RAG әлде ұзын контекст: іздеу үшін схеманы қалай таңдау керек
RAG пен ұзын контекстті салыстырып, олардың құжаттар бойынша іздеуге, бағаға және кідірісіне қалай әсер ететінін қарастырамыз — сонда өз өніміңізге лайық схеманы таңдай аласыз.
Таңдау неде
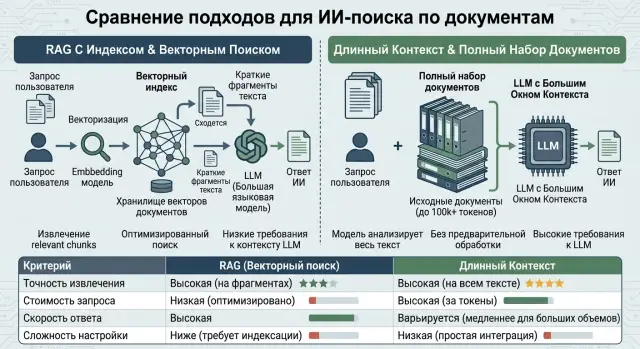
Құжаттарға бір сұрақты екі жолмен шешуге болады. Біріншісі - керек фрагменттерді тауып, модельге тек соларды беру. Бұл RAG. Екіншісі - модельге үлкен мәтін бөлігін немесе бүкіл құжатты жіберу, егер контекст терезесі соған жетсе.
«Қайсысы жақсы» деген дау әдетте тез-ақ басқа жаққа ауысады. Пайдаланушы үшін схема маңызды емес. Оған ақылға қонымды бағаға және ұзақ күтусіз дәл жауап керек.
Сондықтан бірден төрт нәрсеге қараған дұрыс: жүйе қаншалықты жиі керек фактісін табады, бір жауап пен бүкіл сұраныстар ағыны қанша тұрады, нәтиже қаншалықты тез келеді және команда шешімді қолдауға қанша күш жұмсайды.
RAG пен ұзын контекст әртүрлі тепе-теңдік береді. Егер құжаттар үлкен, жиі өзгеретін және сұраныс көп болса, фрагменттер бойынша іздеу баға жағынан жиі ұтады. Модель азырақ токен оқиды, ал индексті жауап логикасын толық қайта құрастырмай-ақ жаңартуға болады.
Егер құжаттар аз, түсінікті және сирек өзгерсе, ұзын контекст көбіне қарапайымырақ. Индекс құрудың, мәтінді бөлу баптаудың және неге керек абзац нәтижеге түспей қалғанын түсінудің қажеті жоқ. 30-40 қысқа нұсқаулықтан тұратын ішкі білім базасы үшін бұл ең тура жол болуы мүмкін.
Құжат түрі де таңдауға қатты әсер етеді. Шарттар, регламенттер және нақты құрылымы бар нұсқаулықтар әдетте екі схемаға да жақсы бейімделеді. Ал хат алмасулар, скандар, кестелер, шу мен қайталануы бар ескі PDF-файлдар көбіне мәселе тудырады. Фрагменттер бойынша іздеу шатаса бастайды, ал ұзын контекст артық мәтінге батып, керек детальды өткізіп жіберуі мүмкін.
Сұраныс жиілігі экономиканы өзгертеді. Егер сұрақ сирек қойылса, қарапайым схема үшін модель шақыруы қымбаттау болса да, соған көне салуға болады. Егер күніне мыңдаған сұрақ түссе, әр жауапқа қосылатын 20-30 мың артық токен шығынды тез-ақ өсіреді.
Ең дұрыс тәсіл — архитектураны ұнатуға қарап емес, нақты сұрақтармен екі тәсілді салыстыру. Осындай тест көбіне өнім үшін не жақсы екенін, тақтада әдемі көрінетін схеманы емес, дәл көрсетеді.
RAG құжаттар бойынша іздеуді қалай шешеді
RAG модельге бүкіл архивті оқытпайды. Алдымен жүйе керек фрагменттерді іздейді, содан кейін оларды сұрақпен бірге LLM-ге жібереді. Тәжірибеде құжаттар бөліктерге бөлінеді, индекс құрылады, сұрақ пен мәтін векторға айналады да, ең жақын бірнеше фрагмент таңдалады.
