Спекулятивті декодтау: қайда жылдамдатады, қайда жоқ
Спекулятивті декодтау LLM-ді әрдайым жылдамдатпайды. Қай жерде шағын модель кідірісті шын мәнінде азайтатынын, ал қай жерде пайдасын жеп қоятынын көрсетеміз.
Неге жауап әрдайым жылдамырақ келмейді
Спекулятивті декодтау генерацияға тағы бір қадам қосады. Алдымен шағын алдын ала модель бірнеше келесі токенді тез ұсынады. Сосын үлкен модель оларды тексеріп, не қабылдайды, не кері қайтарады. Схема қағаз жүзінде жауапты жылдамдатудың оңай жолы сияқты көрінеді. Ал шынайы жүйеде бәрі күрделірек: тексеруге де уақыт пен есептеу керек.
Сондықтан шағын модель автоматты түрде пайда әкелмейді. Ол жалғастыруды жеткілікті жиі дәл табуы керек. Егер ол тым ерте қателессе, үлкен модель тек әдеттегі генерацияға емес, біреудің жорамалын қайта-қайта тексеруге де ресурс жұмсайды. Уақыттың бір бөлігі жай ғана жоғалады.
Бұл редактордың жұмысын еске салады. Егер қара жұмыс дерлік дайын болса, редактор оны тез мақұлдап, әрі қарай өтеді. Ал мәтін әлсіз болса, бәрін басынан жазған оңай. Модельдерде де логика сондай.
Айырмашылық әсіресе қысқа жауаптарда қатты байқалады. Жүйе 20-30 токен қайтаруы керек болғанда, мысалы белгі, қоңыраудың қысқа қорытындысы немесе «иә» не «жоқ» стиліндегі жауап берілгенде, үстеме шығын бүкіл пайданы оңай жеп қояды. Уақыт шағын алдын ала модельді іске қосуға, гипотезаны беруге және негізгі модельмен тексеруге кетеді. Соңында кәдімгі генерация жиі жылдамырақ болып шығады, өйткені онда қадам аз.
Ұзын әрі болжамдырақ жауаптарда жағдай жиі жақсырақ. Егер модель үлгілік мәтін, құрылымды түйіндеме немесе түсінікті шаблоны бар код бөлігін жазса, шағын алдын ала модель көбіне келесі жалғастыруды дәл табады. Онда үлкен модель бір өтуде бірнеше токенді қабылдайды да, кідіріс айтарлықтай азаяды.
Әдетте бәрі төрт нәрсеге тіреледі: шағын алдын ала модель жалғастыруды қаншалықты жиі дәл табады, сіздің жауаптарыңыздың ұзындығы қандай, негізгі модель бір топ токенді қаншалықты жылдам тексере алады және схеманың өзіне қанша желілік не серверлік шығын қосылады.
Сондықтан бірдей модель жұбы әртүрлі тапсырмада әртүрлі әрекет етеді. Қысқа заңдық бот жауабында пайда жоғалып кетуі мүмкін. Ал колл-центрдегі ұзын қоңырау қорытындысында ол бірден көрінеді. Команда тек бір сценарийді тексерсе, оңай қате қорытынды жасайды.
Өндірісте идеяның өзінен керемет күтпеген дұрыс. Алдымен қарапайым сұраққа жауап берген жөн: қай сұрауларда шағын алдын ала модель тұрақты түрде дәл табады, ал үлкен модель нөлден генерация жасағаннан тезірек тексереді. Тек сол жерде ғана схема әдетте өзін ақтайды.
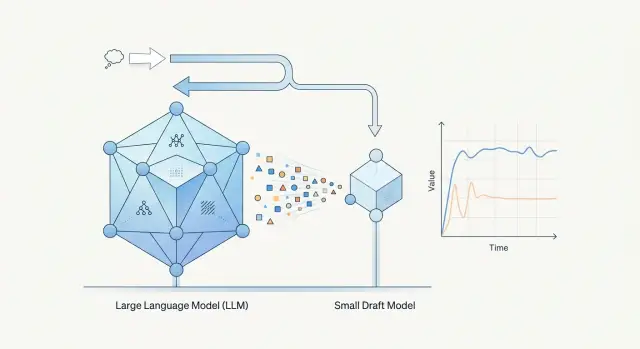
Схема формуласыз қалай жұмыс істейді
Спекулятивті декодтауда бір емес, екі модель жұмыс істейді. Шағын модель жалғастыру ұсынады, ал мақсатты модель қандай токендерді қалдыруға болатынын шешеді. Шағын модель сапа үшін емес, жылдамдық үшін керек.
