LLM-модельдердің бағасын есепте қателеспей қалай салыстыруға болады
LLM-модельдердің бағасын салыстырғанда тек миллион токенге шаққандағы тарифті емес, кіріс, кэш, контекст, қайталау және жауап ұзындығын да есептеңіз.
Неліктен бір миллион токенге берілген баға шатастырады
Бір миллион токенге берілген баға тек бағдар береді. Ол сіздің нақты сценарийде қанша төлейтініңізді көрсетпейді.
Бірінші тұзақ - кіріс пен шығысқа әртүрлі тариф қойылуы. Бір модельде input арзан, ал output қымбат. Екіншісінде керісінше. Егер сіздің сервисіңіз қысқа промпт жіберіп, ұзын жауап алса, тариф бетінде модельдер бір-біріне ұқсап көрінсе де, түпкі сома қатты өзгереді.
Екінші мәселе - контексттің ұзындығы. Тек миллион токенге берілген баға жауап басталғанға дейін қанша мәтін жіберетініңізді айтпайды. Чат тарихы, жүйелік нұсқаулар, мысалдар, құжаттан табылған үзінділер - осының бәрі шотқа кіреді. Білім базасы немесе ұзын келісімшарттар бар тапсырмаларда контекст көбіне жауаптың өзінен қымбатқа түседі.
Промпт кэші қарапайым салыстыруды одан сайын бұзады. Егер бірдей нұсқаулар мыңдаған сұраныста қайталанса, кірістің бір бөлігі арзанырақ тарифтелуі мүмкін. Сонда базалық ставкасы жоғары модельдің өзі ай соңында төменірек шот беруі мүмкін.
Командалар жиі ұмытып кететін тағы бір шығын бар: қате шыққаннан кейінгі қайталау. Модель JSON қайтармады, лимиттен асып кетті, жауапты үзіп тастады, сапа тексерісінен өтпеді - қосымша ретайға сұраныс жіберіледі. Әр 10-20 шақыруға бір рет артық қайта жіберудің өзі есепті байқалатындай бұзады, әсіресе контекст ұзын болса.
Сондықтан бірдей ставкасы бар екі модель бір сценарийде әртүрлі шот беруі мүмкін. Қолдау қызметінде бір модель қысқаша жауап береді, бірақ сөйлесу тарихын көбірек қажет етеді. Екіншісі аз оқиды, бірақ ұзындау жазады. Формалды түрде миллион токен бағасы бірдей. Іс жүзінде біреуі қысқа диалогтарға тиімді, ал екіншісі күрделі өтініштерге ыңғайлы болуы мүмкін.
Сол себепті тек токен бағасына қарап қою - жаман әдет. Типтік сұраныстың құнын кіріс, шығыс, кэш, контекст және қайталаулармен бірге салыстыру керек. Әйтпесе үнемдеу тек кестеде қалады.
Бір сұраныс бағасына не кіреді
Бір сұраныс сирек жағдайда ғана жай ғана кіріс пен шығыстың қосындысына тең болады. Шотта мәтіннің бірнеше қабаты бар, олардың әрқайсысы шығынға өзінше әсер етеді.
Бірінші бөлік - жаңа кіріс. Бұл пайдаланушының хабары, формадан келген жаңа деректер, құжаттың жаңа бөлігі, тапсырманың жаңа параметрлері. Мұндай токендерді провайдер әдетте input үшін толық ставкамен есептейді.
Екінші бөлік - қайталанатын мәтін. Мұнда көбіне жүйелік промпт, ұзын нұсқаулар, жауап шаблоны, чат тарихының бір бөлігі және қайта-қайта қоса беретін ортақ RAG-контекст түседі. Егер провайдер промпт кэшін қолдаса, бірдей префикс арзанырақ болуы мүмкін. Бірақ жеңілдік бүкіл сұранысқа емес, тек шынымен сәйкес келген бөлікке ғана жүреді.
Қате көбіне осы жерде кетеді. Команда тек пайдаланушының соңғы хабарын есептеп, қалған барлық «құйрықты» ұмытады. Ал модель пакетті тұтас көреді. Егер сұранысқа әр жолы 800 токендік системалық промпт, 1200 токендік тарих және база білімінен алынған тағы екі фрагмент 1500 токен қосылса, пайдаланушының қысқа сұрағы енді арзан болып көрінбейді.
