Ұзын құжаттар үшін prefill мен decode-ты бөлу
Ұзын құжаттарда prefill мен decode-ты бөлу кідірісті қай кезде азайтатынын, ал қай кезде артық кезек, тәуекел және шығын қосатынын талдаймыз.
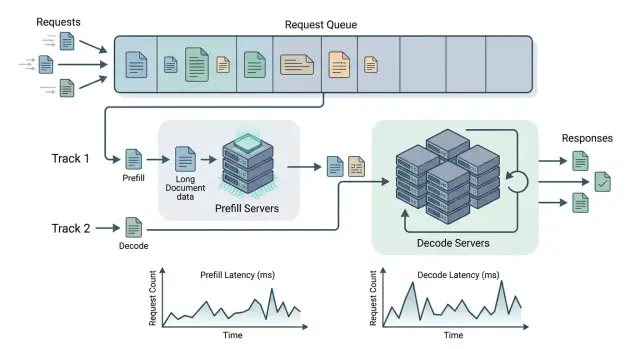
Неліктен ұзын құжаттар тар орынға айналады
Мәселе жауап генерациясынан бұрын басталады. Модель ұзын келісімшарт, нұсқаулық немесе үлкен хат алмасуды алған кезде, алдымен бүкіл кірісті өңдеуі керек. Бұл кезең prefill деп аталады. Кірістегі токендер саны артқан сайын, GPU тек оқып, модельдің ішкі күйін дайындауға көбірек уақыт жұмсайды.
Қысқа чатта бұл іс жүзінде білінбейді. Бірақ 80 немесе 150 беттік құжатта айырмашылық айқын: мұндай бір сұрау қолдау қызметінің ондаған қысқа сұрауынан, білім базасын іздеуден немесе өнім ішіндегі қарапайым көмекшіден ұзақ ресурс ұстап тұруы мүмкін.
Соның салдарынан тек ұзын сұраудың өзі емес, бүкіл жүйе зардап шегеді. Қысқа және ұзын тапсырмалар бір кезек арқылы өтсе, ауыр кіріс басқалардың бәрін тежей бастайды. Тіпті трафик орташа болса да, кідіріс команда күткеннен тез өседі. Кейде бірнеше ірі сұрау қатар келсе жеткілікті.
Ең жағымсыз әсер TTFT-де, яғни алғашқы токенге дейінгі уақытта көрінеді. Пайдаланушы ұзақ әрі әдемі жауапты күтпейді. Ол жүйе шынымен жауап бере бастағанын білгісі келеді. Бірақ decode resource prefill-мен босамайынша немесе кезек осы сұрауға жетпейінше басталмайды. Интерфейс үнсіз тұрады, ал генерация кейін өте жылдам өтуі мүмкін.
Бұл заңгерлерге арналған ішкі көмекшіде жақсы байқалады. Бір қызметкер ұзын келісімшартты талдауға жібереді, сол кезде басқалары қысқа сұрақтар қояды: "7-тармақта қандай айыппұл көрсетілген?" немесе "абзацтың екі нұсқасын салыстыр". Егер мұның бәрі бір GPU пулына түссе, ұзын құжат бүкіл команданың жауап уақытын артқа шегереді.
Сондықтан prefill мен decode-ты бөлу орынды көрінеді. Тар орын көбіне модельдің жазуға ұзақ уақыт жұмсауында емес, ұзын контексті ортақ ресурс үстінде тым ұзақ оқуда жатыр.
Prefill мен decode бөлінгенде не өзгереді
Бір GPU пул әрі ұзын кірісті оқып, әрі жауап генерацияласа, ұзын сұраулар басқалардың бәріне кедергі келтіреді. Үлкен келісімшарт немесе көп нұсқаулық жады мен уақытты жүйе токенді пайдаланушыға бере алатын жерде жұмсайды.
Бөлінгеннен кейін жүктеме екі пулға тарайды. Prefill ресурстары ұзын мәтінді өткізіп, модель күйін дайындайды, ал decode ресурстары тек қадамдық генерациямен айналысады. Өзгеретін нәрсе тек іске қосу схемасы емес, кезектердің мінез-құлқы да.
