Сыртқы LLM-провайдері істен шықса: бір күндік әрекет жоспары
Сыртқы LLM-провайдер істен шыққанда бір күнде қалай әрекет ету керек: маршрутты ауыстыру, лимит енгізу, функцияларды қысқарту және командаларды тез хабардар ету бойынша қадамдық жоспар.
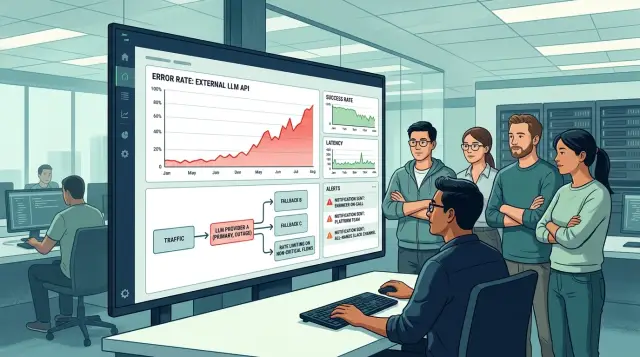
Алғашқы минуттарда не бұзылады
Әдетте бірінші болып жауап бірден керек болатын сценарийлер істен шығады: support chat, операторға арналған кеңес, жауап генерациясы бар search, жіберер алдында мәтінді тексеру. Пайдаланушы "провайдер істен шықты" дегенді көрмейді. Ол тым ұзақ айналып тұрған батырманы немесе қате туралы хабарламаны көреді.
Асинхронды тапсырмалар бастапқыда бәрі тірі деген жалған әсер береді. Қоңырау саммариі, пакетпен классификациялау, түнгі есептер және фондық агенттер бірден тоқтап қалмайды. Олар кезекке жиналып, 10-20 минуттан кейін мәселе worker-лерге, message broker-ге және connection лимиттеріне жетеді.
Кезек бірден бірнеше жерде өседі: API кіреберісінде, retry-лерде, worker пулында және клиент timeout-тарында. Егер қолданба 30 секунд жауап күтсе және тағы 2-3 рет қайталаса, бір істен шыққан маршрут ресурстарды тез бітеп тастайды, ал қолданбаның өзі формалды түрде "жұмыс істеп" тұрғандай көрінеді.
Сондықтан сыртқы инцидентті өз өніміңіздегі bug деп қате қабылдау оңай. Қателер біркелкі түспейді: бір қолданушыда timeout, екіншісінде 429, үшіншісінде бос жауап немесе мәтіннің ортасынан үзілу. Frontend spinner-лерді көреді, backend релизден кейінгі регрессияны іздейді, ал себеп сыртта жатады.
Провайдердің status page-і жиі кешігеді. Сізде кешігу мен қате өсе бастайды, ал сыртта әлі де "жасыл" болуы мүмкін. Растау күту қауіпті: сол уақытта retry-лер traffic-ті үлкейтеді, ал тәуелді сервистер де бірінен соң бірі құлай бастайды.
Егер сізде модель роутингіне арналған бірыңғай шлюз бар болса, алғашқы минуттар тынығырақ өтеді: бүкіл контур емес, бір маршрут құлап тұрғаны көрінеді. Мұндай қабат болмаса, өз метрикаңызға қараңыз. Бір провайдерде қате күрт өсіп, база, кезектер мен желі қалыпты жұмыс істеп тұрса, инцидентті сыртқы деп есептеп, бірден әрекет еткен дұрыс.
Басқаруды кім алады
Сыртқы провайдер құлағанда ең қатты кедергі жасайтыны - қате емес, команданың ішіндегі хаос. Егер platform, product және support бір уақытта шешім қабылдаса, уақыт дау мен қайталауға кетеді.
Бірінші минуттан бастап бір incident duty керек. Ол бәрін жеке өзі жөндемейді. Ол басымдық қояды, ағымдағы status-ты бекітеді және келесі қадамды тағайындайды. Пікірлер әртүрлі болса, соңғы сөз - соныкі.
