Провайдерлердегі әртүрлі токенизаторлар: неге сандар сәйкес келмейді
Провайдерлердегі әртүрлі токенизаторлар бағаға, лимиттерге және контексттің нақты ұзындығына әсер етеді. Есептеулер қай жерде айырмашылық беретінін және оны алдын ала қалай тексеруге болатынын қарастырамыз.
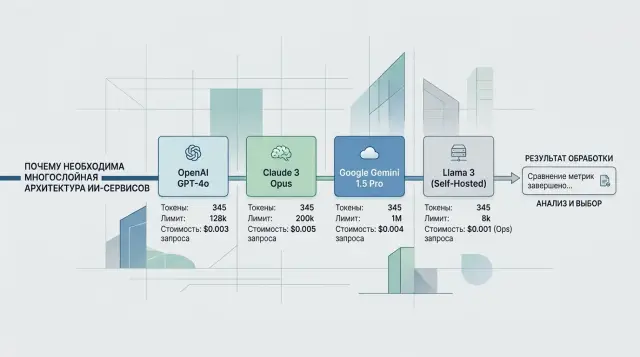
Неге бір жол әртүрлі сан береді
Бір ғана сөйлемнің өзіне тұрақты, “өзіндік” токен саны болмайды. Модель мәтінді адам сияқты тұтас оқымайды. Ол жолды токенизатор ережелері бойынша бөліктерге бөледі, ал бұл ережелер провайдерлер мен модельдерде әртүрлі.
Сондықтан “Тапсырыс статусын 15482 тексер” сияқты қысқа сұраныс бір backend-та бір сан токен алып, екіншісінде едәуір көбірек болуы мүмкін. Айырмашылық әсіресе орысша мәтінде, аралас тілде, JSON-да, кодта, даталарда, эмодзиде және бос орын не тығыз пунктуация бар жолдарда жиі байқалады.
Мәселе тек мәтіннің өзінде емес. Чат-модельге “жалаң” жол өте сирек беріледі. Провайдер сұранысты қызметтік бөліктермен орайды: хабарлама рөлдері, system нұсқаулар, жауап форматы, tools сипаттамалары, ал кейде structured output үшін схема да қосылады. Команда кодта бір репликаны көреді, ал биллинг әлдеқайда ұзын басқа пакетті санайды.
Әдетте айырмашылық үш жерден шығады: токенизатор сөздер мен таңбаларды әртүрлі бөледі; API chat, tools және response format үшін жасырын қабат қосады; backend хабарламаларды модельге жіберер алдында өзше сериализациялайды.
Сондықтан бірдей prompt тек логтарда әртүрлі цифр бермейді. Ол сонымен бірге контексттің әртүрлі бөлігін алады. Бұл сіз контекст терезесінің шегіне жақын істегенде, ұзын диалог тарихын жібергенде немесе үлкен JSON қоса бергенде маңызды. Бір провайдерге “сыйған” нәрсе екіншісінде шекке ертерек тірелуі мүмкін.
Осы жерде командалар жиі шатасады. Әзірлеуші локалдық токен санағышқа қарап, 7 800 көреді де, қор қалдырдым деп ойлайды. Сосын тек base_url-ды AI Router сияқты үйлесімді backend-ке ауыстырып, сол SDK мен сол prompt-тарды қалдырады, бірақ нақты сұраныста басқа сан шығады. Код та, жол да өзгермеген. Өзгергені — жүйенің оны токенге айналдыру тәсілі.
Бұл тақырып тез арада теория болудан қалады. Ол контекст ұзындығына, сұраныстың болжамдылығына және сіздің есептеулеріңіз провайдердің кейін көрсететін цифрымен сәйкес келуіне тікелей әсер етеді.
Токен айырмасы қайдан пайда болады
Модель үшін жол “қалай болса, солай” өмір сүрмейді. Алдымен токенизатор оны модель жұмыс істейтін бөліктерге бөледі. Айырмашылық дәл осы жерден басталады: бір токенизатор сөзді тұтастайға жуық ұстап қалса, екіншісі оны бірнеше бөлікке бөледі.
