Модельдерді жұптық салыстыру: орташа баллсыз A қай жерде B-дан жақсы
Парное сравнение моделей показывает, где одна LLM выигрывает на извлечении данных, а другая — в диалогах, суммаризации и длинных ответах.
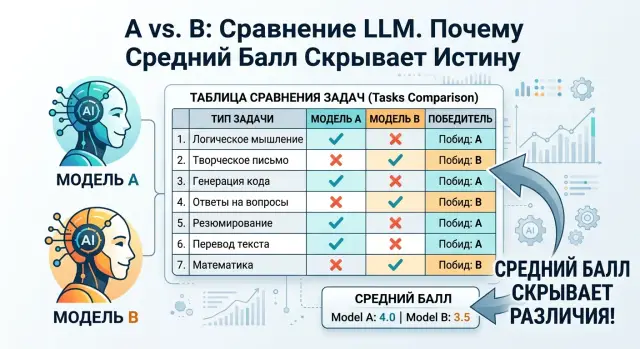
Неліктен орташа балл жаңылыстырады
Бір жалпы балл ыңғайлы көрінеді. Кестені аштыңыз, 84 пен 81-ді көрдіңіз де, таңдау анық сияқты болады. Іс жүзінде бұл көбіне дұрыс ишара емес.
Орташа көрсеткіш әртүрлі қателерді бір жерге үйіп тастайды, ал олардың құны бірдей емес. Модель сәл ғана жылы жауап жазуда нашар болса, бұл жағымсыз, бірақ көтеруге болады. Ал егер ол төлем сомасын, шарт нөмірін немесе өтініш мәртебесін шатастырса, салдары мүлде басқа.
Банк қолдауында бұл әсіресе анық байқалады. A моделі чат жүргізуде жақсырақ болуы мүмкін: сабырлырақ сөйлейді, шарттарды түсініктірек түсіндіреді, клиенттен жұмсақтау нақтылайды. Бірақ сол модель CRM өрістерін толтыруда әлсіздеу болып, операция күнін жиірек жоғалтып немесе өнім түрін қате қоюы мүмкін. B моделі қысқалау жауап береді, бірақ әңгімеден фактілерді дәлірек шығарады. Мұның бәрін бір санға сыйдырсаңыз, осы айырмашылық жоғалып кетеді.
Орташа көрсеткіш жеңіл және қиын кейстерді де араластырып жібереді. Айталық, тесттің 70%-ы жұмыс уақыты, лимиттер және базалық тарифтер туралы жеңіл сұрақтар. Күшті модельдердің көбі олардан оңай өтеді. Қалған 30% — даулы жағдайлар: екі рет есептен шығару, алаяқтық бойынша эскалация, толық емес дерекпен келген сұрау. Дәл сол жерде жұмыс сценарийі бұзылады, бірақ жалпы балл оны көрсетпейді.
Кейде модель жеңіл мысалдардың көптігі есебінен ұтады. Ол оңай тапсырмалардан ұпай жинап, қателіктің бағасы қымбат жерлерде ұтылады. Есепте жақсы көрінеді. Нақты жүйеде — жоқ.
Сондықтан жұптық салыстыру пайдалырақ. Олар сізді әдемі орташаға емес, A мен B-ның тапсырма түрлері бойынша нақты бетпе-бет келулеріне қарауға мәжбүр етеді.
Модельді таңдар алдында бірнеше тікелей сұрақ қою жеткілікті:
- модель мағынаны қай жерде жоғалтады, ал қай жерде тек жауап стилін бұзады;
- қандай қателерді ережемен жабуға болады, ал қайсысы бірден процеске соққы береді;
- қандай тапсырмалар сирек болса да, бизнес үшін қымбат.
Орташа баллға сүйеніп шешім қабылдау көбіне тестті емес, жұмыс сценарийін бұзады. Команда жалпы бағасы жақсырақ модельді таңдап, оны prod-қа шығарады да, кейін қолмен тексерулер көбейгенін, өрістердің түсіп қалғанын және артық эскалацияларды көреді. Кесте бір нәрсе уәде етті, ал күнделікті жұмыс мүлде басқа нәрсені көрсетеді.
