LLM-дегі tail latency: баяу 1% сұранысты қалай табуға болады
LLM-дегі tail latency көбіне ұзын промпттарда, суық модельдерде және құралдарда жасырынады. Ең баяу 1% сұранысты қалай тауып, тар жерлерді жоюға болатынын көрсетеміз.
Неге сұраныстардың аз бөлігі баяулайды
LLM-дегі tail latency-тің жағымсыз бір ерекшелігі бар: пайдаланушы орташа жауап уақытын емес, сирек болатын ұзақ кідірісті есте сақтайды. Егер 99 хабарлама 2 секундта келіп, біреуі 18 секундқа созылса, әсерді дәл сол бір жауап бұзады.
Чатта бұл әсіресе қатты сезіледі. Адам күтеді, тағы бір рет басады, терезе қатып қалды деп ойлайды немесе жай ғана кетіп қалады. Бірнеше жылдам жауаптың пайдасы жоқ, егер маңызды сұрақ кенеттен жарты минутқа «ойланып» қалса.
Орташа кідіріс есепте жақсы көрінеді, бірақ нақты тәжірибені нашар көрсетеді. Ол секірістерді тегістейді, сондықтан команда «қалыпты» санды көреді, ал қолдау баяу LLM сұраныстары туралы шағым алады.
Кідіріс құйрығы әдетте қарапайым репликаларда емес, ауыр тармақтарда көрінеді: ұзын сұраныс, үлкен контекст, сыртқы құралды шақыру, көлемді жауап. Қарбалас уақытта оған кезек қосылады, сөйтіп сол бір сценарийлер одан әрі баяулайды.
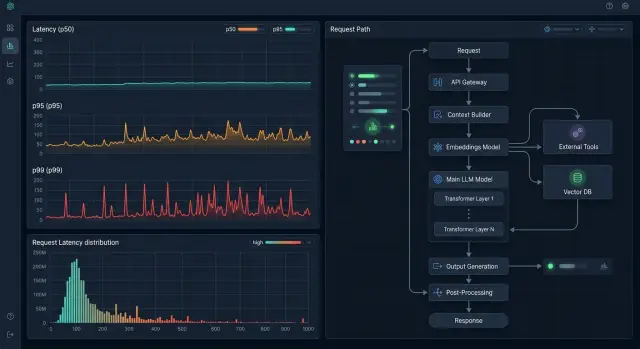
Компания бірыңғай OpenAI-үйлесімді endpoint арқылы жұмыс істесе де, аз ғана трафик ауырлау маршрутқа кетсе, жалпы көрініс тегіс болып көрінуі мүмкін. Пайдаланушы ішкі сызбаны көрмейді. Ол тек жауап тым кеш келгенін көреді.
Сондықтан p95 және p99-сыз орташа мәннің пайдасы шамалы. Сұраныс түрлері мен тәулік уақыты бойынша перцентильдерді қарамайынша, ең баяу 1% әдемі ортақ метриканың артына тығыла береді.
Кідіріс құйрығы әдетте қайда жасырынады
Көптеген LLM-қосымшаларда команда p95 пен p99-ды талдағанға дейін орташа кідіріс төзімді көрінеді. Дәл сол жерде құйрық жасырынады: бір пайдаланушы 2 секунд күтсе, екіншісі 18 секунд күтеді, ал сұраныстар сырттай ұқсас.
Жиі себеп — жүйелік промпттың шамадан тыс үлкеюі және контексттің тым көп болуы. Модель жауап бермес бұрын кірісіндегі әр токенді оқиды. Артық нұсқаулар, ұзын чат тарихы және білім базасынан алынған үлкен үзінділер бірнеше секунд қосады. Әсіресе сұраныстардың 90%-ы қысқа болып, сирек диалогтар бүкіл әңгіме архивін сүйреп жүретін жағдайлар жағымсыз.