Жұмыс циклі қарапайым:
- Шағын алдын ала модель бірнеше келесі токенді ұсынады.
- Негізгі модель сол фрагментті бір өтуде тексереді.
- Егер болжам сәйкес келсе, жүйе бірден бірнеше токенді қабылдайды.
- Егер шағын модель қателессе, жүйе артық бөлікті алып тастап, ауытқыған жерден әрі қарай жалғастырады.
Жылдамдық екі модельдің барынан емес, қабылданған токендер тізбегінен пайда болады. Егер шағын алдын ала модель жиі дәл тапса, үлкен модель мәтіннің бірнеше бөлігін қатар растайды да, жауап жылдамырақ жүреді. Егер нашар тапса, жүйе уақытын да, тексеруге кететін күшті де жоғалтады.
Жақсы мысал — қоңыраудың шаблонды қорытындысы. «Клиент жеткізілімнің кешігуіне шағымданды, кері қоңырау сұрады» деген сияқты сөйлемнің формасы алдын ала жақсы болжанады. Мұндай бөліктерде шағын алдын ала модель сөздерді де, олардың ретін де жиі дәл табады. Сонда негізгі модель бірнеше токенді қатар қабылдайды.
Мұнда екі бөлек көрсеткішті шатастырмау маңызды. Біріншісі — бірінші токенге дейінгі уақыт. Бұл пайдаланушы жауаптың басын қаншалықты тез көретінін көрсетеді. Екіншісі — толық жауап уақыты, яғни жүйе бүкіл мәтінді қаншалықты жылдам аяқтайды.
Спекулятивті декодтау көбіне ұзын жалғамада көмектеседі. Бірінші токен мүлде жеделдемеуі мүмкін, кейде тіпті шағын алдын ала модельдің қосымша қадамы салдарынан сәл кешігіп те келеді. Бірақ 200-500 токендік жауапта, егер шағын модель мәтіннің стилі мен құрылымын жақсы тапса, ұтыс айқын болады.
Сондықтан мұндай схеманы бір санмен бағалауға болмайды. Егер тек бірінші токенге қарасаңыз, пайда жоқ деп ойлап қаласыз. Егер тек ұзын жауаптардың орташа жылдамдығына қарасаңыз, интерфейс басында азырақ ыңғайлы болып қалғанын байқамайсыз.
Қорытынды жасамас бұрын нені өлшеу керек
Тек жауаптың орташа уақытына қарасаңыз, қорытынды оңай қате болады. Орташа мән ұзақ кідірістерді жасырады, ал пайдаланушылар ең алдымен соларды есте сақтайды. Орташаға қоса медиананы және кемі p95 көрсеткішін ұстаңыз. Сонда жылдамдық барлығы үшін жұмыс істей ме, әлде тек ыңғайлы сұрауларда ғана ма — көрінеді.
Бөлек өлшейтін нәрсе — бірінші токенге дейінгі уақыт пен жауаптың соңына дейінгі уақыт. Пайдаланушы үшін бұл екі бөлек сезім. Модель сәл ертерек жауап бере бастауы мүмкін, бірақ шамамен сол уақытта аяқтауы да мүмкін. Керісінше де болады: бірінші токен өзгермейді, ал ұзын жауап едәуір тез жиналады.
Спекулятивті декодтаудың тікелей индикаторы да бар: шағын алдын ала модельдің қанша токенін үлкен модель қайта есептемей қабылдады. Шағын модель жиі дәл тапса, схема пайда береді. Егер негізгі модель оның ұсыныстарын үнемі кері қайтарса, сіз артық жұмысқа төлейсіз де, тексеруге уақыт жоғалтасыз.
Жалпы пайызға ғана емес, сұрау түрлері бойынша бөлініске де қараған пайдалы. Қысқа формалды жауаптарда, қатаң JSON-да және қайталанатын шаблондарда қабылдау көбіне жоғары болады. Күрделі пайымдауларда, сирек терминдерде және ұзын кодта ол әдетте төмендейді.
