Open-weight модельдерге арналған GPU: VRAM, контекст және KV-cache
Open-weight модельдерге арналған GPU-ды тек VRAM бойынша таңдауға болмайды. Контекст ұзындығы, KV-cache және параллелизм GPU есебін қалай өзгертетінін қарастырамыз.
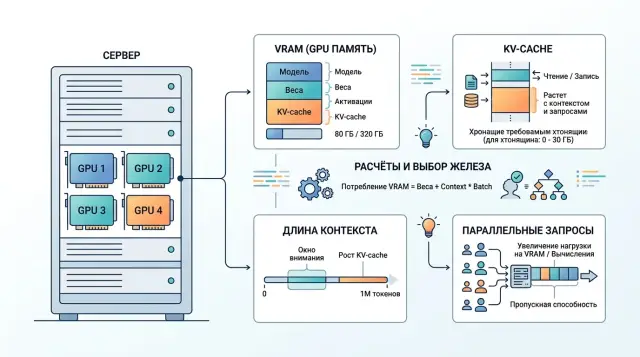
Неге бір VRAM жеткіліксіз
Open-weight модельге GPU таңдағанда, алдымен VRAM-ға қарайды. Бұл пайдалы, бірақ жеке өзі сирек дұрыс жауап береді. Модель жадқа оңай сыюы, бір сұраудағы демодан өтуі мүмкін, бірақ қарапайым трафик келгенде бәрібір баяулап қалады.
Карта жадын тек салмақтар ғана жеп қоймайды. Бір бөлігі квантизациядан кейінгі модельдің өзіне кетеді, бір бөлігі генерация барысында өсетін KV-cache-ке жұмсалады, тағы бір бөлігі қызметтік буферлерге, batching-ке және инференс қозғалтқышының жұмысына қажет. Сондықтан 80 ГБ карта әрдайым жайлы қор бермейді. Егер салмақтар VRAM-ның көп бөлігін алып қойса, ұзын диалогтар мен параллель сұрауларға орын аз қалады.
Суретті ең қатты өзгертетін нәрсе — контекст ұзындығы. 10–20 репликадан тұратын қысқа чат әдетте тыныш жұмыс істейді. Тарихы, құжаттары және system instructions бар ұзақ әңгіме, модельдің салмағы өзгермесе де, KV-cache-ті тез үлкейтеді.
Сондықтан қарапайым қорытынды мынау: GPU-ды модель сыйды ма деген принциппен емес, үш байланысты нәрсеге қарап таңдау керек — салмақтар, контекст және мақсатты кідіріс. Егер сізге алғашқы токен 1–2 секундта келіп, 20 бірдей сұрау кезінде жүйе тұрақты жұмыс істеуі керек болса, тек VRAM көлемін білу жеткіліксіз. Тірі сессияларға қанша жад қалатынын және карта кезексіз қанша токен/сек бере алатынын түсіну қажет.
Қысқа мысал. Команда 70B модельді квантталған түрде жүктеп, демо қосады да, бәрі жұмыс істеп тұрғанын көреді. Кейін оны support чатқа қосады, онда кейбір әңгімелер 30–40 хабарға дейін созылады. Кідіріс күрт өседі. Модель ауырлап кеткен жоқ. Тек KV-cache жиналды, ал параллель сұраулар жадтың қалған бөлігін алып қойды.
GPU таңдауға дейін қандай дерек жинау керек
Темір таңдаудан бұрын логтарды ашқан пайдалырақ, видеокарта каталогын емес. Есеп үшін модельдің абстракт сипаттамалары емес, адамдар сервисті шын мәнінде қалай пайдаланатыны керек.
Алдымен кіріс ұзындығын токенмен жинаңыз. Тек орташа мәнге емес, p95-ке де қараңыз. Орташа көрсеткіш оңай тыныштандырады: сұраулардың көбі қысқа, ал мәселені ұзын құйрық тудырады. Содан кейін жауап ұзындығын қарап шығыңыз. Әдетте 80 токен жазатын бот пен 600 токенге дейін жиі генерациялайтын бот жүйені мүлде басқа деңгейде жүктейді.