Екінші проблема түрі мәтінге емес, модельдің күйіне байланысты. Ұзақ үзілістен кейін кейбір модельдер баяуырақ іске қосылады: контейнер оянады, GPU жүктеме алады, кэш бос болады. Пайдаланушы үшін бұл кездейсоқ ұзақ жауап сияқты көрінеді, ал код өзгермеген. Мұндай суық іске қосуды желі мәселесімен шатастыру оңай.
Уақытты көп жұтатын тағы бір нәрсе — tool calls. Іздеу, CRM, дерекқор немесе ішкі API генерацияның өзінен де ұзақ жұмыс істеуі мүмкін. LLM құралды таңдағанымен, кейін баяу SQL-ді, шамадан тыс жүктелген іздеуді немесе үзік-үзік жауап беретін сервисті күтеді. Егер тізбек бірнеше құралды кезекпен шақырса, трассаны қадам-қадамымен қарағанша кідіріс біртіндеп өсіп кетеді.
Тағы бір қарапайым себеп бар: таймауттан кейінгі қайталау. Бір сервис жауапты 5 секунд күтпей, retry жіберді. Кейін дәл солай келесі қабат та жасады. Логта модель жай ғана баяу сияқты көрінеді, ал шын мәнінде жүйе жүктемені өзі көбейтті.
Провайдер жағындағы кезек те қарбалас уақытта бөлек әңгіме. Күндіз бәрі жылдам, ал кешке сұраныстардың бір бөлігі инференс алдында күтіп қалады. Көп провайдерлі сызбада бұл әсіресе жақсы көрінеді: бір модельдің өзі бірдей промптпен әр провайдерде әртүрлі мінез көрсете алады.
Әдетте құйрықты мына бес жерден іздеген дұрыс:
- жүйелік промпт пен жалпы контексттің көлемі
- үзілістен кейінгі суық іске қосылулар
- әр
tool call-дың кідірісі - таймауттан кейінгі қайта жіберулер
- провайдердегі немесе өз шлюзіңіздегі кезек
Тек жалпы сұраныс таймеріне қарасаңыз, осының бәрі араласып кетеді. Сонда ұзын контекст, суық іске қосылу және баяу құрал бір мәселе сияқты көрінеді, бірақ оларды әртүрлі әдіспен түзетеді.
Кідірісті кезең-кезеңімен қалай бөлуге болады
Жалпы кідіріс баяу 1% сұранысты іздегенде көп көмектеспейді. 10 секундтық бір жауап ұзын промпттан, суық модельден, қайталанған сұраныстан немесе баяу құралдан кешігуі мүмкін. Мұның бәрі бір санның ішінде жатқанда, себеп көрінбейді.
Әр сұраныстың трассасын қадамдар тізбегі ретінде қараған пайдалы:
- API шлюзіне кіру және бастапқы тексеру
- модельді, провайдерді немесе маршрутты таңдау
- модельден алғашқы токенді күту
- соңғы токенге дейін жауап генерациясы
- құралдарды шақыру және нәтижені клиентке қайтару
Мұндай талдау команда бірыңғай OpenAI-үйлесімді шлюз, мысалы AI Router арқылы жұмыс істесе, әсіресе пайдалы. Онда шлюзге кіру, маршрутизация және модель жауабына кететін уақытты бөлек көруге болады, бәрін бір метрикаға қоса салмайсыз.
Токендерсіз де көрініс бұлыңғыр болады. Кіріске қанша токен келгенін және модель шығыста қанша токен бергенін журналға жазыңыз. Сонда мәселе сұраныс ұзындығында ма, әлде қысқа промпт неге әдеттегіден ұзақ күткенінде ме — көрінеді.
Құралдарды бір жолмен емес, бөлек есептеңіз. Іздеу 300 мс, сыртқы скоринг сұрауы 4 секунд болса, бұл екі түрлі оқиға. Егер агент қатарынан үш рет шақырса, әрқайсысының өз басталу уақыты, аяқталу уақыты және статусы болуы керек.