Сондықтан жауап тек модельге емес, іздеу сапасына да тәуелді. Күшті модель әлсіз индексті құтқармайды. Егер нұсқаулық кестенің ортасынан бөлінсе, құжаттың ескі және жаңа нұсқалары араласса, ал PDF нашар OCR-мен жүктелсе, іздеу қоқыс әкеледі. Модель соны тек ұқыпты тілмен қайталап шығады.
Көбіне төрт нәрсе қатты әсер етеді: құжатты фрагменттерге қалай бөлуіңіз, мәтінмен бірге қандай өрістер мен белгілерді сақтауыңыз, индексқа қаншалықты таза мәтін түскені және табылған бөліктерді қайта ранжирлеуді қолданасыз ба.
RAG әсіресе жауап бірнеше абзацта жатқанда, ал жүздеген бетке шашылмаған кезде пайдалы. Өнімнің білім базасы, ішкі регламенттер, шарттар, FAQ, қолдау қызметіне арналған нұсқаулықтар — осының бәрінде іздеу керек жерді тез табады. Егер қызметкер тариф лимитін қалай есептеу керегін сұраса, жүйеге бүкіл құжаттаманы оқу қажет емес. Оған есептеу ережелері бар бөлім және ерекшеліктер көрсетілген көрші фрагмент керек.
Материалдар жақсы құрылымдалса, мұндай тәсіл көбіне толық оқудан жылдамырақ әрі дәл жауап береді. Тағы бір артықшылығы — жауап қайдан шыққанын көрсету оңайырақ, өйткені сұрауға бүкіл архив емес, нақты мәтін бөліктері ғана түседі.
Бірақ RAG да жиі жаңылысады. Сұрақ тым қысқа болуы мүмкін. Сұрақтағы термин құжаттағы тұжырыммен сәйкес келмеуі мүмкін. Керек ой әртүрлі бөлімдерге шашырап кетуі мүмкін. Ондайда іздеу ішінара сәйкес фрагменттерді әкеледі де, модель жауапты бөтен контекстен құрастырады. Сырттай сенімді көрінеді, бірақ жауап қате.
Сондықтан RAG-ты екі бөлек кезеңмен бағалау керек. Алдымен іздеу керек фрагменттерді таба ма, соны тексеріңіз. Содан кейін осы фрагменттер алдыңда тұрғанда модель мағынаны дұрыс ұстай ма, соны қараңыз. Бірінші кезең әлсіз болса, екіншісі де көбіне құлайды.
Ұзын контекстте не өзгереді
Ұзын контексте схема қарапайымырақ. Бөлек іздеудің орнына сіз база білімінің, келісімшарттың немесе хат алмасудың үлкен бөлігін сұрауға қосасыз да, модель бәрін бірден оқиды. Команда үшін бұл ыңғайлы: индекс құрудың, ранжирлеуді баптаудың және алдымен қай фрагментті алу керегін шешудің қажеті жоқ.
Мұндай тәсіл құжат аз болғанда, олар тым жиі өзгермегенде және жауап мәтіннің бірнеше бөлігі арасындағы байланысқа тәуелді болғанда жақсы жұмыс істейді. Модель регламенттің басындағы шартты, қосымшадағы ерекшелікті және құжат соңындағы мерзімді бірден көре алады. RAG-та бұл бөліктерді әлі де дұрыс табып, біріктіру керек.
Ұзын контекст көбіне бір үлкен келісімшартты немесе тендер пакетіні талдағанда, қысқа ішкі білім базасы бойынша жауап бергенде, хабарламалар тізбегін ретімен талдағанда және құжаттағы бөлімдер арасындағы қайшылықты тексергенде таңдалады.
Бірақ үлкен контекст терезесі модельді автоматты түрде мұқият етпейді. Егер сұрауға 150 бет түссе, ол бәрібір лимит, күн немесе ерекшелік жазылған бір жолды өткізіп жіберуі мүмкін. Бұл қалың папканы асығыс парақтап отырған адамға ұқсайды: мәтін көз алдында бар, бірақ ұсақ деталь жоғалады.
Контекстке артық нәрсе кіргенде мәселе күшейеді. Пайдаланушы тауарды қайтару туралы сұрап отыр, ал сіз оған анықтаманың бүкіл архивін, ескі ережелерді және серіктестерге арналған құжаттарды жібересіз. Модель жауап беруге көмектеспейтін беттерге токен жұмсайды. Жауап ұзағырақ жүреді, ал баға мәтін көлемімен бірге дерлік өседі.