A мен B жұбында нені салыстыру керек
Егер бірден бірнеше параметрді өзгертсеңіз, салыстырудың мәні жоғалады. A моделі мен B моделін бірдей жағдайларда тексеру керек: бір prompt, бір temperature, бір жауап форматы, бірдей system нұсқаулар және бірдей токен лимиті. Әйтпесе сіз модельдерді емес, олардың айналасындағының бәрін салыстырасыз.
Дәл осы қағида тапсырмалар жиынына да қатысты. Тұрақты мысалдар тізімін алыңыз да, тест барысында оған жаңасын қоспаңыз. Егер бірінші жартысында қысқа сұрақтар болса, ал екінші жартысында ұзақ әрі күрделі сұрақтар болса, A мен B бойынша қорытынды шуылға айналады.
Бағалау критерийлерін де алдын ала бекітіп қойған дұрыс. Іске қосар алдында жақсы жауап нені білдіретінін шешіңіз: фактілердің дәлдігі, форматты сақтау, толықтық, қысқалық, артық жорамал жасамау. Команда жауаптарды көргеннен кейін ережені өзгерте бастаса, салыстыру тез арада талғам туралы дауға айналады.
Жалпы ұпайға ғана емес, әр мысалдың нәтижесіне де қараған ыңғайлы. Әр тапсырмаға үш нәтиженің бірін қойыңыз: A жеңеді, тең, немесе B жеңеді. Мұндай тәсіл бір модель қай жерде тұрақты күшті екенін, ал қай жерде айырмашылықтың жоғалатынын бірден көрсетеді.
Сапамен бірге жұмыс метрикаларын да жазып жүрген пайдалы. Кейде модель сәл жақсырақ жауап береді, бірақ бағасы үш есе қымбат немесе екі секундқа көп кешігеді. Продакшен үшін бұл ұсақ нәрсе емес. Кем дегенде төрт нәрсеге қараңыз: жауап сапасы, баға, кідіріс және токендегі жауап ұзындығы.
Қате түрін бөлек белгілеңіз. Бір ұтылудың мәні әртүрлі болуы мүмкін:
- факт — модель деректі ойдан шығарды немесе шатастырды;
- формат — JSON, кесте немесе жауап құрылымын бұзды;
- өткізіп жіберу — сұрақтың бір бөлігіне жауап бермеді;
- артық мәтін — су, түсіндірме немесе жорамал қосты;
- орынсыз бас тарту — шамадан тыс сақтанып, қалыпты сұранысты орындамады.
Мұндай белгілеу модельдің мінезін тез көрсетеді. Біреуі фактіде жиі қателеседі, екіншісі форматты жақсы ұстайды, бірақ детальдарды өткізіп жібереді. Бұл модельді нақты тапсырмаға сай таңдауға көмектеседі, әдемі орташа санға емес.
Егер тесттерді бір OpenAI-үйлесімді шлюз арқылы жүргізсеңіз, бірдей баптауларды сақтау оңайырақ. Мысалы, AI Router-да SDK-ны, кодты және шақыру форматын қайта жазбай-ақ, моделді ауыстыруға болады. Бұл тексеруді жиі бұзатын кездейсоқ айырмашылықтардың бір бөлігін алып тастайды.
Қай жерде бірге емес, бөлек есептеу керек
Бір ортақ баға көбіне тапсырмалар арасындағы айырмашылықты жасырады. A моделі чатта біркелкілеу жазуы мүмкін, ал B моделі ұзақ құжаттан деректерді дәлірек шығарады. Мұның бәрін бір санға жинасаңыз, продакшен үшін модель таңдауда керегі ең маңызды сигналды жоғалтасыз.
Алдымен тапсырмалар жиынын жұмыс түрі бойынша бөліңіз. Әдетте бес топ жеткілікті: чат, ақпарат алу, суммаризация, классификация және код. Бұл жай формалдылық емес. Әр топтың өз жеңіс ережесі бар, ал бір топтағы күшті жақ екінші топтағы әлсізді оңай жасырады.
