Embedding өлшемі: іздеу мен код қай жерде бұзылады
Embedding өлшемі іздеуге, индекстерге және сақтау схемаларына әсер етеді. Кодтың қай жерде құлайтынын, сапаның қай жерде төмендейтінін және миграцияны қалай дұрыс өткізуді көрсетеміз.
Мәселе шын мәнінде қайда жатыр
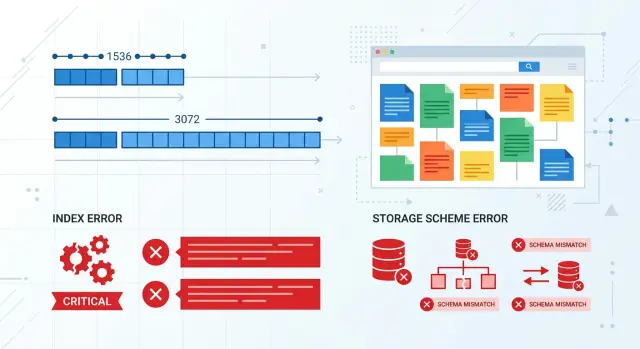
Embedding моделін ауыстыру тек іздеуді ғана бұзбайды. Көбіне ол модель, дерекқор, индекс және ұқсастықты есептейтін код арасындағы келісімді бұзады. Бәрі бір өлшеммен жұмыс істеп тұрған кезде бұл байқалмайды. Мәселе сервис 1536 сан күтіп, 3072 сан алған күні шығады.
Embedding өлшемі — ұсақ баптау емес, деректер контрагының бір бөлігі. Егер сақтау схемасы вектордың нақты ұзындығына есептелсе, жаңа жауап жай ғана сыймайды. Кейбір базалар жазу кезінде бірден қате қайтарады. Басқалары деректерді жанама түрлендіруден кейін қабылдайды, ал бұл одан да жаман: ақау тереңдеп, кейінірек білінеді.
Әдетте бұзылу төрт жолдың біреуімен жүреді:
- жаңа вектордың ұзындығы басқа болғандықтан жазу өтпейді
- векторлық индекс құрудан немесе жаңартудан бас тартады
- салыстыру сервисі similarity операциясында рантаймда құлайды
- іздеу ескі және жаңа векторларды араластырып, нәтижелердің түсініксіз ретін береді
Соңғысы ең жағымсыз. Код құламайды, дашборд жасыл, сұраулар өңделіп жатыр. Бірақ нәтиже бұзылған, өйткені векторлар арасындағы қашықтықтың мағынасы тек бір кеңістіктің ішінде ғана бар. Ескі және жаңа embedding-тер бір мәтінді әртүрлі ережемен сипаттай алады, ал оларды бір индекс ішінде араластыруға болмайды.
Каталогтан тауар іздеуді елестетіңіз. Карточкалар ескі модельмен индекстелген, ал пайдаланушылардың жаңа сұрауларын жаңа модель кодтап жатыр. Формалды түрде іздеу жұмыс істейді, бірақ адам "беспроводные наушники" деп жазғанда, жоғарыдан қаптар, адаптерлер мен кездейсоқ аксессуарлар шығып кетеді. Команда ранжировканы түзете бастайды, бірақ себебі қарапайымырақ: сұрау мен құжаттар әртүрлі векторлық кеңістікте өмір сүріп жатыр.
Мәселе жаңа модель басқа вектор қайтарғанында емес. Мәселе — вектор айналасындағы бүкіл тізбек бір ұзындық пен бір геометрияны үнсіз болжайтынында. Егер оны алдын ала тексермесеңіз, не ашық қате аласыз, не сапаның үнсіз төмендеуін көресіз. Көбіне қымбатқа түсетіні — екіншісі.
Неліктен модельді жай ғана алмастыра салуға болмайды
Embedding моделінде сандар массивінің ұзындығы ғана өзгермейді. Ол мәтіндер өмір сүретін кеңістіктің өзін өзгертеді. Құжат пен сұрау сол күйінде қалуы мүмкін, бірақ олардың бір-біріне қатысты орны енді басқаша болады.