Тағы бір әсер бар. Ұзын контекст бастапқы қадамға ыңғайлы және бірінші жұмыс істейтін сценарийді тез жинауға көмектеседі. Бірақ білім базасы өскен сайын сапаны бір деңгейде ұстап тұру қиындайды. Әр сұраныс көбірек шу алып келеді. Сол кезде ең үлкен терезесі бар тәсіл емес, модельге тек қажет мәтін түсетін тәсіл ұтады.
Егер құжаттар ықшам болса және сұрақ бүкіл пакетті оқуды талап етсе, ұзын контекст әзірлеу уақытын үнемдейді. Егер материал көп болса, ал жауаптар әдетте екі-үш абзацтың ішінде жасырынса, ол тез қымбат әрі баяу болып кетеді.
Ақшаны қай жерде көбірек төлейсіз
RAG-та шығын үш жерде пайда болады. Алдымен - құжаттарды іздеуге дайындау кезіндегі эмбеддингтер. Содан кейін - құжаттар жиі өзгерсе, индексті сақтау және жаңарту. Одан кейін - модельге сұраныс жіберу, бірақ қысқа контекстпен, өйткені промптқа тек табылған фрагменттер түседі.
Ұзын контексте логика басқа. Индекс қажет емес, бірақ модель әр сұраныста көп кіріс токенін оқиды. Егер пайдаланушы бірдей құжаттар жинағы туралы бес рет сұраса, жүйе сол беттерді бес рет қайта оқуға төлейді. Бұған жиі үлкен контекст терезесі үшін қосымша қор да қосылады: команда токен лимиті жоғары модельді жай сақтық үшін алады.
Тәжірибеде шотты көбіне модельдің өз бағасы емес, сіз қайта-қайта жіберетін мәтін көлемі бұзады. Егер құжаттар бойынша іздеу 200 бет орнына 5 керек фрагментті ғана таңдап берсе, үнем кейде сәл арзан модельге ауысудан да күштірек болады.
Мысал қарапайым. Білім базасында 3 000 мақала бар. Пайдаланушы бір баптауға қатысты қысқа сұрақ қояды. RAG модельге 6-10 фрагмент жібереді. Ұзын контекст мақалалар топтамасын немесе бүтін бір бөлімді сүйрейді. Екінші жағдайда сіз артық оқуға төлейсіз және мұны әр жолы қайталайсыз.
Бірақ ұзын контексттің күшті жағы бар: құжаттар саны аз болғанда. Егер сізде бірге 30 000-50 000 токен болатын 15 қысқа нұсқаулық болса, бөлек индекс өзін ақтамауы мүмкін. Эмбеддинг шығыны жоқ, пайплайнға қызмет көрсету жоқ, бірдеңе бұзылатын орын да аз. Ішкі көмекші немесе пилот үшін бұл жиі қарапайым әрі арзанға түспейді.
Сондықтан ақша көбіне екі санға сүйенеді: модель бір жауапқа қанша мәтін оқиды және оны қанша рет қайта оқиды. Құжат аз болса, ұзын контекст жиі қарапайымдылығымен ұтады. Құжат көп болып, сұрақтар тар болса, RAG әдетте шотты едәуір азайтады.
Жылдамдықта не болады
Жылдамдық тек модельге байланысты емес. Оған ең көп әсер ететіні — сұрауға қосатын мәтін көлемі. Сондықтан RAG пен ұзын контекст арасындағы жарыста жеңімпаз тапсырмаға қарай өзгереді.
Егер білім базасы үлкен болса, RAG әдетте жылдамырақ. Іздеу қабаты 5-10 керек фрагментті тауып береді де, модель жүздеген бетті толық оқымай, тек соларды оқиды. Уақыт іздеуге және кейде қайта ранжирлеуге кетеді, бірақ бұл қосымша көбіне үлкен контекстті оқудан аз болады.
Мыңдаған нұсқаулық, регламент және PDF бар қолдау жүйесін елестетіңіз. Пайдаланушы тауарды кепілдікпен қалай қайтаруды сұрайды. RAG қайтару, мерзімдер және керек формалар туралы бірнеше абзацты алып шығады. Модель іске қатысты жауап береді де, қалғанына уақыт жұмсамайды.