Тағы бір жиі қателік — құн мен кідірісті әртүрлі сұраулар жиынында салыстыру. Олай жасауға болмайды. Бірдей таңдау, бірдей генерация параметрлері, бірдей токен лимиті және бірдей жүктеме жағдайы керек. Әйтпесе схема көмектесті ме, әлде сұраулар профилі ғана өзгерді ме — түсінбейсіз.
Ең аз метрика жиыны әдетте мынадай:
- кідіріс бойынша медиана, орташа және p95;
- бірінші токенге дейінгі уақыт және жауаптың толық уақыты;
- қабылданған шағын алдын ала токендер үлесі;
- бір жауаптың құны және 1000 шығыс токенінің құны.
Егер схеманы адал тексергіңіз келсе, продакшеннен қолмен іріктелмеген кемі 100-200 нақты сұрау алыңыз. Содан кейін кәдімгі генерацияны және «шағын алдын ала модель + негізгі модель» жұбын бірдей жиында салыстырыңыз. Осы деңгейдің өзінде-ақ қай жерде шынайы пайда бар, ал қай жерде сандар тек әдемі есепте жақсы көрінетінін байқауға болады.
Пайда әдетте қай жерде бар
Спекулятивті декодтау көбіне жауап ұзын әрі формасы жағынан болжамды болғанда көмектеседі. Егер модель шаблон бойынша қорытынды жазса, табылған өрістерді тізсе немесе белгілі құрылыммен түсіндірсе, шағын алдын ала модель келесі бөлікті жиі дәл табады. Сонда үлкен модель бірнеше токенді бірден растайды да, қадамдар арасындағы кідіріс азаяды.
Жақсы мысал — колл-центрдегі қоңырауларды жинақтау. Көп командада қорытынды бірдей құрылымға келеді: жүгіну себебі, оператордың жасаған әрекеті, сөйлесудің нәтижесі, қайта байланыс керек пе. Тұжырымдар өзгерсе де, жауаптың қаңқасы шамамен бірдей қалады. Мұндай ағындарда LLM шығару жылдамдығы еркін диалогқа немесе шығармашылық мәтінге қарағанда тезірек өседі.
Көбіне пайда модель тар жолмен жүретін тапсырмаларда болады: қоңырау мен кездесулер қорытындыларында, хаттар мен өтінімдерден өріс шығаруда, стандартты сценарийлердегі қолдау жауаптарында, бөлімдері бекітілген қысқа есептерде. Осы жағдайларда шағын алдын ала модель аса күшті болмауы мүмкін. Оған жауаптың күтілетін ырғағын жиі ұстаса болғаны: қызметтік сөздер, маркерлер, типтік байланыстар, қайталанатын құрылымдар. Мәтінде тосын нәрсе неғұрлым аз болса, негізгі модель қатарынан соғұрлым көп растау алады.
Модель жұбының өзі де өте маңызды. Абстрактілі «кіші плюс күшті» жұптардан гөрі, кіші модель шамамен сол стиль мен реттілікпен жазатын жұптар жақсы жұмыс істейді. Бұл көбіне бір отбасыдағы модельдерде немесе ұқсас нұсқаулықтармен үйретілгендерде кездеседі. Егер негізгі модель ұзақ түсіндірмелерді ұнатса, ал шағын алдын ала модель қысқа әрі тура жауап берсе, сәйкестік азаяды.
Тәжірибелік жағы да бар. Жылдамдық екі модель арасындағы үйлестіру арзан болғанда жақсырақ көрінеді. Егер екі модель де алдын ала дайын болып, пайдаланушыға жақын орналасып, қосымша желілік секіріс талап етпесе, пайда сақталады. Ал егер әр тексеруге басқа аймаққа немесе басқа провайдерге қосымша сұрау кетсе, артық кідіріс пайданың өзін тез жеп қояды.
Осы себепті мұндай тәсіл бір реттік демодан гөрі қайталанатын серверлік тапсырмаларда жақсы нәтиже береді. Егер команда AI Router сияқты бір OpenAI-үйлесімді шлюз арқылы әртүрлі модель жұптарын тексерсе, бір сәтті мысалға емес, ұзын құрылымды жауаптарға және бірдей сұрау ағындарына қарап салыстырған ыңғайлы.