Бұл кезеңдердің жүктеме профилі әртүрлі. Prefill кірістің үлкен бөліктерін жақсы көтереді және кейін үлкен контекстті тез өңдесе, қысқа үзіліске шыдай алады. Ал decode, керісінше, кез келген кідірісіне сезімтал. Токендер үзік-үзік келсе немесе алғашқы жауап кеш шықса, пайдаланушы бірден байқайды.
Сол себепті команда енді бір ғана ортақ кідіріс санына қарамай, сұраудың жолын кезең-кезеңімен талдай бастайды: prefill күтуі, prefill уақыты, күйді беру, decode күтуі және генерацияның өзі. Мұндай бөлініс жай ғана "жауап 9 секундта келді" дегеннен пайдалырақ.
Тәжірибеде бұл команданың ішкі әңгімесін тез өзгертеді. Егер алғашқы токенге дейінгі уақыт өссе, себебі бірден түсінікті болады: ұзын кірістер prefill пулын толтырған немесе decode нодалары басқа сессияларға бітелген. Бөлінбей тұрғанда екі мәселе бір нәрсе болып көрінеді де, команда жиі дұрыс емес жерді жөндейді.
Мысал қарапайым. Заңгер 120 беттік келісімшартты LLM-ге беріп, күмәнді тармақтарды табуды сұрайды. Ортақ кезекте бұл сұрау қысқа қолдау диалогтарын оңай кідіртіп тастайды. Бөлінген жағдайда бөлек пул құжаттың өзін өңдейді, ал жауап генерациясы ұзын кіріске тұншығып тұрмайтын басқа ресурстарда жүреді.
AI Router сияқты LLM-шлюз үшін бұл маршрутизация мәселесі де. Егер сұраулар бір OpenAI-үйлесімді қабат арқылы өтсе, ұзын контекстке қай жерде қуат жетпейтінін, ал қай жерде decode-тың өзі шектелетінін көру жеңілдейді. Сонда мәселе абстрактылы "модель баяу" деген емес, тар орындардың түсінікті картасы болып көрінеді.
Бұл схема қай кезде шынымен көмектеседі
Prefill мен decode-ты бөлу модель оқуға жауап жазғаннан әлдеқайда көп уақыт жұмсайтын жерде пайдалы. Егер пайдаланушы 150 беттік келісімшарт бойынша бір сұрақ қойса, уақыттың көп бөлігі дәл кіріске кетеді. Мұндай жағдайда кезеңдерді әртүрлі ресурстарға бөлу нақты ұтыс беруі мүмкін.
Әдетте бұл TTFT арқылы көрінеді. Пайдаланушы әлі бірде-бір токенді көрмеген кезде, GPU үлкен контекстті өңдеумен айналысып тұрады. Егер трассировкалар уақыттың бәрі дерлік prefill-ге кететінін көрсетсе, схема мәнге ие бола бастайды.
Ең жақсысы ұзын кіріс, қысқа шығыс болғанда жұмыс істейді. Мысалы, сервис келісімшартты, есепті, анкетаны немесе медициналық картаны оқып, кейін бірнеше сөйлеммен жауап береді: керекті тармақ табылды ма, қауіп бар ма, қандай дерек жетіспейді, шаблонға не сәйкес келмейді.
Схема сәйкес келетінін көрсететін бірнеше типтік белгі бар:
- құжаттар үлкен, ал жауаптар қысқа;
- кіріс ұзындығы сұраудан сұрауға қатты өзгереді;
- пайдаланушылар жиі келісімшарт, есеп, анкета немесе медициналық карта жүктейді;
- мәселе жалпы жауап ұзақтығында емес, дәл TTFT-де көрінеді;
- мониторинг prefill decode-қа қарағанда көбірек жүктелетінін көрсетеді.
Кіріс көлемінің қатты ауытқуы әсіресе маңызды. Бір сұрауда 3 мың токен, келесісінде 120 мың токен болса, ортақ пул біркелкі жұмыс істемей қалады. Қысқа сұраулар ұзындарының жанында күтіп тұрады да, кідіріс қажетсіз өседі. Prefill үшін бөлек ресурс бұл кезекті тегістейді.
Заңгер көмекшісінің мысалы осыған жақсы келеді. Таңертең ол шаблондар бойынша қысқа сұрақтар алады, ал түстен кейін қызметкерлер жаппай келісімшарт скандарын және ұзын қосымшаларды жүктейді. Бөлінбей тұрғанда бір ауыр құжаттар пакеті бәрін тежеп тастайды. Бөлінгенде prefill оқуды және контекстті дайындауды өзіне алады, ал decode артық паузасыз қысқа жауаптарды береді.