Ұзын контекст егер тізбек өте қарапайым болса, жылдамырақ болуы мүмкін: бір құжат, бір сұрақ, іздеусіз және индекстсіз. Егер сізде 8 беттік қысқа келісімшарт немесе шағын бриф болса, мәтінді толығымен модельге беру оңайырақ. Қадам аз болса, жүйе де аз кідіреді.
Мұндай нұсқа сұрақ құжат тұжырымдарына қатты байланған жерде де жақсы жұмыс істейді. Заңгер он мыңдаған файл архивінен жауап іздемей, бір келісімшартты тексеруді сұрайды. Модель бүкіл мәтінді бірден оқып, аралық логикасыз жауап береді.
Мәселе құжаттар үлкейгенде басталады. Үлкен PDF, кестелер, қосымшалар және қайталанатын блоктар токен санын тез көбейтеді. Бірнеше экранға созылған кесте он қарапайым абзацтан да көп кідіріс қосуы мүмкін. Ал дәл сол ұзын файл модельге қайта-қайта жіберілсе, жүйе әр жолы қайта оқуға уақыт төлейді.
Қайталанатын сұраныстарда RAG көбіне бірқалыптырақ болады. Индекс дайын, іздеу шамамен бірдей уақыт алады, ал промпттағы мәтін көлемі жақын қалады. Ұзын контексте ауытқу көбірек: бір сұраныс тез өтеді, ал келесісі кенеттен ұзын қосымшаға немесе нашар қысылған кестеге тіреледі.
Есептегі орташа жылдамдық әдемі көрінеді, бірақ пайдаланушыны басқа нәрсе қызықтырады — жауап қаншалықты жиі әдеттегіден ұзақ ойланатыны. Өнім үшін бұл идеалды сценарийдегі жарты секунд айырмасынан да маңызды. Сондықтан тек орташа уақытты емес, p95, p99, ұзын құжаттардағы мінез-құлықты және қайталанатын сұраныстардағы тұрақтылықты да қараған дұрыс.
Схеманы қадамдап қалай таңдау керек
Бастауды модельден емес, сұрақ түрінен бастаған дұрыс. Егер пайдаланушыға құжаттан нақты факт керек болса, RAG көбіне болжамды нәтиже береді. Егер үлкен есептің жалпы мазмұны немесе бірнеше бөлімді бірден салыстыру керек болса, ұзын контекст ыңғайлырақ болуы мүмкін, өйткені модель бүкіл материалды көріп тұрады.
Сирек детальдар бөлек тексеруді талап етеді. Егер жауап келісімшарттағы бір жолға, PDF-дегі сноскаға немесе кестедегі ескертпеге байланысты болса, фрагментті іздеудегі қате RAG-ты бірден бұзады. Бірақ ұзын контекст те сәттілікке кепіл емес: модель тым үлкен құжаттағы керек жерді байқамай қалуы мүмкін.
Содан кейін мәтін көлемін есептеңіз. Екі сан керек: орташа құжат көлемі және бір жауапқа модель шынымен оқитын мәтін көлемі. Егер база 2-3 беттен тұратын қысқа нұсқаулықтардан құралса, ұзын контекст жиі орынды көрінеді. Егер сізде ұзын регламенттер, хат алмасулар, есептер және тіркемелер болса, баға тез өседі де, RAG әдетте арзанырақ шығады.
Пайдаланушылардың мінез-құлқын да қараңыз. Адамдар бір база бойынша ұқсас сұрақтарды қайта-қайта қоя берсе, RAG тезірек өзін ақтайды. Индекс бір рет бапталады, ал кейін модельге тек керек фрагменттер түседі. Егер сұрақтар әр жолы әртүрлі болып, құжатты түгел оқуды жиі талап етсе, ұзын контекст артық инженерлік жұмысты азайтуы мүмкін.
Мынадай ретпен жүрген ыңғайлы:
- Сұрақтарды түрлерге бөліңіз: факт, қысқаша мазмұн, салыстыру, сирек детальды іздеу.
- Құжаттардың орташа көлемін және бір жауапқа түсетін нақты мәтін мөлшерін өлшеңіз.
- Ойдан шығарылған мысалдарды емес, пайдаланушылардан алынған 20-30 тірі сұрақты алыңыз.
- Екі схеманы үш метрика бойынша салыстырыңыз: дәлдік, баға және кідіріс.
- Егер бір тәсіл фактілерге жақсы жауап беріп, екіншісі қысқаша мазмұнға жақсырақ болса, гибрид нұсқаны қалдырыңыз.
