RAG-тағы OCR қателері: индекске дейінгі лас мәтіннің 5 белгісі
RAG-тағы OCR қателері іздеуді, дәйексөздерді және жауаптарды бұзады. Лас мәтіннің 5 белгісін, жылдам тексерістерді және индекске дейінгі тазалау тәртібін талдаймыз.
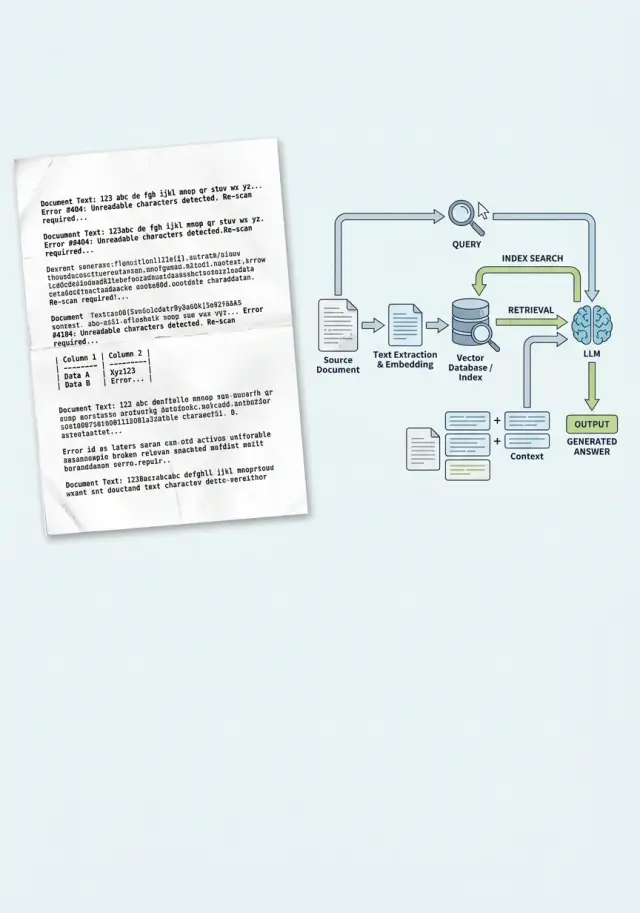
Неге мәселе индекстен бұрын басталады
RAG көбіне жауапты генерациялау сәтінде емес, одан бұрын бұзылады. Ақау жүйе құжатты алғаш рет мәтін ретінде оқығанда пайда болады. Егер OCR қателессе, индекс құжаттың мағынасын емес, бұзылған көшірмесін сақтап қалады. Кейін іздеу дәл сол шуды адал түрде тауып береді.
Бұл әсіресе шарттар, шоттар және актілердің скандарында анық көрінеді. OCR ұқсас таңбаларды шатастырады: "О" мен "0", "l" мен "1", "S" мен "5", пайыз белгісін, бөлшек сызығын немесе тармақ нөмірін жоғалтады. Адам үшін бұл ұсақ нәрсе. Ал іздеу үшін бұл — басқа токен, кейде тіпті басқа факт.
Көбірек байқалмайтын тағы бір мәселе бар. Скан абзац шекарасын бұзады, көрші жолдарды біріктіреді және кестені сөздер мен сандардың жиынтығына айналдырады. Төлеу мерзімі туралы тармақ реквизиттермен жабысып қалуы мүмкін, ал сома тұрған баған басқа блоктың ортасына түсіп кетеді. Осындай мәтінді чанкке бөлгенде, әр бөлік әу бастан бұзылған болады.
Индекс құжатты емес, ішінде қоқыс пен жоғалған құрылымы бар фрагменттер жиынтығын алады. Эмбеддингтер OCR қателескен жерді "болжай" алмайды. Олар өздеріне берілген мәтін бойынша құралады. Егер "ставка 12%" орнына жүйе "ставка l2" не болмаса ыдырап кеткен жолды көрсе, іздеу дұрыс емес фрагментті тартады.
Сондықтан жауабы нанымды, бірақ қате болып шығады. Модель ресми мәтінге ұқсас нәрсені көреді де, сенімді жауап береді. Бұл әрдайым "галлюцинация" емес. Көбіне оған жай ғана нашар негіз берілген.