Орыс тілінде бұл көп адам күткеннен де анық көрінеді. Кириллицадағы сөздер, “счет 2457 по договору” сияқты аралас мәтін, даталар, тырнақшалар, жақшалар, тіпті артық бос орын да ағылшын тіліндегі ұқсас тіркеспен салыстырғанда басқа сан беруі мүмкін. Адам үшін қысқа жол модель үшін қалай бөлінетініне қарай ұзын болып шығуы ғажап емес.
Нақты нені өзгертеді
Қорытынды тек сөздерге байланысты емес. Жалпы көлемге әдетте модельге жіберетіннің бәрі кіреді: system хабарламасы, system және user сияқты рөлдер, өріс атаулары бар JSON-қаптама, structured output немесе tool calling үшін schema, сондай-ақ провайдердің өзінен келетін қызметтік токендер.
Сондықтан командалар көбіне тек prompt мәтінін қарап, сұраныстың шынайы көлемін төмен бағалайды. Қағаз жүзінде сізде 700 таңба болуы мүмкін, ал іс жүзінде модель әлдеқайда көп токен көреді.
Тағы бір қабат бар. Провайдерлерде тек токен сөздігі ғана емес, хабарламаны қаптау тәсілі де әртүрлі. Екі API сыртынан сұраныс пішімі бойынша үйлесімді болып көрінуі мүмкін, бірақ бұл олардың көлемді бірдей есептейтінін білдірмейді. OpenAI API үйлесімділігі тек сұранысты ұқсас тәсілмен жіберуге болатынын айтады. Ол бірдей токенизаторға, бірдей қызметтік токендерге немесе бірдей биллингке кепіл бермейді.
Бұл көп провайдерлі сценарийде анық байқалады. Команда бірдей OpenAI-үйлесімді сұранысты AI Router арқылы әртүрлі модельдерге жібереді де, код өзгермесе де, usage-тың басқа мәнін көреді. Әдетте бұл баг емес. Әр backend мәтінді өзше бөледі және хабарламаларды өзше жинайды.
Ең ыңғайсыз жағдай — structured output. Schema неғұрлым қатаң болса және өріс атаулары неғұрлым ұзын болса, көлем соғұрлым өседі. Кейде JSON-дағы бірнеше “ыңғайлы” өріс қолданушының сұрағынан да көп токен алады.
Бұл баға мен лимитке қалай әсер етеді
Бірдей жол бір backend-та 900 токен, ал екіншісінде 1100 токен алуы мүмкін. Алғаш қарағанда айырма шағын сияқты, бірақ жұмыс сценарийінде ол бюджет пен контекст қорын тез жеп қояды.
Лимиттерде бұл бірден сезіледі. Егер сіз system prompt, диалог тарихы, RAG-тен алынған бес фрагмент және жауапқа орын қалады деп жоспарласаңыз, токендердің қосымша 10–20%-ы бүкіл жоспарды бұзады. Енді бес фрагмент емес, үшеуі ғана сыяды. Немесе тарихты қысқартуға тура келеді де, бот әңгіменің маңызды бөлшектерін жоғалтады.
OpenAI API үйлесімділігі болса да, бұл жоғалып кетпейді. Команда тек base_url-ды ауыстырып, сол SDK мен сол кодты қалдыруы мүмкін, бірақ токен санау бәрібір нақты модель мен провайдерге тәуелді болады.
Ақшалай әсері одан да қатты байқалады. Биллинг көбіне кіріс және шығыс токендерге байланған, сондықтан бір сценарийдің құны өнім өзгермесе де ауысады. Егер сервис күніне 200 000 сұраныс жасаса, ал жаңа backend сұранысқа орта есеппен 150 кіріс токен қосса, бұл күніне 30 млн артық токен деген сөз. Бір айда мұндай сома “дәлсіздік” деп өткізе салатын деңгейден әлдеқайда өсіп кетеді.