Тесті қысқа жиынтықта жасауға болады, бірақ сапаны қолмен тексерген дұрыс. Тек жалпы дұрыс жауаптар пайызын емес, қате бағасын да қараңыз. Ішкі білім базасы үшін бір фактідегі қате кешірімді болуы мүмкін, ал банк немесе клиника үшін — жоқ.
Гибрид көбіне ең тыныш нұсқаға айналады. Жүйе алдымен сұрақ түрін анықтайды: нақты іздеу үшін RAG арқылы өтеді, ал құжаттың шолуы үшін модельге көбірек мәтін жібереді. Егер команда бұрыннан OpenAI-мен үйлесімді AI Router сияқты бір API арқылы жұмыс істесе, мұндай салыстыруларды клиент кодын қайта жазбай-ақ нақты сұрақтарда тексеру оңайырақ.
Өнім білім базасына мысал
Қолдау қызметіне арналған білім базасын елестетіңіз. Онда нұсқаулықтар, тарифтер, жауап үлгілері, ішкі регламенттер және серіктестерден келген PDF-файлдар бар. Қағаз жүзінде бұл бір құжаттар жиыны сияқты, бірақ іс жүзінде адамдар екі түрлі сұрақ қояды.
Бірінші түрі — қысқа және нақты сұрақтар. Мысалы: «B тарифінің лимиті қанша?», «Қайтару үшін қандай жауап формасы керек?», «2-қосымшада серіктеске не уәде етілген?» Мұндайда фрагменттер бойынша іздеу жиі таза жауап береді, өйткені модельге жүздеген бет емес, 2-5 қажет бөлік түседі.
Егер база бойынша бөлу мен іздеу дұрыс бапталса, RAG әлдеқайда ұқыпты жұмыс істейді. Ол жауапқа көрші PDF-тегі ескі шарттарды сирек тартады және қолдау үлгілеріндегі ұқсас тұжырымдарды азырақ шатастырады.
Екінші түрі — бір үлкен құжатты талдау. Қызметкер 120 беттік келісімшартты немесе серіктестің тоқсандық есебін ашып, «Мұнда кешігу үшін қандай айыппұлдар бар?» немесе «Жауапкершілік пен SLA бөлімдерін салыстыр» деп сұрайды. Мұнда ұзын контекст қарапайымырақ болуы мүмкін. Сіз құжатты түгелге жуық модельдің терезесіне саласыз да, күрделі іздеу тізбегіне уақыт жұмсамайсыз.
Өнім білім базасында сирек жағдайда тек бір тәсіл жеңеді. Әдетте сценарийлерді бөлу орындырақ. Қысқа фактілік сұрақтарды фрагменттер бойынша іздейтін тізбекке жіберіңіз, ал бір үлкен файл бойынша сұрақтарды ұзын контекст тізбегіне бағыттаңыз. Жауап үлгілері мен тарифтерді бөлек, жақсы белгіленген құжат ретінде сақтау дұрыс. Серіктестік PDF-файлдарын алдын ала қоқыстан, колонтитулдардан және қайталанатын бөліктерден тазартқан жақсы.
Мұндай құрылым жүйеде әрі ашық анықтама, әрі ішкі қолдау құжаттары болғанда әсіресе пайдалы. Операторға бір ғана ставка немесе бір ғана ереже керек болса, оған бүкіл келісімшарт қажет емес. Ал заңгерге немесе аккаунт-менеджерге, керісінше, жауапты бүкіл құжат аясында алған ыңғайлырақ.
Егер өнім екі міндетті де шешсе, оларды бір тізбекке зорлап сыйғызудың қажеті жоқ. Бір маршрут қысқа сұрақтарға тез әрі арзан жауап берсін. Екінші маршрут ұзын келісімшарттар мен есептерді сабырмен талдасын. Сонда білім базасы болжамдырақ жұмыс істейді, ал команда токендер мен жауап уақыты үшін не төлеп отырғанын жақсырақ түсінеді.
Ең жиі кездесетін қателер
Көбіне команда жалпы идеядан емес, тексеру детальдарынан қателеседі. Схема қағазда қисынды көрінеді, бірақ жұмыста нашар фрагменттер, артық контекст, әлсіз тест жиыны және жүктемені қате бағалау салдарынан бұзылады.