Пайда тез жойылатын жерлер
Шағын алдын ала модель жалғастыруды сирек тапса, спекулятивті декодтау дерлік бонус бермейді. Онда негізгі модель оның нұсқаларын кері қайтарады да, жүйе жылдамдатудың орнына артық жұмыс айналымына уақыт жұмсайды.
Ең жиі жағдай — өте қысқа жауаптар. Егер ассистент әдетте «Иә, құжат қабылданды» немесе «Кейінірек көріңіз» сияқты бір-екі сөйлем жазса, кідірісті ұзын генерация емес, модельдерді іске қосу, сұрауды беру және шағын нұсқаны тексеру тудырады. Мұндай жауаптарда тездететін нәрсе аз.
Мәселелер мәтінді болжау қиын болған жерде де басталады. Бұл күрделі пайымдау, дәл терминдер, тауар кодтары, атаулар, келісімшарт нөмірлері және басқа сирек токендер бар тапсырмаларда анық көрінеді. Шағын алдын ала модель көбіне басында-ақ қателеседі, ал негізгі модель қателікті түзетуге қадам жұмсайды.
Әлсіз шағын алдын ала модель де бүкіл әсерді тез жояды. Егер ол тек сапа жағынан емес, жалғастыру стилі жағынан да негізгі модельден едәуір нашар болса, сіз бірден екі мәселе аласыз: тексеру кезінде көбірек кері қайту және кідірістің көбірек құбылуы. Бір сұрауда бәрі жылдам өтеді, ал келесіде жауап кәдімгі генерациядан да баяу шығады.
Көбіне схема төрт жағдайда ақталмайды: жауаптың өзі өте қысқа, мәтінде сан мен сирек токен көп, шағын алдын ала модель алғашқы қадамдардың өзінде негізгі модельден алшақтайды, ал шағын нұсқаны тексеру кәдімгі генерациядай қымбат.
Соңғы тармақ жиі еленбей қалады. Тексеру де есептеу талап етеді. Егер сіз көлемі тым жақын екі модельді таңдасаңыз, ұзын контекст ұстасаңыз немесе жады мен кезекке тірелсеңіз, үнемдеу дерлік көрінбейді. Өлшеуде бұл жағымсыз көрінеді: жүйе күрделірек, ал жылдамдық өте аз ғана өзгереді.
Тек орташа кідіріс қана емес, медиана, p95 және түрлі сұрау түрлері бойынша қабылданған шағын алдын ала токендер үлесін де қараңыз. Егер қысқа жауаптар жылдамдамаса, ал күрделі сұрауларда негізгі модель шағын нұсқаны жиі кері қайтарса, кәдімгі генерацияны қалдырып, стекді себепсіз күрделендірмеген дұрыс.
Мұны өз тапсырмаларыңызда қалай тексеруге болады
Бір жиі қолданылатын тапсырмадан бастаңыз. Чатты, қорытынды жасауды, өріс шығаруды және хат генерациясын бір тестке араластырмаңыз. Әйтпесе ештеңе түсіндірмейтін орташа сан аласыз. Егер пайдаланушылар көбіне өтінімді қысқаша жіктеуді сұраса, дәл соны тексеріңіз.
Содан кейін қалыпты сұраулар жиынын жинаңыз. Онда тек типтік мысалдар емес, жауап ұзындығы да әртүрлі болсын: өте қысқа, орташа және ұзын. Көбіне дәл ұзын жауаптарда спекулятивті декодтау пайда береді, ал қысқаларда кідіріс онша өзгермейді. Егер оларды бөлмей араластырсаңыз, қорытынды қате болады.
Келесі қадам — екі режимді бірдей баптаулармен жіберу. Біріншісінде тек негізгі модель қалады. Екіншісінде шағын алдын ала модель қосылады. Температураны, max tokens-ты, жүйелік промптты, кэшті және параллелизмді өзгертпеңіз. Кез келген мұндай өзгеріс салыстыруды бұзады.
Бір ғана метрикаға емес, мына жиынтыққа қараған дұрыс: жауап уақыты бойынша p50 мен p95, бір сұраудың және бүкіл таңдама құны, бірдей тексерудегі сапа және жылдамдық қай сұрауларда пайда болғаны.