Сапаға әсері де бар. Prompt контекст лимитіне тым жақын толса, жауапқа аз орын қалады. Модель қысқа жауап береді, ойын ортасында тоқтайды немесе қадамдар тізімін толық шығарып үлгермейді. Сырт көзге “модель нашарлап кеткендей” көрінеді, бірақ шын мәнінде оған жауапқа арналған терезе жетпей қалған.
Бұл көбіне тарихы 10–20 хабарламаға созылатын ұзақ диалогтарда, үлкен құжат үзінділері бар RAG сценарийлерінде, функция схемасы бар tool calling-де және жауап ең кемі белгілі бір деңгейде ұзын болуы тиіс тапсырмаларда байқалады. Мысалы, қолдау қызметінде немесе комплаенсте.
Токенизациядағы айырмашылық логтардағы санағышты ғана өзгертпейді. Ол нақты қанша контекст сыйатынын, сұраныс қанша тұратынын және модель жауапты сіз күткеннен бұрын қай жерде қысқарта бастайтынын өзгертеді.
Қолдау ботының мысалы
Интернет-дүкеннің қолдау ботында күрделі prompt болмауы мүмкін, бірақ мұндай сценарийдің өзі күткен нәтижені оңай бұзады. Әр сұраныста ол жауап беру ережелері бар system нұсқауын, клиенттің хабарламасын және бот алмастыру ретінде ұсына алатын үш тауар карточкасын жібереді.
Клиент: “eSIM және жылдам жеткізілімі бар смартфон керек” деп жазады. Бірінші модель толық пакетті алады. Ол үш карточканың бәрін көреді, жеткізу мерзімін, жадын және бағасын салыстырады да, бірнеше сөйлеммен түсінікті жауап береді.
Екінші модель шамамен сол мәтінді алады, бірақ оны басқа түрде санайды. Орысша сөздерді, артикулдарды, тырнақшаларды, сандарды, JSON бөліктерін және бренд атауларын ол көбірек токенге бөледі. Соның нәтижесінде контекст терезесіне соңғы карточка сыймай қалады. Қолданба сұраныстың құйрығын қиып тастайды да, модель тек екі тауар бойынша ғана жауап береді. Сырт көзге бот каталогтың бір бөлігін “ұмытып қалғандай” көрінеді.
Көзге ештеңе өзгермеген сияқты. Әзірлеуші логтарда сол бір жолдарды көреді. Менеджер сол шаблонды көреді. Бірақ іс жүзінде екі нәрсе қатар өзгереді: кіріс қымбаттайды, өйткені провайдер көбірек токен санады, ал жауап қысқарады, өйткені ұзын кірістен кейін шығысқа аз орын қалады.
Айырма тіпті аз көлемде де жағымсыз болуы мүмкін. Бір провайдерде сұраныс, мысалы, 1450 токен алса, екіншісінде 1680 токен алуы мүмкін. Егер лимит жақын тұрса, сол 230 токен жауапқа арналған қорды жеп қояды. Бот қысқалау жаза бастайды, детальдарды өткізіп жібереді немесе нақтылау сұрағын қоюды тоқтатады. Команда мұны жиі “әлсіз” модельге жаба салады, ал мәселе басқа жерде.
Практикада осы тарих осылай көрінеді: бірдей жол әртүрлі шығын береді, контекст қалдығы да басқа, нәтиже де басқа. Команда ішіндегі дау тез бұрыс бағытқа кетеді. Біреу модель ауыстыруды ұсынады, біреу жүйелік нұсқауды қысқартқысы келеді, үшіншісі тауар каталогын кінәлайды. Ал ең алдымен оңай нәрседен бастау керек — әр backend-та токеннің қалай саналатынын нақты салыстыру қажет.
Қолдауда бұл бірден сезіледі, өйткені бір шаблон күніне мыңдаған рет іске қосылады. Бір диалогқа қосылған бірнеше жүз токен бір айдың ішінде елеулі шығынға да, клиент дәл кеңес күткен жерде қысқа жауапқа да айналады.