Тәжірибедегі сценарий қарапайым: қызметкер шарттың сканын жүктейді, OCR екі тармақты біреуіне біріктіреді, индекс сол бөлікті сақтайды, ал кейін айыппұл туралы сұрау жеткізу мерзімі жайлы блокты қайтарады. Модель оны негіз етіп алып, жинақы жауап жазады. Қате индекстеуге дейін-ақ пайда болған.
Сондықтан RAG-та OCR тек тану сапасымен ғана қауіпті емес. Ол жүйенің нені білім деп санайтынын өзгертеді. Мәтінді жүктемей тұрып тексермесеңіз, нәтиже — ұқыпты пайплайн, бірақ ол үнемі бұзылған дерекке сүйенеді.
Лас мәтіннің бес белгісі
Лас OCR-ды индекстеуге дейін-ақ көбіне байқауға болады. Айласы мынада: мәтін көбіне "шамамен дұрыс" көрінеді. Адамға бұл жетеді, ал іздеу үшін — жоқ. RAG токендерге, көрші сөздерге және құжат құрылымына сүйенеді. Егер OCR осы қабаттардың кемінде екеуін бұзса, жауаптар ауытқи бастайды.
- Әріптер мен сандар орын ауыстырып шатасады. Ең жиі кездесетіні — O мен 0, I мен 1, S мен 5. Шарттарда бұл шот нөмірлерін, даталарды, сомаларды және артикулдарды бұзады.
- Сөздер бөлініп кетеді немесе жабысып қалады. "Жауапкершілік" және "мерзімшарт" таныс сияқты көрінеді, бірақ олар бойынша іздеу нашар жұмыс істейді, ал эмбеддингтер қалыпты тіркес орнына шу алады.
- Кестелер пішінін жоғалтады. Жолдар, бағандар және атаулар араласып кетеді, сондықтан модель сома, мерзім немесе мөлшерлеме ненің қасына тиесілі екенін түсінбей қалады.
- Қызметтік қоқыс негізгі мәтінге кіріп кетеді. Колонтитулдар, бет нөмірлері және қолтаңбалар кенет абзацтың ортасына түседі. Соның салдарынан әр екінші фрагмент "4-бет 12-ден" деп басталып, мағына жағынан ол жай ғана бос шу болып шығады.
- Мәтін бөліктері қайталанады. OCR көбіне бет түйіскен жердегі жолды қайта жазады немесе мөрі мен астарлы фоны бар блокты қайтадан оқиды.
Жеке алғанда бұл ақауларға шыдауға болады. Бірге келгенде retrieval-ды тез бұзады. Шарт сканында тарифтер кестесі ыдырайды, бет нөмірі абзацтың ортасына түседі, ал "10 000" "I0 OOO" болып кетеді. Адам не айтылмақ болғанын түсінеді. Индекс — әрдайым емес.
Мұндай бұзылулар нақты сұрақтарда ерекше байқалады: лимит, мерзім, мөлшерлеме немесе шарттың нақты тармағы туралы сұрағанда. Жүйе керек фрагменттің орнына көрші бөлікті көтереді, өйткені керек сөздер шашырап кеткен немесе қоқыспен араласқан. Кейде жауап сенімді естіледі, бірақ басқа бөлімге сүйенеді. Бұл ашық қатеден де жаман.
Тексеру оңай: шикі мәтінді пішімдеусіз ашып, қатарынан 20-30 жолды оқып шығыңыз. Егер көз әр екі сөйлем сайын іркілсе, индекстеуге әлі ерте. Бір құжатта тізімдегі кемінде екі белгі көрінсе, оны алдымен тазалап, содан кейін ғана чанкке бөлу керек.
RAG жауаптарында не бұзылады
Пайдаланушы сирек "нашар OCR" дегенді мәселенің себебі ретінде көреді. Ол басқа нәрсені байқайды: дәл емес жауап, біртүрлі цитата, түпнұсқамен сәйкес келмейтін шарт нөмірі.