Чаттағы жақсы жауапты кейде сәл қатаң емес формат үшін кешіруге болады. Ал ақпарат алу мен классификацияда олай болмайды. Егер модель ЖСН-ды, өтініш түрін немесе клиент мәртебесін шатастырса, жағымды стиль ештеңені өзгерпейді.
Қысқа және ұзын контекстті араластырмаңыз. Қысқа сұрауда екі модель де шамалас жүре алады, ал 20 бетте айырмашылық анық көрінеді: бірі фактілерді соңына дейін ұстайды, екіншісі деталь жоғалтып, қайталап немесе бос орынды жорамалмен толтыра бастайды.
Тілге де солай қараңыз. Қазақ, орыс және ағылшын сұрауларын, мағынасы бірдей болса да, бөлек есептеген дұрыс. Көп команда қазақшада жақсы орташа балл көріп, кейін дәл өткізіп алмауға тиіс жерлерде әлсіз жауап алып жатады.
Жауап форматы стильден маңызды болған тапсырмалар үшін бөлек топ ашқан жөн. Мысалы:
- қатаң схема бойынша JSON;
- тек бір ғана рұқсат етілген белгісі бар классификация;
- артық мәтінсіз өрістерді шығару;
- іске қосылуы тиіс SQL немесе код;
- міндетті белгілері мен қызметтік өрістері бар жауаптар.
Мұндай кейстерде мәтіннің қаншалықты әдемі жазылғанын емес, жауапты бірден жүйеге жіберуге бола ма, соны бағалаңыз. Қатаңдау стилі бар модель жиі ұтады, өйткені ол pipeline-ды сирек бұзады.
Сирек кейстерді де бөлек ұстаңыз. Олар аз, бірақ қате құны жоғары. Банк үшін бұл — даулы транзакция, клиника үшін — шағымдағы қызыл жалау, ритейл үшін — заңи тәуекелі бар қайтарым. Оларды кәдімгі ағынмен араластырсаңыз, орташа баллда еріп кетеді.
Жұптық салыстыру әр топ бір ғана анық сұраққа жауап бергенде жақсы жұмыс істейді: кім диалогты жақсы жүргізеді, кім өрістерді дәлірек шығарады, кім ұзақ контекстті ұстай алады, кім форматты бұзбайды. Осындай бөлуден кейін жеңіс пен жеңіліс матрицасы нақты сөйлей бастайды.
Тексеру үшін тапсырмалар жиынын қалай жинау керек
Жақсы тапсырмалар жиыны модельдің күнде жұмыста көретін нәрсесіне ұқсауы керек. Тек ойдан шығарылған мысалдарды алсаңыз, салыстыру тез басқа жаққа ауып кетеді: бір модель оқу сияқты сұрауларға әдемі жауап береді, бірақ пайдаланушылардың шынайы формулировкаларында сүрінеді.
Алдымен өнімнен, қолдаудан және ішкі прогондардан нақты сұрауларды жинаңыз. Жүз біркелкі фразадан гөрі бірнеше көзден алынған қысқа кесінді жақсырақ. Егер команда трафикті API-шлюз арқылы өткізіп жүрсе, тест ойлап табудан гөрі пилоттан анонимдендірілген сұрауларды шығарып алған пайдалы.
Сосын жиынды тазалаңыз. Жеке деректерді, клиент атауларын, шот нөмірлерін, телефондарды және тест ортасында көрсетуге болмайтынның бәрін алып тастаңыз. Одан кейін қайталанатындарын жойыңыз. Құпиясөзді өзгерту туралы он бірдей сұрақ жаңа ақпарат бермейді, бірақ қорытындыны қатты бұрмалайды.
Жиынды үш топқа бөлген дұрыс: жеңіл, орташа және шекаралық мысалдар. Жеңіл тапсырмаларда әдетте қысқа сұрақ пен аз контекст болады. Орташада бірнеше шарт, кесте, диалог бөлігі немесе ереже пайда болады. Шекаралықта — ұзын енгізу, шу, қайшылықтар, сирек формат немесе тілдердің араласуы.