Рөлдерді алғашқы 10 минутта бөліп алған жөн. Platform командасы қателерді, квоталарды, timeout-тарды және қосалқы маршруттарды тексереді. Product қай сценарийді қандай бағамен болса да сақтау керегін, ал қайсын уақытша қысқартуға болатынын шешеді. Support ішкі командаларға арналған бір түсінікті хабарлама дайындайды және чаттардағы сыбыстарды емес, пайдаланушылардан келген нақты кейстерді жинайды.
Бір ғана incident channel керек: бір чат, бір қоңырау немесе бір бөлме, бірақ қатар тұрған үш арна емес. Барлық жаңарту сонда түседі. Сол жерде қысқа журнал жүргізіңіз: басталу уақыты, алғашқы симптомдар және пайдаланушы көрген нәрсе. Мысалы: 09:12 - бір провайдерде 5xx өсті; 09:15 - жауап 20 секундтан ұзақ келіп жатыр; 09:18 - support chat ұзақ сұрауларға жауап бермей қалды.
Бір жауапты адам, бір арна және қысқа журнал көбіне бірінші сағатты бос әуреге жұмсамай өткізуге жетеді.
Сәтсіздіктің ауқымын қалай түсінуге болады
Алдымен сезіммен емес, симптоммен жұмыс істеңіз. Бір ғана ақау әр жерде әртүрлі көрінуі мүмкін: бір жерде кідіріс өседі, бір жерде timeout болады, ал бір жерде 5xx тек бір модельде ғана пайда болады.
Қателерді төрт қырынан жылдам бөліңіз: модель, аймақ немесе шығу зонасы, сұрау түрі және уақыт, кемінде 5-10 минут қадаммен. Сонда мәселе жалпы ма, әлде тар жерге соғып тұр ма - бірден көрінеді. Бір провайдердегі бір модель құласа, бұл барлық маршруттағы жаппай timeout-пен бірдей емес.
Содан кейін провайдерден келген істен шығуды өз проблемаңыздан ажыратыңыз. Үш қарапайым нәрсені тексеріңіз: API-key мерзімі өтпеді ме, жаңа релиз бірдеңені бұзбады ма, және сіздің контурыңыз бен сыртқы API арасында желілік апат жоқ па. Мұнда жиі қателеседі: провайдерді кінәлап, кейін жаңа rate limit, proxy немесе қате base_url табады.
Тек қате пайызын ғана қарамаңыз. Егер медианалық кідіріс екі есе өссе, ал 5xx әзірге аз болса, инцидент әлдеқашан басталған. LLM үшін бұл қалыпты ерте белгі. Timeout үлесін, p95 және p99 кідірісті, 5xx үлесін және бір сәтті жауапқа шаққандағы retry санын салыстырған пайдалы.
Қосымша түрде қандай функциялар қазірдің өзінде қосалқы маршрутқа өткенін, ал қайсысы әлі негізгі провайдерде тұрғанын тексеріңіз. 15-20 минуттан кейін командада қысқа status болуы керек: не бұзылды, қай жерде бұзылды, кімге әсер етті және қандай сценарийлер қазірдің өзінде резервте тұр.
Роутингті қалай ауыстыру керек
Сыртқы LLM-провайдер істен шыққанда бүкіл трафикті бірінші қолжетімді ауыстыруға бірден жібермеңіз. Онда жұмыс істеп тұрған сценарийлерді де бұзып, квотаны да тез жұмсап аласыз. Әуелі артық жүктемені азайтыңыз: пакет тапсырмаларды, қайта индекстеуді, auto-summary-ды, түнгі job-тарды және өнім бірнеше сағат онсыз да өмір сүре алатынның бәрін тоқтатыңыз.
Сосын трафикті маңыздылығына қарай бөліңіз. Пайдаланушы дәл қазір жауап күтетін критикалық сценарийлерді алдымен ауыстырыңыз. Әдетте бұл support chat, білім базасы бойынша search және операторларға арналған ішкі көмекшілер. Ұзын есеп генерациясын, мәтінді қайта жазуды және басқа ауыр операцияларды уақытша кейінге қалдырған дұрыс.