Келесі қадам — жүктемені уақыт бойынша көру. Қалыпты сағатта секунд сайын қанша сұрау келеді және пикте қанша? Бір сәтті күнді емес, кемінде бірнеше типтік аптаны алу жақсы. Көп командада орташа көрсеткіш тыныш көрінеді, бірақ есепті кешкі 10–15 минуттық пик бұзады.
Тағы бір жиі еленбейтін параметр — бір уақытта тірі сессиялар саны. Екі сервисте 10 RPS бірдей болуы мүмкін, бірақ GPU-ға түсетін салмақ әртүрлі. Бір жағдайда бұл қысқа, тәуелсіз сұрақтар. Екінші жағдайда — әр әңгіме тарихы KV-cache үшін жад ұстап, параллелизмді жейтін жүздеген ашық чат.
Алғашқы жұмыс кестесі үшін әдетте бес жол жеткілікті:
- кіріс ұзындығы: орташа, p95 және болса p99
- жауап ұзындығы: орташа және үлкен ауытқулар
- секундтағы сұраулар: қалыпты сағат және пик
- бір уақытта белсенді сессия саны
- алдағы айларға кемінде өсу қоры
Қарапайым мысал. Support қызметінде орташа кіріс — 700 токен, p95 — 2800, орташа жауап — 180 токен. Қалыпты уақытта сервис 4 RPS ұстайды, пикте — 11 RPS, ал бір мезетте шамамен 150 диалог белсенді. GPU-ды тек орташа сұраумен есептесеңіз, нәтиже аса оптимистік болып шығады.
Егер production логтары әлі жоқ болса, пилот деректерін алыңыз да, бірден резерв қосыңыз. Пик бойынша кемінде 20–30% қоры жоқ конфигурация әдетте команда күткеннен ертерек тар болып қалады.
Контекст есепті қалай өзгертеді
Контекст ұзындығы есепті бастан ойлағаннан да қатты өзгертеді. Модель салмағы жадта дерлік тұрақты бөлік сияқты тұрады. KV-cache токен саны өскен сайын ұлғаяды. Окно неғұрлым ұзын болса, сол бір GPU соғұрлым аз параллель сұрау көтереді.
Жеңілдетілген логика мынадай: егер 8k токендік сұрауға KV-cache үшін шамамен 2 ГБ керек болса, 32k үшін оған шамамен 8 ГБ, ал 128k үшін шамамен 32 ГБ қажет болады. Өсуі сызықтыққа жақын. Сондықтан GPU-ды тек салмаққа арналған VRAM бойынша таңдау қауіпті. Көп жағдайда тар орын дәл контекстке кететін жад болады.
Қарапайым мысал алайық. Салмақтар мен қызметтік буферлер 48 ГБ алып қойсын, ал картада барлығы 80 ГБ болсын. Тірі сұрауларға 32 ГБ қалады. Онда 8k window кезінде 2 ГБ-тан шамамен 16 сұрау ұстай аласыз. 32k-де — 8 ГБ-тан шамамен 4 сұрау. 128k-де — бір ұзын сұрау және, ең жақсы жағдайда, өте тығыз конфигурацияда тағы біреу.
Бұл әлі жұмсақ сценарий. Шынайы жүйеде контекст ешқашан тек пайдаланушының бір хабарымен шектелмейді. Жадқа system prompt, диалог тарихы, қосымшаның нұсқаулары, RAG-тен алынған құжат үзінділері және кейде таймауттан кейінгі қайта сұрау түседі. Бір retry ескі сессия әлі босамаған болса, жадқа салмақты оңай арттырады.
Сондықтан есепті орташа диалогпен емес, кемінде үш профильмен шығару керек: қалыпты сұрау, ұзын жұмыс диалогы және ұзын тарихтар, retry-лер мен параллелизмнің күрт өсуі бар нашар күн. Егер GPU тек орта сценарийден өтсе, продакшен үшін бұл жеткіліксіз.
Сондықтан практикалық ереже мынау: 128k window-ды жай ғана сақтық үшін қоспаңыз. Көбіне негізгі жүктемені 8k немесе 32k-та ұстаған арзан әрі тұрақтырақ, ал ұзын контекстті тек шынымен керек жерлерде ғана қосқан дұрыс.