Маршрутизациясы бар жүйелерде бұл ерекше байқалады. Ауыр prefill-ді неғұрлым қолайлы ресурсқа жіберуге, ал decode-ты төмен кідірісті топта ұстауға болады. Мұндай тәсіл болжамдылық маңызды болғанда пайдалы: пайдаланушы қысқа жауапты кешіреді, бірақ алғашқы токенге дейінгі ұзақ үнсіздікті нашар қабылдайды.
Егер метрикалар prefill жағында айқын ауытқу көрсетпесе, схеманың ақталуы екіталай. Бірақ сервис негізінен ұзын құжаттарды оқып, қысқа қорытынды берсе, әсері әдетте тез білінеді.
Қай кезде ол тек күрделілік қосады
Prefill мен decode-ты бөлу өздігінен пайда әкелмейді. Егер сұраулардың бәрі дерлік қысқа болса, сіз айтарлықтай ұтыссыз-ақ күрделірек схема құрасыз. Жүйеде ақау нүктелері, кезектер және түсініксіз кідірістердің себептері көбейеді.
Жиі қате былай болады: команда сирек кездесетін ұзын құжаттарды байқап, бүкіл инференс контурын алдын ала қайта құрады. Бірақ трафиктің 90%-ы қысқа контекстпен келсе, prefill үшін бөлек пул бос тұрады. Жаңа маршрутизация ережелері, бөлек лимиттер, жаңа алерттер және қосымша отладка пайда болады, ал жауап уақыты шамамен сол күйінде қалады.
Тағы бір нашар сценарий — жүйе кіріске емес, decode-қа тірелгенде. Бұл құжат онша ұзын емес, бірақ жауап кең болуға тиіс болғанда кездеседі: бір беттік сводка, егжей-тегжейлі түсіндіру немесе ұзын JSON. Онда сұраудың қымбат бөлігі prefill-ден кейін басталады. Сіз пайплайннің кіші бөлігін жылдамдатасыз, ал пайдаланушы бәрібір сол шамада күтеді.
Біркелкі трафик те суретті өзгертеді. Күрт өсулер болмаса, ортақ пул көбіне екі маманданған пулдан жақсырақ жұмыс істейді. Оны басқару жеңіл және әдетте жүктемені біркелкі ұстайды. Бөлек пулдар кері әсер беруі мүмкін: бірі төмен жүктеледі, екіншісі қызып кетеді.
Ең жаман идея — мұндай схеманы кезеңдер бойынша метрикасыз енгізу. Егер команда TTFT, prefill ұзақтығы, decode жылдамдығы, кезек ұзындығы және пулдар арасындағы кідірісті өлшемесе, пікір тез арада болжамға айналады.
Сонда желілік өтімді оптимизация деп шатастыру оңай. Тәжірибеде пулдар арасындағы қосымша hop, күйді сериализациялау және лимиттерді қайта тексеру бүкіл ұтысты жеп қоюы мүмкін. Кейде бұл сұрау үшін ондаған миллисекунд қана, бірақ тұрақты ағынға түскенде тез жиналады.
Егер команда қазірдің өзінде әртүрлі модельдермен жұмыс істеу үшін AI Router сияқты бірыңғай шлюзді қолданса, ішкі бөлінуді тек өлшемдерден кейін енгізген дұрыс. Әйтпесе қолдау күрделене түседі: инциденттерді талдау, тар жерді табу және командаға уақыттың қайда кеткенін түсіндіру қиындайды.
Контекст қысқа, decode басым және трафик болжамды болса, қарапайым контур әдетте ұтады.
Схеманы қадамдап қалай енгізуге болады
Алдымен базалық көріністі өлшеп алыңыз. Онсыз салыстыратын нәрсе болмайды. TTFT-ті, токен/секунд генерация жылдамдығын және кірістің нақты ұзындығын өлшеңіз. Тек орташа мәнді емес, p95-ті де қараңыз: ұзын құжаттар көбіне кідірістің құйрығын бұзады.
