LLM-сервиске backpressure: каскадты апатсыз жұмыс істеу
Backpressure LLM-сервиске жүктеме шыңдарын еңсеруге көмектеседі: кезектерді, лимиттерді және екінші кезектегі сұрауларды каскадты апатсыз қалай қысқартуды қарастырамыз.
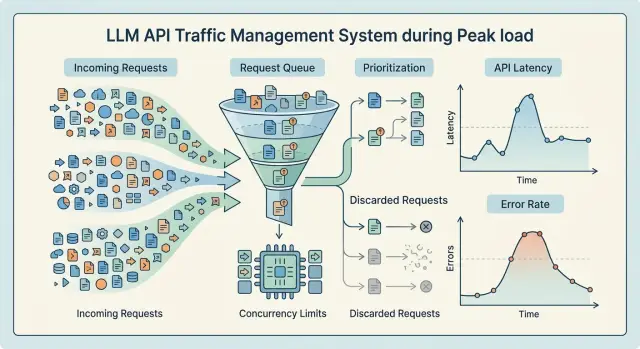
Сұраулар тасқыны кезінде не бұзылады
Трафик күрт өскенде сервис бірден 5xx қателерімен құламайды. Алдымен кідіріс өседі. Кіріс кезегі ұзартады, воркерлер ұзақырақ босамайды, қосылымдар timeout-қа дейін ілініп тұрады. Пайдаланушы әлі де жауап алады, бірақ енді 2 секундта емес, 10-15 секундта.
Бұл ең жағымсыз сәт. Сыртынан жүйе тірі сияқты көрінеді, ал ішінде қор аз-ақ қалған. Тек қателерге қарап отырсаңыз, кезек қайтадан қалыпқа келмейтін нүктені оп-оңай өткізіп аласыз.
LLM үшін бұл қалыпты көрініс. Ұзақ сұрау тек орындалу slot-ын ғана ұстамайды. Ол жадты, желіні, connection pool-ды алады, ал кейде logging, moderation және PII masking-ті де ілестіріп кетеді. Сондықтан кідіріс көзге көрінетін 5xx пайда болмай тұрып өседі.
Шыңды көбіне клиенттердің өзі үлкейтеді
Жауап баяу келгенде клиенттер retry жасай бастайды. Кейде мұны SDK істейді, кейде пайдаланушы батырманы тағы басады. Бір бастапқы сұрау екіге не үшке айналады да, жүктеме дәл жүйеге ең ауыр кезде ұлғаяды.
Әдетте тізбек былай жүреді: клиенттік timeout сервис жұмысты аяқтағанға дейін іске қосылады, клиент қайталап сұрау жібереді, ал ескі сұрау әлі өңдеуде тұрады. Кезек сервис оны тарқатып үлгергеннен жылдамырақ өседі.
Мұндай пик бір секундтағы үлкен апатқа ұқсамайды. Ол толқын сияқты келеді. Алдымен latency өседі, содан кейін жергілікті timeout-тар басталады, кейін түйіндердің бір бөлігі шамадан тыс жүктеледі, ал қайталанған сұраулар жүйенің көршілес бөліктерін де шаршатады.
Бөлек мәселе — бір баяу түйін. Егер провайдер, GPU-хост немесе воркер басқаларға қарағанда баяуырақ жауап бере бастаса, балансировка әрдайым құтқара бермейді. Оған жіберілген сұраулар ұзағырақ ілініп тұрады, slot-тарды алады, ал жалпы кезек бүкіл жолды тежейді. AI Router сияқты шлюзде бұл былай көрінуі мүмкін: модельге баратын бір маршрут баяулады, содан кейін бүкіл OpenAI-үйлесімді endpoint-тың жауап беру уақыты өсіп кетті, өйткені ортақ ресурс қорының өзі бос емес.
Каскадты апат ешқашан толық үзілу ретінде басталмайды. Көбіне бір-бірін итермелейтін ұсақ ақаулар тізбегі болады. Әуелі сервис сәл ғана баяулағандай көрінеді. Бірнеше минуттан кейін ол кезектегі істі тарқатып үлгермейді, тіпті кәдімгі трафиктің өзі шабуыл сияқты болып көріне бастайды.
Егер дәл осы сәтте кезекті қимасаңыз, параллельдікті шектемесеңіз және екіншілік сұрауларды алып тастамасаңыз, жүйе құлдырауын жалғастыра береді де, ең маңызды трафиктің өзін құлата бастайды.