Сапаны екі сәтті жауапқа қарап емес, қарапайым ережемен тексерген жөн. Қорытындылауда бұл фактілердің толықтығы болуы мүмкін, жіктеуде — метканың дәлдігі, дерек шығаруда — дұрыс толтырылған өрістер саны. Егер жылдамдық 15% өсіп, қате көбейсе, мұндай тестті сәтті деп санауға болмайды.
Содан кейін шағын алдын ала модельді ауыстырып, қайта жіберіңіз. Тәжірибеде бұл көбіне идеяның өзіне қатысты ұзақ даудан пайдалырақ. Бір шағын модель мәтіннің жалғасын жақсы болжайды да, шынымен LLM шығару жылдамдығын арттырады, ал басқасы токенді босқа жұмсайды. Модель жұбы күтілгеннен көп нәрсені шешеді.
Егер сізде AI Router сияқты бір OpenAI-үйлесімді шлюз бар болса, мұндай тестті таза өткізу оңайырақ: жұптарды бірдей API арқылы ауыстырып, қалған кодқа тимейсіз. Бұл ыңғайлы, өйткені сіз интеграциядағы жанама өзгерістерді емес, дәл модель жұбының әсерін тексересіз.
Жақсы нәтиже көзге онша түспей көрінеді, және бұл қалыпты жағдай: бір тапсырма, бір таңдама, бірдей баптаулар, p50, p95, баға және сапа бойынша түсінікті айырма.
Мысал: колл-центрдегі қоңырау қорытындысы
Кәдімгі қолдау қоңырауын алайық: 8-10 минуттық әңгіме. Клиент мәселені ұзақ түсіндіреді: тапсырыс дұрыс жерге жетпеген, оператор мекенжайды бұрын ауыстырған, ақша екі рет алынған, ал чатта жауап жоқ. Әңгімеден кейін жүйе CRM үшін қысқа, бірақ мазмұнды қорытынды жасауы керек.
Мұндай тапсырмада спекулятивті декодтау көбіне жақсы пайда береді. Себебі қарапайым: соңғы жауап бір репликадан ұзын, әрі онда болжамды фрагменттер көп. Шағын алдын ала модель «клиент хабарлады», «оператор тапсырысты тексерді», «төлемді қайта қарау керек» сияқты типтік бөліктерді оңай табады. Егер күшті модель бұл токендерді қатарынан растаса, жүйе мәтінді жылдамырақ береді.
Егер қорытынды 80-150 токен болса, үстеме шығынды өтеп шығу оңайырақ. Шағын алдын ала модель алға жылжуға үлгереді, ал күшті модель әр сөзді нөлден генерациялауға уақыт жұмсамайды. Бұл әсіресе жауап құрылымы үнемі ұқсас болғанда байқалады: жүгіну себебі, не істелді, клиентке не уәде етілді, келесі қадам қандай.
Енді басқа тапсырмамен салыстырайық. Тексерістен кейін операторға бір жолдық жауап керек: «Өтінім мәртебесі қандай?» Жүйе «Өтінім екінші желіге берілді, жауап 18:00-ге дейін күтіледі» сияқты бір сөйлем қайтаруы тиіс.
Мұнда мәтін аз. Кейде бұл бар болғаны 10-20 токен. Шағын алдын ала модель үнемдеуге онша үлгермейді, бірақ өз қадамын қосады. Егер жауапта өтінім нөмірі, уақыт, сома немесе клиенттің аты болса, күшті модель даулы токендерді көбірек қайта тексереді. Қабылданған токендер үлесі төмендейді де, пайда жойылады.
Екінші мәселе де бар. Қысқа жауапта адамдар бірінші сөзге дейінгі кідірісті жалпы шығару жылдамдығынан қаттырақ сезеді. Сондықтан тексерудің алдындағы кішкентай қосымша қадамның өзі тездік әсерін бұзуы мүмкін, ал ұзын қорытындыда дәл сол тәсіл жақсы нәтиже берер еді.
Егер команда модель жұптарын AI Router арқылы таңдаса, мұндай сценарийді бірдей қоңыраулар ағынында сынау ыңғайлы. Әдетте көрініс тез анықталады: ұзын қорытындылар көбірек жылдамдайды, ал бір сөйлемдік жауаптар көбіне айтарлықтай ұтпайды.