Кейін трафикті контекст ұзындығы бойынша қарапайым диапазондарға бөліңіз. Бірден он клас енгізудің қажеті жоқ. Әдетте үш топ жеткілікті: қысқа сұраулар, орташа және ұзын. Егер сізде келісімшарт, есеп немесе ондаған бет хат алмасу көп болса, ұзын кіріс шегі тез байқалады.
Содан кейін екі шағын пул көтеріңіз. Бірі prefill-мен, яғни ұзын кірісті оқып, күйді жинаумен айналысады. Екіншісі decode-ты өңдейді, мұнда токендердің бірқалыпты шығуы маңызды. Бастапқыда бүкіл трафикті көшірмеңіз. Айырмашылықты көріп, отладкаға тұншығып қалмас үшін тек ұзын сұраулардың бір бөлігін алыңыз.
Маршрутизация ережесі қарапайым болуы керек. Мысалы: қысқа кіріс бұрынғы жолмен өтеді, ұзындары бөлек prefill пулына жіберіледі, decode әрқашан өз пулында қалады, ал қате болса сұрау кәдімгі маршрутқа қайтады. Мұндай ережені тексеру де, кері қайтару да оңай.
Егер қазірдің өзінде бір OpenAI-үйлесімді шлюзіңіз болса, логиканы бөлек сервистерге көшірмей, бір жерде ұстаған дұрыс. Бұл командалар арасындағы айырмашылықты азайтады және тестті жеңілдетеді.
Келесі қадам — екі режимде тексеру: ең жоғары жүктемеде және тыныш уақытта. Пикте схема ұзын құжаттар үшін TTFT-ті жақсартуы мүмкін. Ал тыныш уақытта, керісінше, бос тұрған пул және артық ауысулар салдарынан қымбаттап кетуі мүмкін.
Тек орташа кідірісті санау аздық етеді. Мың сұрауға кететін құнды, GPU жүктемесін, таймаут үлесін және TTFT бойынша p95-ті салыстырыңыз. Кейде алғашқы токен тезірек келеді, бірақ жалпы есеп 15-20% өседі, ал қолдау айтарлықтай күрделене түседі.
Қалыпты тест қызықсыз көрінеді, бірақ бұл жақсы белгі. Егер бір апта өлшеуден кейінгі ұтыс тек зертханалық ортада ғана байқалса, ал тірі трафикте көрінбесе, схеманы продқа алып келмеген дұрыс.
Ұзын келісімшарттағы қарапайым сценарий
Банк 120 беттік келісімшартты жүктеп, модельден оны 12 тармақ бойынша тексеруді сұрайды деп елестетейік: айыппұл тәуекелі қайда, бұзу тәртібі қалай жазылған, тарифтерді кім өзгертеді, хабарлау мерзімдері қандай, және қай жердегі тұжырымдар тым бұлыңғыр. Адам үшін бұл кәдімгі заңгерлік тексеру. LLM үшін бұл ұзын контексті ауыр сұрау.
Мұндағы ең ұзақ бөлік жауап емес, құжатты оқу. Prefill кезеңінде модель келісімшарттың бүкіл мәтінін өткізіп, ішкі күйін жинайды. Бұл айтарлықтай уақыт алады және қысқа нәтижені генерациялаудан көбірек GPU жүктейді.
Содан кейін decode басталады. Модель келісімшартты қайта оқымайды, тек қорытынды жазады: тәуекел белгісі қойылған 12 тармақ және қысқа түсіндірмелер. Жауап бір-екі бетке созылуы мүмкін. Яғни кіріс орасан, ал шығыс салыстырмалы түрде шағын.
Егер мұндай келісімшарттар қарапайым сұраулармен бір ресурстан өтсе, кезек тез бұзылады. Бір ауыр prefill қысқа тапсырмаларды кідірте алады: хатты қысқарту, клиентпен чат талдау, өтінімді жіктеу. Пайдаланушы мәтін шағын әрі тапсырма жеңіл болса да, баяу жауап алады.
Осы жерде prefill мен decode-ты бөлу шынымен көмектесуі мүмкін. Келісімшарт ұзын оқуға арналған ресурсқа түседі, ал жауап генерациясы төмен кідіріс маңызды басқа ресурста жүреді. Бір LLM-шлюзде бұл әсіресе ұзын құжаттар мен кәдімгі чат сұраулары қатар өмір сүргенде пайдалы. Бір келісімшарт бүкіл ағынды кепілге алмайды.