Retry, таймауттар және маршрутты ауыстыруды да анық белгілеңіз. Әйтпесе алдымен баяу бэкендке түскен, кейін басқа жолмен кеткен сұраныс кездейсоқ секіріс сияқты көрінеді. Шын мәнінде ол қазірдің өзінде басқа орындалу сценарийі.
p95 пен p99-ды тек бір сценарийдің ішінде ғана салыстырыңыз. Қолдау чатын, құжаттарды пакетпен өңдеуді және ішкі көмекшіні бір метрикаға араластырмаңыз. Тіпті бір өнімнің ішінде де сұраныстарды промпт шаблоны, модель және құралдардың болуына қарай бөлген дұрыс.
Егер сценарийдің p95-і 2 секундта тұрса, ал p99 11 секундқа секірсе, орташа мәнге емес, сирек тармақтарға қараңыз. Құйрық көбіне бір нақты кезеңде жатады: ұзын кіріс, суық іске қосылу, баяу tool call немесе жасырын retry.
Баяу 1%-ды қадам бойынша қалай ұстауға болады
Құйрықты барлық сценарийлер бойынша бірден іздеу көбіне пайдасыз. Шу тым көп. Екі кесінді алған оңайырақ: пайдаланушылар күнде іске қосатын ең жиі сценарий және уақыт немесе ақша жағынан ең қымбат сценарий.
Керегі әдемі датасет емес, адал дерек. Кемінде 1000 нақты сұранысты шығарып алыңыз да, қолмен тазаламаңыз. Ұзын диалогтарды, оғаш қайталауларды, үзіліп қалған сөздерді және сирек tool calls-тарды тастамаңыз. Дәл осындай «қоқыста» баяу сұраныстар жиі жатады.
Жұмыс тәртібі қарапайым:
- әр сұраныс үшін бірдей өрістерді жинаңыз: промпт ұзындығы, таңдалған модель, құрал шақыруларының саны, алғашқы токенге дейінгі уақыт және толық жауап уақыты
- массивті топтарға бөліңіз: қысқа және ұзын промпттар, жылдам және баяу модельдер, құралсыз және құралмен сұраныстар
- бөлек p99-ды қараңыз да, ең баяу сұраныстардың өзінде не ортақ екенін сұраңыз
- бір уақытта бір ғана себепті тұжырымдап, оны бөлек тестпен тексеріңіз
Жиі жіберілетін қате қарапайым: команда бірден модельді, токен лимиттерін және tool calls тәртібін өзгертеді. Осыдан кейін график жақсырақ көрінуі мүмкін, бірақ себеп бәрібір белгісіз болып қалады.
Кішкентай мысал. Егер p99-тағы сұраныстардың көбі 12 мың токеннен ұзын болып, олардың ішінде екі ішкі сервиске жүгіну болса, бөлек тесттерден бастаңыз: алдымен сол модельде контекстті қысқартыңыз, содан кейін сол сұраныс жиынында бір құралды өшіріп көріңіз. Сонда секундтар қай жерде кететінін тез көресіз.
Ұзын промпттар не істейді
Ұзын промпт кідірісті көбіне бірінші токенге дейінгі уақытта ұлғайтады. Модель алдымен кірісті оқиды, содан кейін ғана жауап бере бастайды. Егер сұраныс шамадан тыс үлкен болса, кідіріс генерация басталмай тұрып-ақ өседі.
Сондықтан құйрық көбіне жауаптың өзінде емес, кіріс токендерінде жасырынады. Бір сценарий 99 рет жылдам өтеді де, жүзінші сұраныста тек тым ұзын тарих кіріп кеткендіктен кідіріп қалады.
Көбіне жаңа сұрақ аз орын алады, ал ескі контекст көп орын алады. Пайдаланушы бір сөйлем жазады, ал жүйе 20 өткен репликаны, ұзын қызметтік нұсқауларды, құралдардың сипаттамасын және білім базасынан үзінділерді жібереді. Модель мұның бәрін әр жолы қайта оқиды.
Артық жүктемені әдетте бірдей нәрселер тудырады: жауап форматының ережелерін әр сұраныста қайталау, толық чат тарихын қысқа түйіннің орнына жіберу, барлық сценарийге бірдей ереже блоктарын қосу және бір қарапайым шақыру жеткілікті болса да, үлкен құралдар схемасын беру.