Тар орын қайда пайда болады
Трафик өскенде тар орын сирек тек модельдің ішінде пайда болады. Көбіне ол бұрынырақ, кірісте пайда болады: API сұрауларды жүйе оларды тексеріп, белгілеуге, PII-ді маскалауға және орындауға жіберуге үлгергеннен жылдамырақ қабылдайды. Егер кіріс API мен орындау бір қабатта тұрса, воркерлер модельдің ұзақ жауаптарында тұрып қалады да, жаңа трафик бүкіл сервиске бірден қысым түсіреді.
Сондықтан кіріс API-ді орындау кезегінен бөлек ұстаған дұрыс. Бірінші қабат қарапайым нәрселерді тез жасайды: аутентификация, валидация, базалық лимиттер және тапсырманы кезекке жазу. Екінші қабат бос slot пайда болған сайын ғана тапсырманы алады. Сонда қысқа дүркін жалпы кептеліске айналмайды.
Келесі жиі кездесетін тар орын — модельдер мен провайдерлерге параллель шақырулар. Әр модельдің жылдамдығы бөлек, әр провайдердің квотасы мен кідірісі бөлек. Барлығына бір ортақ лимит көбіне нашар жұмыс істейді. Қысқа сұраулар ауырларын күтетін болады, ал жеңіл маршрут баяу көршісінің кесірінен қиналады. Бұл әсіресе трафиктің бір бөлігі сыртқы модельдерге, ал бір бөлігі өз GPU-ларына кеткенде анық байқалады: кезек біреу, ал бұл жолдардың шектері әртүрлі.
Көбіне ағынды аралас кезектер, нақты модельге немесе провайдерге бір мезетте жасалатын шақыруларға лимиттер, outgoing connection pool және тым ұзақ timeout-тар тежейді. Логтау, аудит-логтар, база және сақтау орны да аз проблема тудырмайды. Бұл түйіндер әдетте екінші орында сияқты көрінеді, бірақ кенет бүкіл сұрауды тежей бастайды.
Контекст ұзындығы да картинаны өзгертеді. Бір үлкен контексті сұрау он қысқа сұрауға қарағанда slot-ты ұзағырақ ұстап тұруы мүмкін. Сырттай бұл кездейсоқ төмендеу сияқты, ал себебі қарапайым: жүйе сұрауды данамен санайды, ал ресурс токен мен орындалу уақытына кетеді.
Connection pool-ды жиі бағаламай жатады. Егер ол тым шағын болса, сұраулар model call-ға дейін-ақ бос connection күтеді. Егер timeout-тар тым жомарт болса, ілініп қалған сұраулар socket пен воркерді ұзақ ұстайды. Соның салдарынан RPS қалыпты болғанның өзінде кезек өседі.
Тағы бір ұмытылатын қабат — оқиғаларды жазу. Баяу база, синхронды аудит-логтар немесе жауапты ауыр логтау модельдің өзінен де қаттырақ тежей алады. Ел ішінде деректерді сақтау, PII-ді маскалау және аудит қажет сервистерде бұл ерекше байқалады.
Жауап беру уақытына ғана емес, сұраудың бүкіл жолына қараңыз. Егер сізде AI Router сияқты шлюз болса, метрикаларды кіріс API, кезек, провайдерлерге шақырулар және қызметтік жазбалар бойынша бөліп қараған пайдалы. Сонда тар орын бірден көрінеді де, апатқа жетпей оны тоқтату оңайырақ болады.
Алдын ала қандай лимиттер қою керек
Шексіз кезек әдетте зиян келтіреді. Сыртынан сервис әлі де тұр сияқты көрінеді, ал ішінде қарыз жиналады: кідіріс өседі, жад буферлерге кетеді, воркерлер әдеттегіден ұзақ ілініп тұрады, retry қалған қорды жеп қояды. Кейде кейбір сұрауларды бірден қабылдамай тастаған дұрыс, өйткені бүкіл жүйені қинағанша солай тиімді.
Бірінші лимит — кезек ұзындығы. Оны тек сұраулар саны бойынша емес, күтілетін токен көлемі бойынша да шектеу керек. Қысқа классификация мен ұзақ генерация жүйені әртүрлі жүктейді. Егер тек тапсырма санын есептесеңіз, кезек қауіпсіз болып көрінуі мүмкін, ал шын мәнінде модельдің бүкіл pool-ы толып қалған болады.
Екінші лимит — әр маршрут бойынша in-flight сұраулар саны. Бүкіл API үшін бір ортақ шек емес, ауыр және жеңіл жолдарға бөлек шектер. Интерактив чат, embeddings және түнгі пакет өңдеу бір ғана қалған қуат үшін таласпауы керек. Бір endpoint арқылы әртүрлі модельдер мен провайдерлерге трафик жіберетін шлюзде бұл әсіресе тез байқалады: бір баяу маршрут көршілерін төмен тартады.