Өлшем бірінші болып көзге түседі, өйткені кодқа тұрақты ұзындық ұнайды. Бірақ бұл тек мәселенің көрінетін бөлігі. Жаңа модель мағынаны өз осьтері бойынша басқаша бөледі: бірі заңдық және операциялық тұжырымдарды жақсы ажыратады, басқасы қысқа тұрмыстық сұрауларды ұзын нұсқаулықтарға дәлірек жақындатады.
Бірдей ұзындық та құтқармайды
Егер ескі және жаңа модельдер, мысалы, екеуі де 1536 сан қайтарса, бұл оларды үйлесімді етпейді. Сол 1536 координата мәтінді әртүрлі ережемен сипаттайды. Ескі құжат векторларын жаңа сұрау векторларымен араластыруға болмайды. Іздеу әрдайым қате беріп құламайды, бірақ баяу өтірік айта бастайды.
Бұл қарапайым мысалда көрінеді. Дерекқорда "как закрыть счет", "заморозка подозрительной операции" және "смена номера телефона" деген мақалалар бар делік. Ескі модель "закрыть карту" сұрауы бойынша бірінші мақаланы сенімді түрде топ-орынға қоятын. Модель ауысқаннан кейін дәл сол сұрау кейде операцияны тексеру туралы материалды жоғары шығарады, өйткені жаңа геометрия "закрыть", "блокировка" және "проверка" сөздерін күштірек байланыстырады.
Ұқсастық шектері де бұрынғыдай жұмыс істемей қалады. Егер бұрын құжатты cosine similarity 0.82-ден жоғары болса жарамды деп санасаңыз, миграциядан кейін бұл санның мәні азаяды. Қашықтықтардың үлестірімі өзгереді, сондықтан "ештеңе табылмады" фильтрі, дедупликация және іздеуден кейінгі rerank басқаша жүре бастайды.
Тіпті OpenAI-үйлесімді шлюзде, модельді ауыстырып, SDK-ға тимей-ақ қоя алатын жерде де, мұндай ауысу тегін болмайды. Корпусты қайта embedding-теу, векторлық индексті қайта құру және метрикаларды тірі сұрауларда тексеру керек. Әйтпесе іздеу формалды түрде жұмыс істегенімен, пайдаланушылар басқа құжаттар жиынтығын көріп жатады.
Іздеу сапасы қай жерде өзгереді
Іздеу сапасы команда күтетін жерде емес, басқа жерде жиі өзгереді. Жүйе құламауы мүмкін, индекс қате шығармай құрылуы мүмкін, ал кейбір сұраулар үшін top-10 тізімі бұрынғыдай қала береді. Дәл осы нәрсе шатастырады: ауысу тыныш өтті сияқты көрінеді, ал жаңа модель мәтіндер арасындағы жақындықты басқаша көріп үлгерген.
Бұл әсіресе қысқа сұрауларда қатты байқалады. Пайдаланушы бір-екі сөз жазғанда, модельде тірек сигналы аз болады, сондықтан вектор геометриясындағы кез келген ығысу бірден нәтижеге әсер етеді. Ұзын сұрау көбіне өзін өзі құтқарады: онда контекст көп, нақтылау көп, ал іздеу керекті құжатты табуға жеңілірек.
"лимит карты" сұрауы бұны жақсы көрсетеді. Дерекқорда тарифтер, тәуекел ережелері, FAQ және жаңалықтар жатуы мүмкін. Бір модель нақты ережесі бар бетті жоғары шығарады, екіншісі өнім туралы жалпы шолуды көтеруі мүмкін, өйткені сөздер тақырып жағынан жақын, бірақ пайдаланушы мақсатына сай емес.
Мәселе оңай байқалмайтын жерлер
Фильтрлер мен rerank көбіне сапаның төмендеуін жасырады. Егер векторлық іздеудің үстінде өнім, тіл немесе дата бойынша фильтр тұрса, ол жаман кандидаттарды байқаусызда алып тастап, нәтижені қалыпты етіп көрсетуі мүмкін. Rerank те сондай әсер береді: ол жоғарғы нәтижені түзетеді, бірақ базалық іздеу мүлде таппаған құжаттарды қайтара алмайды.
Сондықтан команда алғашқы үш жауапқа қарап, бәрі дұрыс деп ойлайды. Бірақ recall төмендеп кеткен, ал онымен бірге күрделі жағдайларда дұрыс құжатты табу ықтималдығы да азаяды.