Үшінші бөлік - жауап токендері. Олар да ақша тұрады, әрі көптеген модельде output input-тан қымбат. Бұл қысқа реплика емес, қорытынды, кесте, хат, SQL-сұраныс немесе өрісі көп JSON сұрағанда бірден байқалады.
Тағы бір бөлік бар, оны көбіне тым кеш еске алады: қайталаулар. Продакшнда сұраныстар таймауттан, желі қатесінен, бос жауаптан немесе форматтың бұзылуынан кейін қайта жіберіледі. Егер әр жиырма шақырудың біреуін қайталау керек болса, орташа баға шамамен 5% өседі, тіпті токен тарифтері өзгермесе де.
Сұраныстың түпкі бағасы әдетте жаңа кіріс токендерінен, кэштелген токендерден, шығыс токендерінен және қайталанған шақырулардан құралады. Контекст ұзындығын, кэш үлесін және ретрай жиілігін есептемесеңіз, нәтиже көбіне шындықтан тым оптимистік болып шығады.
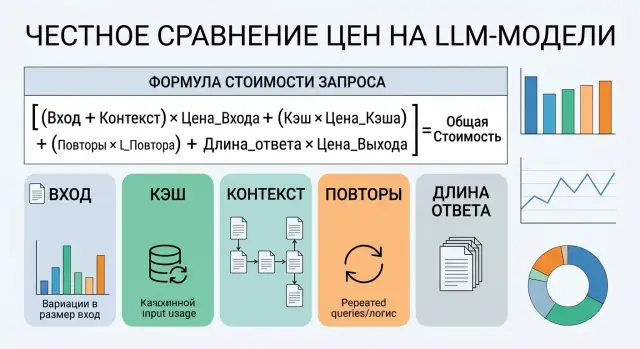
Нақты бағаны көрсететін формула
Тәжірибе үшін абстрактілі ставка емес, типтік бір сұраныстың бағасы маңызды. Мұнда контексттің бір бөлігі кэште тұрғанын, модельдер жауапты әртүрлі ұзындықта беретінін, ал кейбір шақыруларды қайталау керек болатынын ескеру қажет.
Негізгі формула мынадай:
Итог за запрос =
(новый ввод x ставка входа) +
(кэшированный контекст x ставка кэша) +
(ответ x ставка выхода)
Реальная средняя цена =
Итог за запрос x (1 + среднее число повторов)
Жаңа кіріс деп модель бірінші рет көретін токендерді санаңыз. Кэштелген контекст деп жүйелік промптты, ұзын нұсқауларды, шаблондарды және провайдер олар үшін бөлек, арзанырақ тариф алса, тарихты айтады. Жауап - модель генерациялаған барлық шығыс токендері, тіпті олардың бір бөлігі кейін пайдаланушыға жетпесе де.
Қайталаулар есептен жиі түсіп қалады, ал дәл солар түпкі нәтижені айтарлықтай өзгертеді. Егер 10% сұранысты таймаутқа, JSON валидациясына немесе нашар жауаптан кейінгі екінші әрекетке байланысты қайта жіберсеңіз, орташа қайталау саны 0.10 болады, ал көбейткіш - 1.10. Кейде бұл миллион токенге берілген бағадағы бірнеше центтік айырмашылықтан да қатты әсер етеді.
Формуланы практикада қалай оқу керек
Мысалы, сізде бір сценарий бар: 2000 жаңа токен, кэште 8000 токен, 700 жауап токені және 12% қайталау. Сіз нақты модельдің тарифтерін қоясыз да, жарнамалық баға емес, бір жұмыс шақыруының шығынын аласыз. Сосын нәтижені күндік немесе айлық көлемге көбейтесіз.
Салыстыру әділ болуы үшін шарттарды бірдей ұстаңыз: бірдей сұраныстар жиыны, бірдей жүйелік промпттар, жауап ұзындығына бірдей шектеу және қайталауды есептеудің бір тәсілі. Әйтпесе салыстыру бұзылады. Бір модель тек сіз оған қысқалау контекст бергеніңіз немесе қысқалау жауапқа рұқсат еткеніңіз үшін ғана арзан көрінуі мүмкін.
Егер команда модельдерді бірыңғай шлюз арқылы, мысалы AI Router арқылы тестілесе, мұндай есепті жасау жеңілдейді: бірдей сұраныстар жиынын әртүрлі модельдерден өткізіп, провайдер тарифтерін ғана емес, бірдей жүктемедегі нақты бағаны да салыстыруға болады.