Бірақ схеманың құны бар. Егер мұндай құжаттар сирек келсе, мысалы аптасына бірнеше рет қана, әуресі пайдасынан көп болуы мүмкін. Бөлек ресурс пулдарын ұстап тұру, этаптар арасындағы күйді беру, ретрайлар, метрикалар және отладканы баптау керек болады. Сирек тапсырмалар үшін көбіне ұзын сұраулардың кезегін шектеу немесе оларды бөлек маршрутқа шығару оңайырақ.
Бұл сценарийдің қорытындысы қарапайым: жүйеде өте ұзын құжаттар неғұрлым жиі пайда болса, prefill үшін бөлек ресурстың мәні соғұрлым артады. Ағын сирек болса, схема диаграммада әдемі көрінеді, бірақ қолдауда тез жалықтырады.
Схеманы бұзатын қателер
Көбіне команда бәрін бақылаудың өзінде-ақ бұзады. Ол prefill мен decode-ты бір жалпы кідіріс графигіне қосып, әдемі орташа сан алады. Мәселе мынада: мұндай график себебін жасырады: prefill ұзын контекстпен толып қалған, ал decode дерлік зардап шекпейді, немесе керісінше.
Метрикалар аралас болса, кезек қай жерде өсіп жатқанын және пайдаланушының жауабын не бүлдіріп тұрғанын көрмейсіз. Кем дегенде төрт сигналды бөлек ұстаған жеткілікті: prefill алдындағы кезек, prefill уақыты, decode жылдамдығы және қысқа мен ұзын сұраулар үшін p95 пен p99 бөлек.
Орташа мән көбіне орынсыз жұбатады. Пайдаланушы орташа кідірісті емес, 18 секундқа қатып қалған сирек жауапты байқайды.
Екінші жиі қате — барлық ұзын сұрауларды жаңа пулға айқын шектеусіз жіберу. Ұзындықтың өзі сұрау міндетті түрде бөлінуі керек дегенді білдірмейді. 9 мың токен кіріс ортақ пулдан еш қиындықсыз өте алады, ал 60 мың токендік келісімшарт ауыр жүйелік префикспен prefill-ді ұзаққа толтырады. Егер шекті көзбен таңдасаңыз, артық трафикті жаңа тармаққа жай ғана көшіресіз.
Тағы бір мәселе — тым шағын бөлінген пул. Команда ортақ пулдағы кезекті алып тастап, бірден басқа жерде жаңа кезек жасайды. Қағазда архитектура ақылдырақ көрінеді. Нақты жүктемеде ұзын құжаттар жай ғана басқа қатарға тұрады, ал p95 нашарлайды.
Көп жағдайда prompt cache те естен шығады. Бұл қымбат қате. Егер жүйелік нұсқаулар, жауап шаблондары, заңгерлік дисклеймерлер немесе типтік келісімшарттың алғашқы беттері қайталанса, кэш кейде бөлек пулдан да көп пайда береді. Оны ұстау да жеңілірек.
Жақсы мысал — ұзын келісімшартты өңдеу. Егер әр сұрау бірдей префиксті, ережелерді, классификаторларды және қызметтік мәтінді қайта-қайта өткізсе, prefill уақытты босқа жұмсайды. Сол сәтте командаға жаңа маршрутизация схемасы керек сияқты көрінуі мүмкін, ал шын мәнінде алдымен қайталануды алып тастау керек еді.
Нашар белгі оңай танылады: жүйе күрделене түсті, ал кідірістің себебі бәрібір түсініксіз. Егер prefill мен decode-ты бөлек көрмесеңіз, p95 және p99-ды есептемесеңіз және кэшті тексермесеңіз, бөлу тез арада қосымша кезегі бар қымбат баптауға айналады.
Іске қоспас бұрын жылдам тексеру
Бұл схеманы сезіммен емес, цифрмен қосқан дұрыс. Егер команда уақыттың қайда кетіп жатқанын түсінбесе, prefill мен decode-ты бөлу бірден қолдауы қиын, түсіндіруі ауыр тағы бір қабатқа айналады.
Іске қоспас бұрын бірнеше нәрсені тексеріңіз. Алдымен кідірістің қанша бөлігі prefill-ге кететінін қараңыз. Егер жалпы уақыттың жартысынан көбі сонда отырса, тесттің мәні бар. Егер негізгі ауырлық decode-тың өзінде болса, ұтыс шамалы болады.