Әрбір критикалық сценарий үшін алдын ала негізгі қосалқы модельді және екінші fallback-ты анықтаңыз. Тек сапаға емес, бағаға, контекст терезесінің көлеміне және қолжетімді RPM-ге де қараңыз. Жаңа схемаға алдымен live traffic-тің 1-5%-ын жіберіп, содан кейін ғана ауыстыруды кеңейтіңіз.
Тексеру кезінде тек жауап кодына қарамаңыз. Жауап ұзындығын, бос немесе үзіліп қалған хабарламалар санын, JSON форматының тұрақтылығын, орташа кідірісті және фильтрлердің оғаш іске қосылуын да бақылаңыз. Қосалқы модель "сәтті" жауап беруі мүмкін, бірақ құрылымды нашар сақтап, тым көп сөйлеп кетуі ықтимал.
Тағы бір практикалық қадам: инцидент аяқталғанға дейінгі уақытша ережелерді бекітіңіз. Қандай модельдер белсенді, бірінші қай fallback жүреді, қандай лимиттер бар және схеманы кім өзгерте алады - соның бәрін жазып қойыңыз. Әйтпесе бір сағаттан кейін командалар трафикті әр жаққа тарта бастайды.
Лимиттерді қай жерде енгізу керек
Сәтсіздік күні лимиттерді бәріне бірдей қоюға болмайды. Алдымен токенді көп жейтін және ақшаға, клиент support-ына немесе күнделікті операцияларға тікелей әсер етпейтін нәрсе қысқартылады. Әйтпесе жүйе тез арада кезекке тіреліп, пайдалы сұраулар екінші дәрежелі сұраулармен бірге күтіп қалады.
Бірінші кандидат - ұзын контекст. Егер сізде 30-50 хабарламалы чаттар, үлкен тіркемелер, ұзын system prompt-тар немесе мыңдаған токендік генерация болса, оны бірден қысқартыңыз. Тіпті кіріс пен жауаптың ең үлкен өлшемін азайтудың өзі алғашқы 10-15 минутта жүктеменің елеулі бөлігін түсіреді.
Параллельдікті де таңдаулы түрде азайтқан дұрыс. Ішкі көмекшілер, қоңырауларды auto-analysis, хат draft-тары және басқа шұғыл емес сценарийлер баяуырақ жұмыс істей алады. Ал төлем тексерулері, support, antifraud және операциялық тізбектер өз пропуск қабілеті қорын алуы керек.
Әдетте төрт шара жеткілікті. Критикалық емес маршруттар үшін max input tokens пен max output tokens-ты азайтыңыз. Ішкі сервистер мен фондық тапсырмаларға бір мезеттегі сұрау санын төмендетіңіз. Аналитика мен деректерді қайта байытуды кезекке ауыстырыңыз. Және міндетті түрде әр API-key-ге қатаң rate limit қойыңыз, сонда бір тұйық worker бүкіл жүйені құлатпайды.
Соңғы тармақ көбіне бағаланбайды. Retry-дегі қате немесе бір сәтсіз worker бірнеше минутта бір key бойынша секіріс жасап, қолжетімді көлемнің бәрін алып қояды. Кілттер бойынша бөлек лимиттер, қарапайым квота және circuit breaker мұндай күні бүкіл кластерге арналған жалпы лимиттен пайдалырақ.
Қандай функцияларды қысқарту керек
Инцидент кезінде өнімді бұрынғы қалпында сақтап қалуға тырыспаңыз. Бұл көбіне бірден кідірісіне, шығынға және тұрақтылыққа соғады. Жылдамырақ жұмыс істейтін басқа тәсіл бар: жауап ақшаға, өтінімге, тапсырысқа немесе клиентке жауап беру мерзіміне әсер ететін сценарийлерді ғана қалдыру.
Алдымен пайдаланушы бәрібір әрекетін аяқтай алатынның бәрін алып тастаңыз. Қайта генерациялар, "тағы бір рет көрейін" батырмалары, жауаптың балама нұсқалары және автоматты rephrase көп сұрау жейді, ал күнді сирек құтқарады. Қалыпты уақытта бұл ыңғайлы. Сәтсіздік кезінде - артық сән.
