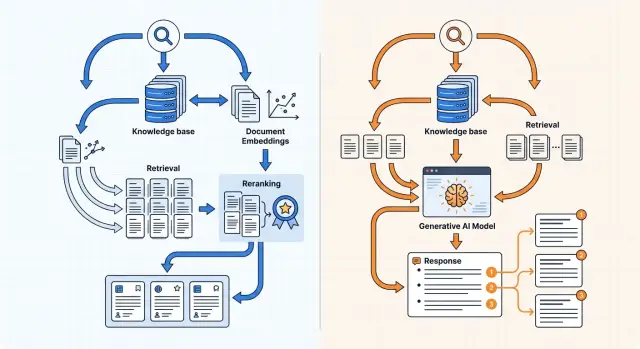
Білім базасы арқылы іздеу: эмбеддингтер ме, әлде генеративті модель ме
Білім базасы арқылы іздеуді эмбеддингтермен де, генеративті модельмен де құруға болады. Индекстеу, реранжирлеу және дәйексөзбен жауап беруді талдаймыз.
Мұндағы мәселе неде
Білім базасы арқылы іздеу сирек бір үлкен қателіктен бұзылады. Көбіне бірден бірнеше ұсақ мәселе кедергі келтіреді, ал олар бірге әлсіз нәтиже береді.
Бірінші мәселе қарапайым: адам сұрақты құжаттарда жазылған сөздермен қоймайды. Қызметкер: "телефон ауысқаннан кейін қолжетімділікті қалай қалпына келтіремін" дейді, ал базада "екінші факторды қайта шығару" деген тақырып тұр. Мағынасы бір. Бірақ беттегі сөздер бойынша — жоқ. Сондықтан кәдімгі іздеу жақсы жиналған базаның өзінде де керек үзіндіні жиі өткізіп алады.
Екінші мәселе — жауаптың сирек бір абзацта ғана жатуы. Шарттың бір бөлігі регламентте, қадамдары нұсқаулықта, ал ерекшеліктері өткен айдағы жаңартуда тұруы мүмкін. Жүйе тек бір бөлікті тапса, жауап толық болмайды. Пайдаланушы үшін бұл ашық "табылмады" дегеннен де жаман, өйткені қате шынайы болып көрінеді.
Үшінші мәселе — деректердегі шу. Базада көбіне дубликаттар, ескі нұсқалар, черновиктер, бос шаблондар және пайдалы мәтіні екі жол ғана, ал қызметтік мәтіні он жол болатын беттер болады. Мұндай қоқыс қарапайым іздеуге де, ақылдырақ тәсілдерге де кедергі жасайды. Жүйе ең жақсы құжатты емес, ұқсас сөздер жиірек кездескен құжатты көтере бастайды.
Тағы бір практикалық жайт бар. Пайдаланушыға жауаптың өзін алу аз. Ол оның қайдан шыққанын білгісі келеді. Бұл әсіресе банк, телеком және медицинада маңызды, өйткені "шамасы, солай шығар" дегенге сүйенуге болмайды. Дереккөзден алынған дәйексөз керек, тіпті бірнеше қысқа дәйексөз керек болуы мүмкін. Сонда жауапты тез тексеруге болады, ал күмәнді жерді бастапқы құжаттан ашып оқуға болады.
Сондықтан білім базасы арқылы іздеу тек "не табылды" деген сұрақ емес, "оған қаншалықты сенуге болады" деген сұрақ та.
Эмбеддингтер арқылы іздеудің пайдасы қандай
Эмбеддингтер арқылы іздеу адамдар сұрақты бір сөзбен, ал база жауабын басқа сөзбен жазғанда пайдалы. Жүйе сұрақ пен мәтіннің әр фрагментін векторға айналдырып, мағынасы жағынан ең жақындарын іздейді. Білім базасы үшін бұл көбіне сөз бойынша кәдімгі іздеуден пайдалырақ.
Соның арқасында дәл сөз сәйкестігі ғана емес, мағыналық ұқсастық та табылады. Егер қызметкер "клиент деректері қайда сақталады" десе, ал құжатта "data residency Қазақстан ішінде" деп жазылса, мұндай қабат керек үзіндіні бәрібір көтеруі мүмкін. Сол сияқты "аудит журналдары" мен "audit-логтар" жұптарында да жұмыс істейді.