Мұндай артық салмақ жауапты сирек жақсартады. Ал кідіріс құйрығына бірнеше секунд оңай қосады.
Жақсы мысал — қарбалас уақыттағы банк қолдау чаты. Клиент карта неге қабылданбағанын сұрайды, ал қосымша сұраныспен бірге тек сұрақты ғана емес, бүкіл әңгімені, ескі тексерулерді, сыпайылық шаблонын, комплаенс ережелерін және бес құралдың сипаттамасын да жібереді. Жауап қысқа, бірақ модель артық мәтінді оқуға уақыт жұмсайды.
Әдетте бәрін кесіп тастау емес, контексті ретке келтіру көмектеседі. Чат тарихын бірнеше қадамнан кейін қысқа түйінге қысқартқан дұрыс. Тұрақты нұсқауларды әр жолы көшіргенше шаблонда сақтаңыз. Егер деректің бір бөлігі жауапқа әсер етпесе, оны жіберудің қажеті жоқ.
Практикада төрт шара жақсы жұмыс істейді: тек соңғы маңызды хабарларды қалдыру, ескі қадамдарды қысқа резюме ету, ережелердің қайталануын алып тастау және тек ағымдағы сұраққа қатысты құжаттарды беру. Көп жағдайда бұл LLM баяу сұраныстарын сапаны айтарлықтай жоғалтпай-ақ азайтуға жеткілікті.
Егер контекстті қысқартқаннан кейін p50 дерлік өзгермей, ал p99 айқын түссе, себеп дәл ауыр промпттарда болған.
Суық модельдер неге баяуырақ жауап береді
LLM тек ұзын промпт үшін ғана баяуламайды. Көбіне мәселе модельдің өзі «суық» болғанында: оны ұзақ уақыт шақырмаған, ал провайдер оны толық дайын күйде ұстамайды. Сонда бірінші сұраныс салмақтарды жадқа жүктеуге, GPU-ды дайындауға және бүкіл контурды іске қосуға төлейді. Пайдаланушы үшін көрініс қарапайым: кеше 2 секунд еді, ал қазір кенет 12.
Мұндай жағдай сирек модельдерде жиірек байқалады. Танымал нұсқалар әдетте жылы күйде тұрады, өйткені трафик тұрақты жүреді. Ал нишалық модель, жаңа релиз немесе fine-tuned нұсқа сағаттап бос тұруы мүмкін. Үзілістен кейінгі алғашқы шақыру көбіне ең баяуы, ал келесілері бірқалыптырақ өтеді.
Автоскейл де күн ішіндегі көріністі өзгертеді. Түнде провайдер аз инстанс ұстап, таңертең жаңаларын көтеріп, қарбалас кезде жүктемені аймақтар мен кезектер арасында қайта бөлуі мүмкін. Соның салдарынан бір сұраныс 10:00-де және 14:00-де әртүрлі мінез көрсетеді, промпт өзгермесе де.
Провайдерлер арасындағы айырма өте анық болуы мүмкін. Бір сұраныс пен бір модель бір операторда жылдам іске қосылып, екіншісінде баяу болуы мүмкін, себебі олардың жылыту және кезек саясаты әртүрлі. Егер сізде бірыңғай шлюз болса, мұндай айырмашылықтарды бірдей сұраныс жиынында салыстыру әлдеқайда оңай.
Тәжірибе қарапайым: бірінші токенге дейінгі уақытты жауаптың жалпы ұзақтығынан бөлек қараңыз, сұраныстың үзілістен кейінгі бірінші ме екенін белгілеңіз және latency-ді провайдер, модель және тәулік уақыты бойынша қадағалаңыз. Суық іске қосылулар сирек болса да, заңдылықты көру үшін көбіне осының өзі жеткілікті.
Қосымша маршрут та пайдалы. Негізгі модель тым баяу оянып жатса, жүйе сұранысты басқа бэкендке немесе сапасы жақын модельге жібере алады. Пайдаланушы ішкі ауысымды байқамайды, бірақ артық 8-15 секунд күтпейді.