Мұны қадам-қадамымен қалай есептеу керек
Бастауды прайстан емес, нақты сұраныстар логтарынан бастаған дұрыс. Провайдер сайты ставкаларды көрсетеді, бірақ бюджет ұзын контекст, қайталау, кэш және жауап ұзындығы арқылы жұмсалады.
Кемінде 7 күндік көшірмені алыңыз. Одан қысқа кезең жиі алдайды: оған ұзын диалогтар, жауапты қайта жасау және қатеден кейінгі бос жауаптар сияқты сирек, бірақ қымбат сценарийлер кірмей қалады.
Алдымен әр сұраныс бойынша үш сан жинаңыз: жаңа кіріс, кэштелген кіріс және жауап токендері. Егер сізде retries немесе regenerate болса, оларды бөлек белгілеңіз. Содан кейін әр шақырудың бағасын бір схема бойынша есептеңіз: жаңа кіріс x input ставкасы + кэш x cache ставкасы + жауап x output ставкасы. Егер модель ұзын контексте бағаны өзгертсе, сол ережені де қосыңыз.
Одан кейін сұраныстарды қарапайым топтарға бөліңіз: қысқа, орташа және ұзын. Тым егжей-тегжейлі жіктеу сирек көмектеседі, ал шекара туралы команда ұзақ таласады. Сосын қайталаулар мен бос жауаптардың үлесін қосыңыз. Жауап бос болса да, сіз кіріс токендері үшін, кейде қайта іске қосу үшін де төлеп қойғансыз.
Есептеуді бір шақырудың құнымен емес, әр топтағы 1000 сұраныстың бағасымен жасаған жақсы. Мұндай формат бюджеттің қайда кетіп жатқанын тез көрсетеді. Миллион токенге берілген бағасы арзан модель тірі трафикте ұтылуы мүмкін, себебі ол жауапты 1,7 есе ұзындау жазады.
Ол үшін кесте өте қарапайым болуы керек: сұраныс тобы, шақыру саны, орташа жаңа кіріс, орташа кэш, орташа жауап, қайталау үлесі, бос жауаптар үлесі және 1000 сұраныстың түпкі құны. Егер трафик AI Router арқылы өтсе, мұндай өрістерді бір жерде жинау ыңғайлы, бірақ тәсіл оның өзіне тәуелді емес.
Жұмыс сценарийіндегі мысал
Банктың қолдау чатын елестетіңіз. Ол білім базасы бойынша жауап береді: тарифтер, лимиттер, картаны бұғаттау, аударым ережелері. Жүйелік промпт аса өзгермейді, өйткені онда жауап стилі, шектеулер, PII тексерісі және заңдық ескертулер жазылған.
Әр сұраныста тек клиенттің сұрағы ғана өспейді. Диалог тарихы мен база фрагменттері де ұлғаяды. Сондықтан контекст құны прайста көрінгеннен жылдам көзге түседі.
Орташа диалог үшін мына сандарды алайық:
- Қайталанатын жүйелік блок: 1400 токен. Соның 85%-ы промпт кэші ретінде өтеді.
- Тарих пен база фрагменттері: бір шақыруға 2800 токен.
- Модель А: кіріс 1 млн токенге 0,20 доллар, кэш 0,05, шығыс 1,20. Ол орташа 850 токен жазады және жағдайдың 35%-ында нақтылау сұрайды, яғни диалогқа 1,35 шақыру кетеді.
- Модель Б: кіріс 0,45 доллар, кэш 0,10, шығыс 0,80. Ол қысқарақ жауап береді, шамамен 450 токен, әрі екінші шақыруға тек 10% жағдайда ғана барады, яғни диалогқа 1,10 шақыру кетеді.
Тек кіріс бағасына қарасаңыз, Модель А екі еседен де арзан көрінеді. Бірақ толық есеп басқаша сурет береді.
Модель А үшін бір диалогқа шамамен 4060 кэшталмайтын кіріс токені, 1600 кэштелген токен және 1150 шығыс токені кетеді. Бұл шамамен 0,00227 доллар.
Модель Б-де кіріс қымбатырақ, бірақ ол аз шығыс токенін жұмсайды және қайталау сирек керек. Орта есеппен 3310 кэшталмайтын кіріс токені, 1310 кэштелген токен және 495 шығыс токені шығады. Бұл шамамен 0,00202 доллар.