Үлкен база үшін бұл жылдам да. Векторлық индекс барлық құжатты бір-бірлеп қарап шықпайды. Ол тез арада шағын кандидаттар жиынын таңдап береді, сосын олармен әрі қарай жұмыс істеуге болады. Сондықтан эмбеддингтерді құжаттама, регламент немесе тикет мыңдаған бет болғанда бірінші қабат ретінде қолдану ыңғайлы.
Ол қай жерде мықты, қай жерде әлсіз
Мұндай іздеу ең жақсысы — әртүрлі тұжырымдар, синонимдер және қысқа контексті сұрақтарда. Алдын ала ұқыпты фрагменттерге бөлінсе, FAQ, нұсқаулықтар және ішкі мақалаларда жақсы жұмыс істейді.
Бірақ мағыналық жақындық жауаптың дәлдігімен тең емес. Қосымша ранжирлеусіз іздеу көбіне жай ғана "ұқсас" фрагментті көтереді, бірақ ол тікелей жауап бермейді. Мысалы, API key деңгейіндегі лимит туралы дәл үзіндінің орнына жүйе қауіпсіздік немесе қолжетімділікті басқару туралы жалпы бөлімді беруі мүмкін.
Тағы бір шекара бар. Эмбеддингтер арқылы іздеу өзі финалдық жауап жазбайды. Ол тек кандидаттарды табады. Егер қысқа жауап, дәйексөз және бірнеше дереккөзді біріктіру керек болса, бір ғана векторлық қабат жеткіліксіз.
Практикада бұл күшті база, бірақ толық жүйе емес. Эмбеддингтер іздеу аясын жылдам тарылтады және сөздер сәйкес келмегенде мағынаны жақсы ұстайды. Соңғы қадамдағы дәлдікке басқа бөліктер жауап береді.
Генеративті модель не береді
Генеративті модель іздеу материалдарды тауып қойған кезде, бірақ адамға құжаттар тізімі емес, байланысқан жауап керек болғанда пайдалы. Ол ұзын сұрақты жақсы ұстайды, диалогтағы нақтылауды түсінеді және қолданушы шаблонмен жазбаса да, мағынаны сирек жоғалтады.
Бұл әсіресе күрделі сұрауларда байқалады. Егер қызметкер: "Корпоратив клиенттерге қайтару шарттары қандай және алдын ала тапсырысқа ерекшелік бар ма?" — десе, модель қайтару ережесінен бір бөлікті, B2B келісімшартынан тағы бір бөлікті алып, екі бөлек сілтеменің орнына бір жауап құра алады.
Оның күшті жағы — кез келген бағаға іздеу емес, бірнеше табылған фрагменттен жауап құрастыру. Білім базасының әр жерінде жатқан фактілерді модель қысқа мәтінге біріктіріп, қайталануды алып тастап, ойдың желісін сақтай алады. Пайдаланушы үшін бұл көбіне бес құжатты қатар оқығаннан ыңғайлырақ.
Бірақ бұл схеманың әлсіз жері де бар. Егер контексте дерек аз болса, ол ескі болса немесе сұраққа нашар келсе, модель өз бетімен толықтыра бастайды. Ол бос орындарды шындыққа ұқсас мәтінмен толтырады, ал қате сенімді болып көрінеді. Білім базасында бұл қауіпті: адам әдемі жауапты көреді де, құжаттарда нақты негіз жоқ екенін бірден байқамай қалады.
Сондықтан генеративті модельді бүкіл іздеуге бірден жіберу көбіне дұрыс емес. Егер ол әр сұрауда тым көп құжатты өзі оқыса, құны тез өседі, ал жауап баяу келеді. Бұл орташа жүктемеде де сезіледі. Алдымен іздеу мен реранжирлеу арқылы кандидаттар санын тарылтып, содан кейін модельге ең жақсы 5–10 фрагментті берген әлдеқайда тиімді.
Дәйексөздер үшін қатаң режим керек. Промптта ережелерді ашық берген дұрыс:
- тек берілген фрагменттер бойынша жауап бер;
- әр маңызды фактіден кейін дереккөзді көрсет;
- дерек жетпесе, "базада растама таппадым" деп жаз;
- ұқсас тұжырымдарды бір "жалпы" дәйексөзге біріктірме.