Суық модель — қате де емес, графиктегі «кездейсоқ шу» да емес. Бұл инфрақұрылымның қалыпты қасиеті. Оны трасса мен маршрутизацияда ескермесеңіз, баяу 1% бәрібір түсініксіз болып көрінеді.
Құралдар секундтарды қалай қосады
Баяу жауаптың себебі жиі модельдің өзінде емес. Модель сыртқы шақыруды күтіп тұрады, ал іздеу, дерекқор немесе үшінші тарап API қайтқанша бүкіл жауап кідірісте қалады.
Құжаттар бойынша іздеу бірнеше жерде бірден уақыт алады. Сақтауға дейінгі желі жүздеген миллисекунд қосады, индекс бірқалыпты жауап бермеуі мүмкін, ал күн, рөл немесе өнім бойынша сүзгілер сұранысты ойлағаннан да ауыр етеді. Егер жүйе тым көп үзіндіні алып, кейін оларды ұзақ сұрыптаса, кідіріс бірінші токенге дейін-ақ өседі.
SQL-де жағдай одан да қаталдау. Кең таңдау, артық өрістер, үлкен кестелерді сұрыптау және дұрыс индексі жоқ join-дар 2-5 секундты оңай қосады. Команда көбіне сұраныс «жұмыс істейді» дегенге ғана қарайды, бірақ шын мәнінде ол қанша жол оқитынын тексермейді.
Бір баяу API бүкіл жауапты ұстап тұруы мүмкін. Бұл CRM, антифрод, төлем сервисі немесе ішкі каталогта болады. Егер шақырулар тізбегі кезекпен жүрсе, әр кідіріс келесісіне қосыла береді.
Әдетте мына тәсіл жылдамырақ жұмыс істейді:
- құжаттарды іздеу мен клиент профилін параллель тяну
- әр сыртқы шақыруға таймаут қою
- екінші дәрежелі құрал үлгермесе, жартылай жауап қайтару
- жиі сұралатын анықтамаларды кэштеу
Егер трафикті бірыңғай шлюз арқылы жүргізсеңіз, логтарда модель уақыты мен әр tool call уақытын бөлек көрсетіңіз. Әйтпесе модельдің өзі баяу деп ойлап, ал секундтарды сыртқы сервис жұтып тұрған болуы мүмкін.
Мұнда орташа жауап уақыты дерлік пайдасыз. Әр құрал бойынша p95 және p99-ды бөлек қараңыз. Сонда құйрық кідірісті нақты кім бұзып тұрғаны бірден көрінеді.
Себебін табуға кедергі жасайтын қателер
Орташа жауап уақыты көбіне орынсыз тыныштандырады. Егер жүйе орта есеппен 2 секундта жауап берсе, бұл пайдаланушыға бәрі жақсы деген сөз емес. Сұраныстардың бір пайызы 12-20 секундқа ілініп қалуы мүмкін, дәл солар тәжірибені бұзады.
Тағы бір жиі қате — әртүрлі сценарийлерді бір графикке құю. Чаттағы қысқа сұрақ, білім базасы бойынша іздеуі бар сұраныс және құжатты ұзақ талдау жүйеге әртүрлі жүк түсіреді. Егер оларды бір сызыққа біріктірсеңіз, «орташа температураны» ғана көріп, баяу сұраныстар пайда болатын орынды жіберіп аласыз.
Көп команда кідіріс қасына промпт көлемін сақтамайды. Сосын секірісті көріп, модель кінәлі ме, желі ме деп дауласады. Шын мәнінде себеп қарапайым болуы мүмкін. Кіріс 2 000-нан 20 000 токенге өсті, іздеу қосымша мәтін бөліктерін қосты, ал модель жауапты ұзағырақ оқи бастады және ұзағырақ генерациялады. Кіріс ұзындығы, шығыс ұзындығы және tool calls саны болмаса, көрініс дерлік соқыр.