Жад шығыны қайдан шығады
Инференс кезіндегі жадты үш бөлікке бөлу ыңғайлы: модель салмағы, runtime және KV-cache. Біріншісі дерлік тұрақты. Екіншісі орташа өзгереді. Үшіншісі өз ережесімен өмір сүреді және қағаздағы әдемі есепті жиі бұзады.
KV-cache модель өлшемінен емес, модель қанша токен көргенінен өседі. Әр жаңа токен барлық қабаттар үшін мәндер қосады. Сондықтан 16k токендік ұзын диалог, модель бірдей болса да, 500 токендік қысқа сұраудан әлдеқайда көп жад ұстайды.
Сессия аз кезде бұл мәселе сияқты көрінбейді. Бір ұзын сессия сирек қорқытады. Ал осындай елу сессия GPU есептеуінен бұрын жадқа тіреледі. Бұл әсіресе continuous batching кезінде қатты байқалады: сервер үнемі жаңа сұрауларды жүріп жатқан генерацияларға қосып, жадта бір уақытта көп тізбекті ұстайды.
Кванттаудағы жиі қателік те осында. Ол салмаққа кететін жадты жақсы азайтады, мысалы FP16-ден 4-bit-ке өткенде. Бірақ бұл KV-cache те сонша қысқарады деген сөз емес. Егер движок KV-cache-ті бөлек сыға алмаса, ол жиі FP16 немесе BF16 күйінде қалады. Нәтижесінде салмақтардан гигабайт үнемдейсіз, ал белсенді сессия санының шегі күткеннен әлдеқайда аз өзгереді.
Тәжірибеде бұл таныс көрінеді: кванттаудан кейін модель бір картаға сыйып, демо жұмыс істейді, бірақ трафик өскенде сервис бәрібір ұзын чаттарда OOM алады. Мәселе салмақта емес. Жадты әр белсенді диалог үшін сервер сақтап отырған токен тарихы жеп отыр.
Параллелизм мен кідірісті қалай есептеу керек
Түнгі пакеттік өңдеу мен тірі чат GPU-ды әртүрлі жүктейді. Пакеттік тапсырмада сағат ішіндегі жалпы өнімділік маңызды. Чатта маңыздысы басқа: алғашқы токен қанша секундтан кейін келеді және пикте кезек үлкейіп кетпей ме.
Сондықтан тек tokens/s жеткіліксіз. Онлайн сценарий үшін кемінде екі метрика керек: time to first token және басталғаннан кейінгі генерация жылдамдығы. Біріншісі пайдаланушы қанша күтетінін көрсетеді. Екіншісі жауап 6 секундқа созыла ма, әлде 20 секундқа ма — соны айтады.
Параллелизмді де минуттық орташа сұрау санына қарап емес, қысқа секірулермен өлшеген дұрыс. Мысалы, әдетте минутына 15 сұрау болса, push-рассылкадан кейін 20 секундта тағы 40 сұрау келуі мүмкін. Дәл осы серпін жүйенің мықтылығын тексереді. Қысқа burst кезекке төтеп береді. 10 минуттық пик SLA-ны бұзады.
Есептеу үшін бірнеше сан жеткілікті:
- сұраулардың 95%-ы үшін TTFT
- сұраулардың 95%-ы үшін толық жауап уақыты
- кіріс пен шығыс токендерінің орташа көлемі
- пик аралығындағы бір мезеттегі сұраулар саны
- SLA бұзылмай тұратын кезек ұзындығы
Осы деректер модельдің кідіріс күрт өспей тұрғанда қанша параллель сұрауды көтеретінін тез көрсетеді. Егер жаңа сұраулар жүйе алғашқы токендерді бере алғаннан тезірек келсе, стендтегі tokens/s жақсы көрінсе де, кезек өсе бастайды.
Rate limit пен тоқтатылған жауаптарды бөлек тексерген пайдалы. Кілт немесе клиент деңгейіндегі шектеу бәрін бірден қабылдауға тырысқаннан жақсырақ. Сол арқылы көпшілік үшін қалыпты кідірісті сақтайсыз. Тоқтатулар да есепке әсер етеді: егер адамдардың бір бөлігі жауапты ортасында жапса, GPU ертерек босайды да, нақты жүктеме старт алған сұрау санына қарағанда төмен болып шығады.