Көптілді коллекциялар одан да қатты әсер алады. Егер база орыс, қазақ және ағылшын тілдерін араластырса, модель ауысуы тілдер арасындағы қашықтықты күрт өзгерте алады. Кеше орысша сұрау қазақша құжатты сенімді тауып тұрса, бүгін сол құжат төменге түсіп кетеді, ал мағынасы өзгермеген болады.
Ескі chunking те қосымша шу енгізеді. Егер бұрын мәтінді тым ірі, тым ұсақ немесе ойдың дәл ортасынан бөлген болсаңыз, ескі модель мұны көтере алатын. Жаңа embedding-тер мұндай бөліктерді кейде кешіре бермейді, ал мәселе іздеу сапасының ауысуындай көрінеді, шын мәнінде қиындықтың бір бөлігі деректер дайындауда жатыр.
Сондықтан модельді, индексті және мәтінді бөлу схемасын бірден ауыстыру қауіпті. Кейін қайсысы іздеуді бұзғанын түсіну қиын болады. Тәжірибеде бір ғана параметр емес, ұқсастықтың бүкіл логикасы өзгереді.
Код қай жерде құлайды
Код көбіне модельге сұрау жіберген кезде емес, келесі қадамда — жаңа векторды сақтау, беру немесе ранжирлеуде қолдану кезінде бұзылады. Егер кеше модель 1536 сан қайтарып, бүгін 3072 қайтарса, мәселе іздеу сапасынан асып кетеді. Жүйе бөліктері арасындағы келісімнің өзі бұзылады.
Ең жиі ақау сақтау орнында болады. pgvector, Milvus, Qdrant және басқа жүйелер схема алдын ала бекітілген жерде вектордың нақты ұзындығын күтеді. Егер баған vector(1536) болып жасалған болса, 3072 ұзындықтағы вектор өздігінен бейімделмейді. База қате қайтарады, ал индексатор тоқтайды.
Тәжірибеде бұл кәдімгі жұмыс сияқты көрінеді. Түнгі batch job құжаттарды топтап алып, embedding есептеп, индекске жазады. Алғашқы үйлеспейтін жазбаның өзі қате береді, тапсырма үзіледі, ал каталогтың жартысы ескі векторлармен қалады. Таңертең API 200 OK қайтарады, бірақ іздеу ескі және жаңа деректердің қоспасымен жұмыс істеп тұрады.
Аз байқалатын бұзылулар да бар: сервистер арасындағы сериализация. Бір сервис embedding есептейді, екіншісі оны нормалайды, үшіншісі индекске салады. Егер бір жерде массив ұзындығы контрактқа жазылып қойса, жаңа формат пайплайнды бұзады. Кейде сервис бірден құлайды. Кейде одан да жаманы — массивті үнсіз қиып тастайды, нөл қосады немесе жазбаны бұзылған деп өткізіп жібереді.
Кэш те жиі тосқауыл болады. Ол құжаттар, сұраулар немесе аралық нәтижелер embedding-терін модель нұсқасынан ұзақ сақтайды. Ауысқаннан кейін сұраулардың бір бөлігі жаңа вектор алады, ал бір бөлігі кэштен ескі вектор алады. Код формалды түрде жұмыс істеп тұр, бірақ индекс пен ранжирлеу үйлеспейтін деректерді салыстырып жатыр.
Әдетте ақау бес жердің бірінде жасырынады: база немесе индекстің схемасы вектор ұзындығын қатаң бекітеді, batch job үйлеспейтін жазбаларды өткізіп жіберуді және логтауды білмейді, сервистер арасындағы алмасу форматы массив ұзындығын тексермейді, кэш модель нұсқасына қарай бөлінбейді, ал мониторинг тек жауап статусы мен сұрау уақытын қарайды.
Соңғысы әсіресе жағымсыз. Кәдімгі мониторинг endpoint тірі екенін, 500 қате жоқ екенін, кідіріс қалыпты екенін көреді. Оған бәрі жақсы сияқты. Бірақ ранжирлеу бұзылған: релевант құжаттар төмен түсіп кеткен, дубликаттар жоғары көтерілген, ұқсастық бойынша фильтрлер түсініксіз шу береді.
