RAG-та білімді толық қайта индексациясыз жаңарту
RAG-та білімді толық қайта индексациясыз жаңарту: өзгерген құжаттарды қалай табуға, қажетті чанктарды қайта есептеуге және ескі жауаптарды нәтижеден алып тастауға болады.
Неліктен ескі жауаптар іздеуде қалып қояды
Проблема жауап генерациясы кезінде емес, одан бұрын - индексте басталады. Сіз құжатты жаңартасыз, бірақ ескі чанктар өздігінен жоғалып кетпейді. Іздеу оларды әлі де сұраққа мағыналық жағынан сәйкес деп есептейді, себебі олар пайдаланушы сұрағына әлі де ұқсайды.
RAG-та білімнің ескіруі көбіне осылай бұзылады. Құжаттың жаңа нұсқасы жүктеліп қойған, ал ескісі векторлық базаға, іздеу кэшіне немесе қызметтік кестеге қалып қояды. Нәтижесінде жүйе бірден екі жад қабатына қарайды: өзекті және ескірген.
Файл күні көп көмектеспейді. Retriever көбіне updated_at өрісі бойынша шешім қабылдамайды. Ол сұрауды чанк мәтінімен, оның эмбеддингінмен және индекстеу кезінде жазған метадеректермен салыстырады. Егер ескі және жаңа құжаттың атауы бірдей, тақырыбы ұқсас, мәтіні де шамалас болса, нәтижеге екі жиын фрагмент те түсіп қалады.
Әсіресе нүктелік түзетулер қиын. Адам үшін ответ клиенту в течение 3 дней дегенді в течение 1 дня деп ауыстыру құжаттың мағынасын өзгертеді. Ал индекс үшін мәтіннің 90%-ы бұрынғыдай қалады. Ескі және жаңа чанктар бір-біріне тым ұқсас болып көрінеді, сондықтан іздеу оларды бірге қайтарып жібереді.
Одан кейін әдетте екі сценарийдің бірі болады. Не ескі чанк жоғарырақ көтеріледі, өйткені сұрақтың тұжырымы өткен редакцияға жақынырақ. Не екі нұсқа да бір контекстке түсіп, модель жауапты әртүрлі құжаттардан жинайды: санды ескі мәтіннен алады, түсіндірмені жаңасынан алады. Пайдаланушы сенімді көрінетін, бірақ қате жауап алады.
Сондықтан қате әсіресе өкінішті болып көрінеді. Команда білім базасы жаңарды деп ойлайды, ал жүйе әлі де ескі саясатқа, бұрынғы тарифке немесе күшін жойған тәртіпке сілтеме жасайды. Банк, медицина немесе ішкі регламент үшін бұл жай ұсақ қате емес, нақты қауіп.
Егер құжат нұсқаларын бақыламасаңыз және ескі чанктарды іздеуден шығармасаңыз, жүйе өткен мен қазіргісін араластыра бастайды. Модель мұнда "өтірік айтып" тұрған жоқ. Ол жай ғана сіз индексте қалдырған дерекке сүйеніп жауап береді.
Құжатты оның нұсқасынан қалай ажыратуға болады
Шатасу көбіне қарапайым қателіктен басталады: әр жаңа жүктеу бұрынғысымен байланысы жоқ жеке құжат ретінде өмір сүреді. Онда іздеу ескі мәтінді де, жаңасын да көреді, ал жүйе қай жауапты өзекті деп санау керегін түсінбейді.
Ең дұрысы - екі нысанды бірден бөлу: бұл қандай құжат және оның қай редакциясы. Құжатқа тұрақты source_id керек. Ол файл атауының өзгеруінен, басқа бумаға көшуінен немесе қайта жүктеуден өзгермеуі тиіс. Егер бұл демалыс ережесі болса, ол заңгер оны алдымен final_v3.docx, кейін final_v4_really.docx деп жіберсе де, сол бір дереккөз болып қала береді.
version_id-ді бөлек сақтаңыз. Бұл нақты редакцияның идентификаторы. Бір source_id үшін бірнеше нұсқа болуы мүмкін. Мұндай схема проблеманың жартысын тез шешеді: қазір қай нұсқа белсенді екенін, қайсысы архивке кеткенін және модель бір апта бұрын қай нұсқаға сүйеніп жауап бергенін түсінуге болады.