Timeout-тарды да кезең бойынша бөлген дұрыс. Бір 60 секундтық жалпы лимит затордың қайда басталғанын сирек түсіндіреді. Кезекте орын күтудің қысқа бюджетін, қосылу мен апстрим жауабына бөлек бюджетті, генерация немесе streaming үшін өз лимитін және post-processing пен лог жазуға тағы бір қысқа лимит қойған тиімді. Егер кезең өз бюджетінен шығып кетсе, сервис оны бірден аяқтауы керек. Әйтпесе жүктеме жасырын түрде жинала береді: клиент әлі күтіп отыр, бірақ жүйе әлдеқашан ұтылған.
Retry-ға қатаңдық керек. Жиі жасалатын қате — бір сұрауды клиент те, прокси де бірнеше рет қайталай беруіне рұқсат ету. Сонда бір ғана ақау жүктемені екі-үш еселейді. Әдетте шағын бюджет жеткілікті: қысқа идемпотентті сұрау үшін бір рет қайталау, ал модель генерацияны бастағаннан кейін ұзақ сұрауларға retry жасамау. Қиындық туғызатын бір шумды интегратордың бәрінің API жүктеме лимиттерін өртеп жібермеуі үшін, бір клиентке минутына жасалатын retry санын бөлек шектеу керек.
Приоритеттерді де анық бөліп қойған дұрыс. Тек API key бойынша емес, жұмыс түрі бойынша да. Онлайн чат, операторды тексеру және fraud scoring-ті архивацияны қысқартудан, backfill-ден немесе эксперименттерден гөрі күштірек қорғау қисынды. Бір клиенттің өзі жиі әрі шұғыл, әрі екінші кезектегі тапсырмалар жібереді. Тек токен бойынша бөлсеңіз, пайдалы трафик фондық жүктемемен бірге оңай батып кетеді.
Қалыпты бастапқы схема қарапайым: шағын кезек, қатаң in-flight лимит, кезеңдер бойынша қысқа timeout-тар, 0-1 retry және жоғары әрі төмен приоритет үшін бөлек квоталар. Мұндай жүйе жұмсақ болмайды. Бірақ ол болжамды түрде бұзылады да, көрші сервистерді ілестіріп құлатпайды.
Кезекті артық кідіріссіз қалай баптау керек
Ұзын кезек сақтандыру сияқты көрінеді, бірақ LLM-сервис үшін ол жиі жағдайды одан әрі нашарлатады. Пайдаланушы 20-30 секунд күткісі келмейді, ал жүйе оның сұрауын әлі де адал түрде жадта ұстап, орын жұмсап тұрады. Кезекті қысқа әрі тапсырма саны бойынша қатаң лимитпен ұстаған дұрыс. Егер бос орын жоқ болса, сервис жұмысты бітірмейтін уәде бермей, бірден бас тартуы керек.
Кезек қысқа дүркінді тегістеуі тиіс, жүктемені жасыруы емес. Егер сервис әдетте секундына 50 сұрауды көтерсе, мыңдаған тапсырмасы бар кезек құтқармайды. Ол тек сәтсіздікті уақыт бойынша жылжытады да, барлығына кідірісті өсіреді.
Әр тапсырманың өз дедлайны сұрау деректерінің жанында тұруы керек. Бөлек кестеде емес және тек клиент логикасында ғана емес, тікелей кезек жазбасында. Сонда воркер модельге жүгінер алдында тез тексереді: сұрау әлі керек пе, әлде мерзімі өтіп кетті ме. Мерзімі өткен тапсырмаларды модельге жүгінбей тұрып өшіру керек. Әйтпесе GPU немесе сыртқы API енді ешкімге керек емес жауапқа уақыт жұмсайды.
Кезектерді мағынасына қарай бөліңіз
Интерактив және пакет сұрауларды араластырмаған дұрыс. Чаттағы жауап, операторға кеңес немесе форманы тексеру секундтар күтеді. Құжаттарды түнгі өңдеу немесе сипаттамаларды жаппай генерациялау күте алады. Егер бәрі бір кезекке түссе, пакет жүктемесі тірі пайдаланушыға керек slot-ты оңай жұтып қояды.
Практикада кемінде екі кезек жеткілікті: интерактив сұрауларға арналған қысқа кезек және фондық тапсырмаларға арналған, лимиттері жұмсағырақ бөлек кезек. Оларға воркер лимиттері мен кезек толып кеткендегі бас тарту ережелері де бөлек болғаны дұрыс. Мұндай құрылым бақылауға да, командаға түсіндіруге де жеңіл.
