Dense, sparse және hybrid retrieval: қалай әділ салыстыруға болады
Dense, sparse және hybrid retrieval-ді әділ салыстыру үшін корпус, сұраулар, метрикалар және чанкинг ережелерін алдын ала теңестіріңіз.
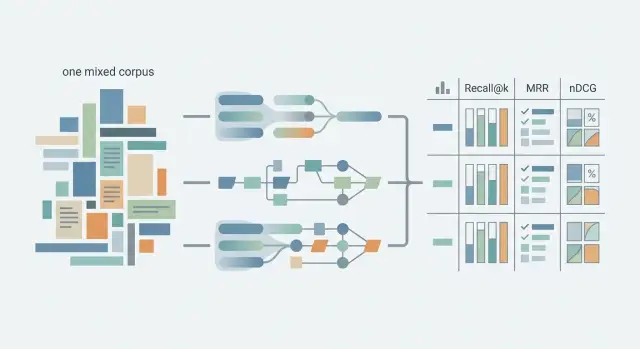
Неге салыстыру метрикаларға дейін-ақ бұзылады
Мәселе көбіне модельде де, индексте де емес. Бәрі одан ертерек шатасады: бір тестке әртүрлі типтегі мәтіндерді салып, бәрінен бір ғана жеңімпаз күтеді. Аралас корпуста бұл іс жүзінде жұмыс істемейді. Sparse дәл сөздер мен сирек терминдерді жақсы іліп алады, dense көбіне мағыналық сәйкестікті табады, ал hybrid жиі жай ғана баптауға көбірек еркіндік бергені үшін жеңіп кетеді.
Қысқа және ұзын құжаттар да әртүрлі сигнал береді. Үш жолдық жазба көбіне бір-екі дәл сөзге сүйенеді. Керісінше, 40 беттік регламент жауапты бірнеше бөлімге шашып жібереді, сондықтан ол жерде тек іздеу әдісі ғана емес, мәтінді чанкке қалай бөлетініңіз де шешуші болады. Мұны теңестірмесеңіз, дау тез арада retrieval-ден preprocessing-ке ауысып кетеді.
Тағы бір өте қарапайым себеп бар: командалар бір нәрсені әртүрлі атайды. Бір бөлімде «шарт нөмірі» деп жазады, екіншісінде «келісімшарт ID-і», үшіншісінде — өтінімнің ішкі коды. Sparse сөздікке байланысты әлсіреуі мүмкін, dense жақын ұқсас нысандарды шатастырады, ал hybrid екеуін де жауып тұрғандай көрініп, тек сондықтан жақсырақ болып көрінуі мүмкін. Бұл оны кез келген корпус үшін ең жақсы етеді деген сөз емес.
Тестті көбіне төрт нәрсе бұрмалайды: әдістерге әртүрлі чанкинг беру, сұрауларды бір типте ғана жасау, индекстеу алдында мәтінді әртүрлі тазалау және релеванттықты бұлыңғыр бағалау. Практикада бұл аралас кез келген жиында көрінеді: білім қоры, қызметтік хаттар, регламенттер, операторлардың қысқа пікірлері. Бір әдіс қысқа жазбаларда керемет іздейді де, ұзын құжаттарда нашар жұмыс істейді. Екіншісі керісінше нәтиже көрсетеді.
Сондықтан dense, sparse және hybrid retrieval-ді «орташа температурамен» салыстыруға болмайды. Алдымен ортақ ережелерді бекітіңіз: бір корпус, бір мәтін дайындау тәсілі, салыстырмалы есептеу шарттары және қай жауапты релевант деп санау керегін шешудің бірдей әдісі.
Алғашқы іске қосуға дейін нені теңестіру керек
Егер әдістерге кіріс дерек әртүрлі болса, салыстыру метрикаларға жетпей-ақ бұзылады. Әділ тест үшін алдымен корпусты бекітіңіз: бір жүктеу күні, бір құжаттар тізімі, бір өрістер схемасы. Бүгін базада 120 мың құжат, ертең 127 мың болса, нәтиже айырмасы әдістен емес, жаңа мәтіндерден шығуы мүмкін.