Көбіне дұрыс емес қабатты емдейді. Команда модельді ауыстырады, температураны қысқартады және параметрлерді бұрайды, ал баяулап тұрғаны сыртқы сервис болуы мүмкін: іздеу, CRM, антифрод немесе құжаттар базасы. Егер модель тез бастап, кейін 4 секунд құрал нәтижесін күтіп тұрса, мәселе модельде емес.
Тағы бір қателік — бірнеше сәтті тест бойынша қорытынды жасау. Құйрық сирек жағдайда, тыныш уақытта бес тексеріспен ұстала қоймайды. Ол жүктеме кезінде, суық іске қосылуда, сирек ұзын промптта немесе баяу сыртқы шақыруда шығады.
Мұнда қалыпты тәртіп мынадай:
- p50, p95 және p99-ды бөлек есептеу
- сұраныстарды араластырмай, түрлері бойынша бөлу
- токендерді, контекст өлшемін және құрал шақырулар санын сақтау
- кезеңдерді бөлек өлшеу: роутинг, модель, іздеу және
tool calls
Осы деректер қатар тұрса, дауласу азаяды. Себеп көбіне бір талдауда-ақ көрінеді, апталап болжағаннан емес.
Талдауға дейінгі қысқа чек-лист
Себеп іздеуге кіріспес бұрын орташа жауап уақытына қарамаңыз. Ол көбіне тыныштандырады және көбіне алдайды. Құйрық тек нашар жағдайлар бөлек өлшенген жерде ғана көрінеді.
Негізгі нәрселерді тексеріңіз:
- сізде сервис бойынша жалпы ғана емес, әр сценарий бойынша да p95 және p99 бар: чат, суммаризация, RAG, агенттік тапсырмалар
- бірінші токенге дейінгі уақыт пен толық жауап уақыты бөлек көрінеді
- логтар промпт көлемін, шығыс токендер санын, retry мен барлық
tool calls-ты олардың ұзақтығымен бірге сақтайды - модель таймауты мен құрал таймауты бөлек бапталған
- қарапайым қосалқы маршрут бар: басқа модель, басқа провайдер немесе маңызды сұраныстарға қысқа жол
Егер бір пункт жетіспесе, талдау тез арада жорамалға тіреледі. Сіз 18 секундтық сұранысты көріп, модель кінәлі деп шешесіз. Ал кейін модель бірінші токенді 900 мс-де бергені, ал 14 секунд баяу іздеу мен құралдың қайталанған шақыруына кеткені анықталады.
Логтарда бүкіл тізбек бір экранда немесе бір сұраныста қатар тұрғаны пайдалы: кіріс, маршрутизация, модель шақыруы, құралдар, retry, қорытынды. OpenAI-үйлесімді сызбада бұл әсіресе ыңғайлы, өйткені провайдерді ауыстырсаңыз да, оқиға форматын бірдей сақтауға болады.
Тағы бір практикалық қадам: қосалқы маршрутты оқиға кезінде емес, алдын ала тексеріңіз. p99 кенет жоғарылап кетсе, сіз бір уақытта әрі мәселені жөндеп, әрі шағым легін талдағыңыз келмейді.
Мысал: қарбалас уақыттағы банк қолдау чаты
Банктің қолдау чаты күндіз бірқалыпты жұмыс істейді. Сұрақтардың көбі қарапайым: «Лимитті қайдан көремін?», «Төлем неге өтпеді?», «Нөмірді қалай ауыстырамын?» Мұндай сұраныстар 2-4 секундқа сыяды. Бірақ кешке p99 күрт жоғарылайды, ал орташа кідіріс дерлік өзгермейді.
Мәселе диалогтың басқа түрінен шығады. Клиент ұзақ әңгімеден кейін жазады, карта, даулы операция және бұрынғы өтініштер туралы мәлімет жібереді. Модель орасан контекст алады, тарихты оқуға көбірек уақыт жұмсайды және жауапты кеш бастайды. Құйрық осылай маскировкаға түседі: чаттың 99%-ы қалыпты көрінеді, ал сирек ауыр сұраныс SLA-ны бұзады.