Бұл әсіресе бір шлюз бір уақытта әрі пайдаланушы сценарийлеріне, әрі фондық pipeline-дарға қызмет көрсеткенде пайдалы. AI Router-де маршрутар мен жүктеме түрлері бойынша мұндай бөлу кезектің қай жерде жинала бастағанын тезірек көруге көмектеседі: кірісте ме, нақты провайдерде ме, әлде өзіңіздегі модель хостингінде ме.
Егер кезек шекке тірелсе, бірден әрі анық бас тартыңыз. Түсінікті себеппен берілген тез жауап 40 секунд күтіп, соңында сол бас тартуды алғаннан жақсы. Клиент кейін сұрауды қайта жіберуі, приоритетін төмендетуі немесе резерв сценарийіне өтуі мүмкін.
Жақсы кезек үлкен болуы міндетті емес. Ол болжамды болуы керек. Өлшемі шектелгенде, дедлайн әр тапсырмада сақталғанда және мерзімі өткен сұраулар модельге жүгінбей тұрып тазартылғанда, кідіріс тіпті пик кезінде де бақылауда қалады.
Екінші кезектегі сұрауларды қалай тастау керек
Жүктеме өскенде жүйе барлық сұрау бірдей деп көрінбеуі керек. Алдымен бизнеске аса қатты соқпайтын ағындарды бөліп алыңыз: фондық summary, "қолайлы болу үшін" жасалатын қайта генерациялар, пакет бағалаулар, шұғыл емес embeddings. Егер жауап экранда дәл қазір адамға керек болса немесе ақшаға, тәуекелге және ережелерді сақтауға әсер етсе, мұндай ағынды ең соңында ғана қимаған дұрыс.
Әдетте қарапайым ереже жеткілікті. Жоғары приоритет тікелей пайдаланушы сценарийі бар немесе кешіктіруге болмайтын шешімдерге қалады. Банк үшін бұл оператор чаты мен тәуекел тексеруі. Ритейл үшін — қолдау қызметінің жауаптары мен төлемдегі антифрод. Каталогты түнде қайта таңбалау немесе ұсыныстарды жаппай қайта есептеуді негізгі ресурс үшін таласпайтын бөлек кезекке жіберген дұрыс.
Бас тартуды екі нәрсеге байлаған жөн: приоритет пен сұраудың жасына. Төмен приоритетті кезек шектен асып кетсе, бірден қабылдамауға болады. Оған 2-5 секунд сияқты қысқа терезе беріп, содан кейін өңдеуден алып тастауға болады. Ескі екінші кезектегі сұрау көбіне жаңа шұғыл сұраудан нашар.
Клиентті іліп қоймаңыз. Егер сұрау өтпейтіні анық болса, бірден жауап беріңіз. 25 секунд күту мен соңында сол бас тарту — одан әлдеқайда жаман. API үшін әдетте "low_priority_dropped" сияқты нақты себеп пен қысқа кеңес жеткілікті: кейінірек қайталау, асинхронды режимге өту немесе сұрау көлемін азайту.
Мұнда логтар жай белгі үшін керек емес. Сұрау түрін, оның приоритетін, кезектегі жасын, күтілетін генерация көлемін, tenant немесе API key-ін және бас тарту себебін жазып отырған пайдалы. Қанша сұрау қабылданбағанын, қанша токен өңделмегенін, қай сценарийлерге әсер еткенін бөлек есептеңіз. AI Router сияқты шлюзде key бойынша rate-limit пен аудит-логтарға қарау әсіресе ыңғайлы: олар қай фондық жүктеме тірі трафикті тұншықтыра бастағанын тез көрсетеді.
Қадамдап қалай енгізу керек
Backpressure-ді кезең-кезеңімен енгізген дұрыс. Барлық қорғауды бірден қоссаңыз, апат азаяды, бірақ команда қай лимит шын мәнінде көмектескенін, ал қайсысы тек мәселені жасырғанын түсінбей қалады.
-
Базалық метрикаларды түсіріңіз. p95 және p99 кідірісін, кезек тереңдігін, in-flight сұраулар санын және қателер үлесін бақылаңыз. Деректерді маршруттар, модельдер және тапсырма түрлері бойынша бөліңіз. Орташа мән пик кезіндегі нақты көріністен көбіне әлдеқайда жақсы болып көрінеді.