Бірінші белгі — іздеу керек абзацты таба алмайды. Құжат индексте бар, бірақ OCR сөзді бөлді, жолдарды жапсырды немесе кестені бүлдірді. Адамға сөйлем әлі де оқылатын сияқты, ал іздеу үшін ол — басқа мәтін. Төлеу мерзімі туралы абзацтың орнына жүйе жалпы шарттары бар көрші блокты шығарады да, жауап басқа жаққа кетеді.
Одан кейін цитаталар бұзыла бастайды. Модель түпнұсқаға ұқсас, бірақ сөзбе-сөз сәйкес келмейтін фрагментке сүйенеді. Шартта "төлем 15 күнтізбелік күн ішінде" деп тұрса, жауапта кенет "10 күн" пайда болады немесе "күнтізбелік" сөзі түсіп қалады. Заңгер, банк немесе сатып алу бөлімі үшін бұл — жұмыс деңгейіндегі қате.
Ең жаманы — OCR әр таңбасы маңызды болатын мәндерді бұзады: сомалар, күндер, ИИН, шарт және қосымша нөмірлері. "8 000 000" "800 000" болып кетеді, 03.06.2024 күні келесі жолға ауысады, ал шарт нөмірі беттің тақырып жолынан бір бөлікті іліп әкетеді. Модель өзіне берілген мәтін бойынша жауап береді, бірақ жауап енді қате.
Жұмыста бұл әдеттегідей көрінеді. Команда шарттың сканын жүктеп, жүйеден мерзімі өткендегі айыппұлды табуды сұрайды. Егер OCR бір бетті екі рет таныса, көшірмелер іздеудің жоғарғы бөлігіне жиналып қалады. Іздеу әртүрлі релевант абзацтардың орнына бір-біріне ұқсас үзінділерді қайтарады. Модель тар әрі шуыл көп контекст көреді, сондықтан керек жауап төменде жатса да, бір фрагментті қайта-қайта айта береді.
Тағы бір тұзақ бар. Модель жетіспейтін сөздерді өзі толтыра бастайды. Егер OCR "5 жұмыс күніне дейін" деген тіркестің бір бөлігін жұтып қойса, контексте "... күннен кешіктірмей" дегендей ғана қалуы мүмкін. Тілдік модель мұндай олқылықты үлгі бойынша оңай толтырады. Кейде дұрыс. Кейде көрші абзацтан сандарды алады.
Әдетте ақау бірнеше белгі арқылы бірден көрінеді: жауап сенімді естіледі, бірақ цитата PDF-пен сәйкес емес; іздеу бірдей чанк-тарды қайта қайтара береді; сомалар мен даталар әр жауапта өзгеріп кетеді; жүйе нақты сұрақты елемей, жалпы тұжырымдарға ауысады.
Егер бұл тесттерде-ақ байқалса, жаңа модель сирек құтқарады. Алдымен мәтінді индекске дейін тексеріңіз. Әйтпесе RAG тез әрі ұқыпты қателеседі.
Жүктеместен бұрынғы жылдам тексерістер
Индекстеуге дейін 15-20 минут жеткілікті — проблемалардың көп бөлігін іріктеп тастауға болады. Егер бұл қадамды өткізіп жіберсеңіз, команда кейін RAG-ды емес, дереккөздегі қоқысты жөндейді.
Қолмен іріктеуден бастаңыз. Бір сәтті PDF-ті ғана емес, әртүрлі құжаттардан 20-30 бетті алыңыз: бірінші бетті, ортасын, соңын, кестесі бар бетті, ескертпелері барын, мөрі барын, контрасті нашарын. OCR әдетте барлық жерде бірдей бұзылмайды. Көбіне ол ең ыңғайсыз жерлерде сүрінеді.
Алдымен нақты мәндерді тексеріңіз. Шарт нөмірлері, ИИН, сомалар, даталар, артикулдар және пайыздар ойланбай-ақ оқылуы керек. Егер "12.03.2024" "12.O3.2024" болып кетсе, ал "№ 451-7" "N 45l-7" түріне ауысса, іздеу мен жауаптар өте сенімді түрде өтірік айта бастайды.