Келесі қадам — айқын дубликаттар мен өте ұқсас көшірмелерді алып тастау. Бұл жиі кездесетін тұзақ: бір нұсқаулық PDF-та, wiki-де және қолдау тобының білім базасында бірдей тұрады. Сонда бір әдіс «көбірек тапқандай» көрінеді, ал шын мәнінде ол бір жауаптың бірнеше көшірмесін ғана ұстады. Бір канондық құжатты қалдырған дұрыс немесе кем дегенде дубль топтарын алдын ала белгілеу керек.
Мәтінді бірдей тазалау бәріне қажет. Егер sparse шикі HTML-ды мәзірімен, төменгі бөлігімен және қызметтік блоктарымен индекстесе, ал dense тазартылған мәтін алса, сіз іздеу әдістерін емес, корпустың екі нұсқасын салыстырып отырсыз. Бірдей пайплайнды бірден бекітіңіз: шуды қалай алып тастайсыз, кестелермен не істейсіз, OCR-ды қалай тазалайсыз, тақырыптар мен түсіндірмелер сақтала ма.
Чанкингте де эксперименттерді араластырмаған дұрыс. Қысқа және ұзын құжаттар әртүрлі әрекет етеді, ал чанк өлшемі нәтижені қатты өзгертеді. Егер бір прогон құжаттарды тұтасымен, ал екіншісі 300 токендік chunk-тармен және overlap-мен жүрсе, айырмашылықтың себебі енді retriever-де емес. Алдымен әдістерді бірдей бөлу схемасында салыстырыңыз. Кейін схемалардың өзін бөлек салыстырыңыз.
Алғашқы іске қосуға дейін мына нәрселерді бекітіп қойған пайдалы:
- корпусты жүктеу күнін
- іздеу өрістерінің тізімін
- тіл, құжат типі және қолжетімділік құқықтары бойынша фильтрлерді
- мәтінді тазалау ережелерін
- осы іске қосуға арналған чанкинг схемасын
Әсіресе өрістер мен фильтрлерді мұқият тексеріңіз. Егер sparse title мен body бойынша іздесе, ал dense тек body-ды кодтаса, тест бірден бұрмаланады. Тіл, бөлімше немесе құжат статусы бойынша фильтрлерге де солай. Олар барлық прогондарда бірдей жұмыс істеуі керек.
Аралас корпуста бұл бірден көрінеді. Мысалы, заңгерлер қысқа жазбалар жазады, саппорт ұзын мақалалар сақтайды, ал product-команда кестелер мен тізімдерді жақсы көреді. Ортақ дайындықсыз dense жай ғана шулы форматты жақсы көтергені үшін жеңуі мүмкін, ал іздеудің өзі күшті болғандықтан емес. Әуелі кірісті теңестіріңіз, содан кейін цифрларға қараңыз.
Қалай бұрмаламай сұраулар жинау керек
Егер тестке арналған барлық сұрауларды бір инженер жазса, сіз іздеуді емес, оның ойды қалай тұжырымдайтынын тексеріп жатасыз. Мұндай жиын әдетте тазалау, қысқа және логикалық болады — нақты пайдаланушы сұрақтарына қарағанда.
Жақсысы — тірі көздерден бастау: іздеу логтары, қолдау тикеттері, ішкі чаттар, саппорт хаттары, білім базасындағы сұраулар тарихы. Онда адамдар «қалай сұрауы керек» дегеннен гөрі, шын мәнінде қалай сұрайтыны тез көрінеді. Белгілеуге дейін дубликаттарды алып тастаңыз және PII-ді жасырыңыз, бірақ тілді «жылтыратып» жібермеңіз. Қате жазулар, үзіліп қалған сөйлемдер және оғаш қысқартулар мұнда керісінше пайдалы.
Содан кейін сұрауларды қарапайым срездерге бөліңіз. 2-4 сөздік қысқа формаларды, бірнеше шарты бар ұзын сұрақтарды, «айтыңызшы, қайда...» сияқты сөйлесу стиліндегі сұрауларды, терминдер мен аббревиатураларды, сондай-ақ қате жазылған және орысша-ағылшынша аралас формаларды бөліп алған жеткілікті.
Аралас корпуста бұл әсіресе маңызды. Бір бөлім «акт сверки» деп жазады, екіншісі — «сверочный акт», үшіншісі шаблон нөмірімен іздейді. Мұндай сұрауларда әдістер әртүрлі әрекет етеді, ал әділ тест соны ұстап қалуы керек.