Командалар қай жерде жиі қателеседі
Бірінші қате қарапайым: команда локалдық токен санау скриптін алып, цифраны шындық деп қабылдайды. Шамалап бағалау үшін бұл дұрыс. Бірақ продакшен үшін жетпейді, өйткені провайдер сұранысты тест ноутбугыңыз емес, өзінің backend-і қалай көрсе, солай есептейді.
Дәл осы жерде үйреншікті есептер бұзылады. Бірдей мәтін сыртынан API бірдей көрінсе де, екі модельде әртүрлі токен алуы мүмкін.
Көбіне қателік пайдаланушының тек кіріс мәтінін ғана қараудан басталады. Бірақ санау әдетте әлдеқайда кең. Оған system prompt, диалог тарихы, structured output үшін schema, tools сипаттамалары және SDK не шлюз өзі қосатын қызметтік өрістер кіреді.
Сондықтан “Тапсырысым қайда?” сияқты қысқа сұрақ нақты жүктеме туралы онша ештеңе айтпайды. Қасында ұзын system prompt пен екі экрандай JSON schema жатса, сұраныстың нақты көлемі бірнеше есе өсіп кетуі мүмкін.
Екінші жиі қате — тек input-ты санап, output-ты ұмыту. Команда кіріс лимитке сыятынын көріп, тынышталады. Кейін модель күткеннен ұзақ жауап береді де, сұраныс не қымбаттайды, не лимитке тіреледі, не жауап ыңғайсыз жерде қысқарып қалады.
Бұл әсіресе қолдауда байқалады. Мысалы, бот орысша хабарлама, ағылшынша артикулдар, сандары бар мекенжай және соңынан үлкен JSON беретін tool шақыруын алады. Қысқа тесттерде бәрі жақсы көрінеді. Ұзын диалогта цифрлар басқаша: кириллица, аралас мәтін және үлкен JSON блоктары токенге әлдеқайда болжамсыз бөлінеді.
Әдеттегі қателер қайталана береді:
- баға мен лимитті тек локалдық токенизатор бойынша салыстырады, провайдер жағында тексермейді;
- модель жауабын қоспай, бір ғана сұранысты өлшейді;
- есепке system prompt, tools және schema-ны қоспайды;
- 1–2 жолдық тіркестерді тексеріп алып, сол қорытындыны 20 хабарламалық диалогтарға көшіреді;
- тек таза мәтінді сынап, кириллица, JSON, кестелер мен аралас тілді тексермейді.
Егер сіз AI Router сияқты үйлесімділік қабаты арқылы жұмыс істесеңіз, азғыру одан да күшті: endpoint біреу, ал модель backend-і бөлек. Сондықтан тексеру “API бойынша орташа” емес, нақты модельдерде, нақты payload-тармен және күтілетін жауап ұзындығымен жүргізілуі керек. Әйтпесе құн мен қолжетімді контекст жоспардан бірінші аптаның өзінде-ақ ауытқиды.
Іске қоспай тұрып қалай тексеру керек
Тек тесттік сөйлеммен тексеру көбіне жалған тыныштық береді. Айырмашылықтар ең қатты қысқа мысалдарда емес, жүйелік prompt, диалог тарихы, JSON schema және ұзын жауап форматы бар нақты сұраныстарда көрінеді.
Модельден емес, өз ағыныңыздан бастаңыз. Логтардан немесе күтілетін сценарийлерден 10–20 нақты сұраныс алыңыз. Жиын әртүрлі болсын: қысқа сұрақтар, ұзын өтініштер, сандар бар мәтін, кестелер, аттар, тапсырыс кодтары және орысша мен ағылшынша аралас мәтін.