-
Алдымен ең бірінші қай жер тірелетінін табыңыз. Бұл сыртқы LLM API, connection pool, GPU бар воркер немесе логтарға арналған база болуы мүмкін. Лимитті кідіріс күрт өсетін және клиенттер retry жасай бастайтын жерге қойыңыз. Егер команда бір ортақ шлюз арқылы жұмыс істесе, шектеулерді API key, модель және провайдер деңгейінде ұстау ыңғайлы.
-
Лимиттен кейін шағын кезек пен қысқа timeout-тар қосыңыз. Кезек қысқа burst-ты тегістеуі керек, минуттар бойы құйрық жинамауы керек. Егер сұрау бірнеше секунд ішінде орындала бастамаса, клиентті күтіп отырғызғаннан кейін қайта retry жасатқызғанша, қате жіберген дұрыс.
-
Содан кейін трафикті приоритет бойынша бөліңіз. Әдетте екі-үш класс жеткілікті: пайдаланушының интерактив сұраулары, фондық тапсырмалар және екінші кезектегі жаппай операциялар. Қатты жүктеме кезінде жүйе ең алдымен төмен приоритетті кесіп тастауы керек. Әйтпесе бір ауыр batch-задача чат, іздеу немесе support bot-ты оңай ығыстырады.
-
Одан кейін қатаң тест жасаңыз. Burst беріңіз, клиенттік retry-ларды қосыңыз да, кезек, кідіріс және in-flight саны қалай өсетінін қараңыз. Сосын қолмен авариялық режимді тексеріңіз: кезекші адам төмен приоритетті өшіре ала ма, лимитті қыса ала ма, немесе трафиктің бір бөлігін уақытша жылдамырақ модельге көшіре ала ма.
Продакшнға мұндай схеманы бірден бүкіл ағынға шығармаңыз. Алдымен трафиктің бір бөлігін беріп, релизге дейінгі және кейінгі метриканы салыстырыңыз, содан кейін ғана аясын кеңейтіңіз. Егер burst-тен кейін кезек тез қайтса, p99 шарықтамаса, ал екінші кезектегі сұраулар пайдаланушы сұрауларынан бұрын түсіп қалса, схема соққыны ұстап тұр деген сөз.
Кешкі пик мысалы
Банктың чат-көмекшісіндегі кешкі пикті елестетіңіз. 18:30 бен 20:00 аралығында адамдар төлемдерін, күмәнді шегерімдерді және өтінімдерінің мәртебесін тексереді. Ағын 4 есе өседі, ал жүйенің ішінде тек клиенттік диалогтар ғана емес, фондық тапсырмалар да жүреді: операторларға арналған жауап жобалары, чаттарды қысқаша мазмұндау және өтініштерді batch арқылы талдау.
Мәселе кірісте емес, worker slot-тарында басталады. Айталық, сервисте 40 slot бар. Клиенттің қысқа сұрауы 2-4 секунд алады, ал диалог тарихы үлкен немесе базадан іздейтін ұзақ сұрау 25-40 секунд ілініп тұрады. Егер осындай он-он бес сұрау қатар келсе, олар слоттардың көбін алып қояды. Тірі чат мұны бірден сезеді: кезек өседі, кідіріс секіреді, timeout-тар көбейеді.
Мұндай сценарийде приоритеттер сән үшін емес, қатаң болуы керек. Тірі клиент бірінші өтуі тиіс. Қалғанының бәрін қыса беруге болады.
Бұл практикада қалай көрінеді
Команда жүктемені үш классқа бөледі. Біріншісі — клиентке нақты уақыттағы жауаптар. Екіншісі — операторға арналған кеңестер мен қысқа ішкі қорытындылар. Үшіншісі — draft, түнгі қайта бағалаулар, пакет тапсырмалар және күте алатын басқа жұмыс түрлері.
Содан кейін қарапайым ережелер енгізіледі: тірі чат үшін 40 слоттың 24-і резервтеледі, ұзақ сұраулар бөлек pool-да ұсталады да, оларға 8 слоттан артық берілмейді, кезекте 8 секундтан асқан тапсырмалар тоқтатылады, ал провайдерден жауап 20 секундта келмесе, сұрау үзіледі. Үшінші класс кезек өскен сәтте бірінші болып тастала бастайды.
Осыдан кейін сервис бәрін бірден құтқаруға тырысуды қояды. Draft-тар сирек жауап береді, batch-задачалар жиірек бас тартады немесе қайта іске қосылады, ал чаттағы клиент пик кезінде де 3-6 секундта жауап алады.