Тіпті сирек жағдайларды толықтыру үшін де барлық сұрауды бір адамның қолымен жазбаңыз. Бірнеше рөлді қосыңыз: саппорт, аналитик, білім базасының редакторы, инженер. Әдетте он мысалдың өзінде олардың тілі қалай бөлінетіні көрінеді. Бұл жақсы. Демек, сіз нақты трафикке жақындайсыз.
Сұрау ниетін де белгілеу пайдалы. Практика үшін бес белгі жеткілікті: факт, нұсқаулық, салыстыру, дәл фраза және идентификатор не термин бойынша іздеу. Мұндай белгілеу нәтижені талдауды қатты жеңілдетеді. Егер dense дәл фразаларды нашар іздесе, ал hybrid ұзын сөйлесу сұрақтарында ұтса, ол бірден көрінеді де, орташа метрикада жоғалып кетпейді.
Қысқа және ұзын құжаттарды қалай дайындау керек
Бүкіл корпусқа бірдей чанкинг жасау салыстыруды дерлік әрдайым бұзады. Егер барлық құжатты 500 токендік бөліктерге бөлсеңіз, қысқа карточкалар пішінін жоғалтады, ал ұзын мәтіндер бөлшектеніп, жауап екі chunk-тың ортасында қалып қояды. Одан кейін сіз әдістерді емес, мағынаның әртүрлі нұсқаларын салыстырасыз.
Қысқа құжаттарға тимеген дұрыс. Тауар карточкасы, қысқа FAQ, тариф сипаттамасы, жарты бетке жетпейтін ішкі ереже көбіне тұтас күйінде жақсы жұмыс істейді. Мұндай мәтінді бөліп тастасаңыз, іздеу үзінділерді қайтара бастайды, ал бастапқы құжаттың өзі-ақ ыңғайлы выдача бірлігі болған.
Ұзын құжаттарға тәсіл басқа. Регламент, келісімшарт, нұсқаулық немесе есепті тақырыптар, ішкі тақырыптар және аяқталған мағыналық блоктар бойынша бөлген дұрыс. Тұрақты өлшемді жоғарғы шек ретінде қолдануға болады, бірақ жалғыз ереже ретінде емес. Әйтпесе бір chunk-қа екі тақырып түседі, ал екіншісінде кестенің сілтемесі ғана қалады, өзі болмайды.
Аралас корпуста метадеректерді мәтіннен бөлек сақтау пайдалы. Ең аз дегенде — құжат типі мен бастапқы команда. Бұл тек фильтр үшін емес. Осылайша сіз бір әдіс FAQ-тарда жақсы, ал екіншісі регламенттерде жақсы іздейтінін көресіз және алгоритм айырмасын жазу стилінің айырмасымен шатастырмайсыз.
Негізгі схема қарапайым:
- қысқа карточкаларды тұтас сақтау
- ұзын мәтіндерді құжат құрылымы бойынша бөлу
- ой жиі блок шекарасынан өтетін жерлерде ғана шағын overlap қосу
- құжат типін, авторын және бөлімін бөлек өрістерде сақтау
- chunk-тың ұзындығын ғана емес, жауаптың толықтығын да тексеру
Соңғы тармақты жиі өткізіп алады. Корпуста нақты жауабы бар 20-30 сұрауды алып, табылған chunk жауапты толық қамти ма — қолмен тексеріңіз. Тек ишара емес, абзацтың жартысы емес, RAG-қа күмәнсіз бере алатын фрагмент болуы керек.
Қарапайым мысал: құжатта «Операциялар бойынша лимиттер» бөлімі бар, ал төменірек ерекше жағдайлар кестесі тұр. Егер chunk кестеге дейін аяқталса, sparse керек тақырыпты табады, dense ұқсас абзацты ұстауы мүмкін, hybrid екі фрагментті де қайтарады. Бірақ ешқайсысы толық жауап бермейді. Мәселе retriever-де емес, құжатты қалай кескеніңізде.
Тестті қалай өткізу керек
Екі қарапайым базалық сызықтан бастаңыз. Sparse үшін әдетте BM25-дің өзі, қолмен баптаусыз-ақ, жеткілікті. Dense үшін бір эмбеддинг-чекпоинт пен бір чанкинг әдісін алыңыз, бастапқыда reranker қоспаңыз. Бірден күрделі пайплайн жинасаңыз, нақты қайсысы өсім бергенін түсінбейсіз.
