде де жақсы сапа береді деген сөз емес. HNSW, IVF және кандидат лимиттерін де қайта есептеу керек, әйтпесе модельдерді емес, баптаулардың кездейсоқ жиынын салыстырасыз.
Ең жаманы — бір релизде бірден екі өзгеріс шығару: жаңа модель және жаңа чанкинг. Сонда ешкім іздеуді нақты не жақсартқанын, не бұзғанын түсінбейді. Егер сапа ұзын құжаттарда төмендесе, себеп модельде емес, мәтінді тым кішкентай бөліктерге бөлгеніңізде болуы мүмкін.
Бір орташа сан да оңай алдайды. Recall@10 немесе nDCG бүкіл жиын бойынша пайдалы, бірақ олар сәтсіздіктерді жасырады. Кемінде қысқа және ұзын сұрауларға, қате терілген сұрауларға, аралас тілге, сирек терминдер мен тауар кодтарына, сондай-ақ жаңа құжаттар мен ескілерге бөлек қараңыз.
Тағы бір практикалық ереже: ауысқан күні ескі индексті жоймаңыз. Оны кемінде параллель прогон мен жылдам кері қайту уақытына қалдырыңыз. Егер кешке іздеу дәл келетіннің орнына тек жуық жауаптарды қайтара бастаса, резервтік индекс көп сағат пен бірнеше жағымсыз қоңырауды үнемдейді.
Қысқа чек-лист және келесі қадамдар
Іске қосар алдында тек жаңа модельді ғана емес, оның айналасындағы бүкіл келісімді де бекітіңіз. Егер өлшемділік, іздеу метрикасы, чанкинг схемасы немесе кіріс мәтіннің лимиті өзгерсе, іздеудің мінез-құлқы да өзгереді. Осы параметрлердің біреуі шетке шықса да, жақсы модель нашар нәтиже беруі мүмкін.
Шешімді бірнеше порогқа түсіріп, сезімге сүйеніп дауласпаңыз. Командада сандар болуы керек: тесттік жиындағы сапаның төменгі шегі, кідірістің жоғарғы шегі, жадтың рұқсат етілген шығыны және мың құжатқа немесе сұрауға кететін баға. Порогтар алдын ала жазылса, пилотты тоқтату да, мақұлдау да оңайырақ.
Іске қосудың алдында мына қысқа тізімнен өтіп шығыңыз:
- бірінші тестке дейін өлшемділікті, метриканы, чанкингті және кіріс лимиттерін растау;
- сапа, кідіріс, жад және баға бойынша шектерді бекіту;
- кері қайту жоспарын дайындау: трафикті кім қайта қосады, ескі индекс қанша уақыт тұрады, snapshot-тар қайда сақталады;
- пилоттан кейін жартылай іске қосу күнін, трафик үлесін және search, infrastructure және product жауаптыларын белгілеу.
Егер бірнеше провайдерді салыстырсаңыз, тесттерді бір OpenAI-үйлесімді шлюз арқылы өткізіңіз. Қазақстан мен Орталық Азиядағы командалар үшін мұны AI Router арқылы жасау ыңғайлы: api.airouter.kz-ке base_url ауыстырып, бір клиенттік контурда модельдерді салыстыруға болады, SDK, код пен промпттарды қайта жазбай-ақ.
Бірден екі міндетті араластырмаңыз: модельді ауыстыру мен жеткізушіні ауыстыру. Егер бәрін бірге өзгертсеңіз, кейін іздеу сапасын не бұзғанын немесе жүйені не баяулатқаныны анықтау қиын болады. Бірдей тесттік контур көп уақыт үнемдейді.
Ескі индексті іске қосқан күні жоймаңыз. Оны пайдаланушылардың әдеттегі сценарийлерінен өтуіне жететін уақытқа қалдырыңыз: білім базасын іздеу, ұзын сұраулар, сирек терминдер, аралас тіл. Бұл көбіне түнгі шұғыл реиндекстен сақтап қалады.