Егер команда модельді үйлесімді API-шлюз арқылы ауыстырса, қауіп жоғалмайды. Үйлесімді endpoint кодты өзгертпей сақтауға көмектеседі, бірақ векторлардың үйлесімділігін өздігінен шешпейді. Embedding өлшемін жүйе схемасының бір бөлігі ретінде қарау керек, модель жауабының ұсақ деталі ретінде емес.
Жұмыс іздеуінен мысал
Қолдау қызметінде білім базасы бойынша іздеу бар. Оператор қарапайым сұрақ енгізеді, жүйе ұқсас фрагменттерді табады да, дайын жауапты немесе мақалалар жинағын көрсетеді. Ұзақ уақыт бойы бәрі 1536 өлшемді embedding моделімен жұмыс істеді.
Кейін команда офлайн-тест өткізіп, 3072 өлшемді жаңа модельде жақсы нәтиже көрді. Белгіленген таңдамада ол басқаша қойылған сұрақтарды жақсырақ тауып, жақын тақырыптарды сирек шатастыратын. Шешім қауіпсіз сияқты көрінді: пайплайнда модельді ауыстырып, базаны біртіндеп қайта индекстеу.
Ақау қатты қате түрінде емес, баяу синхронсыздық түрінде басталды. Бір сервис жаңа 3072 вектор жазып жатты, ал екіншісі әлі де 1536 күтетін ескі индексқа деректер жіберіп тұрды. Жүйе жазбалардың бір бөлігін бірден қабылдамай тастады. Бір бөлігі жартылай ғана өтті: мәтін мен метадерек сақталды, бірақ вектор индексқа түспеді.
Сырттай қарағанда бәрі қалыпты көрінді. API сәтті жауап берді, тапсырмалар кезегі тоқтаған жоқ, мониторинг қызылға жанбады. Логтарда ашық қате аз болды, өйткені қолданба құжат түгел сақталса немесе кемінде қадам соңына жетсе, сұрау өңделді деп есептейтін.
Бір күннен кейін операторлар біртүрлі мінез-құлықты байқады. "как сменить пароль" немесе "где посмотреть счет" сияқты сұрауларда іздеу мағыналас, бірақ дәл емес құжаттарды бере бастады. Жауаптар сенімді көрінді, және бұл жағдайды одан әрі қиындатты: адамдар мәселе сұраудың тұжырымында деп ұзақ ойлады, деректерде емес.
Әдетте мұндайда үш белгі көрінеді: ескі мақалалар жаңаларға қарағанда жақсы табылады, бірдей сұрау әр уақытта әртүрлі нәтиже береді, ал қарапайым сұрақтар күрделі сұрақтарға қарағанда қаттырақ бұзылады.
Embedding өлшемі нақты жұмыста осылай көрінеді. Тек векторлардың үйлесімділігі ғана бұзылмайды. Іздеуге деген сенім де бұзылады. Команда себебін тек салыстырғанда табады: пайплайн қанша құжат қабылдады, қанша вектор шынымен жазылды, және индекске embedding-сіз қанша объект кірді. Сол сандардың арасындағы азғантай айырма да сапаны тез төмендетеді.
Жаңа модельге қадамдап көшу жолы
Embedding моделін ауыстыруды ұсақ баптау емес, схема миграциясы ретінде жүргізген дұрыс. Әйтпесе мәселе ең ыңғайсыз сәтте білінеді: индекс жаңа векторды қабылдайды, ал іздеу құжаттарды үнсіз шатастырады немесе код ұзындықтың сәйкес келмеуінен құлап кетеді.
Алдымен конфигурацияда тек модель атауын ғана емес, embedding өлшемін де бекітіңіз. Егер қашықтық метрикасын нақты көрсетсеңіз, оның нұсқасын да қосыңыз. Команда базада қандай вектор жатқанын және онымен қандай код жұмыс істеп тұрғанын бірден көруі керек.
Ескі және жаңа схеманы қасында қатар ұстаған қауіпсіз, нақты сұрауларда нәтижені көргенше.
- Жаңа векторларға бөлек баған немесе бөлек кесте жасаңыз да, жеке индекс жинаңыз.
- Ескі embedding-терді жұмыс күйінде қалдырыңыз, сонда сізде таза эталон мен жылдам кері қайту болады.
- Бірдей нақты сұраулар жиынын алыңыз: жиі, сирек, қысқа, қате жазылған және ұзын сұраулар.