Командалар тест кезінде қай жерде қателеседі
Көбіне командалар алғашқы сандарға жетпей-ақ экспериментті бұзады. Олар бірден екі нәрсені өзгертеді: промпт пен модель жұбын. Кейін жауап уақытының айырмасын көріп, нақты не әсер еткенін түсінбей қалады: сұрау мәтінінің жаңарғаны ма, басқа шағын алдын ала модель ме, әлде схеманың өзі ме.
Спекулятивті декодтауда бұл әсіресе анық. Бір промпт қысқа әрі сенімді жауап берсе, кішігірім түзетуден кейін ұзын жауап, ескертулер, кесте немесе тізім шығуы мүмкін. Сонда сіз әдістің жылдамдығын емес, мүлде басқа жүктемені салыстырасыз.
Тағы бір жиі қате — тек орташа уақытқа қарау. Орташа көрсеткіш әдемі көрінеді, тіпті әр оныншы сұрау күтпеген жерден баяуласа да. Өндірісте кідірістің шеті орташа мәннен маңыздырақ болады. p95 пен p99 схеманың қай жерде бұзыла бастағанын тез көрсетеді.
Кішкентай таңдама да алдайды. Егер команда 20 не 30 сұрауды жіберіп, бір ыңғайлы сценарийде пайда көрсе, бұл әлі ештеңе дәлелдемейді. Жауап ұзындығы, құрылымы және күрделілігі әртүрлі нақты жүздеген сұрау керек.
Көбіне екі нәрсе ұмытылады: жауаптың ұзындығы және шағын алдын ала токендердің қабылдану үлесі. Егер үлкен модель шағын модель ұсыныстарын жиі кері қайтарса, пайда өте тез азаяды. Қысқа жауаптарда бұл әсіресе байқалады: үстеме шығын бар, ал үнемдейтін нәрсе аз.
Қалыпты тест әдетте былай көрінеді:
- бірдей промпт және генерация параметрлерінің бір жиыны;
- базалық схема мен спекулятивті декодтау үшін бірдей сұраулар жинағы;
- тек орташа емес, p50, p95, p99 салыстыруы;
- нәтижені жауап ұзындығы бойынша бөлу;
- негізгі модель қабылдаған шағын алдын ала токендер үлесін бөлек есептеу.
Жақсы қарсы мысал тез-ақ ес жиғызады. Айталық, қысқа классификация тапсырмаларында модель жұбы кідірісті 18% азайтты. Команда қуанып, нәтижені бүкіл сервисте қолданады. Бірақ ұзын заңдық қорытындыларда дәл сол жұп нөл беруі немесе тіпті баяулатуы мүмкін, өйткені шағын алдын ала модель тым жиі қателеседі де, негізгі модель тексеруге уақыт жұмсайды.
Егер қорытынды тек бір сәтті сұраулар жиынына сүйенсе, бұл қорытынды емес. Бұл жай ғана тест үшін сәтті күн.
Іске қоспас бұрын
Спекулятивті декодтауды барлық сұрауға бірден қосу сирек дұрыс. Ол шағын алдын ала модель жалғастыруды жиі дәл тапқанда және негізгі модель сол токендерді ұзақ кері қайтарусыз растағанда ғана мағыналы.
Іске қоспас бұрын бірнеше нәрсені тексерген дұрыс. Жауап ұзындығына қараңыз. Егер модель әдетте 20-40 токен ғана жазса, үстеме шығын жиі пайданы жеп қояды. Жауап ұзағырақ болса, әсері көбірек көрінеді. Сосын жауаптар бір-біріне формасы жағынан ұқсас па, соны қараңыз. Қоңырау қорытындылары, сұрау карталары, өріс шығару және шаблонды хаттар еркін брейнштормингтен немесе күрделі талдаудан жақсырақ келеді.
Одан кейін тек орташа жылдамдықты емес, басқа нәрсені де өлшеңіз. Сізге қабылданған токендер үлесі, бірінші токенге дейінгі уақыт және жауаптың толық ұзындығы бойынша p95 керек. Орташа мән әдемі сурет салады, ал пайдаланушылар кейін ұзақ шеттерді көреді. Және сапаны міндетті түрде нақты деректерде салыстырыңыз, бес сәтті промптта емес. Егер шағын алдын ала модель негізгі модельді жиі қате тармаққа бұрса, жылдамдық шығынды өтемейді.