Сосын кіріс пен шығыс ұзындығын салыстырыңыз. Орташа жауап бастапқы құжаттан бірнеше есе қысқа болса, prefill үшін бөлек ресурстар жиі айтарлықтай эффект береді. Одан кейін сұраулар ұзындығының ауытқуын бағалаңыз. Бір сұрауда 3-5 мың токен болып, басқасында 30-50 мың токен болса, ортақ пул дерлік әрдайым біркелкі жұмыс істемейді. Кемінде 5-10 есе айырма — бөлек схеманы тексеруге себеп.
Бір метрикаға емес, кемінде үшеуіне қарау керек: TTFT, өткізу қабілеті және кезек ұзындығы. Егер TTFT түсіп, бірақ decode кезегі өссе, демек сіз тар орынды басқа жерге жай ғана жылжыттыңыз. Іске қоспай тұрып-ақ бір пулға тез қайтатын қарапайым rollback керек. Ауысу бірнеше минутта жасалуы тиіс, бөлек спринтте емес.
Жақсы белгі былай көрінеді: пайдаланушылар ұзын келісімшарт, есеп немесе хат алмасу жібереді, модель үлкен кірісті оқиды да, қысқа әрі нақты жауап береді. Бұл режимде prefill жүйені жауап генерациясынан көбірек жүктейді. Онда бөлу алғашқы токенге дейінгі уақытты айтарлықтай қысқартып, кезекті біркелкі етуі мүмкін.
Нашар белгіні де тану оңай. Егер құжаттар ұзындығы жағынан ұқсас болса, жауаптар да шамамен сондай ұзын болса, ал команда әлі тек орташа кідірісті қарап отырса, схема аз ғана пайда береді. Ол жаңа маршрутизация ережелерін, жаңа кезектерді және көбірек ақау нүктелерін қосады.
Өндірістік LLM-сценарийлерін қазірдің өзінде бірыңғай API-шлюз арқылы жүргізіп отырған командалар үшін тексеру әдетте сұраулар журналдары мен екі-үш жүктемелік іске қосуға дейін қысқарады. Бұл сіздің шынымен prefill-ді емдеп тұрғаныңызды, әлде жай ғана қолданба архитектурасын күрделендіріп жатқаныңызды түсінуге жеткілікті.
Кейін не істеу керек
Prefill мен decode-ты бүкіл ағынға бірден таратпаңыз. Кірісі шамамен тұрақты бір типтегі ұзын құжаттарды алыңыз: 80-150 беттік келісімшарттар, тендер пакеттері немесе ұзын медициналық выпискалар. Трафиктің бір бөлігіне A/B-тест жасап, кәдімгі маршрут пен бөлінген схеманы бірдей промпттарда салыстырыңыз.
Тек орташа кідірісті емес, басқа нәрселерді де қараңыз. Ұзын құжаттарда орташа мән жиі алдайды: бір жылдам прогон ең жоғары жүктеме кезіндегі баяу prefill-ді жасырады. Өлшеулерді модель, кіріс ұзындығы, толық сұрау құны және алғашқы токенге дейінгі уақыт бойынша бөліңіз. Маршрутизация қателерін, қайталанған prefill-ді және decode бос ресурс күтуі сіз үнемдегеннен ұзақ болған жағдайларды бөлек белгілеңіз.
Қарапайым кесте жинау пайдалы: модель мен провайдер, кіріс ұзындығы токенмен, prefill және decode уақыты, толық жауап құны және схеманың пайда берген сұраулар үлесі. Бірнеше күннен кейін қай жерде ұзын контекст архитектураны күрделендіруге тұратынын, ал қай жерде тұрмайтынын көресіз. Әдетте шекара саласы бойынша емес, құжат ұзындығы мен бір мәтінге қайталанған сұраулар саны бойынша өтеді.
Егер құжаттарды ел сыртында сақтауға болмайтын болса, екінші сұрақты кейінге қалдырмаңыз: open-weight модельдерді жергілікті хостингпен қолдану керек пе. Банктер, мемлекеттік сектор және healthcare-дің бір бөлігі үшін бұл кәдімгі талап. Ондай жағдайда тек бұлттық маршруттарды емес, open-weight модельдер үшін жергілікті контурды да салыстыру керек.