- Әр модель үшін керекті құжат алғашқы нәтижелерге кіре ме, қанша сұрау бос шығарады, іздеу қанша уақыт алады және қаншаға түседі — соны тексеріңіз.
- Трафикті бөлшектеп ауыстырыңыз, мысалы 5%, кейін 20%, және ескі индексқа бірден қайтатын флагты сақтаңыз.
Салыстыруды әдемі демо таңдамада емес, адамдар күнде қолданатын деректерде жасаған дұрыс. Егер келісімшарттар базасындағы іздеу бұрын "расторжение по инициативе клиента" сұрауымен керекті шаблонды табатын болса, ал жаңа модель жиі қызмет туралы жалпы құжаттарды тартса, орташа скор бұрынғысындай көрінсе де сапа төмендеген.
Recall-ды қарапайым жолмен тексеруге болады: керекті құжат алғашқы 5 немесе 10 нәтижеде бар ма. Бұл сапа қай жерде өзгергенін тез байқауға жиі жетеді. Бөлек түрде толық тізбектің кідірісін де тексеріңіз: embedding генерациясы, жазу, индексқа сұрау және қолданбаға жауап. Кейде жаңа модель жақсырақ ранжирлейді, бірақ 150-200 мс қосады, оны пайдаланушылар сезеді.
Іске қосқан күні ескі индексті өшірмеңіз. Сапа, құн және код қателері бойынша тұрақты көрініс байқалғанша екі нұсқаны қатар ұстап тұрыңыз. Бұл жалықтыратын жол, бірақ асығыс дағдарыстан арзан.
Егер AI Router сияқты бір шлюз арқылы жұмыс істесеңіз, онда бірдей OpenAI-үйлесімді шақырумен модельді ауыстыру азғыруы әсіресе күшті болады. API деңгейіндегі ыңғайлылық пайдалы, бірақ индекстің және деректердің бәрібір бөлек нұсқасы, қайта индексациясы және нақты сұрауларда тексеруі керек.
Іске қосқаннан кейін нені өлшеу керек
Ауыстырғаннан кейін бірден тек жалпы дәлдікке қарамаңыз. Іздеу көбіне тыныш бұзылады: сұраулар графигі бірқалыпты, қате аз, ал адамдар қажетті құжатты бірінші ретте таба бермейді. Модель ауысқаннан кейін аптасына бір рет емес, күн сайын бірнеше метриканы бақылаған пайдалы.
Бірінші метрикалар жинағын бір дашбордта ұстаған жақсы:
- сұрау түрлері бойынша бос нәтижелер үлесі
- жиі сұраулардағы top-10 ығысуы
- индекстеу қателері және қабылданбаған векторлар саны
- индекс көлемі мен жад шығыны
- жазу және іздеу кідірісі
Бос нәтижелерді жүйе бойынша орташа емес, топтар бойынша қараңыз. Қысқа сұраулар, ұзын фразалар, артикльдер, клиент аттары, орысша мен ағылшынша аралас сұраулар әртүрлі әрекет етеді. Егер бос нәтиже 1-2%-дан 6-8%-ға дейін тек қысқа сұрауларда өссе, мәселе бар деген сөз, тіпті орташа метрика төзімді көрінсе де.
Top-10 ішіндегі ығысу өзі жаман емес. Жаман нәрсе — ол жаппай және кездейсоқ болғанда. Жиі сұрауларды алып, ескі және жаңа нәтижені салыстырыңыз: ондықтан қанша құжат жоғалды, қаншасы ішке кірді, бірінші релевант құжат қаншалықты жиі төмен түсті. Егер сізде білім базасы бойынша іздеу болса, "лимит по карте" сияқты сұрау кенеттен нақты жауаптың орнына жалпы беттерді тартпауы керек.
Индекстеу қателерін сұрау қателерінен бөлек есептеңіз. Код кейде үндемейді: кейбір құжаттар индексқа түспеді, өйткені вектордың ұзындығы басқа болды, serializer құйрығын қиып тастады немесе база жазбаны кері қайтарды. Логта бұл ұсақ нәрсе сияқты көрінуі мүмкін, бірақ іс жүзінде сіз корпустың 3-5%-ын жоғалтып алдыңыз.