Әр чанк та қайдан шыққанын білуі керек. Фрагменттерді өздігінен сақтамаңыз. Оларды source_id және version_id-ке байлап қойыңыз, сонда жүйе ескі бөлікті дәл өшіріп, жаңасын оның орнына қалдыра алады.
Егер нұсқа белгілі бір күннен бастап күшіне енсе, valid_from және valid_to өрістерін сақтау пайдалы. Сонда ескі редакция із-түзсіз жоғалып кетпейді. Ол тарихта қалады, бірақ енді әдеттегі іздеуге қатыспайды. Аудит үшін бұл өте ыңғайлы.
Жұмыс және архив қабатын бөлек ұстаған дұрыс. Жұмыс қабатында тек өзекті чанктар жатады. Архив қабатында - тексеру, кері қайтару және даулы жауаптарды талдау үшін өткен нұсқалар тұрады. Егер бәрін бір коллекцияға араластырып, тек ұқыпты фильтрлерге сенсеңіз, ерте ме, кеш пе біреу бір параметрді ұмытып кетеді де, ескі норма қайтадан нәтижеге шығады.
Жақсы схема көзге түспей тұрғандай көрінеді. Бұл - артықшылық. Бір регламенттің бір абзацы өзгерсе, қандай чанктарды жабу керек, қайсысын қайта есептеу керек және нені архивте қалдыру керек екенін нақты білесіз.
Қандай өрістерді сақтау керек
Ең оңай алғашқы қадам - жаңа нұсқаның хешін есептеп, оны бұрынғысымен салыстыру. Бірақ бүкіл құжатқа бір ғана хеш жетпейді. Егер сіз тек бір бақылау сомасын сақтасаңыз, мәтіндегі түзетуді метадеректердің ауысуынан ажырата алмайсыз. Ал бұл жаңарту құнына да, жұмыс көлеміне де әсер етеді.
Тәжірибеде екі соманы бөлек ұстаған дұрыс: text_hash және metadata_hash. Сонда пайплайнның жұмысы түсінікті болады. Егер тек бөлім тегі, иесі немесе қолданылу мерзімі өзгерсе, құжат карточкасын және фильтрлерді жаңарту жеткілікті. Егер мәтіннің өзі өзгерсе, әсер еткен чанктарды қайта құрып, ескілерін іздеуден алып тастау керек.
Әдетте мынадай өрістер жеткілікті: source_id, version_id, text_hash, metadata_hash, updated_at, is_active. Егер мәселелерді тезірек талдағыңыз келсе, өзгеріс авторын немесе түзетуді енгізген процестің идентификаторын қосыңыз.
Өзгерістер журналы әсемдік үшін керек емес. Іздеу кенеттен ескі редакцияға жауап бере бастаса, жаңа нұсқаны кім жүктегенін, қашан болғанын және құжат жаңарту циклінің толық өткен-өтпегенін бірден көресіз. Кемі үш нәрсені сақтау пайдалы: уақыт, бастамашы және өзгеріс түрі. metadata_only белгісі артық қайта есептеуді үнемдейді, ал text_changed құжатты бірден жаңарту кезегіне жібереді.
Қарапайым мысал. Банктің регламентінде құжат карточкасында департамент атауы өзгерді, бірақ ережелер мәтініне қол тигізілген жоқ. Бұл жағдайда эмбеддингтерді қайта есептеу қажет емес. Ал сол құжатта операция лимиті немесе клиентке жауап беру мерзімі өзгерсе, мәтіндік хеш өзгереді де, ескі чанктарды алмастыру керек болады.