Мұндай тәсіл жақсы нәтиже береді: модель адамша жазады, бірақ құжаттардан алшақ кетпейді. Егер команда AI Router сияқты шлюз қолданса, бірдей фрагменттер жиынында бірнеше модельді тез салыстырып, қайсысы дәйексөздермен және ұзын контекстпен мұқият жұмыс істейтінін көру оңай.
Артық шуға жол бермей индекс қалай құрылады
Нашар индекс эмбеддингтер мен реранжирлеуге дейін-ақ білім базасы арқылы іздеуді бұзады. Егер фрагменттерге сайт мәзірі, батырмалар, белгішелердің атауы, футер және шаблондағы дубликаттар түссе, іздеу қоқысты тарта бастайды. Кейін модель сенімді жауап береді, бірақ мағынаға емес, шуға сүйенеді.
Алдымен бастапқы деректі тазалаңыз. Адам сұраққа жауап алу үшін оқитын мәтінді ғана қалдырыңыз. Навигацияны, қызметтік блоктарды, дисклеймерлерді, қайталанатын тақырыптарды және құжаттың әр карточкасындағы бірдей сөйлемдерді алып тастаңыз. Егер бір абзац бес жерде қайталанса, оның бір ғана таза нұсқасын сақтаңыз.
Мәтінді 500 немесе 1000 таңбаға бөлу ыңғайлы, бірақ бұл көбіне мағынаны бұзады. Құжат құрылымына қарай бөлген дұрыс: бөлім, тармақша, нұсқаулық қадамы, жеке ереже, ескерту. Сонда фрагмент бір сұраққа толық жауап береді де, шарттың ортасында үзілмейді.
Әр фрагменттің қасына метадеректерді сақтаңыз: құжат атауы, бөлім атауы, күні, нұсқасы және дереккөз түрі. Бұл ескірген мәтінді сүзуге қатты көмектеседі. Нұсқасы жоқ регламенттер мен нұсқаулықтарда іздеу ескі және жаңа ережелерді тез шатастыра бастайды.
Барлығын бір ортақ индекске салмаңыз. FAQ, ресми регламенттер және тірі хат алмасу әртүрлі міндет атқарады әрі әртүрлі тілмен жазылады. Оларды кемінде үш коллекцияға бөлген оңай: қысқа типтік сұрақтарға арналған FAQ, нақты ережелерге арналған регламенттер мен саясаттар, ал хат алмасу мен тикеттерді көмекші қабат ретінде қалдырыңыз.
Жиі жіберілетін тағы бір қателік — дерек пішінін жоғалту. Кестелер, тізімдер және тіркемелерді бөлек белгілеу керек. Тарифтер кестесі, ерекшеліктер тізімі және PDF-қосымша кәдімгі абзацпен тең емес. Егер оны белгілемесеңіз, іздеу контекстсіз фрагментті қайтарады, ал сандар мен шарттар бұзылады.
Жақсы индекс жалықтыратындай қарапайым. Онда бастапқы мәтінге қарағанда сөз аз, бірақ әр фрагментті ұялмай дәйексөзге айналдыруға болады.
Реранжирлеу қадамдары қалай құрылады
Білім базасы арқылы іздеуде реранжирлеу көбіне міндетті. Эмбеддингтер арқылы сіз көбіне мағынасы ұқсас бөліктерді табасыз, бірақ олардың арасында артық беттер, жалпы ережелер және ұқсас сөздері бар фрагменттер қалады.
Әдетте схема былай көрінеді:
- Алдымен векторлық іздеу 20-50 кандидат әкеледі. Егер аз алсаңыз, керек фрагментті жоғалтып аласыз. Егер тым көп алсаңыз, реранжер шуға уақыт жұмсайды.
- Содан кейін реранжер сұрақ пен табылған бөліктерді алады. Ол әр "сұрақ + фрагмент" жұбын бағалап, жауапқа нақты қаншалықты пайдалы екенін жақсы көрсететін балл қояды.
- Кейін төмен балл жинағанның бәрін алып тастау керек. Шекті өз сұрақтарыңызда тексеріп алған дұрыс, аспаннан алып қоюға болмайды.
- Финалдық модельге 3-8 ең жақсы фрагмент жіберген жөн. Сонда оған жауапты дәйексөзбен құрау жеңілдейді және көрші тақырыптар араласып кетпейді.