Егер пилот қалыпты өтсе, бүкіл трафикті бірден көшірмеңіз. Жаңа модельге жүктеменің бір бөлігін беріп, бірнеше күн метриканы жинап, содан кейін ғана түпкілікті шешім қабылдаңыз. Тәсіл қызықсыз көрінгенімен, әдетте ең арзан әрі ең қауіпсізі.
Жиі қойылатын сұрақтар
Ескі және жаңа векторларды бір индексте ұстауға бола ма?
Жоқ. Өлшемі бірдей болса да, ескі және жаңа модельдер әдетте мәтінді әртүрлі кеңістікте кодтайды. Сол себепті нәтиже құбылып кетеді: бүгін сұрау бір нәрсені табады, ертең басқа нәрсені.
Миграция алдында қандай тесттік жиын керек?
Ең кемі тірі іздеу, қолдау қызметі немесе RAG-логтарынан алынған сұрауларды алыңыз. Әдетте 100–300 мысал жеткілікті, егер жиында қысқа сұраулар, қате терулер, сирек тұжырымдар және орыс, қазақ, ағылшын терминдерінің араласуы болса.
Реиндекстен бұрын қандай метрикаларды тексерген дұрыс?
Тек орташа метрикаға қарамаңыз. Top-k, MRR-ді салыстырып, кейін 20–30 ең нашар сұрауды қолмен талдаңыз. Сонда жаңа модель релевантты құжаттарды қай жерде жоғалтатынын түсінесіз.
Неге ескі ұқсастық порогы жұмысын тоқтатады?
Себебі жаңа модель қашықтықтардың таралуын өзгертеді. Бұрын шуды жақсы алып тастап тұрған threshold миграциядан кейін артық нәтижені өткізіп жіберуі немесе керісінше пайдалы сәйкестіктерді кесіп тастауы мүмкін.
Жаңа индекс жадқа сыятынын алдын ала қалай түсінуге болады?
Алдымен векторлардың таза көлемін есептеңіз: вектор саны × өлшемділік × бір санның көлемі. Одан кейін индекс құрылымы, метадерек, репликалар және қайта жинау кезіндегі уақытша индекс үшін қор қосыңыз.
Жылдамдықты кіші таңдамада салыстыру жеткілікті ме?
Жоқ, толық емес. Бір реттік сұраулар мен батчтар үшін p50 және p95-ті, сондай-ақ боевой көлемге жақын деректерде толық реиндекс уақытын тексеріңіз. Кіші сынамада модель көбіне нақты жүктемеден жылдамырақ көрінеді.
Модельмен бірге чанкинг пен іздеу метрикасын да өзгерту керек пе?
Жоқ, бір ғана нәрсені өзгерткен дұрыс. Егер модельді, чанкингті, метриканы және индекс баптауларын қатар өзгертсеңіз, кейін өсімді не бергенін, не іздеуді бұзғанын түсіну қиын болады.
Фильтрлермен және гибридті ранжирлеумен іздеуді тексеру керек пе?
Оны бөлек, продта жұмыс істейтін сол фильтрлермен және сол пайплайнмен тексеріңіз. Жаңа модель таза векторлық іздеуде ұтуы мүмкін, бірақ product, date немесе region бойынша фильтрден кейін ұтылып қалуы ықтимал.
Жаңа модельді продта қалай қауіпсіз іске қосуға болады?
Жұмыс істейтін тәсіл — екі индексті қатар ұстап, трафикті бөліп көшіру. Сонда тірі сұрауларда нәтижені тез салыстырып, түнде қайта есептемей-ақ кері қайта аласыз.
Миграциядан кейін ескі индексті қашан жоюға болады?
Жұмысқа қосқан күні емес. Старый индекс кемінде бірнеше күн тұрсын, ал жақсысы — метрика тұрақталғанша және қолдау қызметі жаңа шағымдар көрмегенше. Көп команда үшін бұл бір-екі апта алады.