Содан кейін ең қарапайым fusion-ы бар hybrid қосыңыз. Көбіне reciprocal rank fusion немесе скорлардың түсінікті сызықтық қоспасы жеткілікті. Бірінші күні он салмақты таңдауға тырыспаңыз. Әділ тест үшін айлакер, бірақ қайталауға келмейтін схема емес, дөрекілеу болса да, ашық схема жақсы.
Сол бір сұраулар жиыны үш нұсқаның бәрінен де өтуі керек. Прогондар арасында сұрау тұжырымын, фильтрлерді, чанкинг ережелерін немесе корпустың құрамын өзгертуге болмайды. Тіпті болмашы айырмашылық та салыстыруды бұзады, әсіресе корпус ішінде қысқа FAQ, ұзын регламенттер және әртүрлі командалардың құжаттары қатар тұрса.
Практикалық тәртіп мынадай:
- корпус, chunk-тар, stop-сөздер мен фильтрлерді бекіту
- sparse-индекс пен dense-индексті бірдей деректерде құру
- іздеуден кейін қолмен тазаламай, бір пул сұрауды өткізу
- бірдей k жиынында Recall@k, MRR және nDCG есептеу, мысалы 5 және 10
- latency, индекс өлшемі және жаңарту құнын бөлек өлшеу
Метрикаларды бірге оқу дұрыс. Recall@k жүйе керекті фрагментті мүлде тапты ма, соны көрсетеді. MRR ол қаншалықты жоғары көтерілгенін көруге пайдалы. nDCG релеванттық бинарлы емес, «дәл келеді», «ішінара келеді» және «шу» сияқты градациялар бар кезде айырманы жақсырақ көрсетеді.
Офлайн сапа мен құнын бір цифрға араластырмаңыз. Қарапайым кесте жасаған ыңғайлы: сапа, орташа latency p50 және p95, индекс көлемі, қайта индекстеу уақыты мен құны. Сонда, мысалы, dense ұзын құжаттарда өсім бергенімен, жаңартылуы үш есе ұзақ, ал hybrid аралас корпусты бірқалыпты ұстап, жылдамдықтан іс жүзінде ұтылмайтыны көрінеді.
Егер сенуге болатын нәтиже алғыңыз келсе, тюнингті екінші айналымға қалдырыңыз. Бірінші прогон рекорд үшін емес, таза бастапқы нүкте үшін керек. Тек содан кейін fusion салмақтарын таңдауға, chunk өлшемін өзгертуге немесе reranker қосуға болады.
Аралас корпус мысалы
Жақсы тест бір қарағанда қарапайым, бірақ біркелкі емес құжаттар жиынында көрінеді. Айталық, базада 2-3 жолдық қысқа FAQ, екі беттік егжей-тегжейлі нұсқаулықтар және қолдау хаттарының шаблондары бар. Бұлардың бәрі бір қайтару процесін сипаттайды, бірақ мәтіндерді әртүрлі командалар жазғандықтан, тұжырымдар шашыраңқы.
Сұрауды сөйлесу стилінде аламыз: «чекті болмаса, тауарды қалай қайтаруға болады». Бұл таза салыстыруға ыңғайсыз, сондықтан пайдалы. Пайдаланушы білім базасындағы бөлім қалай аталғанын емес, өзі қалай білсе, солай жазады.
Выдача қалай көрінеді
Sparse әдетте дәл сөздерге ілінеді. Егер FAQ-та «чексіз қайтару сатып алуды растаған жағдайда мүмкін» деген жол болса, сол құжат жиі жоғары көтеріледі. Сигнал күшті, өйткені сәйкесу дерлік тура.
Dense басқаша әрекет етеді. Ол «чек сақталмаған болса, қызметкер төлемді карта немесе тапсырыс нөмірі бойынша тексереді» деген сияқты абзацы бар ұзын нұсқаулықты табуы мүмкін. Мағынасы бойынша бұл дұрыс жауап, бірақ тұжырымы басқа.
Сол корпусқа hybrid жиі ең жақсы жоғарғы выдача береді. Ол бір жағынан дәл фразасы бар FAQ-ты, екінші жағынан әрекет тәртібі жазылған ұзын нұсқаулықты қатар ұстай алады. RAG үшін бұл көбіне тек қысқа жауаптан немесе тақырыпта айқын сәйкесуі жоқ жалғыз ұзын құжаттан жақсырақ.