Әр тестке продқа кететіннің бәрін қосыңыз: толық system мәтінін, рөл мен стиль бойынша нұсқауларды, schema немесе қатаң JSON форматты, егер өніміңізде болса, хабарламалар тарихын және тек кіріс мәтінін емес, күтілетін жауап көлемін де.
Айырмашылық көбіне дәл осы жерде бұзылады. Команда тек пайдаланушы хабарламасын санап, контекст лимиті неге ертерек бітетінін түсінбей қалады. Іс жүзінде көлемнің елеулі бөлігін жүйелік нұсқаулар мен қызметтік қабат жеп қояды.
Содан кейін сол бір жиынды әр backend арқылы өткізіңіз. Тек кірісті емес, үш санды салыстырыңыз: кіріс токендер, шығыс токендер және жалпы шығын. Егер бір backend мәтінді көбірек токенге бөлсе, оны бірден баға мен жауап ұзындығынан көресіз.
Жақсы, қарапайым тест — қолдауға арналған 700–900 таңбалық сұраныс, 1–2 беттей system prompt және status, reason, next_step өрістері бар JSON жауабы. Бір модельде мұндай пакет қорымен өтеді, екіншісінде жауап генерациясына дейін-ақ лимитке жақындап қалады.
Релиз алдында қор қалдырыңыз. Көбіне контекст бойынша 15–25% жеткілікті, ал бюджет үшін бір сұранысқа бөлек шек ұстаған дұрыс. Егер орташа шығын қалыпты болып, бірақ 2–3 ұзын кейс қатты ауытқыса, оны елемеңіз. Дәл сондай сұраныстар кейін жауаптың үзілуін, артық қайталауды және күтпеген шотты береді.
Егер сіз AI Router сияқты біртұтас шлюз арқылы жұмыс істесеңіз, бұл тексеруді SDK мен кодты өзгертпей-ақ бірнеше провайдерде қайталау оңайырақ. Бірақ құралдан маңыздысы — тәртіп: модельді жеке өзі емес, продқа нақты қалай кетсе, сол қалпында толық сұранысты тексеріңіз.
Ауытқуды қалай бақылауда ұстауға болады
Ауытқуды толық жою мүмкін емес. Бірдей мәтін бәрібір әртүрлі бөлінеді. Бірақ сұраныс формасы тұрақты болса, ауытқуды болжамды етуге болады.
Көп жағдайда токенді өсіретін нәрсе тапсырманың өзі емес, оның айналасындағы шаблон. Командалар ережелерді system prompt-та қайталайды, кейін developer message-ке қайта жазады, сосын тағы пайдаланушы нұсқауына салып қояды. Егер ереже бір рет жазылып, модель соны орындай алса, екінші және үшінші қайталау көбіне тек контекстті жейді.
RAG-та да ұқсас жағдай. Индекске ұзын фрагменттерді оңай салуға болады, бірақ сұранысқа тек жауапқа нақты көмектесетінін ғана жіберген дұрыс. Бес үлкен мәтіннің орнына екі қысқа, нақты фактісі бар үзінді жиі тиімдірек. Қолдау ботында бұл бірден көрінеді: білім базасынан қосылған артық бір бөлік кейде жауаптың өзінен де қымбатқа түседі.
Тағы бір оңай шара — тесттер арасында system prompt форматын өзгертпеу. Егер бір модель қысқа нұсқаулықпен, ал екіншісі ұзын әрі қайта жазылған мәтінмен тексерілсе, салыстыру бұзылады. Айырмашылықтың backend-тен бе, әлде шаблоннан ба шыққанын түсіне алмайсыз.
Нені бөлек санау керек
Tools, JSON және ұзын тарихы бар сценарийлерді бірге емес, бөлек өлшеген дұрыс. Дәл осы жерлерде токен мен лимит бойынша сандар көбірек айырмашылық береді.
Қысқа тұрақты тест жиынын ұстаған пайдалы: тарихсыз қысқа сұрақ, 10–15 хабарламалық диалог, аргументтері бар tools шақыруы, қатаң JSON жауабы және RAG-вставкалары бар сұраныс.