RAG-тағы әдеттегі қате қарапайым: индексті құрып қойды, ал фрагменттердің сапасын ешкім қолмен тексермеді. Құжатты 1000 таңбадан тұратын тұрақты бөліктерге кеседі, кестелер бытырап кетеді, тақырыптар абзацтармен байланысын жоғалтады, метадеректер бос немесе тым жалпы болады. Нәтижесінде іздеу «жанында бір нәрсені» табады, бірақ керек бөлімді емес. Модель сенімді жауап береді, ал дереккөз көмектеспейді.
Ұзын контексте қате басқа. Модель терезесіне бүкіл архивті жібереді, ал пайдаланушыға нұсқаулықтың бір бөлімі, бір тариф немесе келісімшарттың бір нұсқасы ғана керек. Бұл шығынды тез өсіріп, жауапты жиі нашарлатады. Ескі және жаңа мәтін нұсқалары қатар жатқанда, модель оларды бір жауапқа оңай араластырып жібереді.
Нашар салыстыру да жиі кездеседі. Команда екі схема да жақсы көрінетін бес жеңіл сұрақты алып, қорытынды жасайды. Мұндай тесттің пайдасы аз. Күрделі жағдайлар керек: әртүрлі нұсқадағы ұқсас құжаттар, сирек терминдері бар сұрақтар, жауап сноскада немесе кестеде жасырылған сұраулар, артық детальдары бар ұзын сұрақтар және база ішінде жауабы жоқ жағдайлар.
Тағы бір жиі қате ақшаға байланысты. Көп адам бір сұраныстың орташа бағасын ғана қарайды. Бірақ шынайы жүйеде ең ауыр соққыны пиковые жүктемелер береді. Егер таңертең 10-де мыңдаған сұраныс келсе, ұзын контекст әлдеқайда қымбаттап, кідіріс өседі. RAG-та да өз пиктері бар: эмбеддингтер, қайта индекстеу, қайталама іздеу өтулері. Екі режимді де есептеу керек.
Басқа бір тыныш мәселе бар: модельді ауыстырды да, қалған жүйеге тимеді. Содан кейін бірдей база болса да, іздеу мен сілтеме беру сапасы төмендеуі мүмкін. Бір модель ұзын контекстті жақсы ұстайды, басқа модель табылған фрагменттермен нашар жұмыс істейді, үшіншісі дереккөзге басқаша сілтейді. Сондықтан бұл таңдауды бір рет және мәңгіге деп қарауға болмайды. Модельді, құжатты бөлу тәсілін немесе ретриверді ауыстырғаннан кейін тесттерді қайта жүргізу керек.
Ең қымбат қателер әдетте команда интуицияға тексеруден артық сенген жерден шығады.
Тексерудің ең аз жиыны
Екі схема арасындағы дауды команда пікірімен емес, қысқа өлшеу жиынымен жапқан дұрыс. Егер осы сандар жоқ болса, таңдауды көбіне сезіммен жасайды да, кейін айлап баға, кідіріс және жауаптағы жіберілімдерді түзетеді.
Іске қоспас бұрын әдетте бес тексеріс жеткілікті:
- Бақылау сұрақтары мен құжаттар жинағын құрыңыз. Әр сұраққа эталон жауап немесе модель қайтаруы тиіс фактілер тізімі қажет.
- Бір жауапқа кететін токен шығынын есептеңіз. Қысқа сұраныстарды, ұзын сұраныстарды және салыстыру, үзінді және дәйексөз бар күрделі жағдайларды бөлек қараңыз.
- Кідірісті екі режимде өлшеңіз: қарапайым күн және шекті жүктеме. Бір жылдам тест ештеңе көрсетпейді.
- Іздеудің қаншалықты жиі мүлт кететінін қараңыз. Екі бөлек метрика керек: жүйе керекті құжатты мүлде таппады және жүйе құжатты тапты, бірақ жауапта маңызды фактіні өткізіп алды.
- Сценарийді ауыстыру ережесін бекітіңіз. Мысалы, қысқа сұрақтар RAG арқылы өтеді, ал ұзын келісімшарт немесе регламент толық күйінде үлкен контекст терезесі бар модельге жіберіледі.
Осының өзі әлсіз нұсқаны алып тастауға жетеді. Егер бір шлюз арқылы әртүрлі модельдер мен маршруттарға қол жеткізуге болса, салыстыру жеңілдейді: бірдей жүктемені өткізіп, тек сапаны емес, нақты пайдаланушы сценарийінің бағасын да көруге болады.