Ескі диалогтарға да алдымен тиіскен дұрыс. Егер сервисте ұзын тарих фондық summarization арқылы қысқартылса, оны уақытша өшіріңіз. Бірнеше соңғы хабарламаны сақтап, қысқа контексте жұмыс істеу - ешкім толық оқымайтын ұзын тармақтарға лимит жұмсағаннан арзанырақ.
LLM-ды еркін мәтінді талдау шынымен қажет жерлерде қалдырған жөн. FAQ, тапсырыс статусы, форма өрістерін тексеру және өтініштерді тег бойынша бағыттау бір күнге ережелерге, search-ке және қолданбаның кәдімгі логикасына қайта оралуы мүмкін.
Support chat-та модельден қысқа жауап беруді сұраңыз. 2000 таңбалық ұзын, жылы мәтін керек емес. Status, келесі қадам және не тіркеу керегінің тізімі қажет. Көбіне 300-400 таңбалық жауап мәселені жақсырақ шешіп, жүктемені тезірек азайтады.
Командаларға шуды азайтып қалай хабарлау керек
Сәтсіздік күнінде бұзылудың өзінен де жаман нәрсе - бір-біріне қайшы хабарламалар легі. Бір адам "бәрі құлады" деп жазады. Екіншісі мәселе тек клиенттердің бір бөлігінде ғана дейді. Үшіншісі 15 минутта қалпына келеді деп уәде беріп үлгереді. Солай команда уақыт жоғалтып, жұмыс орнына дауласуға көшеді.
Бірінші хабарлама қысқа әрі нақты болуы керек. Зардап шеккен өнімдерді және бизнес үшін тәуекел деңгейін атаңыз. Мысалы: support chat жұмыс істемейді, ішкі көмекшіде жауаптар қатты кешігуде, пакет тапсырмалар паузаға қойылды, клиент сценарийлері үшін қауіп жоғары, ішкі сценарийлер үшін орташа.
Сосын бір түсінікті status беріңіз: не бұзылды, команда не істеп үлгерді, қазір нені тексеріп жатыр және келесі жаңарту қашан болады. Алғашқы байланыс үшін осы жеткілікті. Егер traffic already резерв маршрутқа ауыстырылса, лимиттер төмендетілсе, ал қымбат функциялар өшірілсе, оны ашық жазыңыз. Адамдарға ұзақ түсініктеме емес, факт керек.
Хабарлама ритмі шуды ұзақ есептен жақсы басады. Егер әзірге жаңалық аз болса да, келесі жаңарту уақыты нақты белгіленсін: 15 минуттан кейін, 12:30-да, сұраулар кезегін тексерген соң. Сонда инженерлерді жеке чаттарда екі минут сайын мазаламайды.
Support пен аккаунт-командаларды бөлек ескертіңіз. Оларға техникалық талдау керек емес. Оларға клиенттерге арналған жұмыс мәтіні керек: не қолжетімсіз, кімде байқалады, айналып өту жолы бар ма және нені уәде етуге болмайды. Егер chat баяуырақ жауап беріп тұрса, бірақ толық жоғалмаса, олар соны дәл айтуы керек.
Мерзімге келгенде салқынқандылық керек. Егер ол әзірге тек болжам болса, "15 минутта жөндейміз" деп жазбаңыз. Оның орнына "келесі жаңарту 12:30-да" деп жазыңыз.
Мысал: support chat сәтсіздік күнінде
Клиент банк чатына: "Төлем өтпей тұр, не істеймін?" деп жазады. Әдетте bot 4-6 секундта жауап береді, бірақ қазір кідіріс 20 секундқа дейін созылады. Пайдаланушы үшін бұл жүйе әлі толық құламаса да, бұл - already failure.