Мұндай қоспа модельдер арасындағы айырмашылықты тез көрсетеді. Бірі жеңіл тапсырмаларда тұрақты деңгей ұстайды, екіншісі ұзын контекстті жақсырақ тартады, үшіншісі сирек жағдайларда жиірек қателеседі. Орташа балл мұның бәрін тегістеп жібереді.
Әр тапсырма үшін алдын ала жақсы жауап нені білдіретінін жазыңыз. Егер тапсырма нақты болса, күтілетін нәтижені көрсетіңіз. Егер ашық тапсырма болса, қарапайым тексеру ережелерін қойыңыз: модель факті ойлап таппайды, форматты сақтайды, маңызды шартты өткізіп жібермейді, артық дерек ашпайды. Әйтпесе талқылау модельдер туралы емес, тексерушілердің талғамы туралы кетеді.
Тағы бір маңызды нәрсе: топтардың көлеміне қараңыз. Егер сізде 60 жеңіл сұрау және 5 шекаралық мысал болса, қорытынды ыңғайлы көрінгенімен, әлсіз болады. Жалпы жиынды кішірейтсеңіз де, дұрыс қамтуды сақтаған жақсы. Практикада әр топта 15-20 мысал жеткілікті болып жатады, кейін модельдер тең түсе беретін немесе жиі орын ауыстыратын аймақтарды кеңейтуге болады.
Жұптық салыстыруды қадамдап қалай өткізу керек
Жұптық салыстырудың тиімді болуы үшін оның мақсаты анық болуы керек. Алдымен модель өнімде күнде не істейтінін жазыңыз: клиентке жауап жазады, құжаттан өрістерді толтырады, тонды тексереді, ұзын мәтіннен факт іздейді. Мақсат бұлыңғыр болса, қорытынды да бұлыңғыр болады.
Сосын жұмысты тапсырма түрлеріне бөліңіз. Әр түр үшін бөлек мысалдар жиынын жинаңыз, әдетте 30-дан 100-ге дейін. 30-дан аз болса, көбіне шу көп болады; 100-ден көп болу әрдайым керек емес. Егер сізде өтініштерді классификациялау, білім базасынан іздеу және қысқа түйіндеме болса, бәрін бір жерге араластырмай, бөлек тестілеңіз.
Екі модель үшін бір прогон
A мен B бірдей жағдайларда өтуі керек. Бірдей prompt, бірдей system message, бірдей параметрлер, бірдей жауап форматы. Егер бір модельде temperature 0.2, ал екіншісінде 0.8 болса, сіз модельдерді емес, баптауларды салыстырып жатырсыз.
Бүкіл тест жиынын алдын ала сақтап, оны пакетпен жүргізу ыңғайлы. Егер команда AI Router арқылы жұмыс істесе, әртүрлі модельдерді бір OpenAI-үйлесімді endpoint арқылы тез өткізіп, қалған қаптаманы өзгертпей-ақ қояды. Бұл ұсақ нәрсе сияқты, бірақ артық қателерді азайтады.
Содан кейін жауаптарды жұптап салыстырыңыз. Әр мысалға үш нәтиженің бірін қойыңыз:
- A жеңеді;
- тең;
- B жеңеді.
Мүмкін болса, модель атауын жасырған дұрыс. Әйтпесе адамдар таныс брендке бейсаналы түрде бүйірлеп кетеді. Егер тапсырма формалды болса, мысалы шарт нөмірін немесе соманы шығару, жеңіс ережесін алдын ала жазыңыз. Егер тапсырма ашық болса, мысалы клиентке жауап жазу, бағалаушыларға қысқа шкала беріңіз: дәлдік, толықтық, артық мәтін, қате тәуекелі.