Мұндай лимиттерге дейін жағдай әдетте бұдан да нашар болады: сұрау түрлерінің көбісі формальды түрде әлі "жұмыста", бірақ жүйе тұтас батып бара жатады. Лимиттерден кейін екінші кезектегі тапсырмалар сәттілік пайызын жоғалтады, бұл қалыпты. Есесіне негізгі сценарий құламайды.
Банк немесе ритейл үшін бұл ақылға қонымды айырбас. Пайдаланушы сервис фондық режимде операторға жауап жобасын жазып жатқандықтан немесе кешкі batch-ты жүргізіп жатқандықтан, күтіп отырмауы тиіс. Егер сервис пиктен аман өтсе және тірі диалогты сақтаса, схема жұмыс істеді деген сөз.
Жүйені тез құлататын қателер
Backpressure көбіне бір үлкен ақаудан емес, бірін-бірі күшейтетін бірнеше жаман шешімнен бұзылады. Сервис әлі ұстап тұр, кейін модель немесе провайдер сәл ғана баяулайды да, кезек өздігінен өсіп кете бастайды.
Ең жиі қате — retry-ларды әрі клиент жағында, әрі сервер жағында қосып қою. Бір сәтсіз сұрау тез арада үшке не тоғызға айналады. Егер сыртқы LLM API онсыз да баяу жауап берсе, мұндай схема қайталау дауылын тудырады да, бастапқы жүктемеден де жылдамырақ кезекті қысады. Әдетте retry-ды бір ғана жақ бақылауы керек және әрекет саны қатаң шектеулі болуы тиіс.
Бір ортақ кезек те аз зиян тигізбейді. Фондық batch-задача кенеттен тірі чатпен немесе өтінімді тексерумен бірдей ресурс үшін таласа бастайды. Нәтижесінде екінші кезектегі жұмыс адамдар дәл қазір күтіп отырған нәрсені тұншықтырады. LLM үшін ағындарды кемінде приоритет бойынша бөлу керек: интерактив сұраулар бөлек, batch бөлек.
Ұзын timeout-тар да сирек құтқарады. Команда модель үлгеріп қалар деп 60 не 120 секунд қалдырғанда, тек connection, memory және воркерлерді ұзақ ұстап отырады. Пайдаланушы бәрібір риза болмайды, ал жүйе тез қалпына келу қабілетін жоғалтады. Қысқа әрі түсінікті бас тарту көбіне үнсіз тұрып қалудан жақсырақ.
Тағы бір жаман әдет — бас тартуды нақты себеп кодынсыз бос timeout-тың артына жасыру. Онда клиент сұрауды қайталау керек пе, арзанырақ модельге ауысу керек пе, әлде пайдаланушыға жүктеме туралы хабарлама көрсету керек пе — оны түсінбейді. LLM сұраулар кезегі үшін бұл әсіресе ауыр: 429, 503 немесе "dropped_by_priority" сияқты бөлек белгі дұрыс реакция жасауға мүмкіндік береді.
Бөлек қауіп — кезек бақылаудан шығып кеткенде воркерлер санын жай ғана көбейтіп, сервисті құтқаруға тырысу. Автомасштабтау кешігеді. Жаңа воркерлер downstream әлдеқашан қызып кеткен сәтте келеді де, модельдік шлюзге, базаға, cache-ке және желіге қысымды одан әрі күшейтеді. Алдымен артық жұмыстың келуін тоқтату, төмен приоритетті алып тастау, содан кейін ғана қуатты абайлап қосу керек.
Практикада тізбек жиі былай көрінеді: провайдер әдеттегіден 4 секундқа баяу жауап береді, клиент те, сервер де қосылып retry жасайды, ортақ кезек томпайып кетеді, ұзақ timeout-тар socket-тарды ашық ұстайды, ал мониторинг тек "timeouts" деп көрсетеді. Бірнеше минуттан кейін бір функция ғана емес, бүкіл сервис құлайды.
Іске қоспай тұрып жылдам тексеру
Релиз алдында орташа жүктемені емес, жүйе әбден толған сәтті тексерген дұрыс. Дәл сол кезде каскадты апаттан қорғаныс жұмыс істей ме, әлде тек ақауды екі минутқа шегере ме — соны көруге болады.
Әуелі кезекке қараңыз. Оның ұзындығы қатаң шектелуі тиіс. Егер ол шексіз өссе, сіз сервис құтқарып жатқан жоқсыз, мәселені сәл ғана кейінге ысырып отырсыз. Сосын пайдаланушылар ұзақ timeout алады, ал воркерлер енді ешкімге керек емес тапсырмаларға жад жұмсайды.