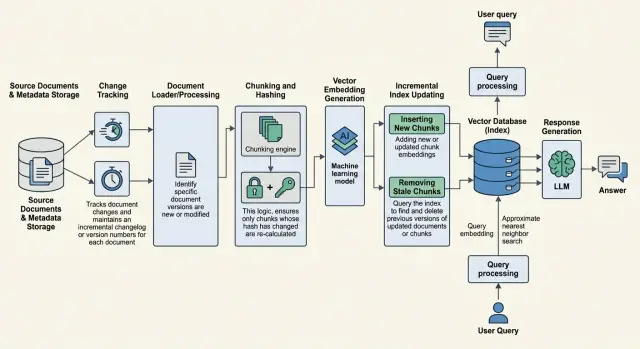
Тек өзгерген бөліктерді қалай жаңартуға болады
Толық қайта индексация тек бастапқы кезеңде ыңғайлы. Кейін ол кедергіге айналады: сағаттап уақыт алады, эмбеддингтерге ақша жұмсайды және іздеуде бір мәтіннің екі нұсқасы қатар өмір сүретін жағымсыз сәт тудырады. Әлдеқайда тыныш жұмыс істейтін тәсіл - нақты өзгерген нәрсені ғана қозғайтын қысқа цикл.
Әдетте процесс былай жүреді. Жүйе хеш, түзету күні немесе нұсқа нөмірі бойынша өзгерген құжаттарды табады. Егер файл өзгермесе, мүлде қозғамаған дұрыс. Өзгерген әр құжат үшін пайплайн мәтінді қайтадан чанктарға бөледі, бірақ тек жаңа нұсқа үшін. Содан кейін жаңа фрагменттерге эмбеддингтер құрып, оларды бөлек жинақ ретінде сақтайды.
Ескі чанктарды бірден өшірмеген дұрыс. Алдымен жаңа нұсқа индекске жетіп, қысқа тексеруден өтуі керек. Тек содан кейін бұрынғы редакция is_active = false арқылы немесе retrieval-ден алып тастайтын нұсқа күйі арқылы белсенді емес болып өзгереді.
Мұнда реттілік бәрін шешеді. Егер алдымен ескі чанктарды жасырып, жаңа жазбалар әлі түспесе, іздеу уақытша көрмей қалады. Егер алдымен жаңасын қосып, бірақ ескілерін өшіруді ұмытсаңыз, жүйе екі редакцияны араластырып, түсініксіз жауаптар бере бастайды.
Жаңартуды екі қадаммен жасаған сенімдірек: алдымен жаңа нұсқаны жазу, кейін белсенділік жалаушасын атомарлы түрде ауыстыру. Сонда жаңалық тексерісі мәселе көрсетсе, кері қайту да жеңіл.
Банк регламентінде жауап беру мерзімі 10 күннен 5 күнге өзгерді деп елестетіңіз. Пайплайн дәл осы құжаттың чанктерін ғана қайта есептеп, тек өзгерген бөліктерге жаңа эмбеддингтер жасауы, ескілерін өшіріп, какой срок ответа по регламенту сияқты сұранысты тексеруі керек. Егер іздеу әлі де кейде 10 күнді шығарса, индекс техникалық тұрғыдан қате жинақталмаса да, жаңарту аяқталды деп санауға болмайды.
Іздеуді тоқтатпай ескі чанктарды қалай өшіруге болады
Ескі чанктар өздігінен жоғалмайды. Егер сіз құжаттың жаңа нұсқасын жай ғана векторлық базаға қоссаңыз, retriever көбіне ескі және жаңа фрагменттерді бірден көріп тұрады. Модель аралас контекст алып, ескірген ережеге сүйеніп жауап береді.
Тиімді тәсіл - алдымен ескі чанктарды логикалық түрде жасырып, физикалық түрде оларды кейінірек өшіру. Әр фрагмент үшін doc_id, version_id, is_active, retired_at сақтау пайдалы. Жаңа нұсқа келгенде, сіз жаңа чанктарды жазып, тексеріп, содан кейін ғана бұрынғы редакцияны is_active = false күйіне ауыстырасыз.
Осылайша ескі контентті алып тастап, жаңа контент әлі индекске түспеген кездегі паузадан қашасыз. Регламенттер, тарифтер және ішкі нұсқаулықтар үшін бұл әсіресе маңызды. Бір абзацтағы қате бүкіл жауапты оңай бұзып жібереді.