Одан кейін нәтижені тапсырма топтары бойынша есептеңіз. Бір ғана қорытынды сан пайдалы суретті жасырып қалады. Мүмкін, A ақпарат алуда жиі жеңер, ал B түсінікті жауаптарды жақсырақ жазар. Жеңістермен қатар баға мен кідірісті бірден қараңыз. Тестте 3% артық жеңіс берсе де, төрт есе баяу жауап беретін модель prod үшін жарамауы мүмкін.
Даулы жағдайларды қайтадан қолмен тексеріңіз. Пайдалы әдіс қарапайым: оларды бір күнге шегеріп, алғашқы шешімге қарамай қайта қарау. Дәл сол жерде көбіне әлсіз критерийлер, сәтсіз мысалдар және сіз бекер араластырған тапсырмалар көрінеді.
Банк қолдауы үшін мысал
Банкте әдетте бір ғана міндет емес, тұтас тізбек болады. Клиент чатқа жазады, кейін форма арқылы өтініш қалдырады, ал қызметкер ұзын ережелер мен ерекшеліктерді қарайды. Егер модельдерге бір ортақ тест беріп, бәрін орташа баллға айналдырсаңыз, сурет тым тегіс болып кетеді.
Екі модельді елестетейік. A моделі клиентпен диалог жүргізуде жақсырақ. Ол сабырлы тонды ұстайды, 6-8 хабарламадан кейін шатаспайды және клиент қалауын, карта түрін, мәселені шешудің алдыңғы әрекетін айтқанын есте сақтайды. Тірі чатта бұл бірден байқалады: клиентке детальдарды қайта айтудың қажеті жоқ, ал жауап жинақы көрінеді.
Бірақ өтініш формасында көрініс өзгереді. Мұнда ұзақ диалог жоқ, есесіне өрістер, кірістірілген мәтін және ұсақ дерек көп. B моделі көбіне шарт нөмірін, операция күнін және соманы былай деп жазылған бейберекет сипаттамадан дұрыс шығарады: «Есептен шығару 14.02 болды, шарт 4571/22, сірә, ескі карта бойынша». Ал A мұндай режимде күнді өтініш күнімен жиі шатастырады немесе бір реквизитті жоғалтады.
Айырмашылық банк ережелерінде одан да айқынырақ көрінеді. Жауап ұзын құжаттағы ескертпелерге тәуелді болғанда, A сенімдірек сөйлейді, бірақ кейде ерекшелікті өткізіп жібереді. Мысалы, ол картаны қайта шығаруға ақы жоқ деп айтып, бірақ басқа қалада шұғыл қайта шығарғандағы төлем туралы тармақты байқамауы мүмкін. B қысқалау жауап береді, бірақ ережеге тұтас көбірек кіреді және артық нәрсе ойлап табуы сирек.
Процесті бөліп қарасаңыз, сурет түсінікті болады:
- клиент чатында A біркелкі әрі сыпайы жауап береді;
- форма талдауда B фактілерді жақсырақ шығарады;
- ережелер мен регламенттерде B көбіне дәлірек;
- бір орташа баллда бұл айырмашылық дерлік көрінбейді.
Сондықтан таңдау абстрактылы «кім күшті?» деген сұраққа емес, процестегі орнына байланысты. Егер модель чаттағы бірінші сызықта тұрса, банкке A қолайлы болуы мүмкін. Егер модель өтініштерді талдап, CRM өрістерін толтырып немесе операторға регламент бойынша көмектессе, B жиі пайдалырақ.
Тапсырмалар бойынша бағалау бір орташа саннан гөрі шынайырақ нәтиже береді. Продакшен үшін керегі — жалпы жеңімпаз емес, сіздің тар жеріңізде азырақ қателесетін модель.
Қандай қателер қорытындыны жиі бұзады
Жаман қорытындының ең жиі себебі қарапайым: команда бірден бірнеше шартты өзгертіп, сосын екі модельді салыстырдық деп ойлайды. Қағаз жүзінде бұл әділ тест сияқты көрінеді, ал шын мәнінде сіз A мен B айналасындағы әртүрлі баптауларды салыстырып отырсыз.