Егер осы тізімдегі кемінде екі тармақ әлі бос болса, схема туралы дауласа берудің ерте уақыты. Алдымен өлшемдерді толықтырыңыз, сосын таңдаңыз.
Әрі қарай не істеу керек
Бүкіл база үшін бір тәсілді бірден таңдауға тырыспаңыз. Бір тірі сценарийді алыңыз: білім базасы бойынша іздеу, қолдау үшін жауап беру немесе келісімшарттармен жұмыс. Егер пилот бір түсінікті кейске сүйеніп тұрмаса, толық құжат ағынында ол одан да тез құлайды.
RAG пен ұзын контекстті талқылағанда әңгіме жиі теорияға ауып кетеді. Кішкентай, бірақ шынайы тест жинағын құрып, бірдей сұрақтарда тәсілдерді салыстырған пайдалырақ. Оған қарапайым сұрақтарды, сирек терминдерді, ұзын құжаттарды және мағынасы ұқсас, модель оңай шатасатын екі-үш жауапты қосыңыз.
Осы жинақта үш схеманы өткізіп көріңіз: RAG, ұзын контекст және гибрид. Тек орташа нәтижеге қарамаңыз. Ұзын контекст қысқа жиында жақсы жауап беріп, бірақ нақты құжаттарда бағаны күрт өсіретін жағдайлар болады. Ал RAG ретривер нашар белгілеуге немесе файлдардың ескі нұсқаларына тап болғанға дейін жақсы сан көрсетеді.
Іске қоспай тұрып, команда бұзуға дайын емес шектерді бекітіңіз: бір жауаптың немесе бір сессияның бағасы, алғашқы токен мен толық жауаптың кідірісі, тест жиынындағы дұрыс жауаптар үлесі, ұзын және шуылы көп құжаттардағы мінез-құлық және нақты жүктемедегі тұрақтылық.
Мұндай шекараларсыз таңдауды көбіне демодағы әсерге қарап жасайды. Бұл шешім қабылдаудың нашар тәсілі.
Егер мұндай тесттерді әртүрлі модельдер мен провайдерлерде тез өткізу керек болса, оны AI Router арқылы жасау ыңғайлы. Қызметтің OpenAI-мен үйлесімді бір API-і бар: командыңызға base_url-ды api.airouter.kz-ке ауыстыру жеткілікті, сонда SDK, код және промпттарды қайта жазбай-ақ нұсқаларды салыстыруға болады.
Пилоттан кейін презентацияда жақсы көрінген схеманы емес, сіздің әдеттегі жүктемеде сапаны ұстап тұратын нұсқаны қалдырыңыз. Егер білім базасы күнде жаңарып, пайдаланушылар құжат фрагменттері бойынша нақты сұрақтар қойса, RAG көбіне баға жағынан ұтады. Егер құжат аз болса, ал жауап кең контекстке тәуелді болса, ұзын контекст қарапайымырақ шешім болуы мүмкін.
Алдымен бір сценарийде пайдасын дәлелдеңіз. Содан кейін ауқымды кеңейтіңіз.
Жиі қойылатын сұрақтар
RAG қашан ұзын контекстен жақсырақ?
RAG әдетте база үлкен болғанда, сұрақтар тар болғанда және жауап бірнеше абзацтың ішінде жатқанда ұтады. Мұндай жағдайда жүйе керек бөліктерді тауып, модельді бүкіл архивті оқуға мәжбүрлемейді.
Бұл нұсқа көбіне баға мен кідірісті жақсырақ ұстайды. Бірақ ол тек іздеу шынымен қажет фрагменттерді тапқанда жақсы жұмыс істейді.
Ұзын контекст қашан орындырақ көрінеді?
Егер құжаттар аз болса, қысқа болса және сирек өзгерсе, ұзын контекст жиі ыңғайлырақ болады. Команда мәтінді бірден модельге береді де, индекс, бөлу және іздеуді баптауға уақыт жұмсамайды.
Бірнеше ондаған нұсқаулықтан тұратын пилот немесе ішкі база үшін бұл көбіне жеткілікті. Кейін база үлкейсе, схеманы қайта қараған дұрыс.
RAG-та сапа көбіне неден бұзылады?