Егер команда бірден бірнеше маршрутты тексерсе, әр провайдерге жеке интеграция жасаудың қажеті жоқ. Егер сізде already OpenAI API-ге арналған стек болса, AI Router мұндай тестті жеңілдетеді: base_url-ды api.airouter.kz-ке ауыстырып, сол SDK, код және промпттарды бір OpenAI-үйлесімді endpoint арқылы жібере бересіз. Эксперимент үшін бұл ыңғайлы: қосымша қабатқа аз уақыт кетеді, ал лог пен аудитті бір жерден қарау оңай.
Бұл кезеңнің қалыпты қорытындысы қарапайым көрінеді, бұл жақсы. Сізде кіріс ұзындығы бойынша шек, prefill және decode үшін модельдер тізімі, әрі схема қай жерде секунд пен ақшаны үнемдейтінін, ал қай жерде тек жүйені күрделендіретінін түсіндіретін нақты жауап болады.
Жиі қойылатын сұрақтар
Prefill мен decode-ты бөлу қашан нақты пайда береді?
Сервисте өте ұзын кіріс болып, жауап қысқа шыққанда этаптарды бөліңіз. Әдетте бұл келісімшарттар, есептер, анкеталар және медициналық карталарда керек болады, өйткені TTFT контекстті оқудан өседі, ал генерацияның өзінен емес.
Ненің тежеп тұрғанын қалай түсінуге болады: prefill ме?
Этаптар бойынша трассировканы қараңыз. Уақыттың көп бөлігі алғашқы токенге дейін кетсе, ал prefill decode-қа қарағанда көбірек жүктелсе, мәселе кірістің өзінде болуы әбден мүмкін.
Сұраулардың көбі қысқа болса, мұндай схема керек пе?
Көбіне жоқ. Егер трафиктің басым бөлігі қысқа әрі болжамды болса, ортақ пул қарапайымырақ, арзанырақ және тұрақтырақ болады.
Ұзын құжаттар сирек келсе, не істеу керек?
Ондайда алдымен бөлек маршрут жасаңыз немесе ауыр сұраулар үшін кезекті шектеңіз. Аптасына бірнеше құжат үшін тұрақты бөлек пул ұстау көбіне тиімсіз.
Іске қоспас бұрын қандай метрикаларды өлшеу керек?
TTFT, p95 және p99, кіріс ұзындығы токенмен, prefill ұзақтығы, decode жылдамдығы және кезектердің ұзындығына қараңыз. Орташа мәннің өзі көп нәрсе айтпайды, өйткені ұзын құжаттар кідірістің құйрығын бұзады.
Егер модельдің жауабы да ұзын болса, схема көмектесе ме?
Пайдасы көбіне аз болады. Егер модель кейін ұзақ сводка, үлкен JSON немесе кең түсіндірме жазса, decode-тың өзі тар орынға айналады.
Артық тәуекелсіз қалай енгізуге болады?
Оны трафиктің бір бөлігінде іске қосып, ескі жолға тез қайтатын мүмкіндік қалдырыңыз. Әдетте ұзын кірістерді бөлек prefill-пул арқылы өткізіп, қалғанын кәдімгі маршрутта қалдыру жеткілікті.
Бұл схеманы көбіне қандай қателер бұзады?
Көбіне командалар prefill мен decode метрикаларын бір графикке біріктіріп, кідірістің себебін көрмей қалады. Сондай-ақ ұзындық шегін "көзбен" қою, тым шағын бөлек пул және этаптар арасындағы артық желілік өтім зиян келтіреді.
Prompt cache пулдарды бөлуден пайдалырақ болуы мүмкін бе?
Иә, жиі солай. Егер сізде жүйелік нұсқаулар, жауап шаблондары немесе құжаттың бірдей бөліктері қайталанса, кэш жаңа архитектурадан да оңай артық prefill-ді алып тастайды.
AI Router сияқты бірыңғай шлюз бұл идеяны тексеруге қалай көмектеседі?
Трафик бір OpenAI-үйлесімді қабат арқылы өтсе, командаға маршруттарды салыстыру және prefill қай жерде, decode қай жерде іркіліп тұрғанын көру оңайырақ болады. AI Router ішінде base_url-ды ғана ауыстырып, сол SDK, код және промпттарды қалдыруға болады, ал логтар мен аудитті бір жерден қарайсыз.