Сосын беттерді тез шолып, қоқыс таңбаларын іздеңіз: "@#|" сияқты тізбектер, кириллица ішіне кірген кездейсоқ латын әріптері, бөлініп кеткен сөздер, бір жолдың қайталануы, арасына бос орын түспеген мәтін бөлігі. Бір жаман абзац қорқынышты емес. Егер мұндай жерлер әр бесінші бетте кездессе, индексті таза деуге болмайды.
Верстканы бөлек тексеріңіз. Екі бағанды құжаттарда OCR көбіне сол және оң бағанды бір жолға жабыстырып тастайды. Сноскаларда да ұқсас жағдай: негізгі мәтін төменге секіреді де, содан кейін абзацтың ортасына ұсақ қаріптегі ескертпе түсіп кетеді. RAG үшін бұл әсіресе жағымсыз, өйткені чанк байланысқан сияқты көрінеді, ал ішкі мағына әлдеқашан бұзылған.
Автоматты тесттерді күрделі жүйесіз де жасауға болады. Ерекше қысқа немесе тым ұзын мәтіні бар беттердің үлесін есептеу, оғаш таңбалар үлесі жоғары жолдарды табу, абзац қайталануларын тексеру және көрші чанк-тарды жиі қайталанатын дубликаттарға салыстыру жеткілікті.
Дубликаттар әсіресе зиянды. Егер бір фрагмент индексқа үш рет түссе, retrieval оны басқалардан жиірек тартады, ал жауап "сенімді" көрінгенімен, қайталауға сүйенеді.
Пайдалы минимум мынадай: іріктемені қолмен қарап шығу, нақты нөмірлер мен даталарды тексеру, қоқыс таңбаларын ұстау, бағандар мен сноскалардың араласпағанына көз жеткізу, әрі дубликаттарды чанкке бөлуге дейін немесе одан кейін бірден алып тастау. Егер құжат осы жиыннан өтпесе, оны индекске салу ерте.
Мәтінді қадамдап тазалау
Лас OCR сирек бір ғана баптаумен түзеледі. Қысқа тізбекпен жүрген дұрыс: нашар файлдарды бөлу, айқын шуды алып тастау, мәтінге қалыпты пішін қайтару және содан кейін ғана индекске жіберу. Әйтпесе жүйе қоқысты сақтап, оны жауаптарда сенімді түрде цитаталайды.
Алдымен нашар файлдарды бөліңіз
Барлық құжатты бір үйіндіге салмаңыз. Шарт, шот, хат сканы және кесте әртүрлі бұзылады. Оларды бір ағынға араластырсаңыз, қате шаблоннан ба, әлде бастапқы сканнан ба — түсіну қиын болады.
Екі белгі бойынша қарапайым топтастыру жеткілікті: құжат түрі және сурет сапасы. Құжат түрі үшін "шарттар", "актілер", "сауалнамалар" және "кестелер" сияқты санаттар жетеді. Сапа үшін үш бөлік ыңғайлы: жақсы скан, төзуге болады және нашар. Нашар файлдарды автоматты түрде ары қарай өткізбеген дұрыс. Оларды кейін RAG-дың біртүрлі жауаптарын талдағаннан гөрі, қайта сканға жіберу арзан.
OCR-ға дейін бетінің өзін тексеріңіз. Егер мәтін бірнеше градусқа болса да қисайып тұрса, жүйе жолдарды жиі жабыстырады. PDF ішінде бос беттер, бөлгіштер, шетінде қара өрістер немесе дубликаттар болса, оларды бірден алып тастаңыз. Үлкен жиында бұл ойлағаннан да көп уақыт үнемдейді.
Сосын мәтін құрылымын қалпына келтіріңіз
Танығаннан кейін OCR әр бетте сүйретіп жүретін қайталанатын бөліктерді алып тастаңыз: колонтитулдар, бет нөмірлері, қызметтік қолтаңбалар, сканер белгілері. Әйтпесе іздеу оларды маңызды сөздер деп ойлап, дұрыс емес фрагментті ұсынып қалады.