Бұл әсіресе қысқа сұрақтарда қатты сезіледі. "Тауарды қайтару лимиті" немесе "демалысты ауыстыру" сияқты сұрақ тым жалпы естіледі. Эмбеддингтер арқылы іздеу үстіне керек бөлімді де, ұқсас сөздері бар, бірақ басқа мағынадағы құжаттарды да шығара алады.
Ұзын сұрақтарда жағдай бөлек. Пайдаланушы егжей-тегжей жазса, эмбеддингтер жақсырақ жұмыс істейді, бірақ реранжирлеу бәрібір артық бөліктерді алып тастайды. Бұл модельдің жауапты әртүрлі құжаттардан жабыстырып, артық нәрсе қосу қаупін азайтады.
Қарапайым мысал: қызметкер пайдаланылмаған демалысты келесі жылға ауыстыруға бола ма деп сұрайды. Бірінші кезең жалпы демалыс регламентін, HR-ға арналған жадынаманы және ауру парағы туралы бөлімді қайтарады. Реранжирлеуден кейін әдетте тек ауыстыру ережесі, мерзімдері мен ерекшеліктері ғана қалады.
Егер команда LLM-сұрауларын AI Router сияқты бір шлюз арқылы өткізіп жүрсе, мұндай схеманы тәжірибеде тексеру жеңіл. Бірдей клиент кодын өзгертпей-ақ реранжерді ауыстырып, кідірісін көруге және қысқа әрі ұзын сұрақтардағы сапаны салыстыруға болады.
Дәйексөзбен жауапты қалай құрау керек
Дәйексөзбен жауап тек модель өз бетінше бірдеңе "еске түсірмегенде" жұмыс істейді. Білім базасы үшін бұл ережені қатаң еткен дұрыс: модель тек сұрауға берген фрагменттер бойынша жауап береді. Егер оларда керек факт жоқ болса, ол солай жазады: "жауапқа дәлел табылмады".
Әр фрагментке қысқа әрі көзге бірден түсетін ID беріңіз. DOC-12, FAQ-03 немесе POL-7 сияқты қарапайым белгілер жарайды. Сонда модель дереккөзді бұлыңғыр қайталамайды және даулы тұжырымнан кейін бірден нақты мәтін бөлігіне сілтеме қоя алады.
Жауаптың жақсы форматы қарапайым: тезис, сосын жақша ішіндегі дәйексөз. Мысалы: "Логтарды сақтау мерзімі — 90 күн [POL-7]". Егер бір сөйлемде екі бөлек факт болса, соңында бір жалпы дәйексөздің орнына екі бөлек дәйексөз қойған дұрыс.
Жалпы жауапты сілтемесіз беруге промптта тікелей тыйым салған жөн. Әйтпесе генеративті модель әрдайым әдемі, сенімді көрінетін, бірақ құжатқа сүйенбейтін мәтін құрап береді. Бұл жиі болатын бұзылыс: жауап жақсы оқылады, бірақ оны тексеру мүмкін емес.
Модельге төрт қарапайым ереже берген пайдалы:
- берілген фрагменттерден тыс білім қолданба;
- тексерілетін әр фактіден кейін дереккөз ID-сін қой;
- бір дәйексөзге бір-бірімен байланыспайтын бірнеше тұжырымды біріктірме;
- фрагменттер жауапты растамаса, дерек жетпейтінін ашық жаз.
Генерациядан кейін тағы бір сүзгі керек. Ол жауап стилін емес, сөйлем мен дәйексөздің байланысын тексереді. Егер модель "келісімшартты кез келген күні бұзуға болады [DOC-4]" деп жазса, тексеру DOC-4 ішінде шынымен сол шарт бар-жоғын, әлде онда жай ғана бұзу туралы сөздер ғана ма — соны қарауы тиіс.
Практикада бұл мәселелердің жартысын шешеді. Тіпті қарапайым post-check қадамы да ең жағымсыз қателерді алып тастайды: ойдан шығарылған мерзімдерді, қате лимиттерді және басқа құжатқа жасалған сілтемелерді.
Үлгі сұрақтардағы мысал
Типтік сұрақтарда эмбеддингтер мен генеративті модельдің айырмасы ең тез көрінеді. Бір сұрақ қосымшадағы кестеге тірелуі мүмкін, екіншісі — жаңа FAQ-қа, үшіншісі — бірден екі құжатқа.