Команда толық тоқтауды күтпейді. Ол бірден трафикті қосалқы модельге ауыстырып, сұрауларды күрделілігіне қарай бөледі. Өтініш статусы, лимиттер, жұмыс уақыты, парольді қалпына келтіру сияқты қарапайым нәрселер bot-та қалады. Ұзақ ой қорыту тізбегі немесе контекстпен дәл жұмыс керек күрделі кейстер екінші маршрутқа кетеді.
Жүктемені түсіру үшін bot жауап режимін өзгертеді. Ол қысқа жазады, артық персонализация қоспайды және соңында қосымша кеңестер ұсынбайды. Бұрын жауап 8-10 сөйлем болса, енді 3-4 қысқа сөйлем және клиентке бір әрекет қана қалады. Мұндай қадам көбіне токенді үнемдеп, кезекті алғашқы минуттарда-ақ азайтады.
Support операторлары да қолмен қабылдау үшін қарапайым шаблон алады. Онда төрт нәрсе ғана бар: ұзақ түсіндірмесіз кешігуді мойындау, бір келесі қадам беру, келесі жауап уақыты туралы айту және бот екі рет қатарынан қателессе, диалогты адамға беру.
Бір сағаттан кейін жағдай әдетте анықталады. Кезек азайса, команда функцияларды біртіндеп қайтарады: алдымен персонализация, содан кейін ұзындау жауаптар және тек содан кейін ғана өтініш тарихын summarization ету сияқты күрделі сценарийлер. Бұл бәрін бірден қайтарып, қайтадан лимитке тірелгеннен қауіпсіз.
Мұндай күндегі жиі қателер
Көбіне команда уақытты сәтсіздіктің өзіне емес, күрт қимылға жоғалтады. Ең қымбат қате - бүкіл трафикті бір қосалқы провайдерге жіберіп, мәселе жабылды деп ойлау. 10-20 минуттан кейін сіз сол проблеманың басқа жерде тұрғанын көресіз: кезек өседі, жауап қымбаттайды, ал функциялардың бір бөлігі күтпеген мінез көрсетеді.
Екінші қате - кідіріс өсіп кеткенде ескі лимиттерді қалдыру. Сәтсіздікке дейін жүйе секундына 50 сұрауды тыныш ұстаса да, ауыстырғаннан кейін сол көлемді көтереді деген сөз емес. Жауап уақыты үш есе ұзарса, бұрынғы лимиттер тек сервисті қосымша қысады.
Үшінші қате - бір релизде маршрутты да, prompt-ты да өзгерту. Егер жауап сапасы төмендесе, оның себебі қайсы екенін енді түсінбейсіз: жаңа провайдер ме, басқа system prompt па, әлде қысқартылған контекст пе. Апат күнінде бір параметрді ғана өзгертіңіз. Алдымен маршрут, сосын лимиттер, және тек қажет болса ғана prompt мәтіні.
Тағы бір типтік мәселе - фондық процестерді ұмыту. Түнгі batch тапсырмалар, eval-жүрістер, автотесттер және аналитиктердің sandbox-тары production-мен бірдей сұрау қорын жейді. Оларды тез баяулату керек, әйтпесе production ресурстар үшін ертеңге дейін сабырмен күте алатын нәрсемен таласады.
Және соңында - үнсіздік. Бизнеске мәселені білу үшін толық талдау керек емес. 15 минуттан кейін-ақ қысқа status қажет: неге әсер етті, не қысқартылған күйде жұмыс істеп тұр және келесі жаңарту қашан болады.
Сәтсіздік күніне арналған қысқа чек-лист
- Алдымен қате көзін тексеріңіз: бұл 5xx, timeout, 429, кідіріс өсуі ме, әлде тек бір аймақтағы ақау ма.
- Бір жауапты адам мен бір жаңарту арнасын тағайындаңыз.
- Критикалық трафикті қосалқы маршрутқа ауыстырып, екінші дәрежелі тапсырмаларды паузаға қойыңыз.
- Лимиттерді төмендетіп, ұзын жауаптарды қысқартыңыз және қымбат функцияларды өшіріңіз.
- Жаңалық аз болса да, келесі status уақытын бірден белгілеңіз.