Фильтр физикалық жоюдан маңыздырақ
Іздеу тек белсенді нұсқаны көруі керек. Ең оңай жол - is_active = true фильтрін және қажет болса ағымдағы version_id көрсеткішін қолдану. Егер мұндай фильтр болмаса, архивтік чанктар ерте ме, кеш пе нәтижеге қайта шығады, тіпті рейтингі сәл төмен болса да.
Ескі чанктарды ортақ retriever ішінде сақтамаған дұрыс. Архивті бөлек namespace-ке, бөлек индекске немесе кемі басқа іздеу класына шығарыңыз. Әйтпесе бір сұранысқа фильтр қосуды біреу ұмытып кетеді де, ескірген мәтін қайтадан контекстке түседі.
Жаңартудан кейін міндетті түрде кэшті тазартыңыз. Бұл жиі кездесетін тұзақ: индекс жаңа, ал пайдаланушы бәрібір response cache-тен, reranker кэшінен немесе қолданбаның аралық қабатынан ескі жауап алады. Кэшті кемі doc_id және version_id-ке байлаған дұрыс, ал құжат ауысқанда осы нысанға қатысты жазбаларды тазарту керек.
Физикалық жоюды бөлек іске қосқан жөн, мысалы түнде немесе аптасына бір рет. Архивті бірден өшіру қауіпті: кейде командаға кері қайту, аудит немесе жаңа нұсқа іздеуді бұзбағанын тексеру қажет болады.
Қашан жаңа эмбеддинг керек
Эмбеддингтерді әр түзетуде бүкіл корпусқа қайта есептеу қажет емес. Егер құжат нүктелік түрде өзгерсе, тек мағынасы өзгерген чанктарды қайта есептеңіз. Бұл уақытты үнемдейді және ештеңе болмаған жердегі іздеуді бұзбайды.
Мұнда қарапайым ереже көмектеседі: мүмкін болса, чанк шекараларын тұрақты ұстаңыз. Бүгін бір абзац бір фрагментке кіріп, ертең ұсақ қосымша әсерінен төмендегі барлық шекара жылжып кетсе, сіз тым көп деректі қайта есептеуге мәжбүр боласыз. Шекаралар тұрақты болса, тек керек бөліктер өзгереді, ал көрші чанктар өз орнында қалады.
Ұсақ түзету әрдайым жаңа эмбеддингті талап етпейді. Егер сіз орфографиялық қате түзетсеңіз, бұйрық нөмірін жаңартсаңыз немесе мағынасы өзгермей тұжырымды сәл өңдесеңіз, ескі векторды қалдыруға болады. Бірақ құжат пайдаланушы сұрағына беретін жауапты өзгертсе, чанк мағына жағынан басқа болады, демек оны қайта есептеу керек.
Тәжірибелік жақсы ереже мынадай. Стиль, емле және пішімдеу әдетте жаңа эмбеддингті қажет етпейді. Жаңа мерзім, лимит, тариф, факт немесе ереже - қажет етеді. Егер сіз бөлімнің ішіне жаңа абзац енгізсеңіз, осы фрагментті қайта есептеңіз, бірақ көршілерін себепсіз қозғамаңыз. Егер құжат құрылымы қайта жазылып, тақырыптар және бөлімдердің мағынасы өзгерсе, бүкіл құжатты қайта жинаған дұрысырақ.
Командалар көбіне сақтанып, түзету орнынан екі-үш көрші чанкты да қайта есептей береді. Әдетте бұл артық. Егер көрші фрагменттің мәтіні мен мағынасы өзгермесе, оны қозғамаңыз.
Жаңартудан кейін тек дәлдікке емес, recall-ға да қараңыз. Жаңа чанк тым тар болып қалса, іздеу оны сұрақтың бұрынғы формулировкаларымен таба алмай қалады. Бұл агрессивті бөлуден кейін жиі болады. Егер пайдаланушылар әдеттегі сұрақпен керек жауапты таба алмай қалса, мәселе көбіне модельде емес, фрагменттерді жаңарту тәсілінде.