Кейін абзацтарды қалпына келтіріңіз. OCR көбіне бір ойды бес жолға бөледі немесе керісінше бүкіл бөлімді тұтас блокқа жабыстырады. RAG үшін бұл жаман: чанк-тар кез келген жерден кесіледі де, мағына шашырап кетеді. Негізгі ережелер қарапайым: бір абзацтың ішіндегі жолдарды жабыстырыңыз, абзацтардың арасында бос жол қалдырыңыз, нөмірлеу мен тізім белгілерін сақтаңыз, ал кестелерді түсінікті мәтіндік түрге келтіріңіз.
Кестелерге байсалды қараған жөн. Егер OCR бағандарды қоймалжыңға айналдырса, оларды "өріс - мән" жұптары ретінде немесе әр жазба бойынша қысқа жолдармен қайта жазыңыз. Мұндай мәтін әлдеқайда жақсы индекстеледі.
Нәтижені қайта индекстеуге дейін тексеріңіз. Әр топтан 10-20 құжат алып, абзацтар оқыла ма, тақырып қайталанбай ма, тізімдер мен кестелер бұзылмап па — соны қараңыз. Осы бөліктердің біреуі болса да ауытқыса, индексті жаңартуға әлі ерте.
Бір шартта бұл қарапайым көрінеді: беттерді түзедіңіз, екі бос бетті алып тастадыңыз, лист нөмірлерін қиып тастадыңыз, абзацтарды біріктірдіңіз, реквизиттер кестесін "өріс - мән" түріне келтірдіңіз де, мәтінді қайта тексердіңіз. Тек содан кейін ғана оны индекске жіберу керек. Әйтпесе қателікті жай ғана жылдам жүктейсіз.
Бір шарт мысалы
Команда RAG-қа 24 беттен тұратын жеткізу шартының сканын жүктейді. Әр бетте мөр, төменде қолтаңба және ұсақ төменгі колонтитул бар: бет нөмірі, дата, шаблон нөмірі. Негізгі мәтін жақсы оқылады, бірақ жауапкершілік бөлімі ең нашар көрінеді: жұқа қаріп, тығыз абзацтар, тармақтардың жанындағы қысқа сандар.
OCR мәтінді біркелкі алмайды. 8.4-тармақта ол жолдың басын бет колонтитуімен бірге оқып, оларды бір фрагментке жабыстырады. "8.4 Жеткізуші тапсырыс берушіні 10 жұмыс күні ішінде хабардар етуге міндетті" орнына индексқа шамамен "8.4 24/24 форма D-17 Жеткізуші тапсырыс берушіні..." сияқты нәрсе түседі. Келесі бетте ұқсас кедергі 8.5-тармаққа жабысады.
Мәселе кейін білінеді. Пайдаланушы шартты бұзу туралы қанша күн бұрын ескерту керек деп сұрағанда, іздеу 8.4 емес, көрші 8.5-тармақты табады. Онда да хабарлама туралы айтылған, бірақ ол бағаның өзгеруі жайлы, ал мерзім басқа — 5 күн. Модель сенімді жауап береді, цитата нанымды көрінеді, ал себеп лас OCR мәтінінде жатады.
RAG-тағы көптеген қателер дәл осылай көрінеді: бұзылғаны жауаптың өзі емес, жүйе ең жақын деп санаған фрагмент.
Мұнда қысқа тексеріс көмектеседі. Ұсақ қаріпті 3-5 бетті ашып, суретті OCR жолдарымен салыстырыңыз. Төменгі колонтитул абзацтың ортасына қайталанбай ма — соны қараңыз. Тармақ нөмірлері секіріссіз және жабыспай ретімен келе ме, тексеріңіз. Содан соң екі күмәнді тармақ бойынша тест сұрау қойып, іздеудің қай фрагментті көтергенін көріңіз.
Бұл мысалда мәселе тез табылды: мәтінде бөлім нөмірінің жанында қоқыс бар және төменгі жол қайталанады. Одан кейін құжатты күрделі сиқырсыз тазалайды: беттің жоғарғы және төменгі аймақтарын қиып тастайды, OCR-ды қайта өткізеді, ұсақ қаріптегі блоктарды бөлек тексереді де, тек содан кейін мәтінді индекске жібереді.