Әр модель немесе маршрут ауысқан сайын осы жиындағы жалпы токен өсімін белгілеңіз. Тек орташа санға емес, шеткі жағдайларға да қараңыз. Егер жаңа backend кіріс токендерге 7–10% қосса, бұл айлық бюджетті жылжытуға немесе ұзын диалогтардың қысқаруына жетіп жатыр.
Егер команда модельдерді AI Router сияқты біртұтас OpenAI-үйлесімді шлюз арқылы ауыстырса, осындай өлшеуді маршрут ауысқаннан кейін бірден жасау ыңғайлы. Сонда тек модель жауабы өзгерді ме, әлде prompt, tools және шығару форматына кеткен қызметтік шығын да өсті ме — соны көруге болады. Бұл жалықтыратын тәртіп, бірақ продта көп ақша мен жүйкені үнемдейді.
Релиз алдындағы жылдам чек
Іске қосар алдында орташа сұранысқа емес, ең ауыр сценарийге қараңыз. Ішінде JSON, чат тарихы және tool сипаттамасы бар бір ұзын диалог шектен асып кетуі мүмкін, ал қарапайым хабарламалар еш қиындықсыз өтеді.
Жақсы тәжірибе қарапайым: нақты өнімдегі ең ұзын 10–20 сценарийді жинап, продқа шығатын backend арқылы өткізіңіз. Тек песочницадан алынған қысқа тесттерге сүйенбеңіз. Олар әдетте тым тыныш сурет береді.
Тек кәдімгі мәтінді емес, токенге қатты әсер ететін нәрселерді де тексеріңіз: кириллица, ұзын сандар, артикулдар, кестелер, код бөліктері және JSON-құрылымдар. “Тапсырыс нөмірі 000184750029” деген хабарлама мен осы ойдың ауызекі нұсқасы адамға көрінбесе де, әртүрлі көлем алуы мүмкін.
Әр команда жиі ұмытып кететін нәрсені бөлек есептеңіз: system prompt пен жасырын қызметтік өрістер, tools және function calling үшін schema, егер JSON сұрасаңыз, жауап форматы, қолданба өзі қосатын чат тарихы, сондай-ақ қателер, қайта жіберулер және қызметтік кірістірмелер мәтіні.
Тек жалаң пайдаланушы сұранысын қалдырсаңыз, бағалау дерлік міндетті түрде төмен болып шығады. Содан кейін модель контекстті қысқарта бастайды, күткеннен қысқа немесе қымбатырақ жауап береді.
Контекст терезесіндегі қор да қажет. Әдетте 10–20% жеткілікті, ал күрделі тізбектер үшін одан да көбірек қалдырған жөн. Егер тестте сұраныс 128 мың лимит кезінде 115 мың токен алса, бұл қазірдің өзінде тар. Кез келген қосымша кесте, JSON-дегі жаңа өріс немесе құралдың ұзын жауабы қалған орынды жеп қояды.
Егер backend-ті үйлесімді OpenAI API арқылы ауыстырсаңыз, код өзгермесе де, бәрін қайта тексеріңіз. AI Router-да сол SDK мен сол сұранысты сақтауға болады, бірақ нақты модельдегі есептеу бәрібір басқаша болуы мүмкін.
Іске қосқаннан кейін қолмен тексеруге сүйенбеңіз. Кіріс пен шығыс токендеріне, контекст шегіне жақын сұраныстар үлесіне және модель бойынша шығынның күрт өсуіне метрика қойыңыз. Бірінші күндегі alert бір аптадан кейінгі инцидентті талдаудан пайдалырақ.
Жақсы финалдық тест жалықтырып жіберетіндей көрінеді, бұл жақсы белгі. Егер ұзын сұраныстар өтіп, JSON бюджетті ісіндірмей, токен графигі себепсіз секірмесе, релиз әдетте тыныш өтеді.