Эмбеддингтер қай жерде дәл түседі
"Логтарды сақтау мерзімі қандай?" деген сұрақ қарапайым сөздік іздеуді жиі шатастырады. Базада әдетте логтау регламенті және мерзімдері бар бөлек қосымша болады. Эмбеддингтер көп жағдайда қосымшаны жақсы табады, өйткені сұрақ пен фрагмент мағына жағынан жақын, тіпті кестеде "audit-логтарды сақтау мерзімі" немесе "ретенция" сияқты тіркестер тұрса да.
Бірақ табылған бір бөлік жеткіліксіз. Пайдаланушыға жай кесте үзіндісі емес, қысқа жауап керек: қандай мерзім, қай логтар үшін және ол қай жерде бекітілген. Мұнда генеративті модель пайдалырақ. Ол мерзімді қосымшадан алады, регламенттегі шартты қосады да, екі дәйексөзбен бір байланысқан жауап құрайды.
"Теңгемен төлеуге бола ма?" деген сұрақта жағдай басқаша. Іздеу көбіне FAQ-ты, төлем шарттары бар бетті және ескірген бетті тауып береді. Эмбеддингтер үшеуін де бірге әкелуі мүмкін. Сосын реранжирлеу ескі бетті төмен түсіріп, тікелей әрі жаңа жауап бар мәтінді жоғары қалдырады.
Модель қай жерде пайдалы, қай жерде қателеседі
"Шоттағы қате болса не істеу керек?" деген сұрақ сирек бір жерде ғана тұрады. Бір құжат тексеру тәртібін сипаттайды, екіншісі хат үлгісін сақтайды, үшіншісі жауап беру мерзімін түсіндіреді. Эмбеддингтер әдетте керек бөліктерді жеке-жеке әкеледі. Генеративті модель соңғы қадамда ұтады: ол әрекеттерді дұрыс ретпен жинап, әр тармақтан кейін дәйексөз қояды.
Қате нәзік көрінеді. Модель жақын, бірақ дұрыс емес бөлімнен дәйексөз келтіруі мүмкін. Мысалы, шоттағы даулы сома бөлігінің орнына реквизиттерді түзету туралы абзацты алу. Мәтін ұқсас, сілтеме формалды түрде бар, бірақ жауап басқа жаққа бұрып жібереді. Сондықтан дәйексөздерді тек мәтін ұқсастығы бойынша емес, бөлім тақырыбы, құжат түрі және істің өз мәні бойынша да тексеру керек.
Қашан гибридті схеманы таңдаған дұрыс
Гибридті схема базаға соқыр сенуге болмайтын, ал қате құны екі қосымша миллисекундтан жоғары болатын кезде керек. Мұндай жағдай банк, телеком, медицина және көптеген ұқсас нұсқаулық, регламент нұсқасы мен бір-біріне өте ұқсас жауаптары бар кез келген ішкі базаға тән.
Ондайда жұмысты бөліктерге бөлген дұрыс. Эмбеддингтер 20-50 кандидатты тез тауып берсін. Бұл арзан, жылдам және үлкен базада жақсы жұмыс істейді. Бірақ олар жиі мағынасы жағынан қатар тұрған фрагменттерді тартады, ал онда басқа тариф, басқа мерзім немесе ереженің ескі нұсқасы болуы мүмкін.
Егер құжат көп болса және мәтіндер бір-біріне ұқсас болса, бірінші іздеуден кейін реранжер керек. Ол жауап құрмайды, тек табылған фрагменттерді дәлірек ретпен орналастырады. Практикада бұл "шамамен дұрыс" табулар санын айтарлықтай азайтады. Білім базасы үшін бұл ойлағаннан да маңызды: пайдаланушы дәлсіз жауап пен қате арасындағы айырманы онша көрмейді.
Генеративті модельді соңында қосқан дұрыс. Ол іріктеліп алынған фрагменттерді алып, қысқа дәйексөзді жауап құрасын. Сонда модель аз қиялдайды, құжаттарды сирек шатастырады және бүкіл базаны шолуға токен жұмсамайды.
"Тек табылған фрагменттерді көрсету" деген бөлек режимді де қалдырған жөн. Бұл қызметкердің дереккөзді өзі тексергісі келгенде, жауап ішкі тексерістен өтуі керек болғанда немесе модель сенімсіз болып, ештеңені қайта айтуға болмайтын кезде қажет.