Жеңілдетілген top мынадай болуы мүмкін:
- sparse: FAQ «чексіз қайтару», «чек жоғалған» деген тіркесі бар хат шаблоны, кейін нұсқаулық
- dense: қайтару нұсқаулығы, сатып алуды растау туралы FAQ, кейін операторларға арналған жазба
- hybrid: FAQ «чексіз қайтару», сатып алуды тексеру қадамдары бар нұсқаулық, кейін хат шаблоны
Fusion қай жерде бұзылады
Мәселе көбіне hybrid идеясының өзінде емес, ранктерді біріктіруде. Егер fusion семантикалық сигналды тым қатты басса, жоғарыға айырбас, кепілдік немесе тапсырысты жою туралы жай ұқсас мәтіндер шығады. Керісінше, егер ол дәл сәйкесулерді тым жақсы көрсе, керек сценарийі бар ұзын нұсқаулық қысқа FAQ-тан төмен түсіп кетеді де, RAG-тағы модель тым жалпы жауап береді.
Мұндай корпуста тек бірінші құжатты емес, top-3-ті де қараған пайдалы. Егер алғашқы үштікте әрі дәл FAQ, әрі толық нұсқаулық болса, жүйе дұрыс жұмыс істеп тұр деген сөз. Егер онда үш ұқсас хат шаблоны тұрса, іздеу бірдеңе тапқан сияқты, бірақ пайдасы аз.
Дәл осындай сұрауларда әділ тест нақты айырманы көрсетеді. Sparse «чексіз қайтару» деген формулировканы ұстайды, dense сөйлесу стиліндегі сұрақты түсінеді, ал hybrid тек fusion дәл сәйкестіктерді тым жалпы мағыналық ұқсастықтан төмен түсірмесе ғана ұтады.
Әдістер қай жерде ажырайды
Бүкіл корпус бойынша бір орташа мән ең маңызды нәрсені жиі жасырады. Жүйе жалпы жақсы балл көрсетуі мүмкін де, дәл адамдар жиі жіберетін сұрауларда сүрінеді.
Sparse әдетте дәл сәйкестіктерді жақсы ұстайды. Егер сұрауда қате коды, артикул, форма нөмірі, өріс атауы, аббревиатура немесе сирек термин болса, мұндай іздеу dense-ке қарағанда нысанаға тезірек тиюі мүмкін. Әртүрлі командалар жинаған корпус үшін бұл қалыпты көрініс: client_id, «Форма 12» немесе процессің ішкі коды сияқты атауларды sparse сенімді табады, ал dense кейде мағынасы ұқсас, бірақ қате құжатқа апарып жібереді.
Dense адам ұзақ әрі өз сөздерімен жазғанда жақсырақ жұмыс істейді. Қайта айту, сөйлесу стиліндегі сұрақ, дәл терминсіз мәселе сипаттамасы — оның күшті жағы. Егер қызметкер «клиенттің келісімін жаңа анкетаға қалай өткіземіз» деп сұраса, dense көбіне керекті құжатты табады, тіпті онда басқа формулировка қолданылса да, мысалы «растауды профильге көшіру».
Hybrid бір процесті әр автор әртүрлі сөзбен сипаттаған кезде пайдалы. Мұндай корпустарда гибридті іздеу RAG ішінде жиі ең тегіс нәтижені береді: sparse дәл сөздерді іліп алады, dense мағынаны тартады. Бұл әсіресе жылдар бойы жиналып, бір сөздікке келтірілмеген білім базаларында байқалады.
Бірақ hybrid те қателеседі. Егер бір сигнал тым қатты болып кетсе, ол выдачаны басқа жаққа сүйрейді. Әдеттегі жағдай: BM25 керек сөз бар, бірақ сұраққа жауап жоқ құжатты тым жоғары қояды. Керісінше қате де болады: dense «сол тақырыпқа қатысты» мәтінді жоғары шығарады, ал нақты реквизиті бар құжат одан жоғары тұруы керек еді.
Сондықтан тек жалпы nDCG немесе Recall-ға қарамаңыз. Сұрауларды кемінде бірнеше срезге бөліңіз: дәл идентификаторлар мен кодтар, 2-4 сөздік қысқа сұраулар, еркін формадағы ұзын сұрақтар, бір ниеттің қайта айтылған нұсқалары және бір процестің бірнеше атауы бар жағдайлар.