Бұл сценарийде екінші тежегіш те бар. Бот карта статусын тексеруі керек болса, ол банктің ішкі сервисіне жүгінеді. LLM өзі тез жауап береді, бірақ ескі API кейде сұранысты 6-8 секунд ұстап қалады. Пайдаланушы бір жалпы жауапты көреді де, кешігуді мәтін емес, сыртқы құрал бергенін түсінбейді.
Команда әдетте құйрықтың бір бөлігін екі қарапайым шарамен азайтады. Алдымен тарихты қысады: толық журналдың орнына соңғы репликаларды, клиент жайлы фактілерді және ескі диалогтың қысқа түйінін қалдырады. Сосын комиссия, лимиттер және картаны қайта шығару сияқты жиі анықтамалық жауаптарды кэшке жазады. Бұл бәрін емдемейді, бірақ ұзақ сұраныстардың елеулі бөлігін азайтады.
Егер кешкі жүктеме өсіп, негізгі модельдің жауап уақыты нашарласа, қосалқы маршрут көмектеседі. Сұраныстардың бір бөлігін сапасы ұқсас, бірақ кідірісі тұрақтырақ басқа модельге жіберуге болады. Жауап стилі сәл қарапайымырақ шықса да, чат SLA шегінде қалады, ал кезек үлкеймейді.
Осындай мысалда қарапайым ереже көрінеді: «баяу чат» іздемеңіз, сирек факторлар қосындысын іздеңіз — ұзын контекст, сыртқы шақыру және шамадан тыс жүктелген не суық модель.
Әрі қарай не істеу керек
Бүкіл платформаны бірден жөндемеңіз. Адамдарға тікелей әсер ететін бір сценарийді алыңыз: қолдау чаты, білім базасынан іздеу немесе операторларға арналған ішкі көмекші. Нақты сұраныстардың шағын жиынтығын жинаңыз, кемінде 100-200 дана, және тек соны жүргізіңіз.
Сосын құйрықтың ең айқын көздерін алып тастаңыз. Көп жағдайда кідіріс модельдің өзінен емес, артық контексттен және кейде 3-5 секундқа ілініп қалатын бір баяу tool call-дан өседі. Егер жауап жүйелік промпттың, ұзын тарихтың немесе сыртқы қадамның бір бөлігінсіз өзгермесе, оны өкінішсіз алып тастаңыз.
Келесіде маршруттарды салыстыруға болады. Бірдей сұраныс жиыны қымбатырақ модельдің ұзақ тапсырмаларда тезірек жауап беретінін, ал қарапайым модель қысқа тапсырмаларда ұтатынын көрсетуі мүмкін. Мұндай қорытынды тек бірдей жүктемеде, production-дағы ортақ орташа көрсеткіштен емес, шығады.
Осындай тесттер үшін бірыңғай OpenAI-үйлесімді endpoint қажет болса, AI Router-ды airouter.kz арқылы қолдану ыңғайлы. Ол SDK, код және промпттарды өзгертпей, сұраныстарды бір API арқылы жүргізуге мүмкіндік береді, ал data residency мен жергілікті кідіріс талаптары бар командалар үшін онда open-weight модельдерді Қазақстанда орналастыру да бар. Бұл маршруттарды бір сұраныс жиынында салыстыруды жеңілдетеді.
Ең маңыздысы — орташа кідірісті емес, нақты сұраныстың қадамдар бойынша жүрген жолын өлшеу. Сонда ең жағымсыз 1% жұмбақ болып қалмайды.
Жиі қойылатын сұрақтар
LLM-дегі tail latency деген не, қарапайым тілмен?
Бұл — басқалардан әлдеқайда ұзақ жауап беретін сирек сұраныстар. Пайдаланушы көбіне орташа уақытты емес, дәл соларды есте сақтайды. Егер сұраныстардың көбі 2 секундта келіп, ал бір бөлігі 12–18 секундқа созылса, мәселе осы құйрықта.
Неге тек орташа кідірісті қарауға болмайды?