Бір ғана өзгерген регламент мысалы
Клиент шағымдарын сақтау жөніндегі банк регламентін алайық. Жаңа редакцияда тек 4-бөлім өзгерді: сақтау мерзімі 30 күннен 90 күнге өсті. Қызметкерлер рөлдері, журнал форматы және келісу тәртібі сипатталған қалған бөлімдер өзгеріссіз қалды.
Егер білімді бүкіл құжат бойынша толық жаңартсаңыз, жүйе жиі барлық чанкті қатарынан қайта есептейді. Бұл артық жұмыс. Мұндай жағдайда ескі және жаңа нұсқаларды чанктар бойынша салыстырып, шынымен мәтіні өзгерген ғана бөлікті жаңарту жеткілікті.
Айтайық, құжат 6 чанкқа бөлінген. Салыстырғаннан кейін 1, 2, 3, 5 және 6 фрагменттері өзгермегені көрінеді. Тек 4-чанк өзгерді, өйткені онда жаңа сақтау мерзімі пайда болды. Демек, жаңа эмбеддинг тек соған керек. Осы чанктың ескі нұсқасы белсенді нәтижеден шығуы тиіс.
Мұнда тек жаңа фрагментті қосу жеткіліксіз. Егер ескі редакцияны белсенді емес күйге көшірмесеңіз, іздеу кейде екі нұсқаны да көтере береді. Сонда модель қақтығысты көреді: бір бөлікте 30 күн, екіншісінде 90. Жауап кездейсоқ болып кетеді, ал бұл баяу индекстен де жаман.
Тәжірибеде қарапайым байлау көмектеседі: әр чанкта document_id, section_id және version_id бар. Әдеттегі іздеуге тек белсенді нұсқасы бар жазбалар қатысады, ал алдыңғысы күн немесе жалауша бойынша жабылған болады. Сонда ескі редакция retrieval-ге қатыспайды, бірақ аудит үшін тарихта қалады.
Тексеру де қарапайым. Жаңартуға дейін Клиенттік шағымдарды қанша күн сақтау керек? деген сұрақ ескі 4-чанкты және 30 күн деген жауапты қайтаратын. Ішінара жаңартудан кейін сол сұрақ жаңа 4-чанкты және 90 күн деген жауапты қайтаруы керек.
Сонымен қатар көрші сұрақтарды да тексеру керек. Мысалы, Архивті жоюды кім келіседі? сұрағы бұрынғыдай өзгеріссіз 5-чанкты көрсетуі тиіс. Бұл жақсы белгі: сіз ескірген жауапты алып тастадыңыз, бірақ құжаттың тұрақты бөліктеріне тимедіңіз.
Жиі бұзатын қателер
Білім базасының өзектілігін көбіне модель емес, пайплайндағы ұсақ қателер бұзады. Құжат жаңарған, жаңа чанктар есептелген, ал іздеу бәрібір ескі редакцияны тартып, жауапты бірден екі нұсқадан құрастырады.
Әдетте себептердің бірі немесе бірнешеуі болады. Команда эмбеддингтерді қайта есептеді, бірақ version_id, is_active немесе өзекті редакция фильтрін жаңартпады. Ескі чанктарды тым кеш өшіреді, сол аралықта іздеу екі нұсқаны да көреді. Әр импортта жүйе жаңа doc_id және chunk_id жасайды да, ескі және жаңа құжаттың байланысын жоғалтады. Кейде бір ғана түзету үшін бүкіл индексті қайта есептеп, сағат жоғалтады әрі қателер қаупін арттырады. Тағы бір жиі нәрсе - іздеу кэшін, жауап кэшін немесе ескі индекс снапшоттарын тазаламау.
Тәжірибеде бұл өте қолайсыз көрінеді. Сіз демалыс регламентін жаңартып, келісу мерзімін 5 күннен 2 күнге қысқарттыңыз, векторлық база жаңа мәтінді сақтап тұр, бірақ жауап кэші әлі кешегі нәтижені ұстап тұр, ал нұсқа фильтрі жұмыс істемейді. Пайдаланушы сұрақ қояды да, құжат түзетілгеніне қарамастан, ескі санды алады.