Тазалаудан кейін іздеу енді керекті үзіндіні қайтарады — бөтен сандар мен қызметтік жолдарсыз 8.4-тармақты. Модель дұрыс фрагментке сүйеніп, нақты жауап береді: хабарлама 10 жұмыс күні бұрын жіберілуі керек. Айырмашылық ұсақ сияқты, бірақ шарт үшін бұл енді жай косметика емес, мағына.
Командалар қай жерде жиі қателеседі
Қателер көбіне модельде де, индексте де басталмайды. Көбінесе команда мәтінді "жеткілікті таза" деп тым ерте есептеп, оны сол күйі пайплайнға жүктей салады.
Бірінші типтік қателік — шикі OCR-ды қолмен іріктемей алу. Адамдар екі-үш сәтті файлды қарап, мәтін оқылатын сияқты екенін көреді де, бүкіл партия дұрыс деп ойлайды. Кейін құжаттардың жартысында бағандар жабысып қалғаны, жол ауысулары бұзылғаны, ал тармақ нөмірлері таңбалар жиынына айналғаны анықталады. Тіпті 20-30 файлдан тұратын іріктеме де жалпы "тану сәттілігі" пайызынан шынайырақ сурет береді.
Екінші қателік — барлық құжат түрін бірдей өңдеу. Шарт, шот және сауалнама тек "ішінде мәтін бар" деген деңгейде ғана ұқсас. Шын мәнінде құрылым әртүрлі: шартта тармақтар мен қосымшалар маңызды, шотта жолдар, сомалар және даталар маңызды, сауалнамада "сұрақ - жауап" жұптары мен белгішелер маңызды. Егер бәрін бір тазалау және бөлу шаблонынан өткізсеңіз, мағына іздеуге дейін-ақ бұзылады.
Тағы бір жаман әдет — мәтінді тым кеш, эмбеддингтерден кейін тазалау. Егер индекс қоқыс фрагменттерін алып қойса, оларды әлдеқашан жаттап үлгереді. Кейін команда дереккөзді түзетеді, бірақ жауаптар жаңа шу қосылмайынша ескісін тарта береді — индекс қайта жиналмайынша.
Бөлек проблема — беттердің қайталануы және бір құжаттың әртүрлі нұсқалары. Индекске нобай, қол қойылған көшірме, басқа қалтадан алынған сол көшірменің сканы және бет бағыты басқа тағы бір дубликат түсіп кетеді. RAG қайсысы дұрыс екеніне емес, қайсысы көп кездесетініне "дауыс береді". Нәтижесінде жауап шарттың ескі редакциясына сілтеме жасауы мүмкін, тек оны үш рет жүктегендіктен.
Ақырында, командалар мәтін мен дереккөздің байланысын жиі жоғалтады. Таза фрагментті бет нөмірінен, файл атауынан және құжат нұсқасынан бөлек сақтайды. Жүйе демо режимінде тұрғанда бұл байқалмайды. Заңгер, аудитор немесе аналитик жауаптың дереккөзін көрсетуді сұраған сәтте, қалталар бойынша қолмен іздеу басталады.
Банк, клиника немесе мемлекеттік сектор үшін бұл әсіресе жағымсыз. Егер жүйе бет пен құжатты көрсете алмаса, жауап формалды түрде дәл болса да, оған сенбейді.
Сондықтан әр фрагменттің жанында кемінде құжат түрін, бет нөмірін, файл не нұсқа идентификаторын және дубликат немесе жақын көшірме белгісін сақтаған дұрыс. Бұл ұсақ нәрсе сияқты, бірақ кейін оғаш жауаптарды талдауға сағат үнемдейді. Егер индексқа нұсқа, бет және дубликатты тексеру жоқ мәтін түссе, мәселені көбіне жұмыс істеп тұрған жүйеде түзетуге тура келеді.