Келесі қадам не болуы керек
Алдымен команда ішінде токенді немен өлшейтініңізге келісіп алыңыз. Әйтпесе әзірлеуші локалдық токенизаторға қарайды, қаржы маманы провайдердің шотына қарайды, ал SRE контекст лимиті қатесіне қарайды. Үшеуінің цифры әртүрлі, мұнда дауласып пайда жоқ.
Көбіне бір эталон алып, оны жұмысқа бекіткен дұрыс. Биллинг үшін бұл әдетте сұранысты өңдеген backend-тің нақты usage дерегі. Ерте бағалау үшін локалдық есепті қолдануға болады, бірақ оның жанына бұл тек болжам екенін анық жазып қойған жөн.
Егер сізде қазірдің өзінде бірнеше провайдер болса, бәрін бір “идеал” санға түсіруге тырыспаңыз. Одан да қарапайым ереже енгізіңіз: баға мен лимит бойынша шешімді команда модельдің нақты жауабы мен продакшен логтарының дерегіне сүйеніп қабылдайды.
Қысқа жұмыс чегі де керек. Бір эталон санауды таңдап, оны құжатта бекітіңіз. Модель ауысқаннан кейін бірдей сұраныстар жиынын өткізіп, usage-ты салыстырыңыз. Провайдер ауысқанда бағаны, жауаптың қысқаруын және контекст қорын бөлек тексеріңіз. Аптасына бір рет ең қымбат сценарийлерге қарау үшін input tokens, output tokens және лимит қателері бойынша дашборд ұстаңыз.
Мәселелер көбіне backend-ті үнсіз ауыстырғаннан кейін шығады. Кеше қолдау боты 12 мың токенге сыйып тұрса, бүгін басқа провайдерде сол диалог кенет лимитке жақындайды. Код та, мәтін де өзгермеген, бірақ токенизация басқа. Мұндайды пайдаланушылар шағымданғаннан кейін емес, нақты сұраныстардан құралған тест жиынында ұстаған дұрыс.
Егер трафикті бірнеше провайдер арқылы жіберсеңіз, бір OpenAI-үйлесімді endpoint ұстап, әр маршруттың шығынын бір жерде салыстырған ыңғайлы. Мысалы, AI Router бірдей payload-тарды әртүрлі маршрут арқылы SDK мен кодты өзгертпей өткізуге мүмкіндік береді, ал Қазақстандағы компаниялар үшін ай сайын теңгемен B2B инвойсинг береді. Бұл өз сұраныстарыңызда тексеруді алмастырмайды, бірақ backend-терді салыстыруды әлдеқайда жеңілдетеді.
Ең пайдалы келесі қадам қарапайым: 20–30 нақты prompt алыңыз, қолданғыңыз келетін барлық модельдерден өткізіңіз де, әр іске қосуға төрт санды сақтаңыз — input, output, жалпы баға және контекст лимитіне дейінгі қор. Осыдан кейін даулы жерлер әдетте қалмайды.
Жиі қойылатын сұрақтар
Неге бірдей жол әртүрлі токен санын береді?
Себебі токен саны тек мәтінге ғана байланысты емес. Әр модельдің өз токенизаторы бар, ал провайдер оған қоса қызметтік қабатты қосады: рөлдер, system prompt, schema, tools және жауап форматы.
Сондықтан бірдей жол екі backend-та әртүрлі пакетке айналады, ал биллинг енді сол пакетті есептейді.
Неге локалдық токенизатор көбіне провайдер цифрларымен сәйкес келмейді?
Локалдық есептегіш әдетте тек сіздің мәтініңізді немесе сұраныстың жеңілдетілген нұсқасын көреді. Провайдер болса SDK, API және backend арқылы жинақталғаннан кейін модельге нақты жіберілген нәрсені санайды.
Алдын ала шамалау үшін локалдық есеп жарайды, бірақ соңғы баға мен контекст көлемін провайдердің нақты usage дерегімен тексерген дұрыс.
Провайдер мәтіннен басқа сұранысқа нені қосады?