Ең жиі қате - идентификаторларды бұзу. Егер doc_id әр импортта өзгерсе, жүйе бұл сол құжаттың жаңа редакциясы екенін түсінбейді. Ескі чанктар жарияланымнан алынбай, жаңаларымен қатар жиналып қалады. Сондықтан құжат нысаны үшін тұрақты doc_id, ал әр редакцияға бөлек version_id ұстаған дұрыс.
Бір түзету үшін толық қайта индексация да өзектілікті бұзады. Сіз бүкіл корпусты өңдеп жатқанда, индекстің бір бөлігі жаңа, екінші бөлігі ескі күйде қалады, ал жаңарту кезегі өсіп барады. Егер бір бөлім өзгерсе, әдетте тек әсер еткен чанктарды және тек шекаралары шын мәнінде жылжыған жағдайда ғана көрші бөліктерді қайта есептеу жеткілікті.
Кэште командалар көбіне екі рет қателеседі: не мүлде тазаламайды, не бәрін түгел өшіреді. Точкалы тазалау жасаған дұрыс, құжат, нұсқа немесе сұраныстар жиыны бойынша. Әйтпесе не ескірген жауаптарды ұстап қаласыз, не пайдасыз жылдамдықтан айрыласыз.
Жарияламас бұрын тексеру
Релиз алдында индекстің қате жиналмағанын ғана тексеру аз. Іздеуде ескі мәтін бөліктері қалмағанын анықтау әлдеқайда маңызды. Негізгі мәселе көбіне осы жерде шығады: жаңа нұсқа жүктелген, ал жауап әлі де өткен редакциядан үзіндіні сүйреп әкеледі.
Тексеру тым қысқа болуы мүмкін. Құжатта тұрақты document_id болуы керек, нұсқада - өз нөмірі, күні немесе хеші, іздеу қабаты тек өзекті чанктарды қайтаруы тиіс, ал кэш құжат нұсқасын ескеруі немесе дұрыс жарамсыздандырылуы керек. Бөлек шағын тест сұрақтар жиыны керек: мерзімдер, лимиттер, мөлшерлемелер, өріс атаулары, процесс қадамдары сияқты, ескі цитата бірден көрінетін сұрақтар.
Егер осы пункттердің бірі орындалмаса, релизді бір сағатқа шегерген дұрыс, кейін продакшен неге ескі нұсқаулықпен жауап беретінін бір күн бойы түсіндіріп отырғаннан гөрі.
Елестетіңіз, қайтару ережесінде мерзім 14 күннен 30 күнге өзгерді. Инкременталды жаңартудан кейін тура сұрақ қойыңыз: Қайтаруға қанша күн беріледі? Егер жауап немесе цитата әлі де 14 күнді көрсетсе, мәселе үш жердің бірінде: ескі нұсқа деактивацияланбаған, версия фильтрі істемеген немесе кэш бұрынғы нәтижені қайтарған.
Метадеректерді қолмен тексеру де пайдалы. Табылған чанктарда document_id, ағымдағы version_hash және өзектілік жалаушасы сәйкес болуы тиіс. Ескі чанктарды аудит үшін сақтауға болады, бірақ іздеу оларды айқын сұраныссыз көрмеуі керек.
Егер команда бірнеше модельді салыстырса, retrieval-контурды өзгеріссіз қалдырып, тек генерацияны ауыстырған жақсы. Мұндай схема үшін AI Router сияқты OpenAI-мен үйлесімді бір ортақ шлюзді қолдану ыңғайлы: сол SDK, сол код және сол промпттар қалады, ал модельдерді салыстыру таза болады. Сонымен қатар аудит логтары мен кэш ережелерін бір қабатта бақылау оңайырақ.