Точностьқа ең көп әсер ететіні — модельдің өзі емес, іздеу сапасы. Егер мәтінді дұрыс тазаламаған болсаңыз, фрагменттерді біркелкі бөлмесеңіз немесе құжаттардың ескі және жаңа нұсқаларын араластырып жіберсеңіз, модель жауапқа қате негіз алады.
Алдымен жүйе керек бөліктерді қолмен таба ма, соны тексеріңіз. Содан кейін ғана жауап сапасына қараңыз.
Неге ұзын контекст әрдайым дәл жауапқа кепіл емес?
Өйткені мәтін терезеде бар болуы модель оны міндетті түрде байқайды дегенді білдірмейді. Ұзын құжаттарда да ол күндерді, лимиттерді, сілтемелерді және ерекшеліктерді өткізіп жіберуі мүмкін.
Жағдайды артық шу ушықтырады. Егер сұрауға ескі нұсқаларды, қосымшаларды және қажетсіз бөлімдерді қоссanız, модель назарын дұрыс емес жерге жұмсайды.
Күніне мыңдаған сұрақ түскенде әдетте қайсысы арзанырақ?
Жүктеме үлкен болғанда көбіне RAG арзанырақ болады. Модель әр жауапқа азырақ токен оқиды, сондықтан айырмашылық тез-ақ есепте көрінеді.
Ұзын контекст тек шағын құжаттар жиынында арзанға түсуі мүмкін, онда индекс өзін ақтамайды. Сондықтан модельдің бағасын емес, бір жауапқа кететін мәтін көлемін және қайталау санын есептеңіз.
Пайдаланушы үшін қайсысы жылдамырақ?
Үлкен білім базасында RAG жиі жылдамырақ болады, өйткені модель жүздеген бет емес, 5–10 фрагментті ғана оқиды. Іздеу де уақыт алады, бірақ бұл қосымша көбіне ұзын мәтінді оқудан аз болады.
Егер сізде бір қысқа құжат пен бір сұрақ болса, ұзын контекст жылдамырақ жауап бере алады. Мұнда теория емес, нақты кіріс көлемі шешеді.
RAG пен ұзын контекстті қалай әділ салыстыруға болады?
20–30 нақты сұрақ алыңыз, ойдан шыққан ыңғайлы мысалдарды емес. Әр сұрақ үшін алдын ала дұрыс жауапты немесе жүйе қайтаруы тиіс фактілерді жазыңыз.
Содан кейін бірдей жинақты RAG және ұзын контекст арқылы өткізіп, дәлдік, баға және кідірісті салыстырыңыз. Таблицаларға, сілтемелерге, құжаттардың ұқсас нұсқаларына және база ішінде жауабы жоқ сұрақтарға бөлек қараңыз.
Бірден гибрид схема жасаған дұрыс па?
Иә, көптеген өнімдерде гибрид ең тыныш шешім болады. Қысқа фактілік сұрақтарды фрагменттер бойынша іздеу арқылы жіберуге болады, ал бір үлкен келісімшартты немесе есепті ұзын контекст арқылы талдаған ыңғайлы.
Осылайша сіз бір схемаға барлық міндетті бірдей арта салмайсыз. Әдетте бұл сапаны бірқалыпты етеді және шығынды түсініктірек басқарады.
Жіберу кезінде қандай қателер жиі кездеседі?
Көбіне команда құжаттарды жұмысқа дайындауда қателеседі. RAG-та мәтінді кездейсоқ бөліктерге бөліп, тақырыптар мен кестелерді жоғалтып жібереді, ал ұзын контекстте модельге бүкіл архивті сұрыптамай-ақ жібере салады.
Тағы бір жиі қате — әлсіз тест. Егер сіз жүйені бес жеңіл сұрақпен ғана тексерсеңіз, нақты жұмыста не болатынын іс жүзінде білмейсіз.
Уақыт аз болса, пилотты неден бастаған дұрыс?
Бір сценарийден бастаңыз: қолдау қызметі, регламенттер бойынша іздеу немесе келісімшарттарды талдау. Бірден бүкіл базаны және барлық сұрақ түрін алмаңыз.
Шағын сұрақтар жинағын құрып, дәлдік, баға және кідірісті өлшеңіз де, содан кейін сол сценарийге сай схеманы таңдаңыз. Егер пилот бір нақты кейсте тұрмаса, толық көлемде ол одан сайын бұзылады.