Өз ағыныңызға арналған кезең-кезең есеп
Бастысы карта таңдаудан емес, бір жұмыс комбинациясынан бастаған дұрыс: модель, дәлдік және мақсатты контекст ұзындығы. Бірдей 8B нұсқасы FP16, FP8 және INT4-та өте әртүрлі мінез көрсетеді. Жадты жуық бағалау үшін салмаққа кететін көлемді қарапайым есептейді: параметр саны бір салмақтың көлеміне көбейтіледі. 8B модель үшін бұл FP16-та шамамен 16 ГБ, FP8-та шамамен 8 ГБ, INT4-та шамамен 4 ГБ.
Содан кейін есеп былай жүреді.
-
Шынымен іске қосатын модельді алыңыз да, дәлдігін таңдаңыз. FP16 әдетте болжамдырақ, FP8 жақсы компромисс береді, INT4 жадты едәуір үнемдейді, бірақ күрделі тапсырмаларда сапаны төмендетуі мүмкін.
-
Салмаққа кететін жадты есептеп, үстіне бірден қызметтік шығын қосыңыз. Runtime, есептеу графы және fragmentation үшін VRAM-ның тағы 15–25% қалдырған дұрыс. Егер карта тек салмаққа әзер жетсе, продакшен үшін бұл жеткіліксіз.
-
Қажетті сессия санына KV-cache қосыңыз. Мұнда орташа емес, жұмыс пиктері маңызды. Егер бот 200 сессияны 8–12 мың токенмен ұстаса, модельдің салмағы ыңғайлы сыйып тұрса да, KV-cache басты шектеуге айналады.
-
Есепті кідіріс мақсатымен салыстырыңыз. Карта жад бойынша сәйкес келіп, бірақ throughput үшін жоғары batch-қа кетсе, жауап тым баяу болуы мүмкін. Чатта қосымша 300–700 мс-ті қолданушылар бірден байқайды.
-
Содан кейін архитектуралық нұсқаларды салыстырыңыз. Бір үлкен GPU әдетте ұзын контекст пен ауыр KV-cache үшін жақсы: бәрі бір жадта тұрады, карталар арасында артық алмасу жоқ. Екі кіші карта сұраулар тәуелсіз бөлінетін болса және жалпы throughput маңызды болса қолайлы. Бір ұзын сессия үшін мұндай схема жиі пайдасынан гөрі күрделірек.
Егер сіз AI Router сияқты шлюз арқылы жұмыс істесеңіз, бұл есеп бәрібір керек. Ол open-weight модельді қай жерде өзіңізде ұстау тиімді екенін, ал қай кезде сирек ұзын сұрауларды сыртқы маршрутқа жіберген дұрыс екенін түсінуге көмектеседі.
Қолдау чат-ботына мысал
12 жаңа сұрау/сек бар support қызметін елестетейік. Бот орташа 300 токен жауап береді және 32k window-ы бар 32B модельде жұмыс істейді. Осы деректің өзінен-ақ жүктеме ауыр екені көрінеді: тек жауап генерациясына секундына шамамен 3600 токен керек.
Жад бойынша көрініс мынадай. 8-бит форматында 32B модельдің салмағы шамамен 32 ГБ алады. Тағы бірнеше гигабайт қызметтік буферлер мен инференс қозғалтқышына кетеді. Толық 32k контекстті есептесек, мұндай модельдің KV-cache-і бір белсенді диалогқа шамамен 8 ГБ-қа дейін жетуі мүмкін.
80 ГБ H100-мен модель әдетте сыйады, бірақ мұнда жайлы қор аз. Салмақтар мен буферлер жүктелгеннен кейін KV-cache пен batching үшін шамамен 35–40 ГБ қалады. Бұл карта толық 32k window-ы бар бірнеше ғана бір мезеттегі сессияны көтере алады деген сөз. Егер бір жауап кемінде 3 секунд алса, секундына 12 сұрау кезінде жүйеде шамамен 36 белсенді сұрау жиналады. Сол сәтте жадқа да, генерация кідірісіне де тірелеміз.