Бірінші іске қосудан кейін не істеу керек
Бірінші іске қосудан кейін бүкіл құжат корпусына қол тигізбеңіз. Өзгеріс бірден байқалатын бір дереккөзді алыңыз: регламенттер, ішкі анықтама немесе келісімшарттар каталогы. Сонда инкременталды қайта индексация шынымен жұмыс істей ме, жоқ па, тезірек түсінесіз және артық шудың ішінде жоғалып кетпейсіз.
Метрикаларды бірінші күннен бастап жинаңыз. Әйтпесе бір аптадан кейін жүйе жаңарып жатқан сияқты көрінгенімен, нақты қай жері бұзылып жатқанын түсінбей қаласыз. Бастапқыда төрт көрсеткіш жеткілікті: құжат өзгергеннен жаңа нәтижеге дейін қанша минут өтеді, іздеу ескі чанк нұсқасын қаншалықты жиі көтереді, бір ішінара жаңарту қанша тұрады және жүйе қанша құжатты өткізіп жіберді немесе екі рет өңдеді.
Егер сізде тест сұрақтар жиыны бар болса, әр жаңартудан кейін оны іске қосып отырыңыз. Бір схема жаңа құжаттарда жақсы жұмыс істеп, бірақ кэштен, индекстен немесе аралық нұсқа кестесінен ескі жауаптарды әлі де тарта беруі мүмкін.
Өзектілікті бақылауды әдеттегі релиз цикліне кірістірген дұрыс. Команда жаңа парсерді енгізгенде, чанкингті өзгерткенде немесе жою ережелерін түзеткенде, релиз қысқа тестті қамтуы керек: құжатты өзгерттіңіз, жаңартуды күттіңіз, ескі нұсқа енді іздеуге түспейтінін растадыңыз.
Сонымен қатар толық және ішінара қайта есептеуді сандармен салыстырған пайдалы. Егер күн сайын базаның 2-3%-ы ғана өзгерсе, толық қайта индексация бюджетті бекер жағады. Тек эмбеддинг құнын ғана емес, кезектің ұзақтығын, индекстің дайын болу уақытын және артық жою операцияларының санын да қараңыз.
Қазақстандағы командалар үшін тағы бір практикалық сұрақ бар: бастапқы құжаттар, индекс, логтар, PII маскалауы және нұсқалардың қызметтік кестелері қайда сақталады. RAG-контуры схема бойынша жергілікті көрінуі мүмкін, ал деректердің бір бөлігі шын мәнінде ел шекарасынан тысқа кетіп жатады. Мұны іске қоспай тұрып тексерген дұрыс, кейін емес.
Жақсы нәтиже қарапайым көрінеді: жаңа құжат тез іздеуге түседі, ескі чанк нәтижеде шықпайды, жаңарту құны болжамды болып қалады. Бұл бір дереккөзде тұрақты жұмыс істесе, келесісін қосуға болады.
Жиі қойылатын сұрақтар
Құжат жаңартылғаннан кейін RAG неге бәрібір ескі нұсқаға жауап береді?
Көбіне индексте екі редакция да қатар тұрады. Іздеу ескі чанктарды жаңаларындай сенімді табады да, модель жауапты екі нұсқадан құрастырады.
Құжат пен оның редакциясын бөлек сақтаңыз. Алдымен жаңа нұсқаны жүктеп, тексеріп алыңыз, содан кейін ескісін is_active = false арқылы немесе ағымдағы version_id фильтрімен өшіріңіз.
`source_id` пен `version_id` несімен ерекшеленеді?
source_id құжаттың өзін сипаттайды және жаңа жүктеуден, файл атауынан немесе бума ауысуынан өзгермейді. version_id осы құжаттың нақты редакциясын сипаттайды.
Мұндай схема қазір қай нұсқа белсенді екенін, қайсысы архивке кеткенін және жүйе бұрын қай редакцияға сүйенгенін түсінуге көмектеседі.
Құжат пен чанк үшін қандай өрістерді сақтау керек?
Әдетте source_id, version_id, text_hash, metadata_hash, updated_at және is_active жеткілікті. Чанктарға құжат пен нұсқаға байланыс қосыңыз, сонда ескі фрагменттерді тез өшіруге болады.