Тағы төрт сигналды жиі бағаламайды: қайта индекстеуден кейін индекс көлемінің өсуі, іздеу түйініндегі жадтың артуы, жаңа құжаттарды енгізудің баяулауы және іздеудің p95 пен p99 кідірісінің көбеюі.
Егер жаңа модель векторды екі есе ұзын етсе, индекс те әдетте ауырлай түседі. Сонда іздеу дәл болып қала беруі мүмкін, бірақ жаңа деректерді жазу баяулайды, ал жад ең жаман сәтте — фондық қайта индексация кезінде — таусыла бастайды. Сондықтан жақсы іске қосуды тек релеванттылықпен емес, эксплуатация көзімен де қарайды.
Қымбатқа түсетін қателер
Ең жиі және ең қымбат қате — жаңа векторларды ескілермен бір индексте араластыру. Қағаз жүзінде бұл ұқыпты миграция сияқты көрінеді: құжаттардың бір бөлігі қайта есептеліп үлгерді, бір бөлігі әлі жоқ. Шын мәнінде іздеу түсініксіз мінез көрсете бастайды. Кейбір сұраулар күрт жақсарады, басқалары тыныш төмендейді, ал команда апталап релеванттылықтың нақты қай жерде бұзылғанын талқылайды.
Мәселе тек вектор ұзындығында емес. Ескі және жаңа модель бірдей өлшем берсе де, олардың кеңістігі әртүрлі құралуы мүмкін. Онда жақын көршілер енді бір нәрсені білдірмейді. Индекс жауап беріп тұрады, логта қате жоқ, бірақ нәтиже пайдаланушыны басқа жаққа бұрып жібереді.
Команда тек офлайн-метрикаға қараған кезде де көп ақша жанып кетеді. Тест таңдамада жаңа модель recall-ға 4-5% қосуы мүмкін, сонда бәрі релизге қуана келіседі. Кейін қате жазылған тіркестер, қысқа фразалар, ішкі жаргон және аралас орысша-қазақша мәтінмен тірі сұраулар келеді де, сурет өзгереді. Егер прод трафикті тексермесеңіз, сіз іздеуді емес, оқу стендін тексердіңіз.
Тағы бір тұзақ — өлшемді тек құжаттамада немесе wiki-де сақтау. Құжаттаманы рантайм оқымайды. Код индексацияда да, сұрауда да вектор ұзындығын өзі тексеруі керек. Егер команда модельді үйлесімді шлюз арқылы ауыстырса, қолданба SDK-ны өзгертпей жұмыс істей береді. Бұл ыңғайлы, бірақ дәл соның кесірінен жаңа модель басқа ұзындықтағы вектор қайтарған сәтті өткізіп алу оңай.
Көбіне бірден екі қабат бұзылады: embedding моделін ауыстырып, сонымен қатар chunking-ті де өзгертеді. Мұндай релизден кейін қайсысы әсер бергенін ешкім түсінбейді. Мүмкін, жаңа модель шынымен жақсарған шығар. Ал мүмкін, мәтіндер жай ғана қысқарақ бөліктерге бөлінгендіктен, іздеу анық сәйкестіктерді жақсырақ таба бастаған шығар. Екі параметрді бірден өзгертсеңіз, себеп-салдар байланысын жоғалтасыз.
Ең жүйкені жұқартатын сценарий — A/B тексеру соңына жетпей ескі индексті өшіру. Мұны орынды үнемдеу үшін немесе деректердің екі нұсқасын қатар ұстамау үшін жасайды. Содан кейін кез келген ақау дүрбелеңге айналады: кері қайту жоқ, салыстыратын нәрсе жоқ, ал іздеу сапасы туралы дауды жанама белгілермен жүргізуге тура келеді.
Қысқа тексеру тізімі
Embedding өлшеміне қатысты қателер сирек бір үлкен апат болып көрінеді. Көбіне іздеу алдымен үнсіз бұзылады, ал код кейінірек құлайды, өйткені база мен индексте әртүрлі векторлар араласып үлгереді.
Минималды ережелер жинағын құжаттамада емес, жүйенің өзінде бекіткен дұрыс.
- Әр вектор үшін модель нұсқасы мен модель атауын сақтаңыз.
- Базаға жазар алдында вектор ұзындығын тексеріңіз.
- Бір индексте embedding-тің тек бір түрін ғана ұстаңыз.
- Әдейі әртүрлі ұзындықтағы векторларды индекске жазып көруге тырысатын тесттер қосыңыз.