Бір модель бүкіл конвейерді өзі атқармауы керек. Егер ол әрі іздесе, әрі ранжирлесе, әрі жауап жазса, қате қай жерде кеткенін бақылау қиындайды. Кейін ақау индексте ме, фрагмент таңдауда ма, әлде генерацияда ма — түсіну қиын болады.
Білім базасы үшін гибрид нақты жұмыста жиі ұтады. Эмбеддингтердегі жылдам бастапқы іздеу жылдамдық береді, реранжирлеу дәлдікті арттырады, ал генеративті модель ыңғайлы финалдық жауап жасайды. Әр қадамның өз міндеті бар, және бұл бәрін бір модельден бірден сұрағаннан сенімдірек.
Командалар көбіне қай жерде қателеседі
Мәселелердің басым бөлігі модельден емес, команданың білім базасын қалай дайындайтынынан басталады. Құжаттар индекске шикі күйінде, құрылымсыз, нұсқасыз және фрагмент шекаралары дұрыс қойылмай түскен болса, тіпті жақсы іздеу де тез мәнін жоғалтады.
Индекстеудегі қателер
PDF-ті жиі біртұтас мәтін ретінде жүктейді. Нәтижесінде тақырыптар, кестелер, сноскалар мен ескертпелер бір ағынға жабысып қалады. Іздеу сөздерді табады, бірақ құжаттың мағынасын жоғалтады. Егер нұсқаулықта "Ерекшеліктер" бөлімі бар болса, ал қасында кестеде ескі лимиттер тұрса, модель қатар тұруы тиіс емес бөліктерден жауапты оңай жинап алады.
Тағы бір шеткі жағдай — тым ұсақ бөлу. Команда мәтінді 100-150 таңбаға бөлсе, фрагментте тұтас ой болмай қалады. Тауарды қайтару туралы сұрақ "14 күн ішінде" деген бөлікке түсіп, ал "тек онлайн тапсырыстар үшін" деген шарт көрші фрагментте қалып, жоғалуы мүмкін.
Жиі кездесетін тағы бір қате — индекс жаңартылмай қалады. Құжатты өзгертіп қойған, ал іздеу бәрібір ескі нұсқаны тартады. Банк, ритейл немесе телеком командасы үшін бұл тез арада клиентке қате жауап беруге және қолмен тексерудің көбеюіне әкеледі.
Жауаптағы қателер
Іздеу жақсы болса да, командалар жиі промптқа тым көп фрагмент салады. Модель 15-20 бөлік көреді, олардың бір бөлігі бір-бірімен қайшы келеді, ал жауап бұлыңғыр болып кетеді. Әдетте аз, бірақ таза фрагмент берген дұрыс: реранжирлеуден кейінгі бірнеше күшті кандидат ұзын мәтін үйіндісінен көбіне жақсы жұмыс істейді.
Дәйексөзде де жиі қателеседі. Кез келген көрші абзац немесе тақырыбы ұқсас үзінді дәйексөз бола алмайды. Дәйексөз жауаптағы нақты фразаны тікелей растауы керек. Егер жауапта сома, мерзім немесе шарт болса, жанында сол құжаттағы дәл жол тұруы тиіс, ал сол бөлімнің жалпы абзацы емес.
Қалыпты жүйе қарапайым нәрселерге сүйенеді: ұқыпты парсинг, фрагменттің орынды өлшемі, жаңартылған индекс және дәйексөздерді қатаң тексеру. Бұларсыз эмбеддингтер мен генеративті модель арасындағы таластың мәні жоғалады.
Іске қосар алдындағы жылдам тексеріс
Білім базасы арқылы іздеуді қысқа тестсіз іске қосу — жақсы идея емес. Демода бәрі сенімді көрінеді, ал тірі сұрақтарда тез арада бос жауаптар, қате дәйексөздер және модельге артық шығындар шығады.
Алғашқы тексеріс үшін қызметкерлерден немесе клиенттерден алынған 30-50 нақты сұрақ жеткілікті. Идеал формулировкаларды емес, кәдімгі сұрақтарды алған жақсы: қателері бар, қысқа нақтылауы бар және бұлыңғыр сөздері бар. Сонда жүйенің лабораторияда емес, шынайы жұмыста қалай әрекет ететінін көресіз.