Егер ақауларды жеңіл талдағыңыз келсе, өзгеріс бастамашысын және metadata_only немесе text_changed сияқты түзету түрін де сақтаңыз.
Ішінара жаңарту қашан жетеді, ал қашан бүкіл құжатты қайта жинау керек?
Егер жауаптың мағынасы өзгерсе, тек әсер еткен чанктарды қайта есептеңіз. Осылайша эмбеддингтерге артық ақша жұмсамайсыз және корпустың тұрақты бөліктерін қозғамайсыз.
Бүкіл құжатты қайта жинаудың мәні құрылым өзгерсе, тақырыптар ауысса немесе чанк шекаралары қатты жылжып кетсе ғана бар. Ондайда нүктелік жаңарту таза нәтиже бермейді.
Ескі чанктарды іздеуді тоқтатпай қалай алып тастауға болады?
Алдымен жаңа нұсқаны индекске жазып, іздеудің оны көретініне көз жеткізіңіз. Сосын бір ауыстыру арқылы өткен редакцияны белсенді емес күйге көшіріңіз.
Сонда жаңарту кезінде іздеу уақытша соқыр болып қалмайды және ескі мен жаңаны араластырмайды. Физикалық жоюды кейінірек, жұмыс трафигінен бөлек жасаған дұрыс.
Ұсақ түзетуден кейін эмбеддингті қайта есептеу керек пе?
Жоқ, әрдайым емес. Егер сіз орфографиялық қатені түзетсеңіз, пішімдеуді немесе бұйрық нөмірін мағынасын өзгертпей жаңартсаңыз, ескі векторды қалдыруға болады.
Ал егер сұраққа берілетін жауаптың өзі өзгерсе, мысалы мерзім, лимит, тариф, ереже немесе кез келген факт жаңарса, сол чанк үшін жаңа эмбеддинг есептеңіз.
Құжат жаңарғаннан кейін кэшпен не істеу керек?
Кэшті түгел емес, нүктелік түрде тазалаңыз. Жазбаларды doc_id және version_id-ке байлап қойыңыз, сонда құжат ауысқанда тек әсер еткен жауаптар мен іздеу нәтижелерін алып тастайсыз.
Ескі кэш қалса, пайдаланушы жаңа индекс тұрса да кеше берілген жауапты көреді. Ал бәрін бірдей тазаласаңыз, пайдасыз жылдамдықтан айрыласыз.
Жаңа нұсқаның шынымен іздеуге түскенін қалай тез тексеруге болады?
Құжаттың өзгерген орны туралы тура сұрақ қойып, тек жауапты емес, табылған чанкты да тексеріңіз. Онда ағымдағы document_id, version_id немесе version_hash сәйкес болуы керек, ал ескі фрагмент retrieval-ге түспеуі тиіс.
Жанындағы өзгермеген сұрақтарды да өткізіңіз. Егер олар бұрынғыдай жұмыс істесе, жаңарту таза өткенін білдіреді.
Неліктен толық қайта индексация жиі нәтижені нашарлатады?
Бір құжаттағы бір ғана түзету үшін толық қайта индексация ұзақ кезек тудырады, бүкіл корпусқа ақша жұмсатады және ескі мен жаңа деректерді бір индексте араластыру қаупін арттырады.
Инкременталды жаңарту сабырлырақ: тек шынымен өзгерген бөлікті ғана ауыстырасыз және өзектілікті бақылау оңай болады.
Егер бізде әлі инкременталды жаңарту болмаса, неден бастау керек?
Бір дереккөзден бастаңыз, мысалы регламенттерден немесе ішкі анықтамадан. Тұрақты source_id, бөлек version_id, белсенді нұсқаға фильтр және мерзімдерге, лимиттерге, ережелерге арналған тест сұрақтар жиынын енгізіңіз.
Сосын құжат түзетілген сәттен жаңа нәтижеге дейінгі уақытты, іздеудегі ескі чанктар үлесін және ішінара жаңарту құнын өлшеңіз. Бір жинақта схема тұрақты жұмыс істесе, кейін кеңейте беріңіз.