Іске қоспай тұрып схеманың керегі жоқ жерлерді де белгілеп алған пайдалы. Қысқа жауаптар, қабылдану үлесі төмен жағдайлар немесе қымбат кері қайтулар үшін бұл режимді тез сөндірген дұрыс, оны идеяның өзі үшін ұстамаңыз.
Жақсы белгі былай көрінеді: ұзын әрі құрылымы ұқсас жауаптар, токендерді тұрақты қабылдау және p95-тің айтарлықтай төмендеуі. Нашар белгі одан да қарапайым: орташа уақыт сәл жақсарған, бірақ шеттері ұзарған және сапа құбылып тұр.
Тәжірибеде командалар спекулятивті декодтауды бір сценарийде қосып, 15-20% плюс көріп, кейін нәтижені барлық тапсырмаға көшіреді. Бұлай жасауға болмайды. Бір жүйенің ішінде маршруттардың бір бөлігі ұтып, бір бөлігі ұтылуы мүмкін. Егер сіз мұны AI Router сияқты бір шлюз арқылы тексерсеңіз, режимді бүкіл трафикке емес, сұрау түріне қарай таңдаулы қосқан дұрыс.
Әрі қарай не істеу керек
Спекулятивті декодтауды барлық трафикке бірден таратпаңыз. Бір тапсырмадан бастаңыз: жауабы бірнеше сөйлемнен ұзын және кідірісті пайдаланушы немесе оператор айқын сезетін жерден. Пилотқа қоңырау қорытындысы, чаттағы ассистент жауабы немесе ұзын құжаттан өріс шығару жақсы келеді.
Бірден метрикаларды таңдаңыз, әйтпесе тест тез арада әсерге сүйенген дау болып кетеді. Әдетте төртеуі жеткілікті: кідіріс бойынша p50 және p95, шағын алдын ала модель қабылдаған токендер үлесі, 1000 сұрауға шаққандағы құн және шағын қолмен таңдамадағы сапа айырмасы. Егер сапа құбылса, жылдамдық оны құтқармайды.
Табыс шегін алдын ала жазып қойған пайдалы. Мысалы, схема p95-ті кемі 20% төмендетсе, сапа түспесе және құн 5%-дан артық өспесе, сәтті саналады. Әр команданың цифры бөлек болады, бірақ шек міндетті түрде керек. Әйтпесе тесті апталап созып, нәтижені әр жолы әртүрлі түсіндіре беруге болады.
Әрекет жоспары да қарапайым болуы тиіс: бір модель жұбын және бір сұрау түрін таңдаңыз, схемасыз және схемамен бірдей мысалдар жиынын жіберіңіз, қысқа сұрауларды ұзындардан бөліңіз де, әдіс қай кезде көмектесетінін, қай кезде бөгет болатынын белгілеп қойыңыз.
Кері қайтару жоспары бірінші күннен болуы керек. Қысқа сұраулар, бір-екі сөйлемдік жауаптар және күрделі пайымдаулар көбіне бүкіл пайданы жеп қояды. Ондай жағдайлар үшін бірден мынадай ереже қойған дұрыс: егер сұрау таңдалған шектен қысқа болса, егер қабылданған токендер үлесі нормадан төмен түссе немесе жауаптағы түзетулер көбейсе, жүйе кәдімгі режимге қайта оралсын.
Егер команда модельдерді AI Router арқылы бұрыннан салыстырып жүрсе, мұндай тестті өткізу оңайырақ. Шлюз жағында модель жұптары мен маршруттауды ауыстырып, клиент кодына, SDK-ға және промпттарға тимейсіз. Бұл уақыт үнемдейді және тәуекелді азайтады: инженерлер бір эксперимент үшін интеграцияны қайта жазуға апта жұмсамай, тезірек таза сандар алады.
Жақсы келесі қадам өте қарапайым: бір сценарийді таңдаңыз, пайда шегін қойыңыз, 500-1000 нақты сұрауды өткізіп, нәтижені кестеге сақтаңыз. Содан кейін ғана схеманы әрі қарай кеңейту керек пе, жоқ па — айқын болады.
Жиі қойылатын сұрақтар
Спекулятивті декодтау деген не, қарапайым тілмен?