Бір чатта айырма аса білінбейді. Айына 100 мың диалогта ол анық көрінеді: шамамен 227 доллар мен 202 доллар. Егер Модель А операторды қолмен тексеріске де жиірек жіберсе, айырма одан да өседі.
Бұл мысал бір қарапайым шындықты жақсы көрсетеді: алдымен қайталанатын жүйелік блокты, содан кейін контекст құнын, одан кейін жауап ұзындығын және тек содан кейін екінші шақыру ықтималдығын есептеу керек.
Есептер көбіне қай жерде бұзылады
Әдетте бәрі тым қарапайым метрикадан басталады. Команда миллион кіріс токеніне берілген бағаны кестеге енгізіп, ең арзан модельді таңдайды. Кейін шот келеді де, ақшаны кіріс емес, шығыс жеп қойғаны анықталады.
Бұл көбіне модель көп жазатын тапсырмаларда болады: клиентке жауап беру, хат дайындау, құжат талдау. Егер бір модельдің кірісі арзан, бірақ ол орта есеппен екі есе ұзын жауап берсе, тек input бойынша салыстырудың пайдасы аз.
Екінші жиі қате - ұмыт қалған контекст. Сұраныс бағасына тек пайдаланушының сөзі емес, жүйелік промпт, диалог тарихы, шаблондар, құрал схемалары және қызметтік нұсқаулар кіреді. Егер жүйелік промпт 1200 токен тұрса және оны әр шақыруда жіберсеңіз, ол өте тез айтарлықтай шығын бабы болып кетеді.
Орташа мән де алдайды. Айталық, 10 сұраныстың 8-інде модель 150 токенмен жауап береді, ал 2 жағдайда 2500 токенге кетеді. Қағаз жүзінде орташа жауап қалыпты көрінеді, бірақ бюджетті дәл сол ұзын шеттер бұзады. Сондықтан тек орташаға емес, жоғарғы диапазонға да қарау пайдалы.
Промпт кэші де жиі қалып қояды. Егер сізде префикстің үлкен бөлігі қайталанса, мысалы бірдей жүйелік блок, тауарлар каталогы немесе тексеру шаблоны, кірістің нақты құны төмендейді. Кэшті есепке алмасаңыз, модель қымбат сияқты көрінуі мүмкін, ал тірі трафикте ол арзанырақ шығады.
Тағы бір дөрекі қате бар: командалар сценарийді ауыстырып жібереді. Бір модель қысқа сұрақтарда сыналады, екіншісі ұзын құжаттарда, сосын сандарды бірдей ағын сияқты салыстырады. Мұндайдан кейін кез келген қорытынды кездейсоқ болып шығады.
Есептің бұзылмауы үшін сценарийді, жүйелік промптты, тарих көлемін, жауап ұзындығы шегін және кэш пен қайталауды есептеу ережелерін бірдей ұстау жеткілікті. Қалғаны екінші кезекте.
Қымбат модель қашан арзанға түседі
Кіріс пен шығыс тарифінің төмен болуы ай соңында міндетті түрде арзан шот дегенді білдірмейді. Кейде бір миллион токенге бағасы жоғары модель сол жұмысты арзанға орындайды, өйткені қысқарақ жауап береді, аз қателеседі және артық қайталауды қажет етпейді.
Ең жиі жағдай - жауап ұзындығы. Бір модель 800 токен жазады, ал екіншісі 200 токенге сыйып, мағынасын жоғалтпайды. Күніне мыңдаған сұраныс болса, шығыс бағасындағы айырма тез арада арзан тарифтің пайдасын жояды.
Тағы бір жағымсыз сценарий - қайта шақыру. Егер модель JSON-ды 5-10% жағдайда бұзса, сіз тек тағы бір жауап үшін ғана төлемейсіз. Сіз нұсқауды, тарихты, мысалдарды және көбіне үлкен контекстті қайта жібересіз. Бір артық ретрай кейде ондаған сәтті сұраныстағы екі модель арасындағы тариф айырмасынан да қымбатқа түсуі мүмкін.
Модель жиі нақтылау сұрағанда да солай болады. Формалды түрде ол арзан көрінуі мүмкін, бірақ әр қосымша сұрақ диалогты созады. Қолдау қызметінде, құжат талдауда және ішкі copilot-сценарийлерде бұл бюджетке өте байқалмай соққы береді: кіріс өседі, шығыс өседі, ал кэш әрдайым көмектесе бермейді.