Бірінші сағаттың соңына қарай командада төрт сұраққа жауап дайын болуы керек: не бұзылды, қандай трафикті сақтап қалдық, лимиттер қайда тұр және келесі апдейтті кім береді.
Инциденттен кейін не істеу керек
Мұндай күнді әсермен емес, цифрмен талдаған дұрыс. Үш дерек тобын жинаңыз: қанша сұрау құлады, кідіріс қалай өсті және бизнес нақты қай жерде ақша, өтінім немесе пайдаланушы жоғалтты. Егер support chat 40 секундқа баяу жауап берсе, ал қате үлесі 1%-дан 12%-ға өссе, бұл - шешім қабылдауға арналған материал, "бәрі жай ғана баяулады" деген жалпы сөз емес.
Содан кейін роутинг ережелерін қайта қараңыз. Көбіне сәтсіздік схема әлсіз болғанын көрсетеді: бір провайдер тым көп трафик алып тұрған, қосалқы маршрут кеш қосылған, ал лимиттер секірісті ұстай алмаған. Ауыстыру шегін, резервтегі трафик үлесін және команда, функция немесе сұрау түрі бойынша шектеулерді түзетіңіз.
Сол сценарийді стендте қайталап шығу пайдалы: негізгі провайдерді қолмен өшіріп, ауысу уақытын, қате өсуін, кезектердің күйін және бюджет шығынын тексеріңіз. Егер тест жүйені қайта құлатса, жоспар әлі пісіп жетілмеген. Қалыпты сәтсіздік сценарийі жалықтыратындай болуы керек: traffic қосалқы маршрутқа кетеді, кейбір функциялар ережеге сай өшеді, командалар түсінікті сигнал алады.
Тағы бір қорытындыны келесі сәтсіздік басталғанда емес, алдын ала жасаған дұрыс. Егер сізге routing, key бойынша fallback, rate limit және ел ішіндегі local model-дерді орналастыратын бір қабат керек болса, оны жаңа инцидентке дейін шешіңіз. Қазақстандағы командалар үшін ондай қабат AI Router болуы мүмкін: бір OpenAI-үйлесімді endpoint, провайдерлер арасында роутинг және жергілікті GPU-инфрақұрылымдағы өз модельдері. Бірақ мұндай құрал болса да, инцидент өзінен-өзі жоғалмайды - тәртіп, метрика және қарапайым ереже кез келген ыңғайлы панельден маңыздырақ.
Жиі қойылатын сұрақтар
Проблема провайдерден бе, әлде бізден бе, оны қалай тез түсінеміз?
Өз метрикаңызға қараңыз, status page-ге емес. Егер бір провайдерде timeout, 5xx және p95 күрт өсіп, ал сіздің базаңыз, желіңіз бен кезектеріңіз қалыпты болса, мұны сыртқы инцидент деп есептеп, ауыстыруды бастаңыз.
Өзіңіз жақтан үш нәрсені бірден тексеріңіз: API-key мерзімі, жаңа релиз және сыртқы API-ға баратын желі жолы. Бұл тексерулер бірнеше минут алады және жиі жалған дабылды алып тастайды.
Сәтсіздіктен кейін алғашқы 10 минутта не істеу керек?
Алдымен өнім бірнеше сағат өмір сүре алатынның бәрін тоқтатыңыз: batch тапсырмалар, түнгі job-тар, auto-summary және қайта индекстеу. Сосын бір кезекші тағайындап, бір байланыс арнасын ашып, уақыт пен симптомдар жазылған алғашқы status-ты бекітіңіз.
Провайдердің ресми растауын күтпеңіз. Сіз күтіп тұрған кезде retry-лер мен ұзақ timeout-тар кезекті бітеп тастайды.
Инцидент кезінде шешімді кім қабылдауы керек?
Бір ғана incident duty engineer болсын. Ол даулы шешімдерді қабылдайды, келесі қадамды белгілейді және командалардың трафикті әр жаққа тартып жібермеуін қадағалайды.