Көбіне санауға хабарлама рөлдері, system prompt, диалог тарихы, JSON-қаптама, tools сипаттамалары және structured output үшін schema кіреді. Кейде backend хабарламаларды жіберер алдында сериализациясын да өзгертеді.
Сондықтан пайдаланушының қысқа сұрағы толық сұраныстың көлемі туралы онша көп нәрсе айтпайды.
Токен айырмасы қай мәтін түрлерінде қаттырақ көрінеді?
Айырмашылық әсіресе орысша мәтінде, орысша-ағылшынша аралас мәтінде, JSON-да, кодта, даталарда, ұзын сандарда, артикулдарда, тырнақшаларда, жақшаларда және тығыз пунктуацияда қатты байқалады. Эмодзи мен артық бос орындар да есепті оңай өзгертеді.
Егер сізде қолдау, RAG немесе tool calling болса, дәл осындай деректерді тексеріңіз, тек екі-үш жолдық таза мәтінді емес.
Бұл контекст лимитіне қалай әсер етеді?
Өте қарапайым: дәл сол сұраныс контекст терезесінде көбірек орын алады. Егер сіз лимитке жақын жұмыс істеп жүрсеңіз, тарихтың бір бөлігі, RAG-фрагменттері немесе JSON сыймай қалуы мүмкін.
Сондықтан қосымша мәтін келгенде қолданба сұраныстың соңын күткеннен бұрын қысқарта бастайды, ал кодтағы prompt өзгермесе де, нәтиже өзгереді.
Сондықтан модель қысқарақ жауап беруі мүмкін бе?
Иә, бұл жиі болады. Кіріс көбірек токен алса, жауапқа аз орын қалады, сондықтан модель қысқалау жазады немесе ойын ортасында тоқтатып тастайды.
Сырт көзге бұл әлсіз модель сияқты көрінеді, бірақ себеп көбіне сұраныстың терезенің тым үлкен бөлігін алып қойғанында.
Нақты цифрларды іске қоспай тұрып қалай тексеремін?
Тесттік фразамен емес, өнімдегі 10–20 нақты сценариймен тексеріңіз. Әрқайсысының толық payload-ын өткізіңіз: system prompt, тарих, tools, schema және күтілетін жауап ұзындығын.
Әр модель бойынша кіріс токендерін, шығыс токендерін, жалпы бағаны және лимитке дейінгі қорды салыстырыңыз. Сонда айырмашылық релизге дейін көрінеді, шағымнан кейін емес.
Контекст бойынша қандай қор қалдырған дұрыс?
Көп жағдайда контекст бойынша 15–25% қор жеткілікті. Егер сізде ұзын диалогтар, үлкен фрагменттері бар RAG немесе үлкен JSON-ды tools болса, көбірек қор қалдырыңыз.
Тестте сұраныс шекке тым жақын тұрса, кез келген жаңа дерек есепті тез бұзады.
Тек base_url-ды ауыстырып, кодқа тимесем не істеймін?
Барлығын қайта тексеріңіз, сол бірдей нақты сұраныстар жиынымен. Үйлесімді API код пен SDK-ны сақтайды, бірақ бірдей токенизаторды, хабарламаларды бірдей қаптауды және бірдей usage-ты уәде етпейді.
Қолданба қате бермей жұмыс істеп тұрса да, баға мен жауаптың қолжетімді ұзындығы айтарлықтай өзгеруі мүмкін.
Продтағы токен ауытқуын қалай азайтуға болады?
Сұраныс формасын тұрақты етіңіз. Бір ережені бірнеше жерге қайталамаңыз, артық JSON-ды қысқартыңыз және RAG-қа жауапқа шынымен көмектесетін фрагменттерді ғана жіберіңіз.
Тағы бір пайдалы тәсіл — тұрақты тест жиыны. Әр модельді немесе маршрутты ауыстырған сайын бірдей payload-тардағы шығынды салыстырып, input, output және лимит қатесіне метрика қойыңыз.