Бұл екі модельден тұратын схема. Шағын алдын ала модель бірнеше келесі токенді тез ұсынады, ал үлкен модель сол бөлікті бірден тексеріп, сәйкес келгенін ғана қалдырады. Пайдасы үлкен модель бір токенді емес, қатар тұрған бірнеше токенді растай алғанда көрінеді.
Неге спекулятивті декодтау жауапты әрдайым жылдамдатпайды?
Өйткені схема қосымша қадам қосады. Алдымен шағын алдын ала модель жұмыс істейді, кейін үлкен модель тексеруге уақыт жұмсайды, ал сәйкестік әлсіз болса, сол тексеру бүкіл пайданың орнын басады. Қысқа жауаптарда бұл әсіресе жиі байқалады.
Қандай тапсырмаларда бұл тәсіл әдетте пайда береді?
Ең жақсы нәтиже ұзын әрі формасы ұқсас жауаптарда көрінеді. Қоңырау қорытындылары, өрістерді шығару, стандартты қолдау жауаптары және бекітілген құрылымы бар қысқа есептер жақсы келеді. Мұндай тапсырмаларда шағын алдын ала модель келесі бөлікті жиі дәл табады.
Қашан кәдімгі генерацияны қалдырған дұрыс?
Өте қысқа жауаптар, бір сөйлемдік репликалар және сирек токендері көп тапсырмалар үшін оны қоспаған дұрыс. Құжат нөмірлері, сомалар, есімдер, тауар кодтары және күрделі пайымдаулар сәйкес келу үлесін тез төмендетеді. Ондайда кәдімгі генерация жиі жылдамырақ әрі қарапайым болады.
Бұл схема бірінші токенді де жылдамдата ма?
Көбіне жоқ. Бірінші токен шамамен сол уақытта келуі мүмкін немесе тіпті сәл кешігуі мүмкін, өйткені жүйе алдымен шағын алдын ала модельді іске қосады. Бірақ ұзын жауапта жалпы уақыт көбіне айқын азаяды.
Тестте қандай метрикаларды өлшеу керек?
Бір орташа санға емес, бірден бірнеше метрикаға қараңыз: p50, p95, бірінші токенге дейінгі уақыт, толық жауап уақыты және қабылданған алдын ала токендер үлесі. Сондай-ақ бір жауаптың бағасын және 1000 шығатын токеннің құнын есептеңіз. Сонда тек сәтті, жылдам жағдайларды емес, баяу шеттерді де көресіз.
Әділ тексеру үшін қанша сұрау керек?
Алғашқы қорытынды үшін әдетте 100–200 нақты сұрау жеткілікті, егер таңдама әділ болып, қолмен іріктелмесе. Егер трафик жауап ұзындығы мен түрі бойынша қатты әртүрлі болса, 500–1000 сұрау алыңыз да, нәтижені сценарийлерге бөліңіз. Әйтпесе орташа сан нақты сәтсіздіктерді жасырады.
Шағын алдын ала модельді қалай таңдаймыз?
Бір ең кішкентай модельді емес, негізгі модельге ұқсас стильде және сөз тәртібімен жаза алатын модельді таңдаңыз. Көбіне бір отбасының модельдері немесе ұқсас нұсқаулықтармен үйретілгендері жақсы жұмыс істейді. Таңдағаннан кейін бір сәтті мысалға емес, өз деректеріңіздегі қабылданған токендер үлесіне қараңыз.
Бұл схема сапаны нашарлатуы немесе құнын өсіруі мүмкін бе?
Иә, мүмкін, сондықтан оны бөлек тексеру керек. Егер шағын алдын ала модель жиі қателессе, үлкен модель кері қайту мен түзетуге көбірек қадам жұмсайды, ал баға мен кідіріс өседі. Тек жылдамдықты емес, метка дәлдігін, қорытындының толықтығын немесе дұрыс толтырылған өрістер санын да қараңыз.
Спекулятивті декодтауды жұмыс істейтін сервиске қалай қауіпсіз қосуға болады?
Бір сценарийден бастап, табыс шегін алдын ала қойыңыз. Мысалы, режимді тек жауаптар белгіленген ұзындықтан асқанда, p95 шынымен төмендегенде және сапа түспегенде ғана қосыңыз. Егер AI Router арқылы модель жұптарын тексерсеңіз, маршруттауды шлюз жағында өзгертіп, клиент кодына тимей-ақ жұмыс істей аласыз.