Екі L40S-та сурет басқа. Қағаз жүзінде жалпы жад көбірек, бірақ ол автоматты түрде қосылмайды. 32B модель үшін көбіне tensor parallel керек, яғни карталар үнемі дерек алмасады. Жад бөлінуі жеңілдейді, бірақ кідіріс өсіп, баптау күрделене түседі. Support чат-боты үшін бұл ыңғайсыз компромисс: пайдаланушыға бірінші токен тез керек, ал карталар арасындағы алмасу көбіне дәл соған соққы береді.
Егер нақты диалогтар қысқа болса, мысалы 32k орнына 2k–4k токен болса, H100-ді пилотқа немесе шағын production-ға әлі де қарастыруға болады. Егер ұзын контекст жиі керек болса, басты сұрақ модель сыя ма деген емес, KV-cache кідіріс секірмей тұрып қанша бір мезеттегі сессияны көтере алады деген сұрақ болуы керек.
Практикалық қорытынды қарапайым: бір H100 — болжамды кідіріс профилі және эксплуатациядағы аз күрделілік керек болса, ыңғайлы негізгі түйін. Екі L40S бастапқыда арзан көрінуі мүмкін, бірақ операциялық мәселені тезірек әкеледі. Берілген ағын үшін бір машинаны емес, бірнеше репликаны немесе модель бойынша маршрутизацияны ойлаған дұрыс. Сонда 32B күрделі диалогтарға қалады, ал қысқа сұраулардың негізгі бөлігі ықшам модельге беріледі.
Қай жерде жиі қателеседі
Ең жиі қате қарапайым: команда тек салмақ көлеміне қарап, GPU таңдауы дерлік жасалды деп ойлайды. Тәжірибеде бұл тек бастамасы ғана. Жадты контекст ұзындығы, KV-cache, қызметтік токендер, batching және параллель сұраулар жейді. Модель қағазда сыйып тұрса да, кәдімгі жүктемеде кідіріс күрт секіруі мүмкін.
Екінші қате — орташа сұрау бойынша есептеу. Бұл ыңғайлы, бірақ дерлік әрқашан тым оптимистік. Егер орташа диалог 1800 токен болса, ал сессиялардың 10%-ы 8000 токенге жетсе, дәл осы құйрық жоспарды бұзады. Support, банк немесе телеком қызметі үшін мұндай сценарий қалыпты: пайдаланушы хат алмасу тарихын, келісімді жібереді, сосын нақтылау сұрайды.
Үшінші тұзақ — тек пайдаланушы мәтінін есептеу. Шынайы сұрауда system prompt, тарих, шаблондар, рөлдер, кейде RAG-тен үзінділер және қызметтік токендер болады. Нақты контекст интерфейсте көрінгеннен әрдайым ұзын.
Төртінші қате — бір потоктағы әдемі тестке сену. Ондай прогон тек алғашқы танысу үшін пайдалы. Production-та параллелизм маңызды: 8, 16 немесе 32 бірдей генерация бір идеал сұрауға мүлде ұқсамайды. Бір потокта карта керемет жылдамдық көрсетіп, ал нақты жүктемеде жад пен өткізу қабілетінің кесірінен кенет баяулауы мүмкін.
Және соңында командалар қор қалдырмайды. Бүгін сіз 4k промптқа есептейсіз, ал бір айдан кейін өнім 16k, көбірек тарих және жауапты тексерудің екінші кезеңін сұрайды. Қазірдің өзінде дәл шекарада тұрған конфигурацияға міндетті түрде қайта қарау керек болады.
Сатып алмас бұрын тексеру
Сатып алуға дейін қысқа тексеріс жасау пайдалы. Бір модель мен бір дәлдікті бекітіңіз. Орташа емес, кіріс пен шығыс үшін p95 және p99 алыңыз. Күндік орташа емес, минуттық пиктерге қараңыз. Содан кейін қажетті параллелизмге KV-cache есептеп, өсу қоры мен бір түйін істен шыққан сценарийді қосыңыз.