Тест дизайнындағы қате
Бірінші бұрмалану модельдерге әртүрлі prompt жазғанда пайда болады. Біріне қысқа әрі қатаң нұсқау береді, екіншісіне мысалдары бар кеңірек нұсқа береді де, кейін жауапқа қарап модельдің сапасы туралы қорытынды жасайды. Бұл жерде сіз модельді емес, prompt авторының жұмысын тексеріп тұрсыз.
Нәтижені тең емес контекст те бұзады. Егер A моделі клиенттің толық диалогын, ережелерді, жауап шаблонын және қайта генерацияға екінші мүмкіндікті алса, ал B тек деректің бір бөлігін көріп, бірінші талпыныста жауап берсе, салыстыру бүлінген болады. Контекст ұзындығын, талпыныс санын, temperature, max tokens және retry ережелерін бекітіп қойыңыз. Егер тестті бір шлюз арқылы жүргізсеңіз, бұл параметрлерді конфиг пен логта ұстап отырған дұрыс, әйтпесе кейін модель неге кенет жақсы болып кеткенін ешкім түсінбейді.
Жеңісті түсіндірудегі қате
Тағы бір тұзақ — қатаң формат керек жерде әдемі стильді жеңіс деп санау. Витрина немесе чат жауабы үшін жағымды тон плюс болуы мүмкін. Бірақ егер тапсырма JSON, CRM өрістерін толтыру немесе өтінішті бағыттауға арналған белгілер сұраса, артық бір сөздің өзі нәтижені бұзады. Модель тірірек жазып, сонымен бірге схеманы бұзып немесе міндетті өрісті өткізіп жібергені үшін маңызды жерде ұтылуы мүмкін.
Көп команда қателіктің бағасын есептемейді. Бекер. Айталық, модель тон бойынша сәл жақсырақ, бірақ 100 жағдайдың 8-інде өтініш мәртебесін шатастырады, ал оператор түзетуге әр жолы 3 минут жұмсайды. Сонда жағымдырақ модель аптасына ондаған сағат қолмен жұмыс жейді. Бағалауға тек тесттегі жеңістерді емес, қайта түзету құнын, эскалация санын және қате әрекет тәуекелін де енгізу керек.
Соңында, жаман қорытындылар көбіне тым кішкентай таңдаудан туады. Бес сәтті мысал ештеңені дәлелдемейді. A моделі қысқа FAQ-та жеңуі мүмкін, ал B ұзын нұсқауларда, өріс шығаруда және банк саясатына қатысты жауаптарда ұтады. Сондықтан продакшенге модельді бірнеше әдемі кейс бойынша таңдауға болмайды. Ондаған не жүздеген тапсырма керек, оларды түрлерге бөліп алған жөн, әйтпесе жеңіс пен жеңіліс матрицасы кездейсоқ суретке айналады.
Модель таңдаудың алдындағы жылдам тексеріс
Іске қоспай тұрып, нашар шешімді іріктеп тастауға он минут та жеткілікті. Тек орташа баллға қарасаңыз, есепте әдемі көрініп, негізгі сұраулар ағынында әлсіз жүретін модельді таңдап қою оңай.
Қысқа фильтр көбіне бір ортақ саннан жақсырақ жұмыс істейді:
- тесттерді тапсырма топтарына бөліңіз де, ақпарат алу, суммаризация, классификация, диалог және қатаң шаблонмен жұмыс істеуді араластырмаңыз;
- қорытынды ұпайға ғана емес, әр мысалдағы жеңіс пен жеңіліске қараңыз;
- бағаны, кідірісті және ақау үлесін бөлек есептеңіз;
- даулы жауаптарды қолмен тексеріңіз;
- нәтижені жүктеменің негізгі бөлігін құрайтын басты сценариймен салыстырыңыз.
Мұндай фильтр жалған көшбасшыларды тез алып тастайды. Айталық, B моделі орташа бағамен ұтады, бірақ қысқа әрі дәл құрылымды жауаптарда ұтылады, ал сізде негізгі ағын дәл сондай сұраулардан тұрады. Онда оның бірінші орнының мәні аз.