Осылай бөлгенде сурет әлдеқайда әділ болады. Кейде орташа есепте «жеңімпаз» мүлде жоқ болып шығады: дәлдік үшін sparse керек, мағына үшін dense керек, ал hybrid сұрау типіне қарай әр сигналдың салмағын баптай алсаңыз ғана мәнді болады.
Бағалаудағы жиі қателер
Қателердің көбі формуладан емес, тестті дайындаудан шығады. Бір корпуста үш жолдық FAQ-тар, ұзын регламенттер және әртүрлі командалардың құжаттары жатса, метрикалар оңай-ақ әдемі, бірақ әділетсіз салыстыру береді.
Бірінші қате — әдістерді әртүрлі чанкингпен салыстыру. Егер sparse тұтас бетпен жұмыс істеп, ал dense 300-500 токендік бөлік көрсе, сіз іздеуді емес, корпустың әртүрлі бейнелерін салыстырып отырсыз. Кейде содан кейін бір тәсіл жақсы деген қорытынды жасайды, бірақ ол жай ғана мәтіннің ыңғайлы формат алғаны үшін.
Екінші қате — fusion-ды тест жиынына ыңғайлау. Бұл жиі болады: hybrid алып, dense пен BM25 салмақтарын метрика өскенше бұрай береді де, соны финал нәтижесі деп атайды. Баптау үшін бөлек dev-жиын керек. Тест жиыны соңына дейін жабық қалуы тиіс.
Үшінші қате де тыныш, бірақ қорытындыны бұзады: корпус тек бір индекс үшін тазаланады. Мысалы, қайталанатын тақырыптар, үлгі фразалар мен stop-сөздер sparse үшін алынып тасталады да, dense басқа мәтінге қалады. Немесе керісінше, тек эмбеддинг үшін өрістерді қайта жазып, бөлімдерді біріктіреді. Әділ тест бәріне бірдей бекітілген корпустың бір нұсқасынан басталады.
Тағы бір шу көзі — дубликаттар, шаблондар және құжаттардың ескі нұсқалары. Олар score-ды көбіне кездейсоқ көтеріп жібереді. Сұрау керек құжатқа емес, оның көшірмесіне, черновигіне немесе ескірген редакциясына түседі. Қағаз жүзінде метрика қалыпты көрінеді, ал нақты RAG жүйесінде пайдаланушы дұрыс емес жауап алады.
Орташа score-дың өзі де көп нәрсе айтпайды. Екі жүйеде Recall@10 ұқсас болуы мүмкін, бірақ қате жіберу сипаты басқа болады. Біреуі ұзын құжаттарды тұрақты жоғалтады. Екіншісі қысқа қызметтік жазбаларда шатасады, өйткені термин аз.
Өлшемнен кейін кемінде 20-30 промахты қолмен қарап, себебін белгілеу пайдалы. Әдетте бірнеше сценарий қайталанады: релевант фрагмент индекске түспеген, chunk тым үлкен не тым кішкентай болған, сұрау мен құжат әртүрлі лексика қолданған, выдачаға ескі нұсқа немесе дубль кірген, не hybrid ранктерді әр әдістен де нашар қосқан. Мұндай талдау кестедегі тағы бір үтірден кейінгі саннан әлдеқайда пайдалы.
Финалдық өлшемге дейінгі тексеріс
Финал цифрларды көбіне модель емес, шарттардың ұсақ айырмасы бұзады. Бір индекс кеше, екіншісі бүгін жиналған. Бір прогонда сұраулар тазартылды, екіншісінде сол күйі қалды. Осыдан кейін салыстыруды әділ деуге болмайды.
Егер сенуге болатын тест керек болса, тек метриканы емес, өлшеу тәртібін де тексеріңіз. Әсіресе қатарында қысқа карточкалар, ұзын регламенттер және әртүрлі командалардың мәтіндері жатқан аралас корпуста.
Іске қосар алдында қысқа тізімнен өткен дұрыс:
- бірдей бір жүктеуден алынған бір корпус алу
- әдістер арасында тұжырымды өзгертпей, бір сұрау жинағын өткізу
- релеванттықты белгілеудің бірдей схемасын ұстау
- бірдей top-k-ты бекіту
- тек бір жалпы санға емес, срездер бойынша есепке қарау
Көбіне осы соңғы тармақ дауды шешеді. Орташа метрика бірқалыпты көрінуі мүмкін, бірақ ішінде dense ұзын түсіндірмелі мәтіндерді жақсы ұстайды, sparse қысқа құжаттардағы дәл сәйкестіктерді тартып алады, ал hybrid айырманы тек кейбір сұрауларда ғана тегістейді.