Ұзын контекст те бөлек әңгіме. Күштірек модель көбіне үлкен құжатты жақсы ұстайды, керек абзацты табады және жүйелік промпттағы шектеулерді жоғалтпайды. Арзан модель маңызды бөлікті өткізіп жіберуі мүмкін, содан кейін команда ұзын нұсқаулармен, ережелерді қайталаумен немесе екінші өтумен оны толықтыруға мәжбүр болады. Қағазда тариф төмен. Іс жүзінде шығын жоғары.
Кішкентай мысал: A моделі прайс бойынша екі есе арзан, бірақ орта есеппен 500 токенге көп жазады, JSON бұзылғандықтан 7% жағдайда қайта шақыруды талап етеді, жиі нақтылау сұрайды және ұзын контекстпен нашар жұмыс істейді. Мұндай сценарийде жоғары тарифі бар B моделі аяқталған тапсырмаға шаққанда арзанырақ болуы әбден мүмкін. Токен бағасын емес, артық қайталаусыз пайдалы нәтиженің бағасын есептеу керек.
Таңдау алдында қысқа тексеріс
Модельдерді салыстырмас бұрын бір қысқа бақылау тізімін жинап алған пайдалы.
Үш тарифті бөлек жазыңыз: кіріс токендеріне, кэштегі токендерге және шығыс токендеріне. Сосын толық контекстті есептеңіз: system prompt, диалог тарихы, табылған құжаттар және қызметтік нұсқаулар. Одан кейін тек орташа жауап ұзындығын емес, жоғарғы шегін де қосыңыз, сонда ұзын жауаптар орташа мән ішінде жоғалып кетпейді. Соңында қайталама шақыру үлесін міндетті түрде енгізіңіз: регенерациялар, ретрайлар, қайта сұрақтар және кэштен өтпей қалулар.
Кэшке келгенде мінсіз сценарий салмаңыз. Егер жүйелік промпт пен тарихтың бір бөлігі қайталанса, кіріс шынымен жаңа мәтінге қарағанда арзанырақ болады. Бірақ кэш сирек жағдайда 100% бірдей токендерді қамтиды. Бәрі тым әдемі болжамға емес, мысалы 60% сияқты шынайы үлеске сүйенген дұрыс.
Тағы бір қарапайым ереже: модельдерді бірдей сұраныстар жиынында салыстырыңыз. Екі сәтті мысалда емес, қысқа демода емес, нақты тапсырмалардың бірдей себетінде. Сонда ғана миллион токенге берілген бағадағы айырмашылық шудан арылып, есеп сіз шынымен не төлейтініңізді көрсете бастайды.
Әрі қарай не істеу керек
Барлық есептен кейін модельді прайстағы бір санға қарап таңдамаңыз. Кемінде бір аптаға нақты логтарды алып, салыстыруға база жинаңыз: кіріс токендері, шығыс токендері, кэшке түсу, контекст ұзындығы және сұраныстарды қайталау. Осы деректерсіз миллион токенге берілген баға әрдайым тым әдемі көрініс салады.
Трафикті бірден үш режимге бөліп алған пайдалы: қалыпты, ұзын және проблемалы. Орташа мән жиі артық шығынды жасырады. Қарапайым сұраныстарда модель арзан көрінуі мүмкін, ал ұзын құжаттарда немесе ретрайларда шот мүлде басқаша өседі.
Бағаның жанында тағы екі санды ұстаңыз: сапа және кідіріс. Әйтпесе салыстыру қайтадан жаңылады. Модель 10% арзан болуы мүмкін, бірақ 2 секундқа баяу жауап береді немесе команда кейін қолмен түзететін нәтижені жиірек береді. Онда токен үнемі жай ғана жоғалып кетеді.
Одан кейін 2-3 модельге қысқа пилот керек. Бірдей нақты тапсырмалар жиынын алыңыз: мысалы, өтініштерді жіктеу, құжатты қысқаша мазмұндау және база бойынша жауап беру. Осы жиынды кандидаттардан өткізіп, формуладағы болжамды нақты шотпен салыстырыңыз. Бірнеше жүз сұраныстан кейін-ақ есеп қай жерде тым оптимистік болғаны көрінеді.