Баға, кідіріс және ақау үлесін бөлек есептеу көбіне соңғы бағалаудан да қаттырақ шешімді өзгертеді. Қолдау қызметі үшін 1.8 және 2.4 секунд жауап айырмасы бірден сезіледі. Оған бракты жауаптардың 3-4% өсімі қосылса, команда кейін қолмен тексеруге ақша төлейді.
Даулы мысалдарды сұр аймақта қалдырмаған дұрыс. Жеңіс пен жеңіліс матрицасы оғаш көрінетін 20-30 жауапты алып, қолмен қайта қарап шығыңыз. Содан кейін модель шынымен қай жерде қателесетіні және тест қандай тапсырма түрлерін орынсыз араластырғаны анықталады.
Егер жылдам тексерістен кейін бір модель негізгі сценарийде жақсырақ болып, бюджетке сыйып, жауап форматын бұзбаса, пилот үшін осының өзі жеткілікті. Қалғанын келесі тест раундында толықтыруға болады, таңдауды апталарға созудың қажеті жоқ.
Нәтижемен кейін не істеу керек
Жұптық салыстыру сирек барлық жағдайға бір жеңімпаз береді. Тесттен кейін идеал модель іздемей, жұмысқа жарайтын шешім қабылдаған дұрыс: бір модельді негізгі ағынға қалдырып, екіншісін тұрақтырақ күшті тапсырмаларға резерв ретінде ұстау.
Продакшендә бұл әсіресе пайдалы. Бір модель типтік сұрауларға тезірек әрі арзанырақ жауап бере алады, ал екіншісі ұзақ түсіндірмені жақсырақ жазады, өрістерді дәлірек шығарады немесе даулы кейстерде сирек қателеседі. Мұндай тәсіл әдетте бір орташа санмен таңдаудан адалырақ.
Нәтижелерді командадағы кез келген адам таңдау неге дәл осылай жасалғанын түсінетіндей сақтаған жөн. Жалпы бағаға ғана сүйенбей, қысқа шешім картасын қалдырған дұрыс:
- қай модель негізгі болды, қайсысы резерв;
- оларды қандай тапсырмалар жиынында салыстырдыңыз;
- тестке қандай prompt нұсқасы мен деректер қатысты;
- әр модель қай жерде ұтады және қай жерде ұтылады;
- іске қосу үшін қандай шектеулер маңызды.
Мұндай журнал уақыт үнемдейді. Бір айдан кейін ешкім арзанырақ нұсқадан неге бас тартқанын есіне түсірмейді, егер себебі қате мысалдармен бірге жазылмаған болса.
Салыстыруды модель, prompt немесе дерек деген үш элементтің біреуі өзгерген сайын қайта өткізген дұрыс. Жүйелік хабарламаның шағын түзетулері де кей тапсырмаларда жеңімпазды өзгерте алады. Сол сияқты провайдердегі модель жаңартылғаннан кейін немесе пайдаланушылар ағыны ауысқан соң да нәтиже өзгеруі мүмкін.
Егер сезімтал деректермен жұмыс істесеңіз, талаптарды пилоттан бұрын тексеріңіз, кейін емес. Түсінікті аудит логтары, PII бүркемелеу, кілт деңгейіндегі лимиттер және қажет болса деректерді ел ішінде сақтау керек. Қазақстандағы командалар үшін мұны жауап сапасымен бірдей маңызды деп қарауға болады. AI Router-да мұндай мүмкіндіктер бар, сондықтан оны бір endpoint арқылы модель салыстыруға ғана емес, жергілікті сақтау мен бірдей қол жеткізу ережелері маңызды тексерулерге де қолдану ыңғайлы.
Жақсы тест қорытындысы қарапайым көрінеді: негізгі модель, резерв модель, ауысудың түсінікті ережелері және таңдау себебінің сақталуы. Сонда келесі релиз жаңа даудан емес, қайталанатын тексеруден басталады.