Тәжірибеде көбіне екі жерде қателеседі: ұзын диалогтардың ұзындығын төмен бағалайды және карта queue-сыз қанша параллель сессия көтеретінін асыра бағалайды. Мысалы, support-та әдетте минутына 30 сұрау болса, пикте — 90. Егер контекст ұзындығының 99-перцентилі орташа мәннен үш есе жоғары болса, ал жүйе бір мезетте 12–16 белсенді генерация ұстап тұрса, карта модель салмағына емес, KV-cache-ке тірелуі мүмкін. Онда кідіріс секіріп өседі, ал кезек бірнеше минутта жиналады.
Егер сіз AI Router арқылы бірнеше маршрутты қазірдің өзінде сынап жүрсеңіз, осы суреттің бір бөлігін нақты трафикте алдын ала алуға болады: сұрау ұзындығы, минуттық пиктер, ұзын диалогтардың үлесі, rate limit-тен кейінгі мінез-құлық. Қазақстан мен Орталық Азиядағы командалар үшін бұл бір OpenAI-үйлесімді endpoint арқылы бірдей сценарийлерді SDK, код және промпттарды қайта жазбай-ақ өткізуге ыңғайлы тәсіл.
Жақсы тексеріс нәтижесі жалықтыратын сияқты көрінеді, және бұл дұрыс. Сізде бір таңдалған модель, бір дәлдік, токендердің нақты перцентильдері, минуттық пик жүктемесі, KV-cache есебі, 20–30% өсу қоры және бір түйін істен шыққандағы түсінікті жоспар бар. Егер осы сандардың біреуі жоқ болса, схеманы кейін қайта жасағаннан гөрі, дерек жинауға тағы бір күн бөлген жақсы.
Есептен кейін не істеу керек
Қағаздағы есеп керек, бірақ соңғы шешімді бәрібір тірі жүктемедегі тест береді. Кесте тек бағыт көрсетеді. Стенд есептің қай жерде тым батыл болғанын тез көрсетеді: контекст ұзындығында ма, бір мезеттегі сұрау санында ма, әлде кезекте күту уақытында ма.
Нақты промпттарды немесе соған максимально ұқсас нұсқаларды алыңыз. Бір орташа сұраумен шектелмеңіз. Қысқа диалогтарды, ұзын құжаттарды, пайдаланушылар санының секіруін және кемінде бір үлкен контексті ауыр сценарийді тексеріңіз. Тест кезінде төрт метрикаға қарасаңыз жеткілікті: TTFT, басталғаннан кейінгі tokens/s, memory used және queue time. Дәл осы сандардың байланысы маңызды. Мысалы, tokens/s қалыпты көрінуі мүмкін, бірақ кешке queue time үш есе өседі. Пайдаланушы үшін бұл сәл баяу, бірақ тұрақты жауаптан да жаман.
Содан кейін екі режимді салыстырыңыз: локал хостинг және API-маршрутизация. Сезімтал деректер, ел ішіндегі төмен кідіріс немесе fine-tuned нұсқалар үшін өз контурыңыз көбіне ақталады. Сирек, ауыр немесе эксперименттік тапсырмалар үшін API арқылы бірнеше модельге қол жеткізу көп жад қоры бар темір сатып алғаннан арзанырақ болуы мүмкін.
Осындай тексеруде AI Router аралық қадам ретінде пайдалы болуы мүмкін. airouter.kz ішінде командалар бірдей сценарийлер жиынын әртүрлі frontier-модельдер мен open-weight нұсқалар арқылы api.airouter.kz-қа шығарып, үйреншікті SDK, код және промпттарды өзгертпей-ақ өткізе алады. Бұл өз GPU кластеріңізді қашан көтеру керек, ал қашан API-маршрутизация жеткілікті екенін түсінуге көмектеседі.
Егер тест қалыпты өтсе, бүкіл көлемді бірден сатып алмаңыз. Бір жұмыс жүктеме профилін алыңыз, кезек пен контекст бойынша қор қалдырыңыз, ал екі аптадан кейін жаңа деректермен өлшеуді қайталаңыз. Мұндай тәсіл әдетте идеал конфигурацияны бірінші реттен дәл табуға тырысқаннан арзанырақ.