Приоритет бойынша бөлінуді де тексеріңіз. Пайдаланушының интерактив сұрауларын пакет job-тардан, фондық қайта есептеулерден және жаппай прогондардан бөлек ұстаған жөн. Әйтпесе бір түнгі импорт бүкіл қорды жеп қойып, чат, іздеу немесе қолдауды құлатып тастайды.
Іске қосар алдында қысқа чек-парақтан өткен пайдалы:
- кезек сервер жадынан емес, қатаң лимиттен кесіледі;
- интерактив және пакет трафик әртүрлі приоритет класстарымен өтеді;
- орын жетпесе, сервис ұзақ күтпей 429 немесе 503 қайтарады;
- метрикаларда кезек тереңдігі, ең ескі тапсырманың жасы және тасталған сұраулар үлесі көрінеді;
- кезекші команда ауыр маршрутты, модельді немесе провайдерді қолмен өшіре алады.
Бас тарту мінез-құлқын бөлек тексеріңіз. 429 немесе 503 жауабы тез әрі болжамды келуі тиіс. Ең жаманы — 40 секунд бойы connection ұстап тұрып, соңында бәрібір құлайтын жүйе. Мұндайда пайдаланушы тәжірибесі тек нашарлайды, ал upstream қосымша жүктеме алады.
AI Router сияқты шлюз үшін бұл әсіресе маңызды: бір баяу провайдер немесе ауыр маршрут бүкіл қалған трафикті төмен тартып кетпеуі керек. Егер команда проблемалы бағытты қолмен өшіре алса, уақыт ұтады да, кезектің бүкіл жүйеге жайылып кетуіне жол бермейді.
Соңғы тексеру қарапайым: сервиске қалыптан жоғары, мысалы 2 есе пик беріп, үш санға қараңыз — кезек ұзындығына, тапсырмалар жасына және бірден бас тартулар үлесіне. Егер олар басқарылатын түрде өссе, ал интерактив ағын тірі қалса, конфигурация жұмысқа жақын деген сөз.
Әрі қарай не істеу керек
Backpressure-ді бірден барлық маршрутқа таратпаңыз. Бір негізгі сценарийден және бір екінші кезектегі сценарийден бастаңыз. Сонда команда кезек нақты қай жерде көмектесетінін, ал қай жерде тек жүктемені жасыратынын тезірек көреді.
Жақсы алғашқы жұп қарапайым көрінеді: онлайн пайдаланушы сұрауларын бірінші қорғайсыз, ал пакет тапсырмаларды төменірек приоритетке қоясыз немесе бірінші болып кесесіз. Мысалы, клиентпен чат соңына дейін қорғалады, ал тауар сипаттамаларын түнгі генерациялауды ауыртпалықсыз кейінге шегеруге болады.
Одан кейін команда ішінде қысқа келісім керек. Product, әзірлеу және қолдау командасы пик кезінде жүйе нені сақтауы тиіс, ал нені таңертең қолмен талдамай-ақ тастауға болатынын алдын ала шешуі керек. Алдын ала келіспесеңіз, дау дәл инцидент кезінде басталады.
Бірнеше ережені ғана бекітіп алған дұрыс: қандай сұраулар кезексіз немесе қысқа кезекпен өтеді, қандай тапсырмаларды 5-15 минутқа шегеруге болады, жүйе қуат жетпегенде бірінші нені тастайды және авариялық режимде лимиттерді кім өзгертеді.
API клиенттері үшін бөлек контракт жазыңыз. Түсінікті қате кодтары мен retry-дың айқын мінез-құлқы керек. Уақытша лимит асса, әдетте 429 жеткілікті, ал жалпы қуат жетпесе — 503. Клиент сұрауды қайталай алса, оған Retry-After беріп, сирек әрі jitter-пен retry жасауды сұраңыз. Үзіліссіз қайталау тіпті сау сервисті де тез қырады.
Егер сіз Қазақстанда LLM API құрып жатсаңыз, бүкіл контурды нөлден жинаудың әрдайым қажеті жоқ. Кейде AI Router сияқты дайын шлюзді алған оңайырақ: бір OpenAI-үйлесімді endpoint, әртүрлі провайдерлер мен модельдерге маршрутизация, key деңгейіндегі rate-limits, аудит-логтар және деректерді ел ішінде сақтау, егер data residency, төмен кідіріс немесе заң талаптары маңызды болса. Бұл сіздің приоритеттер мен лимиттер схемасын алмастырмайды, бірақ базалық инфрақұрылымның бір бөлігін алып тастайды.
Бірінші маршрут кешкі пикті тосынсыз аман өткізсе, келесісін қосыңыз. Егер кезек метрикалары, бас тартулар үлесі және жауап беру уақыты кемінде бір апта қалыпты болса, тәсілді әрі қарай кеңейтуге болады.