Егер команда көптеген модельдерді бір OpenAI-үйлесімді endpoint арқылы тестілесе, AI Router провайдерлер арасында ауысқанда SDK, код және промпттарды өзгертпеуге көмектеседі. Соның арқасында барлық прогон үшін бір лог форматын және бір есептеу схемасын сақтау жеңілдейді.
7-10 күндік тексерістен кейін сізде абстрактілі миллион токен бағасы емес, өніміңіздегі жұмыс сұранысының нақты құны болады. Сол санға сүйеніп, шешімді сабырмен әрі өз-өзіңізді алдамай қабылдауға болады.
Жиі қойылатын сұрақтар
Модельдерде миллион токен бағасынан бөлек нені салыстыру керек?
Миллион токенге берілген тарифке емес, типтік сұраныстың құнына қараңыз. Жаңа кірісті, кэш ескерілген қайталанатын контексті, жауап ұзындығын және қайталама жіберулердің үлесін қосыңыз. Сонда прайстағы әдемі сан емес, нақты сценарийдегі шығын көрінеді.
Бір сұраныстың нақты бағасын қандай формула көрсетеді?
Мына схеманы алыңыз: (жаңа кіріс × input ставкасы) + (кэштегі контекст × cache ставкасы) + (жауап × output ставкасы). Егер сұраныстардың бір бөлігі ретрайға немесе регенерацияға кетсе, нәтижені (1 + орташа қайталау саны) мәніне көбейтіңіз.
Жаңа кіріс пен кэштелген контексттің айырмасы қандай?
Жаңа кіріске модель бірінші рет көретін мәтінді жатқызыңыз: пайдаланушының хабары, форманың жаңа өрістері, құжаттың жаңа бөлігі. Кэшке әдетте системалық промпт, шаблондар, тарихтың бір бөлігі және қайта-қайта жіберілетін ортақ префикс кіреді.
Неліктен ұзын контекст жалпы шотты қатты өзгертеді?
Контекст тез үлкейеді: жүйелік нұсқаулар, чат тарихы, білім базасынан алынған үзінділер және қызметтік ескертпелер сұрақпен бірге есепке кіреді. RAG немесе ұзын құжаттар бар тапсырмаларда контекст көбіне жауаптың өзінен де қымбат болады.
Ретрай, регенерация және бос жауаптарды қалай есептеу керек?
Әр сұранысқа орташа қайталау үлесін немесе бір аяқталған сценарийге шаққандағы шақыру санын қосыңыз. Егер сұраныстардың 10%-ын қайта жіберсеңіз, бағаны 1,10-ға көбейтіңіз, өйткені кіріс пен жауап үшін қайта төлейсіз.
Тарифі жоғары модель неге кейде арзанырақ болып шығады?
Ол кезде қымбатырақ модель қысқалау жауап береді, JSON-ды сирек бұзады және диалогты артық созбайды. Нәтижесінде ол шығыс токендерін аз жұмсайды және ұзын контексті қайта жіберуге сирек мәжбүрлейді.
Есептеу үшін токендердің орташа саны жеткілікті ме?
Жоқ, тек орташа мән жетпейді. Жауап пен контексттің жоғарғы шегін де тексеріңіз, әйтпесе сирек кездесетін ұзын сұраныстар қосымша шығынды жасырып, бюджет болжамын бұзады.
Бағалау үшін логтарды қандай кезеңнен алған дұрыс?
Логтарды кемінде 7 күнге алыңыз. Мұндай кезең әдетте қарапайым сұраныстарды, ұзын диалогтарды, формат қателерін және қысқа демода көрінбейтін қымбат сценарийлерді қамтиды.
Екі модельді әділ түрде қалай салыстыруға болады?
Бірдей нақты тапсырмалар жиынын екі модель арқылы өткізіп, системалық промптты, тарихты, жауап лимитін және кэш ережелерін бірдей ұстаңыз. Осы шарттардың біреуі өзгерсе, салыстырудың мәні жоғалады.
OpenAI-үйлесімді бірегей шлюз модельдерді салыстыруға көмектесе ме?
Иә, мұндай шлюз тесті жеңілдетеді, өйткені провайдерді ауыстырғанда SDK, код және промпттарды өзгертпейсіз. Мысалы, AI Router арқылы бірдей жүктемені әртүрлі модельдерден өткізіп, бағаны есептеуге арналған логтарды бір форматта жинауға болады.