Орташа көрсеткіш секірістерді тегістеп жібереді. Ол жүйе «қалыпты» сияқты көрінгенімен, p99 жоғарылап, кейбір адамдар тым ұзақ күтіп қалғанда да жақсы сан көрсетуі мүмкін. Чат пен агенттік сценарийлерде бұл әсіресе қауіпті: бір ұзақ жауап ондаған жылдам жауаптан да қатты әсер етеді.
Баяу 1%-ды ұстауға қандай метрикалар көмектеседі?
Алдымен әр сценарий бойынша p95 пен p99-ды қараңыз. Оған қоса бірінші токенге дейінгі уақытты, толық жауап уақытын, кіріс пен шығыс токендерінің санын және әр tool call-дың ұзақтығын қосыңыз. Осы сандар секундтардың қай жерде жоғалатынын тез көрсетеді.
Ең баяу сұраныстар әдетте қайда жасырынады?
Көбіне құйрық ұзын жүйелік промптта, созылыңқы чат тарихында, модельдің суық іске қосылуында, баяу сыртқы сервисде немесе таймауттан кейінгі retry-лерде жасырынады. Қарбалас уақытта оған провайдердегі немесе өз шлюзіңіздегі кезек те қосылады.
Модельдің өзі ме, әлде сыртқы құрал ма — қалай түсінуге болады?
Сұранысты қадамдарға бөліп, әр бөлігін бөлек өлшеңіз. Егер бірінші токен тез келіп, бірақ толық жауап ұзаққа созылса, құралдар мен сыртқы API-лерге қараңыз. Егер кідіріс бірінші токенге дейін өссе, көбіне ұзын контекст, кезек немесе суық модель кінәлі.
Егер құйрық ұзын контексттен өссе, не істеу керек?
Артықты алып тастаудан бастаңыз. Тек маңызды хабарламаларды қалдырыңыз, ескі әңгімені қысқа түйінге қысқартыңыз, бірдей ережелерді әр сұраныста қайталамаңыз және керек болмаса құжаттарды түгел тасымаңыз. Көп жағдайда бұл сапаны жоғалтпай-ақ p99-ды айтарлықтай төмендетеді.
Суық модельді қалай тануға болады?
Бірінші сұраныстың үзілістен кейін қанша уақыт алатынын әдеттегі шақырулармен салыстырыңыз. Егер үзілістен кейін алғашқы жауап күрт баяуласа, ал кейінгілері бірқалыпты жүрсе, бұл — суық іске қосылу. Продакшнда бұған басқа бэкендке немесе тұрақтырақ модельге қосалқы маршрут көмектеседі.
Retry-лердің өзі баяу сұраныстар тудыруы мүмкін бе?
Иә, бұл жиі кездеседі. Бір қабат жауап күтпей қалып, қайта жіберу жасайды, сосын келесі қабат та солай істейді де, жүйе жүктемені өзі арттырады. Айқын таймауттар қойыңыз, әр retry-ді логта белгілеңіз және қайталаулардың бірін-бірі қайталамайтынын тексеріңіз.
Нормалды талдау үшін ең аз қандай логтар керек?
Мына қарапайым жиын жеткілікті: сценарий, модель, провайдер, бірінші токенге дейінгі уақыт, толық уақыт, кіріс және шығыс токендері, tool calls саны, әр шақырудың ұзақтығы, таймауттар және retry. Егер бір OpenAI-үйлесімді шлюз қолдансаңыз, бұл форматты барлық маршрутта бірдей ұстаңыз. Сонда провайдер ауысқанда салыстыру бұзылмайды.
Жүйені қатты қайта жасамай `p99`-ды қалай түсіруге болады?
Бәрін бірден өзгертпеңіз. Бір жиі сценарийді алыңыз, 100–200 нақты сұраныс жинаңыз да, гипотезаларды кезекпен тексеріңіз: контекстті қысқартыңыз, бір tool call-ды алып тастаңыз, маршрутты ауыстырыңыз, модель мен құрал таймауттарын бөліңіз. Сол кезде құйрықты нақты не қысқартып тұрғанын, әлде тек графикті жылжытып тұрғанын тез көресіз.