- Дайын кері қайту жолын ұстаңыз: ескі индекс, ескі модель және конфиг немесе флаг арқылы ауысу.
Мұны қарапайым сценарийде оңай тексеруге болады. Сіз жақсы сапа күтіп, embedding моделін ауыстырасыз. Жаңа модель басқа ұзындықтағы вектор бере бастайды. Егер база схемасы өлшемді валидацияласа, қате бірінші жазбада көрінеді. Егер жоқ болса, қоқыс индексқа түседі, ал іздеу түсініксіз мінез көрсетеді: кей сұраулар жұмыс істейді, кейбірі жоқ, ал релеванттылық айқын себепсіз құбылады.
Тіпті модельдерге бір API-шлюз арқылы кірсеңіз де, бұл тексерулер бәрібір керек. Шлюз провайдерді ауыстыру мен маршруттауды жеңілдетеді, бірақ векторлардың үйлесімділігін сіздің орныңызға түзетпейді.
Жақсы ереже қарапайым: модель тек деректер нұсқасымен, индекспен және кері қайту жоспарымен бірге өзгереді. Сонда embedding өлшемі жасырын мина болудан қалып, команда бақылауда ұстайтын кәдімгі техникалық параметрге айналады.
Әрі қарай не істеу керек
Кішкентай тірі сұраулар жинағынан бастаңыз да, модель ауыстырмас бұрын әр жолы соны іске қосып отырыңыз. "кошка" немесе "договор" сияқты синтетикалық мысалдарды алмаңыз. Нақты жұмыстан 30-50 сұрау алыңыз: қысқа, ұзын, қате жазылған, сирек терминдері бар сұраулар. Мұндай жинақ embedding өлшемі кодқа кедергі келтірмей тұрғандай көрінгенімен, іздеуді бұзып жатқан жерді тез көрсетеді.
Әр құжат пен индекстің қасында үш нәрсені сақтаңыз: модель атауы, вектор өлшемі және индекстеу күні. Бұл жалықтыратын тәртіп, бірақ ол көп сағаттық талдауды үнемдейді. Дерекқорда 1536 және 3072 векторлары араласқанда, мәселе бірден көріне бермейді. Алдымен сапа аздап төмендейді, кейін біреу жазу кезінде қате ұстайды, ал кейін команда индексте нақты не жатқанын түсінбей қалады.
Тіпті шағын командада да төрт жұмысты бөліп ұстаған пайдалы: жаңа модельдегі іздеу сапасын бөлек тексеру, жаңа вектор ұзындығы үшін сақтау схемасын бөлек өзгерту, ескі құжаттарды бөлек қайта индекстеу және жаңа модельді продакшенге бөлек қосу. Егер мұның бәрін бір релизге қоссаңыз, не бұзылғанын түсінбей қаласыз: жаңа модель ме, ескі индекс пе, әлде жазу коды ма.
Ыңғайлы біртұтас API де тәртіпті талап етеді. Егер команда AI Router және api.airouter.kz endpoint арқылы модель ауыстырса, embedding үшін дәл сондай дерлік шақыруға сүйене беруге болмайтынын ұмытып кету оңай. Мұндай шлюз тәжірибені және провайдерді ауыстыруды жылдамдатады, бірақ жазу алдында вектор ұзындығын тексеріп, индекс нұсқасын бөлек ұстау бәрібір қажет.
Тәжірибелік ереже қарапайым: embedding моделінің кез келген миграциясы продакшеннен емес, бақылау өтпесінен басталады. Егер жаңа модель сіздің сұраулар жиынында іздеуді жақсартып, вектор үйлесімділігінен өтті және схеманы бұзбаса, тек содан кейін трафикті көшіріңіз. Embedding тақырыбында сақтық көбіне шұғыл кері қайтудан арзан түседі.
Жиі қойылатын сұрақтар
Модель басқа ұзындықтағы вектор бере бастағанда бірінші не бұзылады?
Алдымен деректердің контракті бұзылады. База, индекс немесе ұқсастық сервисі, мысалы, 1536 сан күтеді, ал 3072 алады. Ең жақсы жағдайда жазу кезінде бірден қате көресіз. Ең жаманы — пайплайнның бір бөлігі жаңа векторды үнсіз жұтып, іздеу құжаттарды ашық қате шығармай-ақ шатастыра бастайды.