Жиі қойылатын сұрақтар
Неге LLM-сервис алдымен баяулап, бірден 5xx қателерімен құламайды?
Себебі шамадан тыс жүктеме көбіне алдымен жауап беру уақытына соғады. Кезек ұзартады, воркерлер ұзақырақ босамайды, қосылымдар timeout-қа дейін ілініп тұрады, ал сервис әлі жауап беріп тұрғанымен, тым баяу болады. Тек 5xx-ке қарап отырсаңыз, мәселені кеш байқайсыз.
Сұраулар тасқыны кезінде затор әдетте қай жерде басталады?
Көбіне затор модельге сұрау жіберілмей тұрып-ақ пайда болады: сұрауды тексеру, PII-ді маскалау, лог жазу немесе кезекке салу кезінде. Одан кейін оны нақты модельге, провайдерге, connection pool-ға немесе баяу базаға қойылған лимиттер күшейтеді.
Кешкі пикке деп үлкен кезек керек пе?
Жоқ, ұзын кезек көбіне зиян келтіреді. Ол шамадан тыс жүктемені жасырады, кідірісті өсіреді және қазірдің өзінде мәні жоқ тапсырмаларды жадта ұстап тұрады. Қатты лимиті бар қысқа кезек ұстаған дұрыс, ал орын болмаса, бірден бас тартқан жөн.
Фондық тапсырмалар тірі трафикті басып кетпеуі үшін не істеу керек?
Жұмыс жүктемесін кемінде екі кезекке бөліп, оларға әртүрлі worker лимиттерін беріңіз. Чат, іздеу және пайдаланушыға жауаптар бөлек жүрсін, ал batch, қысқаша мазмұндау және түнгі тапсырмалар бөлек болсын. Сонда фондық жүктеме тірі сценарийдің slot-тарын жұтып қоймайды.
LLM-сұрауларына қандай timeout қою керек?
Кезеңдерге бөліп қойған дұрыс. Кезекте күтуге қысқа мерзім беріңіз, апстриммен қосылуға бөлек мерзім қойыңыз, генерацияға өз лимитін және постөңдеуге шағын лимит беріңіз. Сонда сервис қай жерде тұрып қалғанын бірден көресіз және ілініп қалған сұрауларды тым ұзақ ұстамайсыз.
Жүйеге қауіп тудырмай, қанша retry қалдыруға болады?
Әдетте қысқа идемпотентті сұрау үшін бір рет қайталау жеткілікті, ал ұзақ генерация басталғаннан кейін нөл рет қайталау жақсырақ. Ең бастысы — клиент жағында да, сервер жағында да бір уақытта retry жасамау, әйтпесе бір ғана сәтсіздік жүктемені тез еселейді.
Сұрауды кезекте ұстамай, бірден қай кезде кері қайтарған дұрыс?
Тапсырма енді пайда әкелмейтін болса, бірден бас тартқан дұрыс. Кезек шекке жетсе, ал сұрау төмен приоритетті болса немесе оның дедлайны өтіп кетсе, бірден жауап берген жақсы. Тез бас тарту ұзақ күтіп, соңында бәрібір бас тартқаннан жақсырақ.
Backpressure жеткіліксіз екенін бірінші болып қандай метрикалар көрсетеді?
p95 және p99 кідірісіне, кезек тереңдігіне, ең ескі тапсырманың жасына, in-flight сұраулар санына және бірден бас тартулар үлесіне қараңыз. Тар жерді тез табу үшін метрикаларды маршруттар, модельдер, провайдерлер және тапсырма түрлері бойынша бөлек талдаған пайдалы.
Релиз алдында backpressure-ді қалай тексеруге болады?
Сервиске қалыптыдан жоғары жүктеме беріп, клиенттік retry-ларды қосып, кезек, тапсырма жасы және жауап беру уақыты қалай өзгеретінін қараңыз. Жақсы схема төмен приоритетті тез кесіп тастайды, интерактив трафикті тірі ұстайды және пиктен кейін жылдам қалпына келеді.
Барлығын өзіміз құрастырмай, AI Router сияқты шлюзді қашан алған дұрыс?
Егер сізге әртүрлі модельдер мен провайдерлер үшін бір OpenAI-үйлесімді endpoint, key бойынша rate-limits, аудит-логтар және деректерді ел ішінде сақтау керек болса, ол пайдалы. Бұл инфрақұрылымның бір бөлігін жеңілдетеді, бірақ приоритеттер, лимиттер және бас тарту ережелерін бәрібір бөлек баптау керек.