Іске қоспас бұрын бес нәрсені тексерген жөн:
- әр сұрақтың эталондық дереккөзі бар: нақты құжат, бөлім және нұсқа;
- іздеуді, реранжирлеуді және финалдық жауапты бөлек қарап шығасыз, тек жалпы нәтижеге ғана қарамайсыз;
- бір жауаптың құнын жеке есептейсіз: іздеу, реранжирлеу және генерацияны қоса;
- база жеткілікті күшті дәлел таппаса, жүйе үндей алады;
- жаңа файл, түзету және ескі нұсқаны жоюдан кейін индексті кім жаңартатыны алдын ала келісілген.
"Үндей алу" тармағы әсіресе маңызды. Егер модель жорамалдап жауап берсе, қате шынайы болып көрінеді де, продта ұзақ өмір сүреді. Білім базасы үшін "растама табылмады" деген жауап бөтен дәйексөзбен берілген сенімді ойдан шығарылған жауаптан қауіпсіз.
Тағы бір жиі қателік — тек дәлдікті тексеріп, құнын ұмыту. Бір ғана сұрақты шартты түрде 2 центке де, 20 центке де шешуге болады. Жүздеген мың сұрауда айырмашылық жағымсыз сезіледі. Егер команда бірнеше модельді OpenAI-үйлесімді AI Router сияқты шлюз арқылы салыстырса, SDK-ны өзгертпей бір сұрақтар жинағын өткізіп, қай жерде артық төлем сапаны айтарлықтай өсірмейтінін бірден көруге болады.
Егер құжат түзетілгеннен кейін индекс бір аптадан соң ғана жаңарса, бүкіл тесттің мәні жоғалады. Іске қосу алдында қарапайым әрі анық процесс болуы керек: жаңа нұсқаны кім жүктейді, ескі нұсқаны қалай белгілейді және жүйе қашан оған сілтеме жасауды тоқтатады.
Практикада неден бастау керек
Адамдар қазірдің өзінде қоятын 30-50 нақты сұрақты алыңыз. Қолдаудан келетін өтініштерді, сатылымнан түсетін жиі сұрақтарды және ішкі регламенттерден алынған үзінділерді араластырыңыз. Сонда сіз әдемі демоны емес, тірі жүктемені тексересіз: қысқа фактологиялық сұрақтарды, шарттары бар ұзын сұрақтарды және даулы тұжырымдарды.
Жиынтықты бірнеше түрге бөлген ыңғайлы: "Өтінішке жауап беру мерзімі қандай?" сияқты қарапайым факт, "Клиент деректерін өшіруді сұраса не істеу керек?" сияқты қадамдық сұрақ, "Ереже қашан қолданылмайды?" сияқты ерекшелігі бар сұрақ және пайдаланушының сөздері құжат мәтінімен сәйкес келмейтін сөйлесу стиліндегі сұраныс.
Кейін сол бірдей жиынтықты үш схема арқылы өткізіңіз. Біріншісі — реранжирлеуі бар эмбеддингтер арқылы іздеу. Екіншісі — гибрид: сөз бойынша кәдімгі іздеу плюс векторлық іздеу, содан кейін реранжирлеу. Үшіншісі — табылған фрагменттер бойынша дәйексөзбен генеративті жауап. Тест барысында таңдауды өзгертпеңіз, әйтпесе салыстыру тез мәнсіз болады.
Нәтижелерді бір кестеге жинаған ыңғайлы:
| Схема | Дәлдік | Баға | Кідіріс | Дәйексөз сапасы |
|---|---|---|---|---|
| Эмбеддингтер | ||||
| Гибрид | ||||
| Генеративті жауап |
Тек дұрыс жауаптардың үлесіне емес, басқа нәрселерге де қараңыз. Жүйе көбіне сенімді көрінетін жауап жазады, бірақ дұрыс емес құжатқа сілтеме жасайды немесе көрші абзацтан дәйексөз тартады. Білім базасы үшін бұл жаман белгі. Егер дереккөзі тұрақсыз болса, пайдаланушылар іздеуге де, жауапқа да тез сенбей қояды.
Егер команда бір сценарийді бірнеше модель мен провайдер арқылы өткізіп отырса, әр тест үшін интеграцияны қайта жазудың қажеті жоқ. AI Router арқылы airouter.kz-де base_url-ды api.airouter.kz-ке ауыстырып, нұсқаларды SDK, код және промпттарды өзгертпей салыстыруға болады. Бұл әсіресе өлшеу кезеңінде ыңғайлы: бастысы — адал тексеріс, жаңа орта жинағы емес.