Әрі қарай не істеу керек
Бүкіл архивті бірден жүктемеңіз. Алдымен индекстен бұрын бет сапасының қарапайым шегін қойыңыз: мәтін қатарынан оқылады, қызметтік қоқыс абзацтарды жауып тастамайды, кестелер ыдырамайды, ал бетте "п0дпись/п0дпись/п0дпись" сияқты ұзын тізбектер жоқ. Мұндай шек әдемілік үшін емес керек. Ол сенімді, бірақ қате жауаптардың тәуекелін азайтады.
Құжаттарды екі ағынға бөлу пайдалы. Шектен өткендері әрі қарай жүреді. Шектен өтпегендері бөлек қарау кезегіне кетеді. Оларды араластырмаңыз, әйтпесе қате қайдан шыққанын кейін ажырату қиын болады — модельден бе, чанкингтен бе, әлде мәтіннің өзінен бе.
Бастапқыда бүкіл база емес, шағын іріктеме жеткілікті. Бір типтегі 30-50 құжатты алыңыз, мысалы шарттар немесе актілер, және оларды тазалауға дейін және кейін бірдей сұрақтар жинағында салыстырыңыз. Айырмашылық әдетте тез көрінеді: модель даталарды азырақ шатастырады, сомаларды азырақ жоғалтады және керек фрагментті жақсырақ цитаталайды.
Егер команда RAG үшін бірнеше модельді сынап жүрсе, бірдей индексті ұстап, тек модельді ауыстырған дұрыс. Сонда мәселе индексте ме, әлде модельдің өз мінез-құлқында ма — анық көрінеді. Кемінде екі-үш модельдің жауаптарын бірдей сұрақтарда және бірдей контексте салыстырыңыз: керек фрагментті қаншалықты дәл табады, артық нәрсе қоспай ма, "табылмады" деп адал айта ала ма және кестелер мен сноскаларда шашырамай ма.
Мұндай тексеріс үшін SDK мен ағымдағы промпттарды қайта жасамай-ақ модельдерді ауыстыру ыңғайлы болғаны жақсы. Бұл жерде AI Router көмектесе алады: сервисте бір OpenAI-үйлесімді эндпоинт бар, сондықтан командаға әртүрлі модельдерді салыстыру кезінде кодты өзгерту қажет емес. Қазақстандағы командалар үшін бұл деректерді ел ішінде сақтау маңызды болса және B2B-инвойсингті теңгемен жүргізу керек болса да, практикалық нұсқа.
Мінсіз пайплайн күтпеңіз. Қарапайымдылық жеткілікті: сапа шегін енгізу, нашар беттерді бөлек кезекке жіберу және шағын іріктемеде қысқа A/B тест өткізу. Осыдан кейін командада лас OCR кедергі жасап тұр деген жалпы сезім емес, нақты беттер тізімі, тазалау ережелері және индекс қай сұрақтарда бұзылатыны туралы деректер пайда болады.
Жиі қойылатын сұрақтар
Қайсысы қате екенін қалай түсінуге болады: OCR ме, әлде модель ме?
Көбіне оны дереккөздегі іздерден байқауға болады. Жауап сенімді естіледі, бірақ цитата PDF-пен сәйкес келмейді, сомалар мен даталар құбылады, ал іздеу керек абзацтың орнына көрші бөлікті көтереді.
Шикі мәтінді пішімдеусіз ашып, оны түпнұсқаның 20–30 жолымен салыстырыңыз. Егер OCR таңбаларды шатастырса, жолдарды жапсырса немесе бет колонтитулын абзацтың ортасына кіргізсе, ақау модельге дейін басталған.
OCR қай құжаттарды жиі бұзады?
Ең көп зардап шегетіні — шарттардың, шоттардың, актілердің және сауалнамалардың скандары. Онда әр таңба маңызды, ал OCR нөмірлерді, даталарды, пайыздарды және қысқа тармақтарды жиі бұзады.
Әсіресе кестелері, сноскалары, мөрлері, ұсақ қарпі және контрасті нашар беттер зардап шегеді. Дәл солардың үстінде іздеу көбіне көрші фрагментке ауып кетеді.
Бүкіл архивті қолмен тексеру керек пе?
Жоқ, бүкіл архивті қолмен қарап шығудың қажеті жоқ. Көбіне 20–30 беттен тұратын іріктеме немесе бір типтегі 30–50 құжат жеткілікті.