Жиі қойылатын сұрақтар
Неге GPU-ды тек VRAM көлеміне қарап таңдауға болмайды?
Өйткені VRAM тек модельдің салмағына ғана кетпейді. Жадтың бір бөлігі KV-cache-ке, қызметтік буферлерге, batching-ке және инференс қозғалтқышының өзіне жұмсалады. Сондықтан модель демода қалыпты жұмыс істеп тұрып, тірі трафикте баяулап немесе OOM бере бастауы мүмкін.
GPU таңдауға дейін қандай деректерді жинау керек?
Алдымен нақты логтарды алыңыз. Кіріс пен шығыс ұзындығы токенмен, орташа мәндер мен p95, қалыпты сағаттағы және пиктегі жүктеме, бір уақытта белсенді сессия саны және кемінде 20–30% өсімге қор керек. Осы сандарсыз есеп көбіне тым оптимистік шығады.
Салмақтан бөлек жадқа ең көп не әсер етеді?
Ең қатты әсер ететіні — контекст ұзындығы. Модель салмағы көп өзгермейді, ал KV-cache тарихтағы токендер санына қарай өседі. Сондықтан 8k-ден 32k немесе 128k-ке өту бос жадты тез жеп, параллелизмді азайтады.
KV-cache деген не, қарапайым тілмен?
KV-cache — модель сол диалогта бұрын оқып қойған токендерді сақтайтын жад. Тарих ұзараған сайын ол көбірек орын алады. Бір ұзын сессия әдетте қорқынышты емес, бірақ ондай сессиялар көбейсе, сервер жадқа тез тіреледі.
Кванттау жад мәселесін шешеді ме?
Жоқ, толық шешпейді. Кванттау модель салмағына кететін жадты жақсы азайтады, бірақ KV-cache команда күткендей қатты кішіреймей қалуы мүмкін. Сондықтан модель картаға сиғанымен, белсенді диалог саны күткендей өспейді.
Пакеттік өңдеуге емес, чат-ботқа қандай метрикалар маңызды?
Чат үшін тек tokens/s-ке қарау жеткіліксіз. p95 сұрауларға TTFT, толық жауап уақыты, алғашқы токеннен кейінгі генерация жылдамдығы және пик кезіндегі queue time керек. Бірінші токен кешіксе, пайдаланушыға стендтегі жақсы орташа жылдамдықтың мәні аз.
128k контекстке бірден конфигурация алған дұрыс па?
Жоқ, егер міндетте ұзын диалогтар немесе үлкен құжаттар болмаса. Көбіне негізгі жүктемені 8k немесе 32k-та ұстап, ұзын контекстті тек сирек сценарийлерге қосқан тиімді. Сол кезде кідірісті бақылау да оңайырақ болады.
Ұзын контекст үшін бір үлкен GPU жақсы ма, әлде екі кіші карта ма?
Әдетте бір үлкен карта ыңғайлырақ. Ол кідірісті болжамдырақ ұстайды және GPU-лар арасында дерек алмасуға уақыт жұмсамайды. Екі карта жалпы throughput маңызды болып, сұраулар оңай бөлінетін жағдайда ғана орынды.
Қуат пен жадқа қандай қор қалдырған дұрыс?
Егер production логтары болмаса, пик сценарийдің үстіне кемінде 20–30% қор қосыңыз. Бұл өсіп жатқан жүктемені, ұзын диалогтарды және есептегі ұсақ қателерді көтеруге көмектеседі. Егер бір түйін істен шыққанда сервис құламауы керек болса, оны да бірден есепке алыңыз.
Қағаздағы есептен кейін не істеу керек?
Алдымен нақты немесе өте ұқсас промпттармен тірі тест өткізіңіз. Қысқа және ұзын диалогтарды, пайдаланушы санының күрт өсуін және үлкен контексті бар ауыр сценарийді тексеріңіз. Егер тест шекарада ғана өтсе, бірден бәрін сатып алмаңыз — бір жұмыс конфигурациясын алып, бірер аптадан кейін жаңа деректермен қайта өлшеген дұрыс.