API мен SDK өзгермей қалса, модельді жай ғана ауыстыра салуға бола ма?
Жоқ, бұл жеткіліксіз. Үйлесімді шақыру модельге жіберілетін кодты сақтап қалады, бірақ ескі индексті жаңа embedding-термен үйлесімді етпейді. Дұрыс көшу үшін деректердің бөлек нұсқасын ұстаңыз, корпус векторларын қайта есептеңіз және нақты сұрауларда нәтижені тексеріңіз.
Екі модель де 1536 сан берсе, ескі және жаңа embedding-терді араластыруға бола ма?
Жоқ. Бірдей ұзындық векторлардың бір кеңістікте өмір сүретінін білдірмейді. Егер ескі құжат embedding-терін жаңа сұрау embedding-терімен араластырсаңыз, іздеу бірден құламаса да, нәтижелердің реті түсініксіз болып кетеді.
Мониторинг бәрі дұрыс деп тұрса да, іздеу неге бұзыла береді?
Өйткені кейбір ақаулар сервисті құлатпайды. Endpoint тез жауап береді, кезек тоқтамайды, бірақ релеванттылық уже төмендеп кеткен болады. Бұл әсіресе қысқа сұрауларда байқалады: адам бірнеше сөз жазады да, жоғарғы жақтан тақырып жағынан ұқсас, бірақ керек емес құжаттар шығады.
Модель ауысқаннан кейін код көбіне қай жерде құлайды?
Әдетте сақтау орны немесе индексатор құлайды. vector(1536) бағаны 3072-ні қабылдамайды, batch job тоқтайды, ал каталогтың бір бөлігі ескі векторларда қалады. Құжаттар арасындағы сериализация мен кэш те жиі бұзылады, егер олар модель нұсқасы мен массив ұзындығын тексермесе.
Жаңа модельге қалай тихо поломкасыз көшуге болады?
Ең қауіпсіз жол — модель ауысуын схема миграциясы ретінде жүргізу. Ескі индекстің қасына жаңа индекс құрып, корпус үшін embedding-терді қайта есептеп, екі нұсқаны нақты сұрауларда салыстырып, содан кейін ғана трафикті бөліп ауыстырыңыз. Тұрақты нәтиже көрмей тұрып, ескі индексті өшірмеңіз.
Жаңа модельге ауысқаннан кейін нені өлшеу керек?
Тек орташа дәлдікке қарамаңыз. Күн сайын бос нәтижелер үлесін, top-10 ішіндегі ығысуды, индекстеу қателерін, іздеу кідірісін және индекс көлемін бақылаңыз. Егер жаңа модель векторды ұзартып жіберсе, жад пен жазу жылдамдығы да жиі төмендейді.
Барлық құжаттардың embedding-терін қайта есептеу керек пе?
Иә, қалыпты жағдайда бүкіл корпусты қайта есептеу керек. Ескі құжаттар мен жаңа сұраулар бір векторлық кеңістікте өмір сүруі тиіс, әйтпесе нәтижелер араласып кетеді. Ішінара переиндексация тек уақытша қадам ретінде жарайды, егер бөлек индекстер ұстап, трафикті нақты бөліп отырсаңыз.
Embedding ауысқанда кэш іздеуді қалай бұзады?
Кэш мәселені оңай жасырады. Ауыстырғаннан кейін сұраулардың бір бөлігі жаңа вектор алады, ал бір бөлігі кэштегі ескі векторды пайдаланады, сол кезде жүйе үйлеспейтін деректерді салыстырады. Модель нұсқасына қарай кэшті бөліп, миграция кезінде тазалап отырыңыз, әйтпесе талдау жұмысы ауысудың өзінен де ұзаққа созылады.
Егер мен AI Router арқылы жұмыс істесем, өлшем мәселесі жойыла ма?
Жоқ, шлюз үйлесімділік тексеруін алып тастамайды. AI Router бір OpenAI-үйлесімді endpoint арқылы модель мен провайдерді ауыстыруды жеңілдетеді, бірақ вектор ұзындығын, индекс нұсқасын және қайта индексацияны команданың өзі бақылауы керек. Embedding үшін бұл — деректер схемасының бөлігі, модель жауабының ұсақ деталі емес.