Тек сәтті файлдарды емес, бәрін араластырып қараңыз. Бастапқы, ортаңғы, соңғы беттерді, кестелері бар беттерді, мөрі мен ұсақ қарпі бар беттерді тексеріңіз. Сонда OCR қай жерде жиі сүрінетінін тез түсінесіз.
Индекс алдында шикі мәтінде не тексеру керек?
Мағынаны бұзатын нәрселерге қараңыз: даталар, сомалар, шарт нөмірлері, ИИН, пайыздар және артикулдар. Егер мұнда "O" орнына "0" немесе "l" орнына "1" сияқты шатасу болса, индекс қате істей бастайды.
Сосын құрылымды тез бағалаңыз. Мәтін қатарынан оқылуы керек, ішінде қоқыс таңбалар, жол қайталанулары, жабысып қалған бағандар және абзац ортасындағы кенет бет нөмірлері болмауы тиіс.
Неге кестелер RAG жауаптарын жиі бұзады?
Өйткені нашар OCR-дан кейін кесте бағандар арасындағы байланысты жоғалтады. Сома, мерзім және мөлшерлеме мәтінде қалады, бірақ ненің қайсысына қатысты екені түсініксіз болады.
Егер кесте ыдырап кетсе, оны сол күйі индекстеуге болмайды. Жолдарды "өріс: мән" түрінде қайта жазған дұрыс немесе әр жазбаны бөлек мәтіндік блок ретінде сақтаған дұрыс.
Құжатты қай кезде бірден тоқтатып, индекстемеу керек?
Егер көз мәтінге әр екі сөйлем сайын іркілсе, құжатты индекске жібермеңіз. Бұл қарапайым, бірақ адал тест.
Егер бетте бағандар араласса, төменгі колонтитул қайталанса, сандар тек жорамалмен оқылса немесе бір абзац бірнеше рет кездессе, алдымен құжатты тазалаңыз немесе жаңа скан сұраңыз.
Текстті чанкингке дейін тазалау керек пе?
Иә, алдымен тазалау, содан кейін чанкинг. Егер сіз лас мәтінді бөліктерге бөлсеңіз, әр чанк қателікті іздеуге әрі қарай алып кетеді.
Алдымен қайталануларды, колонтитулдарды, бос беттерді және жол жабыстыруларын алып тастаңыз. Тек содан кейін мәтінді фрагменттерге бөліп, индекс құрыңыз.
Бет дубликаттары мен бір құжаттың әртүрлі нұсқаларымен не істеу керек?
Дубликаттармен бірден айналысу керек. Әйтпесе іздеу ең дұрыс фрагментті емес, индекс ішінде жай ғана жиі қайталанатын бөлікті тарта береді.
Әр фрагменттің жанында бет нөмірін, файл атауын және құжат нұсқасын сақтаңыз. Сонда жауаптың қайдан келгенін тез көресіз де, нобайды қол қойылған көшірмемен шатастырмайсыз.
OCR қателесіп қойған болса, жаңа модель құтқара ма?
Әдетте жоқ. Жаңа модель ұқыптырақ сөйлей алады, бірақ ол бәрібір индексте жатқан мәтінге сүйенеді.
Мұны оңай тексеруге болады: бір индексті қалдырып, екі-үш модельге бірдей сұрақтар қойыңыз. Егер бәрі бірдей жерлерде сүрінсе, мәселе дереккөзде немесе іздеуде, модельдің өзінде емес.
Команда RAG-ты скандарда енді ғана енгізіп жатса, неден бастау керек?
Кішіден бастаңыз: бір типтегі құжатты алыңыз, бет сапасының шегін қойыңыз және нашар скандар үшін бөлек кезек ашыңыз. Осыдан-ақ көп грубый ақауды алып тастауға болады.
Егер бірнеше модельді салыстырсаңыз, бір индексті ұстаңыз да, тек модельді ауыстырыңыз. Мұндай тексеріс үшін SDK мен қазіргі промпттарды қайта жасамай-ақ, бір OpenAI-үйлесімді эндпоинт арқылы модельдерді ауыстыру ыңғайлы.