Метрика кестесінің қасына 20-30 қолмен талданған промахты қалдырыңыз. Бұл қайталанатын ақауды көруге жеткілікті: нашар chunk, шуылы көп тақырыптар, тілдердің шатасуы, дубликаттар немесе тым жалпы сұрау. Мұндай мысалдарсыз әдемі санға сеніп қалып, шынайы мәселені байқамай қалу оңай.
Финалдық өлшем барлық әдіс үшін скучно және бірдей болуы керек. Корпус бойынша іздеуді бағалаудың қалыпты түрі де осы: тест кезінде еркіндік аз, тесттен кейін дау аз.
Өлшеуден кейін не істеу керек
Өлшеуден кейін бір жалпы санға қарап жеңімпазды бірден жарияламаңыз. Орташа nDCG немесе Recall@k пайдалы, бірақ өнім орташа мәнмен өмір сүрмейді. Егер трафиктің 70%-ын коды, тариф атауы немесе артикулы бар қысқа сұраулар құраса, алдымен сол срезге қараңыз.
Мынадай жағдай болады: dense жалпы метрикада жеңеді, бірақ пайдаланушыларға ең көп қиындық әкелетін сұрауларда жиі қателеседі. Онда ол өнім үшін жеңімпаз емес. Орташа мәні сәл төмен болса да, басым сценарийлерді сенімді жауып тұратын әдісті таңдаған дұрыс.
Көбіне бір әдісті емес, негізгі схеманы және резерв нұсқаны таңдаған ақылдырақ. Мысалы, dense еркін формулировканы жақсы түсінеді, ал sparse аббревиатураларды, форма нөмірлерін және сирек терминдерді дәлірек табады. Мұндайда hybrid-ті бәріне бірдей іске қосудың қажеті жоқ. Кейде fallback ұстап, коды мен дәл термині бар сұрауларды екінші retriever-ге жіберу оңайырақ.
Шешім шыққан соң оны жазбаша бекітіңіз. Қысқа есеп төрт сұраққа жауап беруі керек: қай әдіс приоритетті срездерде жақсы жұмыс істейді, қай жерде ол әлсірейді және ол тесікті қандай fallback жабады, қандай баптаулар қолданылды, сұрау, кідіріс және қайта индекстеу қанша тұрады.
Мұндай шаблон сезімге негізделген дауды тез жояды. Команда бірдей цифрлар мен бірдей мысалдарға қарай бастайды.
Егер кейін чанкингті немесе сөздікті өзгертсеңіз, тест аяқталды деп санамаңыз. Тіпті жақсы retriever-дің өзі жаңа chunk шекараларынан, басқа лемматизациядан немесе stop-сөздерді тазалаудан кейін мінезін айтарлықтай өзгертеді. Аралас корпуста бұл бірден байқалады: ұзын регламенттер жақсырақ кесіледі, ал қысқа жазбалар дәл сәйкестіктерін жоғалтады. Мұндай түзетулерден кейін сол сұраулар жинағымен және сол есеп шаблонымен қайта прогон жасау керек.
Тағы бір тұзақ бар: команда retrieval мен LLM-қабатты бір уақытта өзгертеді. Сонда өсімді не бергені белгісіз қалады — іздеу ме, reranking пе, әлде жауап беретін жаңа модель ме. Егер сіз бір мезгілде әртүрлі модельдерді тесттесеңіз, оларға қол жеткізу инфрақұрылымын retrieval экспериментінен бөлек ұстаған ыңғайлы. Мысалы, airouter.kz ішіндегі AI Router әртүрлі модельдер үшін бір OpenAI-үйлесімді endpoint береді, сондықтан retrieval-ды SDK, код және промпттарды қайта жазбай-ақ бөлек салыстыруға болады.
Мұндай тесттің қалыпты қорытындысы скучное сияқты естіледі, бірақ керегі де сол: қандай сұрау типтерінде қай әдіс мықты, қай жерде қателеседі, қолдауға қанша тұрады және продакшен үшін нені таңдадыңыз. Командада осы сұрақтарға жауап болса, салыстыру бекер өткен жоқ.