Платформа қателер мен маршруттарды тексереді, product нені жұмыс күйінде сақтау керегін шешеді, support ішкі командалар мен клиенттерге арналған бір мәтінді дайындайды.
Қай трафикті алдымен резервке ауыстыру керек?
Алдымен пайдаланушы дәл қазір жауап күтетін сценарийлерді ауыстырыңыз. Әдетте бұл support chat, операторға арналған көмекші және жауап генерациясы бар search.
Ауыр әрі шұғыл емес тапсырмаларды паузаға қойған дұрыс. Ұзақ есептер, мәтінді қайта жазу және фондық талдау тұрақтанғанша күте тұрады.
Бүкіл трафикті бірден қосалқы модельге жіберу керек пе?
Жоқ, барлық трафикті бірден көшіру қауіпті. Қосалқы маршрутты шамадан тыс жүктеп, квотаны жағып жіберіп, екінші провайдерде де жаңа кезек алуыңыз мүмкін.
Алдымен live traffic-тің 1-5%-ын жіберіп, кідірісті, жауап форматын және мәтін ұзындығын тексеріңіз, содан кейін үлесті ұлғайтыңыз. Сонда мәселені бәріне әсер етпей тұрып көресіз.
Сәтсіздік күні лимиттерді қай жерде енгізген дұрыс?
Алдымен шұғыл емес сценарийлердегі ұзын контекст пен ұзын жауапты қысқартыңыз. Бұл жүктеменің бір бөлігін тез түсіреді және өнімді көп бұзбайды.
Содан кейін ішкі сервистер мен фондық тапсырмалар үшін параллельдікті азайтыңыз. Әр API key-ге қатаң rate limit қойыңыз, сонда бір тұйықталған worker бүкіл қолжетімді көлемді алып қоймайды.
Қандай функцияларды уақытша қысқартуға болады?
Пайдаланушы әрекетті бәрібір аяқтай алатынның бәрін өшіріңіз. Қайта генерация, жауаптың балама нұсқалары, артық персонализация және тарихты фондық summarization әдетте көп шығын алып, апат күні аз пайда береді.
Мүмкін болған жерде ережелер мен қолданбаның кәдімгі логикасына қайтыңыз. FAQ, тапсырыс статусы және форма өрістерін тексеруді LLM-сыз-ақ жабуға болады.
Командалар мен support-қа дүрбелеңсіз қалай хабарлау керек?
Қысқа әрі нақты жазыңыз: не істен шықты, кімге әсер етті, команда не істеп үлгерді және келесі status қашан болады. Мұндай формат ұзақ түсіндіруден гөрі шуды жақсы азайтады.
Support-қа клиенттерге арналған бөлек мәтін беріңіз. Оларға техникалық талдау емес, нақты тұжырым керек: не қолжетімсіз, қай жерде кідіріс бар және қазір нені уәде етуге болады.
Провайдердің status page-і ештеңе көрсетпесе не істеу керек?
Жаңалықты күтпеңіз, ол түс өзгерткенше. Егер метрикаларыңыз кідіріс пен қателердің өскенін көрсетсе, өз жоспарыңызбен әрекет етіп, инцидентті нақты деп қабылдаңыз.
Status page жиі кешігеді. Мұндай сәтте сіздің графиктеріңіз, оқиғалар журналы және қосалқы маршруттарды тексеру көбірек көмектеседі.
Келесі сәтсіздік жеңілірек өтуі үшін инциденттен кейін нені талдау керек?
Үш аймақ бойынша цифрларды жинаңыз: қанша сұрау құлады, кідіріс қаншалықты өсті және бизнес қай жерде өтінім, ақша немесе уақыт жоғалтты. Осы деректер ауыстыру шегін, лимиттерді және резервтегі трафик үлесін түзетуге көмектеседі.
Содан кейін сол сценарийді стендте қолмен қайталаңыз. Егер жүйе қайта тұншығып қалса, жоспар әлі шикі. Егер сізде AI Router сияқты бірегей шлюз болса, роутинг ережелерін, key бойынша лимиттерді және local model жұмысын да тексеріңіз.