Тесттен кейін сенімді түрде дұрыс дереккөзді табатын ең қарапайым нұсқаны қалдырыңыз. Егер эмбеддингтердің өзі дәл құжатты және қалыпты дәйексөздерді берсе, схеманы күрделендірудің қажеті жоқ. Егер олар синонимдерде, ұзын сұрақтарда немесе ережедегі ерекшеліктерде жиі қателессе, онда гибридті іздеу мен генеративті қабатты қосу орынды.
Жиі қойылатын сұрақтар
Білім базасы үшін не жақсы: эмбеддингтер ме, әлде генеративті модель ме?
Эмбеддингтер сұрақтағы және құжаттағы сөздер дәл сәйкес келмесе де, үзінділерді мағынасы бойынша іздейді. Генеративті модель өзі жақсы іздемейді, бірақ табылған бөліктерден қысқа, түсінікті жауап құрап, дәйексөз қоса алады.
Неге кәдімгі сөздік іздеу жиі қателеседі?
Өйткені адамдар сұрақты көбіне сөйлесу тілінде қояды, ал құжаттар ресми немесе техникалық тілмен жазылады. Қатынасты қалпына келтіру туралы сұрақ перевыпуск второго фактора туралы мақаладағы сөздермен сәйкес келмеуі мүмкін, бірақ мағынасы бір.
Қашан бір ғана векторлық қабат емес, гибридті іздеу керек?
Егер сізде ұқсас құжаттар, ескі нұсқалар және ережедегі ерекшеліктер көп болса, гибридті тәсілді таңдаңыз. Алдымен іздеу кандидаттарды тез табады, кейін реранжирлеу артықтарын алып тастайды, ал модель финалдық жауапты тек ең жақсы үзінділерден жазады.
Финалдық жауап үшін модельге қанша фрагмент беру керек?
Әдетте реранжирлеуден кейінгі 3–8 күшті үзінді жеткілікті. Егер 15–20 бөлік берсеңіз, модель тақырыптарды жиі араластырады, ескі нұсқаларды іліп алады және көмескі жауап жазады.
Құжаттарды фрагменттерге қалай дұрыс бөлу керек?
Мәтінді жай ғана таңба саны бойынша бөлмеңіз, әйтпесе мағына жоғалады. Бөлімдер, нұсқаулық қадамдары, бөлек ережелер мен ескертпелер бойынша бөліңіз, сонда бір фрагмент бір сұраққа толық жауап береді.
Индекстегі дубликаттар мен ескірген нұсқалармен не істеу керек?
Алдымен навигацияны, шаблондық блоктарды, бос беттерді және қайталануларды алып тастаңыз. Сосын әр фрагментке күнін, нұсқасын және дереккөз түрін сақтаңыз, сонда іздеу жаңа регламентті ескі черновикпен шатастырмайды.
Жауапта дәйексөздер не үшін керек?
Дәйексөзсіз адам жауаптың қайдан шыққанын және оған сенуге бола ма, жоқ па — түсінбейді. Тексерілетін фактіден кейін қысқа фрагмент ID-сін қою ең ыңғайлы, сонда күмәнді жерді бір минутта ашып тексеруге болады.
Егер модель тікелей дәлел таппаса, не істеу керек?
Модельден тек берілген фрагменттер бойынша жауап беруді және растау жоқ екенін ашық жазуды сұраңыз. Мұндай бас тарту кейін жұмысқа кететін, бірақ шын мәнінде дұрыс емес әдемі ойдан шығарылған жауаптан пайдалырақ.
Продқа шығар алдында жүйені қалай тексеруге болады?
Бірінші тексеріс үшін қызметкерлерден немесе клиенттерден алынған 30–50 нақты сұрақ жеткілікті. Тек дәлдікке емес, жауап бағасына, кідірісіне, дәйексөз сапасына және дерек аз болғанда жүйенің үндей алмайтынына да қараңыз.
Интеграцияны қайта жазбай бірнеше модельді салыстыруға бола ма?
Иә, егер сіз OpenAI-үйлесімді шлюзді, мысалы AI Router-ды қолдансаңыз. Тек base_url-ды api.airouter.kz-ке ауыстырып, SDK, код және промпттарды өзгертпей бірдей сұрақтар жинағын әртүрлі модельдерден өткізе аласыз.